Apriori算法的压缩二进制编码改进
2020-07-14肖建于徐成振
谷 鹏,肖建于,徐成振
(淮北师范大学计算机科学与技术院,安徽淮北235000)
随着大数据时代的到来,各领域产生的数据呈“井喷式”增长,数量多而杂,从以前的GB 级别,飞速发展到现在PB 甚至EB 级别的数据. 虽然数据增长很快,但是真实价值的数据是分散在这些海量数据中的. 因此数据挖掘技术应运而生,而关联规则是其中一个重要的分支,在数据挖掘中有着广泛的运用. Agrawal 等[1]在1993 年首次提出的Apriori 算法是关联规则挖掘算法中最有影响力的一种,但Apriori也存在缺陷:一是生成候选项集和频繁项集的效率低;二是要多次扫描数据库,I/O 负载大;三是候选项集与未处理的事务集对比占用大量时间和空间.
不少学者对此从各个方面进行研究改进.Bhandari 等[2]采用并行算法和聚类算法的思想对算法进行改进. Vasoya 等[3]提出将数据库划分为各个簇,再用基于矩阵的Apriori 算法对每个簇进行处理. 张岩庆[4]、陈兴蜀等[5]针对大数据集使用分布式的方法对算法进行改进. 徐哲炜等[6]通过增加约束条件减少候选集的想法改进Apriori算法.Liu 等[7]利用先验的思想对数据进行处理,结合信息的特性产生关联规则.
这些算法对Apriori 进行了改进,提高了算法效率,但也存在着不足. 一是忽视了数据库中的事务可能存在的重复信息,使得算法的对比次数增多;二是没有对处理的事务进行压缩整理,消耗了大量存储空间. 对此,本文提出基于压缩二进制编码的Apriori 改进算法CBE-Apriori (Compressed Binary Encoded),只需要对数据库扫描两次,利用二进制数间的运算更为高效的思想,将集合转化成二进制编码,并对事务的二进制编码压缩,减少空间占用和比较次数提升算法效率.
1 相关知识
1.1 性质与定义
定义1[8]设I={i1,i2,...,im}是所有项的集合,T={t1,t2,...,tn}是所有事务的集合. 事务集合T的每个项集都是I的子集.
性质1[9]频繁项集的所有非空子集必是频繁项集,任意非频繁项的超集必是非频繁项集.
性质2频繁k项集A和B连接得到的候选(k+1)项集C,若其子集{A[k],B[k]}不是频繁项集,则候选集C必不是频繁项集.
证明:由性质1得,因为C的子集{A[k],B[k]}不是频繁项,所以C不是频繁项集.
性质3将A和B两个数据集转化为二进制编码,若AB=A,则A为B的子集.
性质4将A和B两个数据集转化为二进制编码,则A∧B的结果为A和B不同时含有的项集.
1.2 基本算法
Apriori算法是数据挖掘算法中最为常用的算法之一,应用在各种领域,例如铁路风险的预控[10]、森林虫害预测[11]、城市交通流预测[12]等.Apriori算法的核心基于性质1,通过寻找候选项集并利用迭代的方法由频繁k项集生成候选(k+1)项集,其主要流程由以下两步组成:
(1)连接,若两个k项集的前k-1 项相等但第k项不同,则连接两个频繁项集生成候选(k+1)项集.
(2)剪枝,通过扫描数据库,计算候选项集中每个项集的支持度,将其与最小支持度进行比较,若小于最小支持度,则不是频繁项集,删去此项来缩减候选项选项集,最后遍历完生成频繁项集.
2 CBE-Apriori 算法
由以上描述可知,Apriori 算法每次生成频繁项集时需要对数据库进行扫描,影响算法的运行效率;连接时,需判断项集前(k-1)项元素是否相等;计算支持度时需对每个事务进行对比,没有对事务进行压缩.
2.1 算法改进思想
(1)通过扫描数据库得到的频繁1-项集,对事务进行二进制编码,利用频繁1-项集对事务编码可以减小编码的长度,且二进制运算的效率更高,以可以提高算法的性能.
(2)事务编码后会出现重复项,对其统计并将重复项只保留一个,这样可以减少之后频繁项集编码与事务编码对比的次数.
(3)根据性质2、3、4,将候选项集和事务进行逻辑“与”的操作来计算支持度;将两个候选项集逻辑“异或”操作,判断其是否为频繁项集,减少了算法的时间复杂度.
2.2 算法流程
CBE-Apriori算法流程如下:
输入:事务数据库D,最小支持度min-support
输出:频繁项集L
(1)扫描输入的事务数据库D,获取频繁1-项集
(2)扫描事务数据库D,通过获取的频繁1-项集将事务转化为二进制编码.
(3)扫描事务的二进制编码,将相同的二进制编码压缩成一个并计数出现次数到n中,得到事务二进制编码集Dc.
(4)通过频繁k项集生成候选(k+1)项集,利用性质3将候选k项集和Dc进行与的位运算操作,计算支持度,对比min-support生成频繁(k+1)项集.
(5)利用性质2 和4 将频繁项集两两异或,判断结果是否为频繁2-项集. 若是将频繁项集与异或的结果利用或位运算将其连接生成候选k项集,重复步骤(4)的操作生成频繁(k+1)项集.
(6)最终将步骤(4)生成的结果合并为L.
3 算法分析与实验对比
3.1 实例分析
举例说明CBE-Apriori算法,事务数据库如表1所示,设最小支持度为0.4.

表1 事务数据库
(1)扫描事务数据库,获取频繁1-项集,对得到的频繁1-项集转化为二进制编码,频繁1-项集与编码结果如表2所示.

表2 频繁1-项集与编码结果
(2)通过频繁1-项集的编码结果对事务集进行二进制编码.每个事务中含有的单个频繁1-项子集根据其对应的二进制编码,将它们利用逻辑“或”位运算操作进行连接,得到的事务与编码结果如表3所示.

表3 事务与编码结果
(3)扫描事务的二进制编码结果,统计每个编码出现的次数并删除重复项,得到的事务编码与重复数结果如表4所示.

表4 事务编码与重复数结果
(4)扫描频繁1-项集,将其两两组合生成候选2-项集,共生成C24=6 个候选2-项集,此步骤不能进行删减操作,所以生成的候选2-项集规模较大.生成的候选2-项集与编码结果如表5所示.
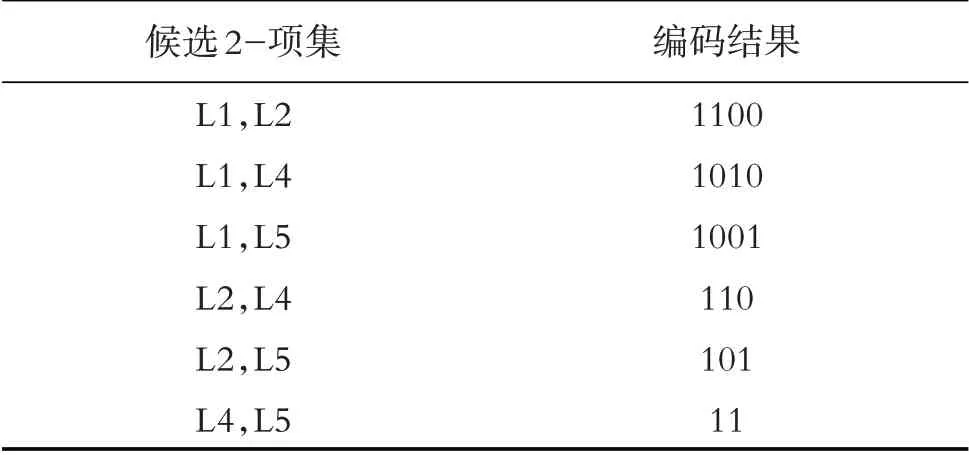
表5 候选2-项集与编码结果
(5)根据性质3,将候选2-项集编码的结果与每个事务的二进制编码逻辑“与”运算,若得到结果等于其候选2-项集编码,则将其事务编码对应的重复数提取出进行累加,累加最终的结果除以事务总数可以得到其候选项集对应的支持度.候选2-项集与支持度的结果如表6所示.

表6 候选2-项集与支持度结果
(6)根据最小支持度阈值去除不符合条件的候选2-项集生成频繁2-项集,根据性质2和性质4,将得到的频繁2-项集相互进行逻辑“异或”,将其结果是否存在与频繁2-项集中,若存在则将两个频繁2-项集进行连接得到候选3-项集编码. 例如候选2-项集编码1100 与1010,1100∧1010=110 其结果存在于频繁2-项集编码中,则1101100=1110. 其结果为候选3-项集的编码.
随着职业教育的发展,中职学校英语学科成为一门必修学科,英语口语表达成为一项必备的语言技能。然而,英语又是中职学生学习最为吃力的学科之一,大多数学生为此备受打击,已不再奢望能学好英语,处在进退维谷的尴尬境地。由此,要重点树立学生学习英语的信心和勇气,培养学生学习英语的兴趣,在教学中注入情感,用发展的眼光看待学生。同时借鉴专业教学的理念,任务引领、驱动,明确学习目标,搭建师生互动学习的平台和学生展示的舞台。再者,要尊重学生、爱护学生,建立和谐的师生关系,采用灵活的教学方法,定制学生的学习任务,让每个学生学有所获。
遍历完频繁2-项集编码的最终结果只有一个1110,所以候选3-项集只存在一个,将其与事务编码进行逻辑“与”,统计并计算得到其支持度0.6. 因为其频繁3-项集有且只有一个,所以不能生成候选4-项集,程序到此结束,最终输出所有频繁项集.
3.2 性能分析
与Apriori 相比较,可以发现CBE-Apriori 有以下几点改进:
(1)CBE-Apriori 算法只需对数据库扫描两次,避免Apriori 算法运行时多次对数据库扫描的问题,使算法效率有着显著的改善.
(2)利用位运算“与”“异或”“异或”代替Apriori算法生成候选项集和频繁项集的步骤,因采用的是位运算,所以在数据集的连接和裁剪时的时间复杂度为O(1),而Apriori 算法在连接两个频繁k项集时要判断前k-1 项是否相同,因为要按照特点顺序对其进行排列,而在较好情况下,k项集排序的时间复杂度也有O(klogk),而且裁剪操作时,要判断候选(k+1)项集的子集,因为数目为k,所以时间复杂度为O(k). Apriori 算法的连接和裁剪的时间复杂度其结果为将两者相乘得到O(k2logk). 所以相比较CBE-Apriori 算法在连接和裁剪上比Apriori 效率要更好.
(3)在对事务编码时由于将重复项压缩为一个,节约了数据占用的内存空间. 在之后的实验对比中,事务集经过压缩后相比于原事务个数有着明显的减少,可在后续的对比步骤中可以减少时间复杂度.
3.3 实验对比
实验平台为:Intel Core i5-8400 CPU,内存16 GB @2667 MHz DDR4,操作系统为Windows 10,采用Python 3.7.3 作为编程语言,分别实现Apriori算法和CBE-Apriori 算法. 实验数据选用UCI 数据库中的蘑菇(Mushroom)数据集,该数据集中共有8 124 条事务,总计119 个属性,事务含有属性的最大个数为23 个. 在图1 中按照30%、35%、40%、45%的支持度给出了Apriori 算法、BE-Apriori 算法[13]和CBE-Apriori 算法处理蘑菇数据集的各自运行时间.表7表示各支持度下,压缩后事务集的个数.

图1 蘑菇数据集运行时间

表7 支持度与事务集个数结果
当设定有支持度时,生成的频繁1-项集对事务进行编码,因滤去无意义的属性,生成的事务编码会生成大量重复项,对其进行过滤压缩,由表7 可以看出事务集个数有明显减少. 但是当最小支持度达到45%时,事务集个数没有变化,说明在最小支持度为45%的情况下,事务集的编码没有重复项.
图1 显示,最小支持度分别为30%、35%、40%、45%时,Apriori 算法运行时间分别为6.03 秒、2.43秒、1.33 秒、1.01 秒;BE-Apriori 算法运行时间分布为8.07 秒、3.91 秒、2.1 秒、1.36 秒;CBE-Apriori 算法运行时间分别为2.35 秒、1.11 秒、0.73 秒、0.66 秒. 分析实验结果分析可知,BE-Apriori 算法虽然同样用的二进制编码,但是没有对事物集压缩,当赋予的最小支持稍大时,运算效率不如初始的Apriori算法.
当支持度较小时,生成的频繁1-项集较多,会导致后续生成的候选项集和频繁项集中的元素数量更大,使得运行时间更长.因为CBE-Apriori算法采用位运算代替集合运算,并将将要对比的事务数量进行压缩,从而减少算法的运行时间.从图1可以看出,当支持度较小时,算法消耗的时间远小于Apriori;当支持度增加时算法的运行时间逐渐接近,但CBE-Apriori 算法的运行时间还是小于Apriori算法.
以上数据的对比结果显示,CBE-Apriori 算法在空间存储上和运行时间上对比Apriori 有着明显的提升,运行时间最大提升达到61%.
4 结语
本文针对经典Apriori 算法的缺点,提出通过生成的频繁1-项集将事务转化为二进制编码,且对二进制编码进行压缩,使之后的运算都在内存中完成. 并利用逻辑运算代替Apriori算法中集合直接的运算提高算法效率. 通过对算法时间复杂度的分析和实验证明,相对于Apriori 算法,改进的算法可以更快速的得到频繁项集和减少内存空间的占用,并且因为对数据集的压缩,也改进了当最小支持度稍大时,只用二进制编码运用于Apriori 算法时性能不如原算法的效率快的问题.
