基于神经网络和社区发现的高维数据推荐系统
2020-07-13唐新宇张新政刘保利
唐新宇 张新政 刘保利
1(广东工商职业技术大学计算机工程学院 广东 肇庆 526040)2(广东工业大学自动化学院 广东 广州 510090)3(空军工程大学理学院 陕西 西安 710000)
0 引 言
随着网络信息的爆炸式增长,用户从网络获取目标信息的效率降低,许多大型购物网站、新闻网站和视频网站等集成了推荐系统为用户提供感兴趣的内容[1]。传统的推荐系统大多根据用户对项目的评分信息为用户提供推荐列表,但用户评分矩阵具有极大的稀疏性,且冷启动问题和灰羊用户问题也为推荐系统带来了极大的挑战[2]。随着社交网络的普及,各种应用场景也包含了复杂的社交关系,例如在购物网站中店铺和用户之间存在关注关系,买家之间也存在社交关系[3]。将推荐系统和社交网络之类的上下文相结合,是解决推荐系统稀疏性问题、冷启动问题和灰羊用户问题的一种方式[4]。
文献[5]挖掘社交网络来发现隐藏的用户-物品偏好关系,然后对用户建模分析并选择合适的推荐引擎进行个性化物品推荐,该算法展开了对用户社交关系和隐性反馈的研究,加入了社交关系、人口统计学信息和用户消费记录等隐性信息。文献[6]先基于社交网络将用户分组,再使用局部敏感哈希技术为分组提供推荐列表。文献[7]设计了好友强度指标计算社交圈的紧密性,然后根据好友强度和社交圈紧密度预测用户的偏好,提高推荐的准确率。文献[8]将社交网络关系引入协同过滤推荐系统中,从社交网络提取用户偏好和社区偏好信息并建模为质量函数,通过Dempster组合规则将多个偏好融合,由此提高协同过滤推荐系统的推荐性能。随着社交关系日益复杂,用户可能受到多重社交关系和上下文的影响,这些影响因素称为“上下文维度”[9]。现有的方案[5-8]为了提高推荐系统的性能,大多考虑了全部的“上下文维度”,导致计算复杂度提高,并且对推荐的准确率也产生了负面的影响。
为了解决“上下文维度”问题,本文设计了基于神经网络和社区发现的推荐系统。建立多层感知神经网络来识别最相关的上下文维度,学习上下文维度对用户偏好的影响力;设计了社区发现算法将用户分组,解决稀疏性问题并降低数据的维度;采用张量分解模型处理相关上下文维度,提高处理效率;最终基于上下文信息丰富的真实数据集完成了仿真实验,实验结果验证了本文算法的有效性。
1 总体结构设计
图1为本文推荐系统的总体结构设计。系统包含4个模块:(1) 采用神经网络识别影响力大的上下文维度;(2) 基于社交关系、地理位置、人口统计学将用户分组;(3) 基于用户分组的张量分解模型处理上下文维度数据;(4) 产生推荐列表。
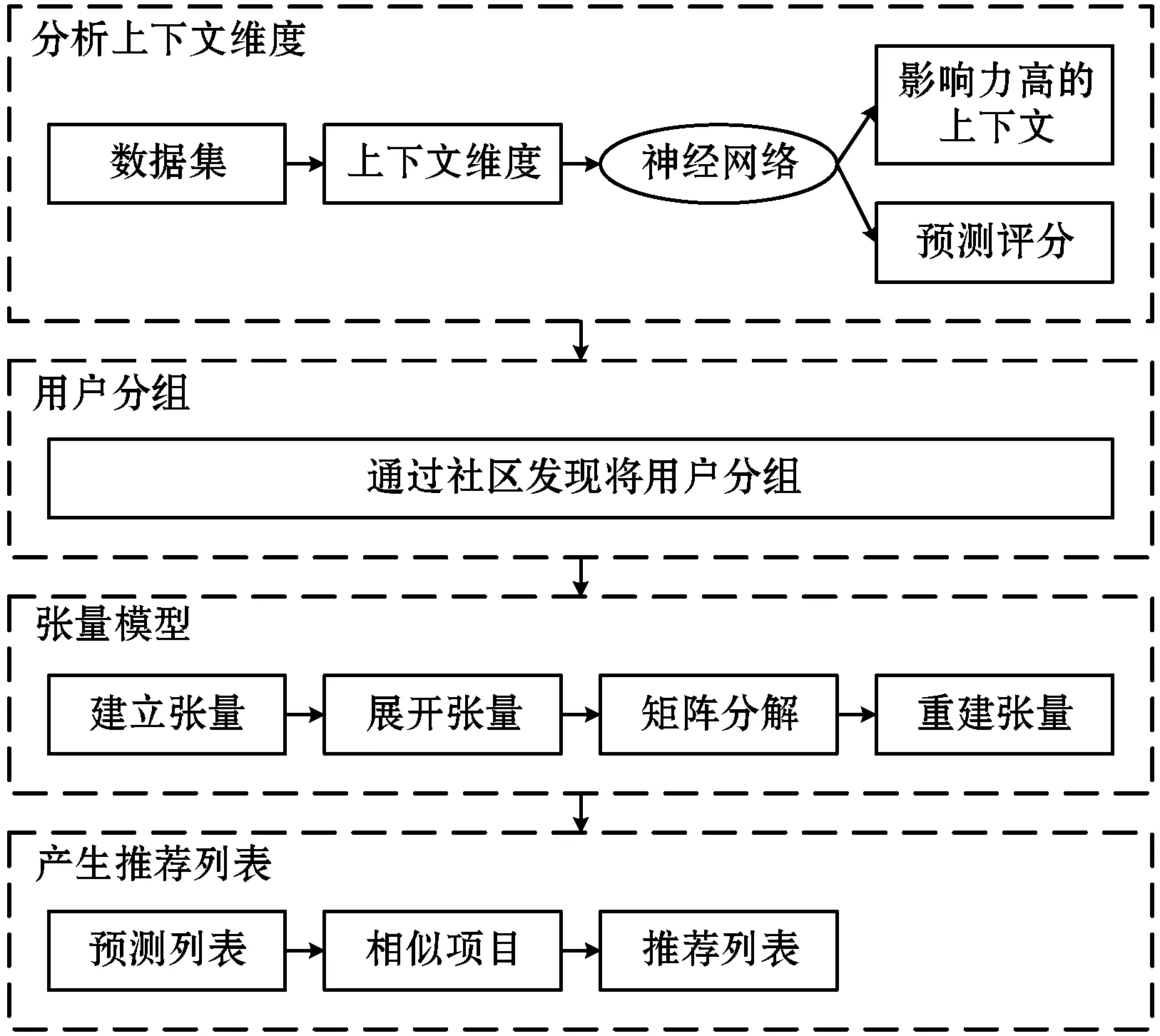
图1 推荐系统的总体结构
2 基于神经网络的上下文维度分析
通过多层感知神经网络[10]分析上下文维度,识别影响力大的上下文维度。
2.1 训练神经网络
多层感知神经网络分为输入层、隐层和输出层。以电影推荐数据集LDOS-CoMoDa[11]为例,设数据集为D,D共有12个上下文特征,12个上下文的维度为48,输入层节点的数量等于上下文的维度。假设上下文为c1=时间{早晨,下午,晚上,夜间},c2=日期{工作日,周末},c3=互动{第1次观看电影,第n次观看电影}。神经网络的输入和输出关系表示为:
OI=II
(1)
式中:OI为输入层的输出;II为输入层的输入。
输入层节点与隐层节点连接,隐层节点与输出层节点连接,连接的权重分别设为wij和wjk,通过训练神经网络确定wij和wjk。隐层节点是输入数据的加权调和函数,根据试错实验的结果将隐层节点数量设为11,此时验证实验的精度最高。隐层的神经元向量定义为:
h(j)=f(w(j)Th(j-1)+b(j))
(2)
式中:h(j)表示j层神经元的向量;w(j)为j层的权重矩阵;b(j)为偏差项;f为激活函数。
隐层节点计算输入量的加权调和值,计算方法为:
(3)
式中:IH为隐层节点的输入;wij为输入层到隐层连接的权重;OIi为输入层第i个节点的输出;bH为隐层的偏差;p为预测器的分级数;h为隐层的神经元数量。采用单隐层网络减少计算复杂度,如图2所示。

图2 上下文维度的单层神经网络
隐层节点支持在预测器和响应变量之间建模非线性关系,因为本文神经网络为前馈神经网络,所以采用双曲正切激活函数作为输入到输出的映射函数。双曲正切激活函数的输出为OH=φ(IH),φ(IH)定义为:
(4)
每个预测类别创建一个输出层神经元,如果用户满意度范围为1~5,那么输出层的神经元数量为5。输入层到输出层的映射函数定义为:
(5)
式中:IO为输出层的输入;wjk为隐层到输出层连接的权重;OHj为第j个隐层神经元的输出;bO为输出层的输入偏差;j为隐层的神经元数量;t为目标类别的数量。
Softmax函数能够预测多分类数据的输出,所以采用Softmax函数作为输出层的激活函数。神经网络的最终输出定义为:
(6)
通过最小化交叉熵误差获得Softmax激活函数期望的输出。计算每个目标类别观察值和实验值的交叉熵误差之和E:
(7)
式中:t为目标类别的数量(实例中为5);y为样本o是否被正确分类的标记值;p为观察样本的预测率。
然后通过反向传播训练神经网络,最小化预测误差。在反向传播阶段比较实际输出和期望输出,如果存在误差,则调节权重来获得接近期望的输出。使用梯度下降法计算最小化误差的权重,将误差对每个权重向量δwij求偏导δE:
Δwij=-l[δE/δwij]
(8)
式中:l为学习率。
学习率和动量是反向传播训练的两个重要参数。动量m设为0.9。采用衰减的学习率因子β,定义为:
β=(1/mK)×ln(η0/ηlow)
(9)
式中:η0为初始化学习率,设为0.4;ηlow为学习率的下限,设为0.001;K为训练样本的数量。
2.2 识别影响力大的上下文维度
例子中共有12个上下文特征,但每个维度的重要性不同,因此需要识别出对用户偏好影响力大的维度。在神经网络模型中则是选出对评分影响较大的预测器。算法1是评估上下文维度重要性的算法。
算法1上下文维度的重要性评估算法
输入:输入层-隐层连接权重wij,隐层-输出层连接权重wjk。
输出:上下文维度ci的相对重要性。
For each上下文维度cido
计算每个隐层神经元的wj=wij×wjk;
将wj除以j的输入神经元总数量;
//j为隐层神经元
对所有输入神经元的值求和Sum;
将Sum除以输入神经元的数量,其结果为上下文维度的相对重要性。
3 基于社区发现的用户分组
设计了基于社区发现的用户分组算法,以用户的社交关系、用户的人口统计信息(年龄、性别等)、地理位置等信息作为社区发现的判断依据。该模块能够利用用户组的相似性,解决稀疏性问题。目前的社区发现方法存在两个问题:(1) 采用随机参数导致稳定性较弱;(2) 需要预设社区数量。这两个问题导致这些方法无法适用于推荐系统,所以本文设计了基于子空间传播的社区发现算法,包括以下3个步骤:
步骤1使用线性稀疏编码将图映射到低维空间。
步骤2检测社区的代表中心。
步骤3通过标签传播机制构建最终的社区。
图3为用户分组的流程图。

图3 用户分组的流程图
3.1 子空间映射
根据子空间的自表达特性:子空间内的每个数据点可表示为其他点的线性组合[12]。借助该特性将邻接矩阵映射到低维空间,低维空间内社区结构的分离度高于原高维空间。首先计算两个节点的最短路径,然后采用高斯核将网络映射到全局的相似性空间,最终采用线性稀疏编码将相似性空间映射到低维空间。
首先为每个节点vi生成一个距离向量Gi。距离向量包括:用户的社交关系、用户的人口统计信息(年龄、性别等)、地理位置。该向量是从vi到其他所有节点的最短路径集合,所有向量的集合表示为G∈Rn×n,G=[G1,G2,…,Gn],n为节点数量。然后通过以下的高斯核函数将距离向量转化为相似性评分:
(10)
式中:σs为衰减率计算为(2×G)的平均总标准偏差;⊙为点积运算。社区内连接较为密集,社区间连接较为稀疏,因此同一个社区内节点的最短路径数量应该小于社区之间。每个节点vi的相似性为其他节点的线性组合:
(11)
式中:αi=[αi(1),αi(2),…,αi(n)]为相似性系数的向量,αi(j)为节点vi到vj的相似性系数;sj是节点vj相似性向量。vi到vj的相似性系数可能不同于vj到vi的相似性,即αi(j)≠αj(i)。
根据文献[12]一个类内的每个数据点可表示为同一个类内其他数据点的线性组合。因此采用l1-正则化的稀疏线性分解法计算最优相似性系数向量,其目标函数定义为:
(12)

(13)
式中:D为对称线性稀疏矩阵。
3.2 检测社区的代表中心
首先使用节点排序策略计算每个节点的全局影响值,然后根据影响值检测社区的代表中心。该策略的核心思想是社交网络中的社区一般围绕有影响力的节点。采用影响力和重要性度量节点在其子空间内的影响值,节点vi的影响值定义为:
(14)
式中:di为D的第i行。该式采用节点密度和距离向量计算节点的影响值。子空间的节点越多或者子空间内节点间相似性更高,该子空间组成社区的概率越大。
子空间内影响值最大的节点被选为社区中心的候选节点,节点vi的子空间定义为:
sSpace(vi)={vj|∀j=1,2,…,n,j≠i,D(i,j)>β}
(15)
式中:β定义了每个节点的影响范围。算法2为社区中心的检测算法。
算法2社区中心检测算法。
输入:β,D,S
输出:社区中心CC
计算节点重要性Pt;
//使用式(14)计算
CC=NULL;
for eachifrom 1 toN
计算子空间sSpace(vi);
//使用式(15)计算
for each 节点vjinsSpace(vi)
Tag=TRUE;
ifPt(vj)>Pt(vi) then
Tag=FALSE;
end if
end for
if(Tag==TRUE) then
CC=CC∪{vi};
end if
end for
3.3 标签传播
标签传播为每个节点分配社区,包括搜索微社区和构建最终的社区两个过程。
(1) 搜索微社区。微社区定义为成员间相似性最大的一组节点。初始化将每个社区中心作为一个微社区,然后将其子空间内能够增强其质量的节点加入该微社区。根据式(16)选择加入第i个微社区的节点:
CM(Ci)={vj|∀j=1,2,…,n,j≠i,JD(Ci,vj)>0}
(16)
式中:Ci为算法1初始化的第i个社区。设JD为局部关系和子空间关系的组合,用于度量节点和微社区的相似性,计算为:
JD(vi,vj)=D(vi,vj)×JS(vi,vj)
(17)
式中:JS为Jaccard相似性矩阵,D为式(13)的结果。JS度量了每对节点的局部密度:
(18)
式中:Γ(vi)为节点vi的相邻节点集。
采用以下的适应度函数计算节点vj加入社区Ci的质量增益:
ef(Ci,vj)=fCi∪vj-fCi
(19)
f定义为:
(20)

(21)

(22)
淘汰每个微社区的无效节点。该步骤计算每对节点的全局相似性,定义为Jaccard相似性和高斯相似性的乘积:
sim(vi,vj)=S(vi,vj)×JS(vi,vj)
(23)
算法3为建立微社区的程序。
算法3建立微社区的算法。
输入:D,S,JS,CC
输出:微社区集合MCS
JD=D⊙JS;
Foreachifrom 1 toCC
Ci={CC(i)};
CMi={vj|∀j=1,2,…,n,JD(Ci,vj)>0}
Nextmax:Max_Fit=0;
Foreachkfrom 1 to |CMi|
ef=fCi∪CMik-fCMik;
//式(17)计算相似性
ifef>max_fitthen
max_fit=ef;
candi_node=CMik;
end if
end for
end for
if max_fit>0 then
Ci=Ci∪candi_node;
CMi=CMicandi_node;
Goto Nextmax;
Endif
Nextmin:min_fit=0;
forkfrom 1 to |Ci|
ef=fCi-fCivk;
//式(23)计算相似性
if min_fit=ef;
min_fit=ef;
candi_node=vk;
end if
end for
if min_fit<0 then
Ci=Cicandi_node;
Goto Nextmin;
end if
end for
(2) 组建最终社区的结构。使用式(23)计算每个无标记节点的适应度,选择其中适应度最高的社区分配方案。通过一个简单实例解释用户分组的每个步骤,对LDOS-CoMoDa数据集进行了训练实验,神经网络的参数σs和β最优值分别为1.199 3和0.01。图3中:(a)是17个节点和3个社区的网络;(b)将网络映射到低维相似性空间,节点上的数值为式(23)计算的全局重要性;(c)是算法2选择的社区中心,分别为节点1、10、15。(d)是微社区候选节点;(e)是删除无效节点后的微社区;(f)是标签传播建立的最终社区结构,具体方法是使用式(23)计算每个无标记节点的适应度,选择其中适应度最高的社区分配方案。

(a) 3个社区的网络 (b) 网络映射到低维空间

(c) 社区的代表中心 (d) 搜索候选节点

(e) 构建微社区 (f) 标签传播建立社区图4 社区分簇的实例
4 基于簇的张量分解模型
4.1 奇异值分解
用户评分矩阵A的元素(i,j)表示为aij,元素(i,j,k)的三阶张量表示为Aijk。采用奇异值分解模型(Higher Order Singular Value Decomposition Model,HOSVD)处理用户-评分矩阵。首先建立3阶张量<用户,电影,上下文信息>,再根据张量建立新矩阵,对每个矩阵进行SVD,最终重建张量。
(1) 初始化张量。将不同的上下文维度建模为张量,三个模式的张量记为TM∈RIu×Im×Ci。张量TM的元素表示了在上下文环境下的兴趣,例如:一个28岁的女性用户在和孩子观看电影的情况下,评分为4。
(2) 展开张量。展开张量将张量转化为矩阵形式。例如:在“用户-电影-上下文”的维度,假设张量为TM∈RIu×Im×Ci,TM表示用户u在上下文i对电影m评分r。在“评分-好友”的维度,此时基于社交关系预测用户的评分。
(3) 应用SVD处理矩阵。应用SVD处理每个展开的矩阵,具体方法为:
TM1=U(1)·S1·V1TM2=U(2)·S2·V2,
TM3=U(3)·S3·V3
(24)
式中:U(1)、U(2)、U(3)为SVD的左矩阵。SVD计算张量SM的所有维度。
(4) 建立核心张量SM。核心张量SM能够发现用户和项目之间的多维度关系。其计算方法为:
(25)
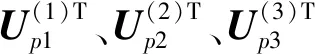
(26)
4.2 生成推荐列表
5 实 验
5.1 实验方法和环境
采用真实的电影评分数据集LDOS-CoMoDa。LDOS-CoMoDa数据集通过问卷调查形式统计了用户在不同上下文的情况下对电影的评分,该数据集包括了用户的人口统计学信息、用户观看电影的上下文信息以及用户间的好友关系。LDOS-CoMoDa数据集共有113位用户对于1 186部电影共2 094条评分记录,该数据集共有12种上下文因素,评分范围为1~5,稀疏度为1.6%,如表1所示。
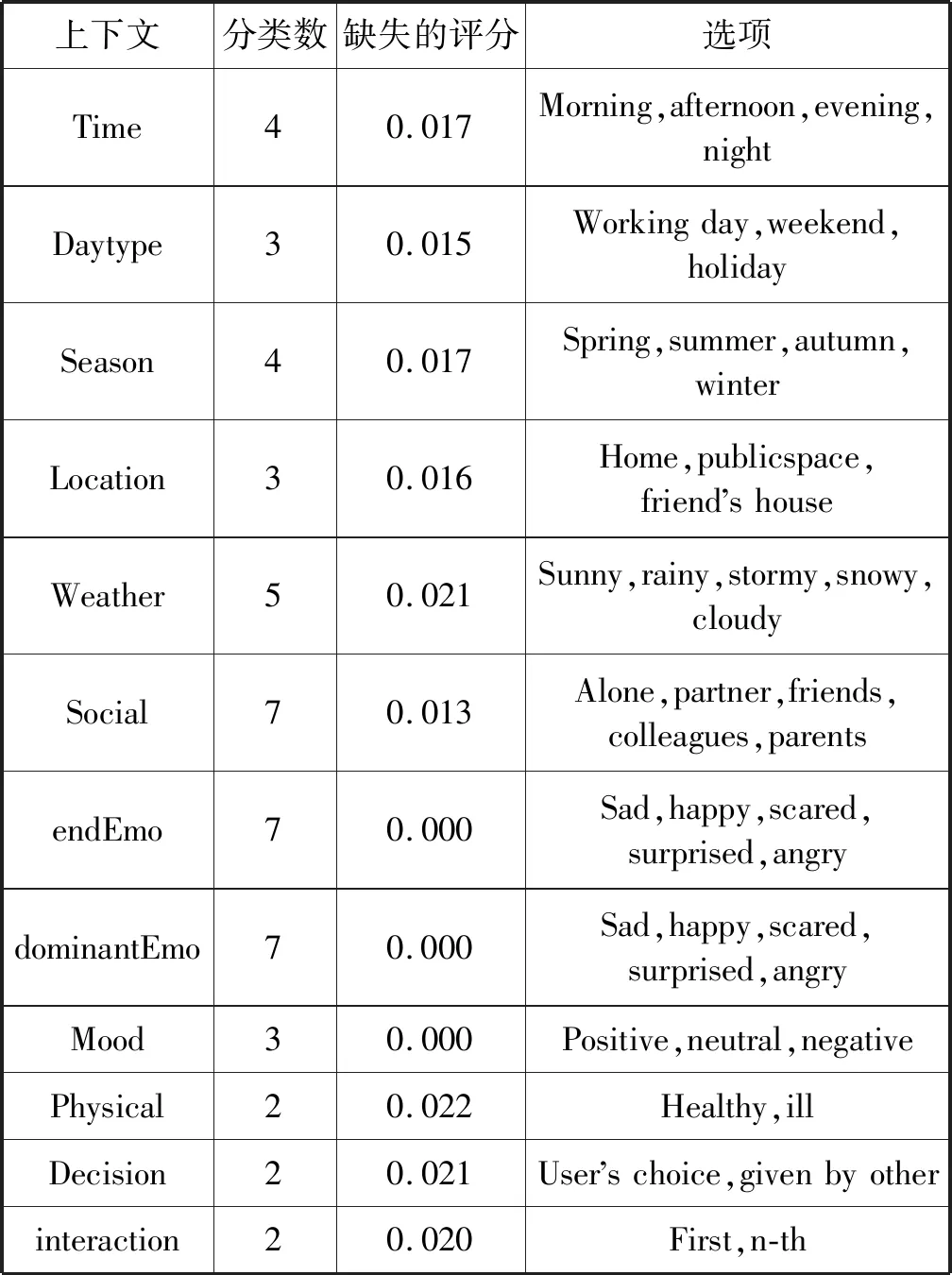
表1 员工基本信息
为了验证本文提出的方法的有效性,引入了4种不同类型的推荐算法:ESVD[13]、HRMARM[14]、PCAP[15]和HACAR[16],并比较它们的推荐效果。ESVD是一种基于增强奇异值分解的推荐算法,因为本文算法采用了张量分解技术,所以选择该算法作为对比方法。HRMARM是一种基于关联规则挖掘和社交关系的推荐算法,本算法也考虑了社交关系和社区划分处理,所以选择该算法作为对比方法。PCAP和HACAR均通过分析用户上下文信息增强推荐系统的性能,这两个算法未考虑上下文维度的影响力,而本文算法考虑了上下文维度的影响力,所以选择这两个算法作为对比方法。
基于MATLAB 2017b实现本算法。采用5折交叉检验方法进行推荐实验,将每组实验结果的平均值统计为最终的性能结果。
采用平均绝对误差MAE、均方根误差RMSE和精度评估推荐系统的推荐性能。
(27)
(28)
式中:pu,i为用户u对电影i的预测评分;ru,i为用户u对电影i的实际评分;N为数据集内的评分总数量。MAE值越低表示推荐的准确率越高。
精度Pr定义为:
(29)
5.2 上下文影响力实验
本文的核心思想是利用多层感知神经网络选出影响力大的上下文维度,以期提高推荐系统的性能。采用文献[17]的连接权重方法测试预测器的重要性,该方法计算输入层-隐层和隐层-输出层的预测器重要性之和,将结果作为上下文维度的相对重要性。图5是神经网络所计算的不同上下文维度的影响力结果,图中结果显示endEmo和dominantEmo是两个影响力较大的上下文维度,Decision和interaction的影响力较低。
5.3 推荐系统的总体性能
将本文算法与4个对比方案进行比较,图6、图7分别为5个推荐算法对于LDOS-CoMoDa数据集的平均MAE结果和RMSE结果。可以看出,PCAP、HACAR和本文算法均明显优于ESVD和HRMARM算法,所以考虑推荐系统的上下文环境对于LDOS-CoMoDa数据集的推荐性能较好。PCAP和HACAR算法的性能极为接近,而本文算法的性能略优于PCAP和HACAR算法,所以本文算法通过多层感知神经网络为分析上下文维度的重要性,有效地提高了推荐的准确率。

图6 推荐系统对于LDOS-CoMoDa数据集的MAE结果
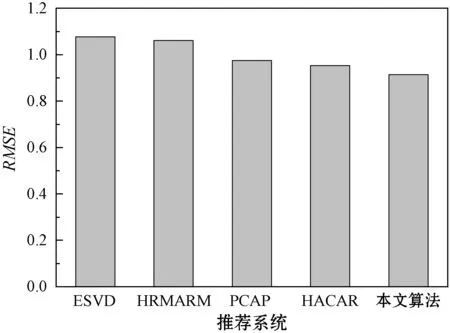
图7 推荐系统对于LDOS-CoMoDa数据集的RMSE结果
5.4 上下文维度对推荐精度的影响
根据图5可看出上下文维度endEmo、dominantEmo和season是影响力最大的维度。实现多层感知神经网络来分析显著预测器,最大化用户在不同上下文情况下评分的方差。图8是12个上下文维度的神经网络预测精度结果,结果表明endEmo、dominantEmo和season的预测精度明显高于其他的上下文维度。此外,5.2节中social维度的影响力较为普通,但其预测精度高于平均值,其原因是本算法的用户分组策略中考虑了社交关系和人口统计学信息,使得社交关系对推荐的精度产生了有利的影响。
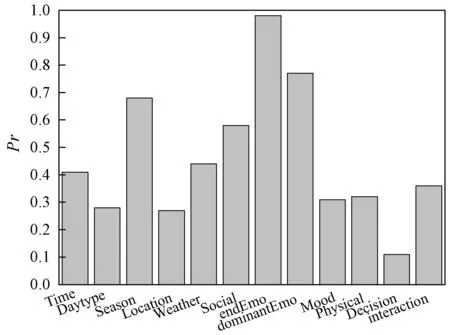
图8 上下文维度的神经网络预测精度结果
5.5 不相关上下文维度对推荐性能的影响
图8表明endEmo、dominantEmo、season和social上下文维度对预测精度的贡献较为突出,说明推荐系统引入不相关的上下文维度则会导致推荐性能降低。将不相关上下文维度建立为张量,然后为用户产生推荐列表,图9为引入不相关上下文维度后的推荐系统MSE值。可以看出,引入不相关维度导致总体的推荐性能大约衰减了15%,因此本系统通过对上下文维度的筛选有效地排除了不相关维度带来的负面影响。

图9 引入不相关上下文维度后的推荐系统MSE值
6 结 语
本文推荐系统通过神经网络识别影响力大的上下文维度,基于社交关系、地理位置、人口统计学将用户分组,基于用户分组的张量分解模型处理上下文维度数据,最终产生推荐列表。基于LDOS-CoMoDa数据集的实验结果表明,本系统通过上下文维度的分析有效地提高了推荐的性能。
本文基于LDOS-CoMoDa数据集进行了实验验证,但该数据集仅有2 094条记录,数据规模较小。目前研究领域中没有符合上下文维度要求的大规模数据集,未来将考虑构建大规模的相关数据集,测试本算法处理大数据的效果。
