基于自适应引力搜索的支持向量机在公安巡防警情分类中的应用研究
2020-07-13王云李丛
王 云 李 丛
(南京理工大学泰州科技学院 江苏 泰州 225300)
0 引 言
众多分类算法中,万普尼克(Vapnik)提出的支持向量机算法SVM运用尤为广泛。该算法是一种广义的线性分离器,对于特定的学习样本,无差错地进行识别或者寻找出最优的超平面[1]。SVM在图像识别、文本分类、人脸识别、入侵检测等领域都有非常广泛的应用。
本文首先在传统GSA算法基础上,提出自适应引力搜索算法,将改进的算法用于对支持向量机的核函数和惩罚系数进行调优,搜索最优的C和σ的参数组合。最后,基于本文提出的改进方法实现了公安警情信息的高效自动分类。
1 GSA改进
1.1 相关公式
1) 惯性质量Mi(t)的计算公式为[2]:
(1)
式中:fiti(t)表示粒子在时刻t的适应度值(该值决定粒子惯性质量),best(t)代表t时刻最优适应度值,worst(t)代表最差适应度值。
2) 粒子i的引力计算公式为[3]:
(2)
式中:ε为一个非常小的常量,G(t)为万有引力常量,Rij(t)表示两个粒子之间的欧式距离。
3) 万有引力常数G(t)的一般计算公式为[4]:
G(t)=G0×e-αt/T
(3)
式中:G0为初始值,t为当前迭代次数,T为总迭代次数。
4) 更新后万有引力常数G(t)的计算公式为[5]:
(4)
式中:G0为G(t)的初始值,alfa表示速度衰减常数,max_it表示最大迭代次数,t为当前迭代次数。
1.2 改进思想
由式(2)知,引力常数G是影响算法性能的一个参数,G的大小直接影响算法中粒子受到的合力和加速度的大小,从而决定着算法运算时粒子每次移动“步长”的大小,是影响粒子能否摆脱局部最优、实现最优精细度最直接的因素[6]。由式(3),G从刚开始就迅速下降,即在算法搜索初期就加大了开发力度,缺少前期的有效探索过程,容易使算法陷入局部最优。显然,这种情况容易打破算法探索和开发的平衡。
针对上述不足,本文提出了使用引力常数G的自适应策略来改进GSA算法。设计引力常量的自适应变化公式如下:
(5)
式中:n为描述勘探和开发比例的一个参数,当n=1时,式(5)将转化成式(4)。引入自适应引力常量,改进引力常量的计算公式,通过改变算法比例系数n来调整算法的探索与开发能力,自适应调整算法的寻优步长,使算法在初期加大搜索力度,后期加大开发力度。
1.3 性能评估
算法仿真结果如图1所示。图中曲线1为改进前引力常数随迭代次数t的变化情况,可见引力常量G从刚开始就迅速下降,易陷入局部最优;而曲线2则为本文改进后引力常数随迭代次数t的变化情况,可见提出的引力常量自适应变化公式可由n来调节算法的探索与开发能力,n值越大,算法初期的搜索力度越大。

图1 引力常量与迭代次数t的关系
2 基于自适应GSA的SVM参数优化
SVM分类器性能主要取决于惩罚因子和核函数参数,而传统参数选取方法则多采用反复试凑的手工选取方法,效率低下且易获得局部最优解[7]。针对上述问题,对两个决定因素进行优化,寻找最优的参数组合显得尤为重要,下文给出基于本文提出的自适应GSA优化SVM参数的核心技术。
2.1 粒子编码方式
编码方式采用二进制字符串和SVM参数进行组合编码。假设一个粒子可以用一条长度为3的染色体来表示,其中长度为3表示一条染色体携带3个信息,分别是:进行二进制编码的字符串、惩罚系数C和核参数σ。解码后对应的十进制值的计算表达式如下所示:
(6)
2.2 适应度函数设计
选取一个优秀合理的适应度函数可以让实验的结果更加准确并且具有说服力。现采用均方差(MSE)作为支持向量机的适应度函数[8]。MSE具体公式如下:
(7)
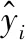
2.3 SVM参数优化流程
利用本文提出的自适应的GSA较强的全局搜索能力,采用自适应步长去替换原来的固定步长,不断优化调整SVM参数,具体算法流程图如图2所示。
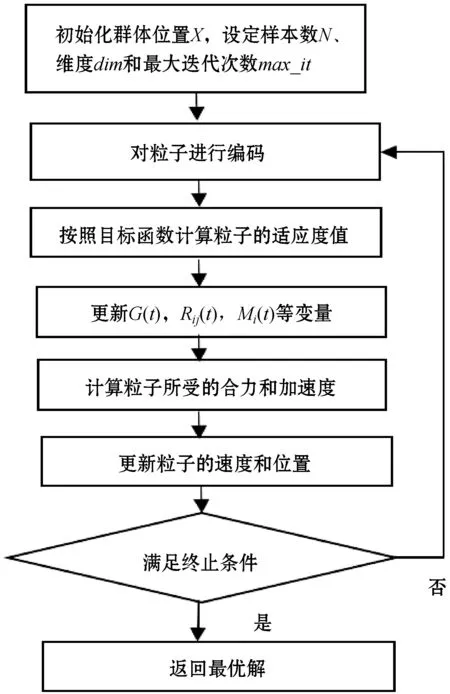
图2 基于自适应GSA的SVM算法流程图
Step1随机初始化群体位置X,设定样本数N、维度dim和最大迭代次数max_it。
Step2对粒子进行编码。
Step3计算MSE作为粒子的适应度值。
Step4利用式(5)计算G(t),并更新Rij(t)、Mi(t)等变量。
Step5计算合力、加速度。
Step6通过改进的自适应策略和引力计算方法计算并更新粒子的位置及速度,完成一次迭代过程。
Step7判断有无满足终止条件,若满足则输出算法最优解;不满足需重复算法Step 2-Step 6。
3 基于自适应GSA-SVM的公安巡防警情自动分类识别
3.1 系统功能
智能巡防系统分为基于Android的移动端和基于.Net的后台管理端,移动端具备实时勤务、盘查录入、接处警、勤务查询、在线学习、警情自动分类等功能;后台具有对信息的管理功能,主要包括删改查等数据操作。其中警情自动分类系统是泰州市海陵区公安巡防智能系统的子系统,其分类需求主要包括交通事故类别、反恐类别、刑事类别等。该子系统可以实现将采集的情报文本自动归类到已设定的类别中,便于案情研判者选择其感兴趣的类别,并与同类别或不同类别信息进行对比分析。
3.2 开发环境
本系统基于Windows 10操作系统,使用Java编程语言编制智能巡防分类模块核心代码,并将其打包成一个功能jar包,供外部应用调用。
3.3 多分类器构建
公安巡防信息中,警情类别有多种,针对二分类问题的SVM算法则显得无能为力。本文采用间接法构造多个分类器,从而克服传统SVM算法分类的不足,根据需要,共需n(n-1)/2个SVM,而其中每个SVM均采用二分类训练集进行训练[9]。例如,以下给出在a和b两个类中寻找最优的超平面训练集:
(8)
(9)
(10)
在建立n(n-1)/2个SVM模型基础上,对检测样本进行判断分类。经过筛选淘汰之后,最终输出的类别就是测试样本类别。
3.4 警情文本分类模块设计
警情自动分类模块由训练样本和分类两部分组成。对于已知类别的训练样本,采用分类算法计算分类模型;对于测试样本,使用上步计算结果的分类模型判断待分类样本点所属类别,后对分类器的性能进行评价。警情文本分类模块设计如图3所示。
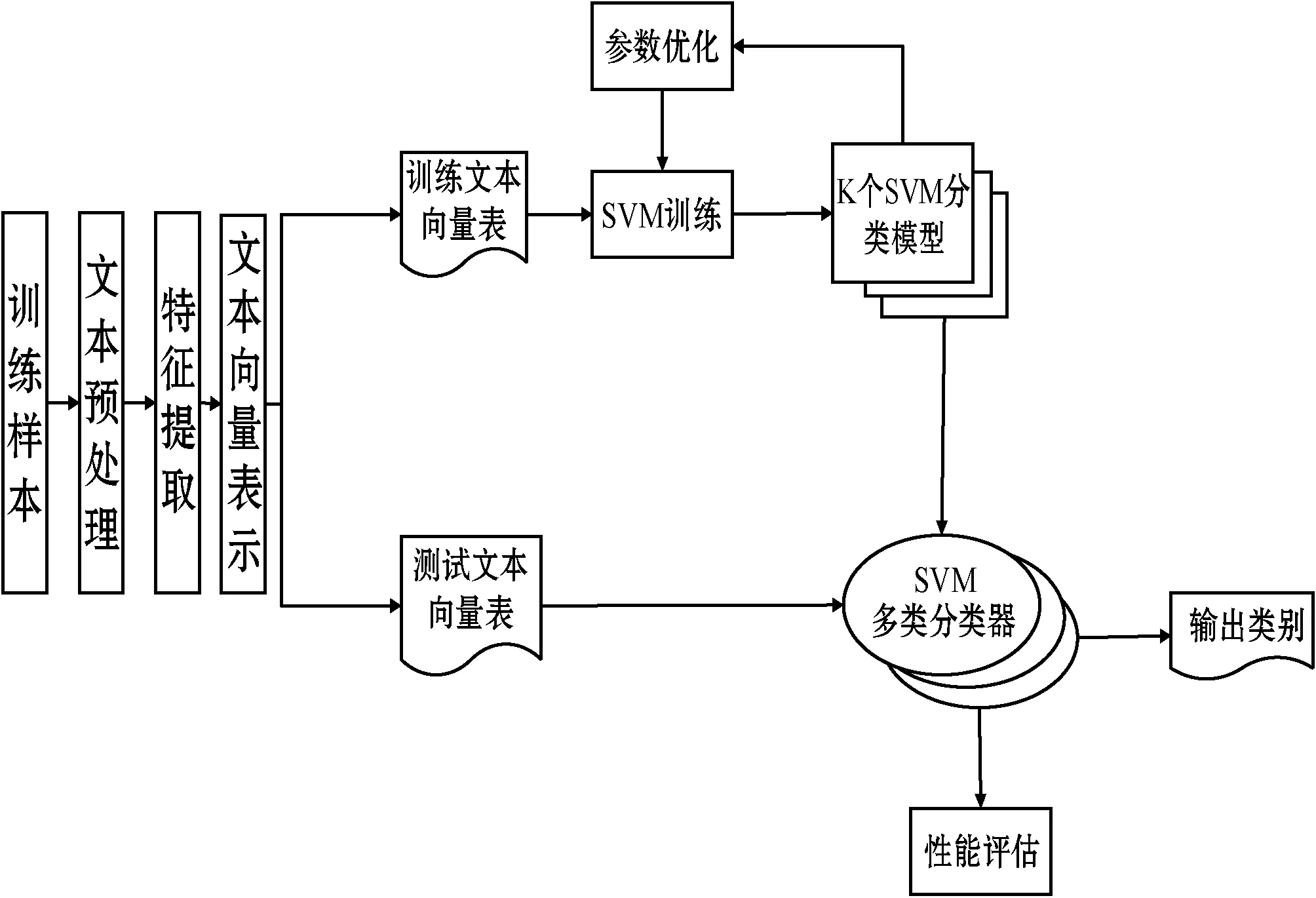
图3 警情文本分类模型设计图
3.5 警情分类识别的步骤
本文所实施的警情分类识别步骤如下:
Step1收集原始的文本数据。
Step2对数据进行预处理,使得处理后的结果可以作为自动分类子系统的输入,减少样本训练使用的时间,加快收敛速度,从而加强对警情的判别能力。
Step3把预处理的数据交由SVM作为输入,通过自适应GSA-SVM算法优化得到最优参数。
Step4使用Step 3结果进行样本训练时,针对不同数量的警情类别样本数,须采用不同的方法训练样本(样本数较多时,采用边界样本方法,否则采用虚拟样本),最后进行组合构造,最终建立最优警情判别模型。
Step5基于Step 4建立的警情判断模型,加入测试样本集合进行检测。
Step6输出加入的测试样本的警情判断结果。
4 实验评估
为了验证算法改进的效果及公安巡防自动分类系统设计的合理性,本文测试选取警情中的多个类别,多组数据综合进行验证。
4.1 测试数据与评估标准
1) 测试数据。文本分类中的语料库指用于测试和训练学习机器的文本集合,语料库选择是否合适,将直接影响文本分类器的性能。语料库应广泛代表分类系统所需处理的实际存在的各类别文本。本文测试中,语料库来源于泰州市海陵区公安情报文本集,训练文本共计1 521条,测试文本共计612个。测试分为10组进行,为了前后测试的连贯性,每组测试中训练文本集始终保持不变。测试用数据分布要求如表1所示。
表1 测试用的数据分布表
2) 性能评估标准。采用目前普遍使用的准确率和查全率以及两者的综合评价指标F1测试值作为分类器性能的评价指标[10]。
4.2 实验结果与分析
1) SVM参数优化方法的有效性测试。首先,确定自适应引力搜索算法的初始参数,如:样本数为1 200,维数为800,最大迭代次数为30。然后在编码范围里随机寻找多个点作为粒子群的初始位置,按照适应度函数来搜索全局最优点。详细的实验结果如表2所示。
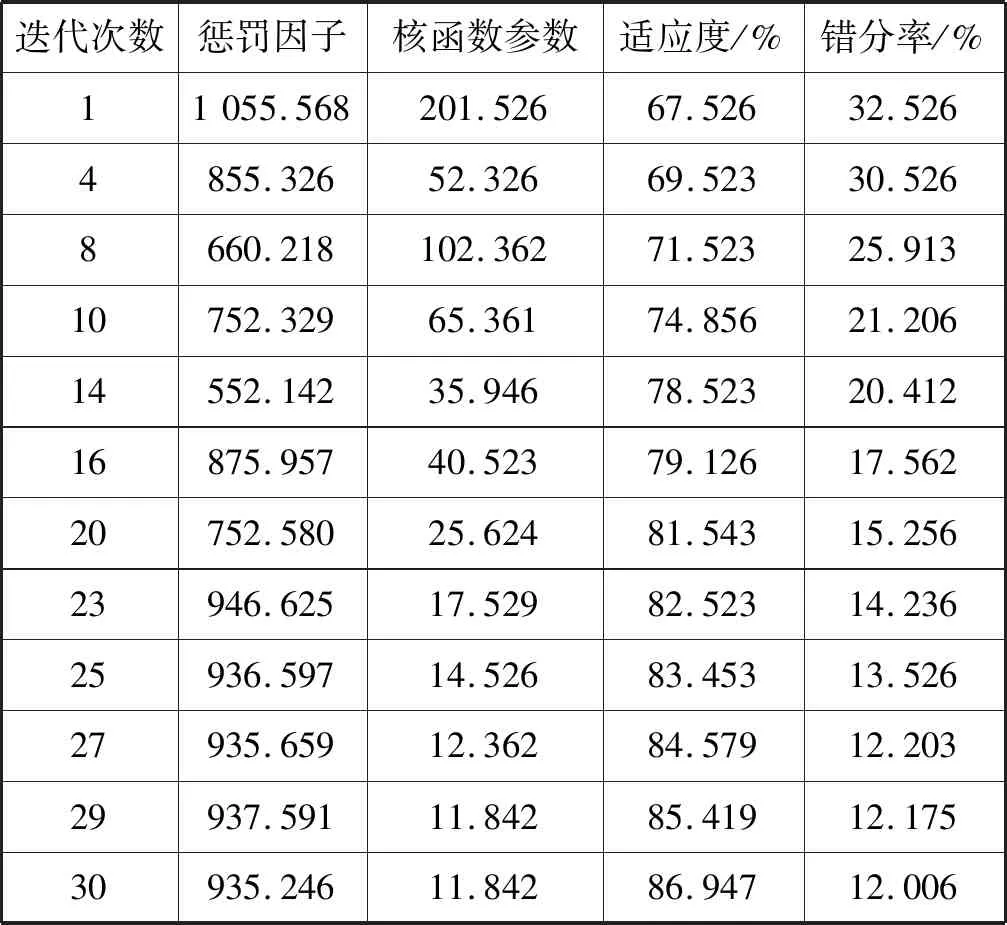
表2 SVM参数优化结果
表2列出了在SVM参数的优化过程中,随着迭代次数的增加,得到了(C,σ2)的最优解(935.246,11.842)。通过查看表中数据,可以发现随着迭代次数的增加,错分率在下降的同时,适应度有所提高。
2) 分类性能比较。为了便于比较,现分别采用GSA和本文改进的自适应GSA算法对SVM进行训练,最大迭代次数设为2 000,粒子数为40,G0设为50。采用泰州市海陵区公安巡防智能系统情报文本集中的100个警情文本数据作为测试集,两种方法比较结果如表3所示。

表3 性能比较
结果表明,基于自适应的GSA优化SVM参数产生了较高的精度和较强的泛化能力。
两种方法对公安巡防警情信息的分类效果比较如图4所示。
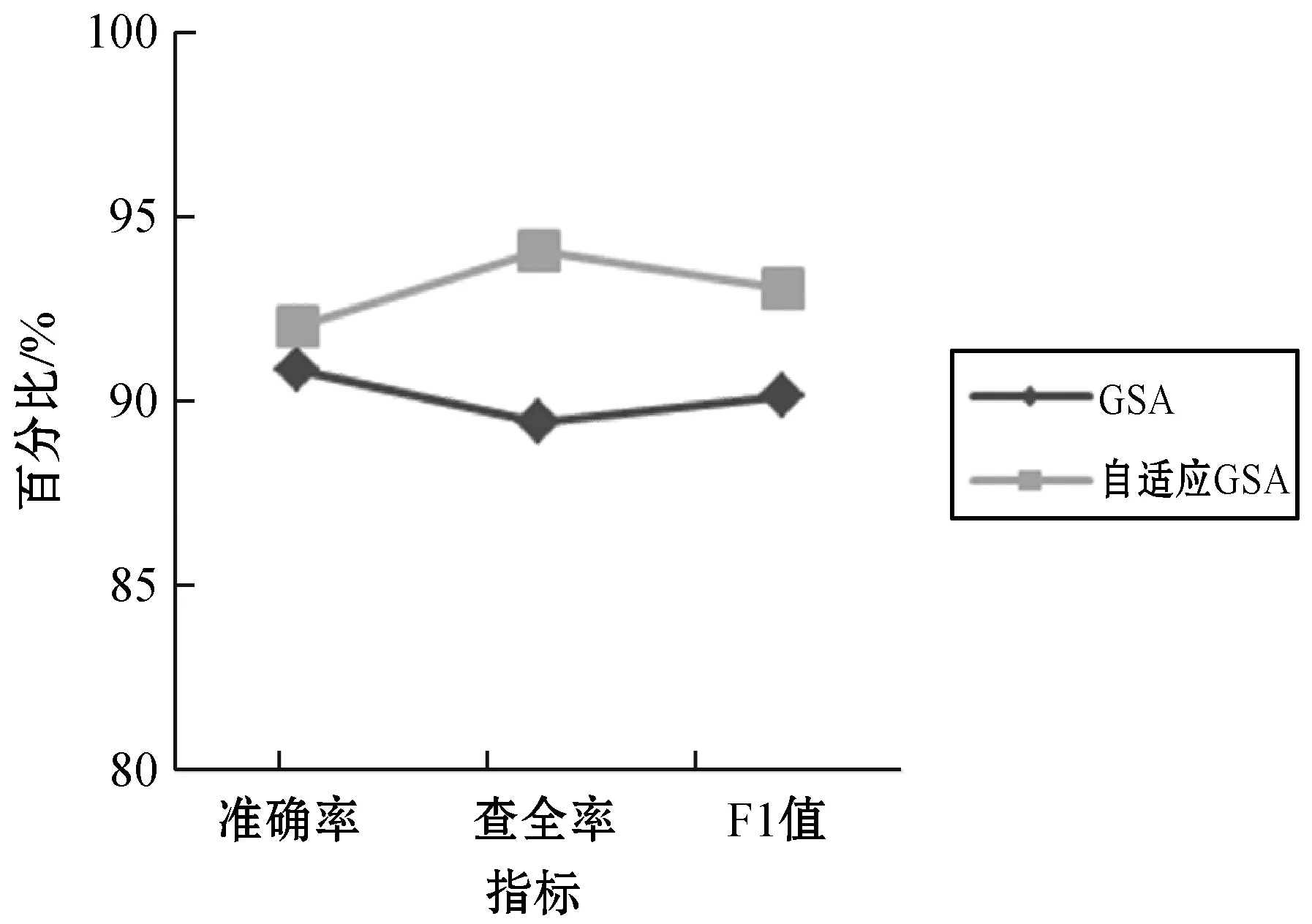
图4 两种方法比较SVM分类的效果
可以看出,本文所用的SVM参数优化方法无论是在准确率、查全率及综合评价指标F1方面,都优于传统GSA算法,采用基于自适应GSA的SVM方法可以得到更优的SVM参数。
5 结 语
本文在传统GSA的基础上,提出一种自适应的引力搜索算法。该算法避免了传统GSA易于得到局部最优解的缺点,用改进的GSA优化SVM参数,参数优化结果的精度有所提高。将研究的方法应用于实际的公安巡防警情自动分类中,实验结果表明,本文提出的改进方法是合理、有效的。
