基于体检数据的糖尿病风险预测模型对比研究
2020-07-09马文彬王克于滨冯超南纪俊
马文彬 王克 于滨 冯超南 纪俊

摘 要:随着中国糖尿病患者人数及病死率不断上升,对空腹血糖的有效检测及合理预测是目前的研究重点。采用数据挖掘的方法,根据体检数据建立空腹血糖变化预测模型。基于前三年的医学检查数据预测第四年空腹血糖的变化,从医学检查数据库中收集实验数据。在特征选择阶段,使用主成分分析选择最佳特征子集,结合5种机器学习算法建立模型并预测患病风险。实验结果表明随机森林算法模型对糖尿病风险预测效果最佳。
关键词:空腹血糖;机器学习;PCA;体检数据;糖尿病预测
中图分类号:TP311.13;R587.1 文献标识码:A 文章编号:2096-4706(2020)23-0072-04
Comparative Study of Diabetes Risk Prediction Models Based on Physical Examination Data
MA Wenbin1,WANG Ke2,YU Bin3,FENG Chaonan3,JI Jun1,3
(1.Qingdao University,Qingdao 266071,China;2.East Hospital of Qingdao Municipal Hospital,Qingdao 266071,China;
3.Beijing Wanlingpangu Technology Co.,Ltd.,Beijing 100089,China)
Abstract:With the increasing number of diabetes patients and mortality in China,the effective detection and reasonable prediction of fasting blood glucose is the focus of current research. Using the method of data mining,the prediction model of fasting blood glucose change was established according to the physical examination data. Based on the medical examination data of the previous three years to predict the change of fasting blood glucose in the fourth year,the experimental data is collected from the medical examination database. In the feature selection stage,principal component analysis is used to select the best feature subset,combined with five machine learning algorithms to build a model and predict the risk of disease. The experimental results show that the random forest algorithm model is the best for diabetes risk prediction.
Keywords:fasting blood glucose;machine learning;PCA;physical examination data;diabetes prediction
0 引 言
糖尿病是一种日渐流行的疾病,严重时会引发许多并发症,但早期糖尿病患者没有任何症状或者症状较轻,所以早期糖尿病并不容易被发现[1]。如果在糖尿病早期对患者进行适当的护理,改变其生活方式并辅助药物治疗,能够使糖尿病并发症的风险降低30%~60%[2]。空腹血糖(Fasting Blood Glucose,FBG)是糖尿病诊断的重要指标,对于FBG的研究可以帮助患者在糖尿病发病早期发现风险从而得到尽早治疗,通过对近些年国内外研究发现,糖尿病预测模型大多采用同年体检数据,预测效果不可靠且不具有提前预测性。本文以青岛大学国家自然科学基金项目“基于健康数据分析的半监督在线学习血糖预测建模算法研究”和青岛大学山东省自然科学基金“基于健康数据分析的半监督在线学习血糖预测建模算法研究”為支撑,将数据挖掘、机器学习技术应用于体检数据中,构建预测模型并预测患病风险。
1 研究现状
近些年来,利用机器学习算法对糖尿病的研究日益增多。Kavakiotis等人[3]使用传统机器学习算法对糖尿病进行建模预测,Polat和Güne?[4]通过主成分分析和神经模糊推理来区分体检者是否患有糖尿病。Han等人[5]提出利用支持向量机对糖尿病进行筛查,并添加了集成学习模块。Tresp等人[6]采用神经网络对血糖值进行预测,分别从递归神经网络和时间序列卷积神经网络两方面研究了神经网络在糖尿病患者血糖代谢建模中的应用。Georga等人[7]采用支持向量回归算法对1型糖尿病患者皮下葡萄糖浓度进行预测。余丽玲等人[8]将支持向量机和自回归积分滑动平均进行组合,较好地反映血糖的波动趋势。
随着科技的不断发展,我们获取的数据更加全面。Gani等人[9]提出将数据驱动的预测模型与频繁的葡萄糖测量相结合,为糖尿病患者提供了更好检测血糖值的方法。Pradhan等人[10]采用遗传编程对UCI资料库的糖尿病数据集进行训练和测试,使用遗传编程所取得的结果与其他实施技术相比具有最佳的准确性。
有些学者使用了新的预测方法,魏芬芬[11]使用灰色预测模型对血糖进行预测,结果在患者餐后血糖方面的预测效果尤其突出,但过程比较复杂。丰罗菊等人[12]以311名糖尿病患者为例,采用有序回归和受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC)等方法,对糖尿病肾病患者的空腹血糖值进行了预测值筛选。
目前已有的研究多数存在研究算法单一、样品量较小等不足,本研究采用海量高维体检数据,采用多种算法对体检血糖数据进行建模,对比各算法结果从而选择最优模型,能够更加准确地对糖尿病做出风险预测。
2 算法简述
本研究使用决策树、随机森林、支持向量机、逻辑回归、朴素贝叶斯算法对体检血糖数据进行建模,通过对比各算法结果选择最优模型。
决策树(Decision Tree,DT)是一种常见的机器学习算法,它采用“树状结构”进行决策[13]。决策树中主要包括根节点、叶子节点和内部节点。决策树中的每个节点代表其中一个对象,节点的不同路径为不同的结果选择。决策树学习的目的是产生一棵具有较强泛化能力的决策树[14]。
随机森林(Random Forest,RF)是一种用于分类、回归等任务的集合学习方法,其操作方法是在训练时构建众多决策树,并输出各个树类的模式(分类)或平均预测(回归)的类[15]。通过Bootstrap抽样方法从原始训练样本集N中有放回地随机抽取k个样本生成相互之间有差异的新的训练子集,再根据k个训练子集建立k棵决策树,对于响应变量为分类变量的数据,应结合多棵树的分类结果对每个记录以投票的方式决定其最终的分类[16]。
支持向量机(Support Vector Machine,SVM)是一种监督学习模型,用于分类和回归分析[17]。给定一组训练实例,每个实例被标记为两类中的一类,SVM算法通过建立模型将新的实例分类,使其成为一个非概率的二元线性分类器。除执行线性分类外,SVM还能使用内核技巧高效地执行非线性分类,将其输入映射到高维特征空间中[18]。
逻辑回归(Logistics Regression,LR)是一种广义的线性回归模型,常用于数据挖掘、经济预测等领域,尤其多应用于二分类问题。对逻辑回归来说,自变量既可以是分类数据,也可以是连续数据;而逻辑回归的响应变量,则对应着分类变量。逻辑回归算法中用到的Sigmoid函数以及阶跃函数使得它能够比较容易地扩展到多类问题来使用[19]。
朴素贝叶斯算法(Naive Bayes,NB)使用贝叶斯定理中的概率推理方法,通过计算样本在不同类别的概率来对样品进行分类,同时,朴素贝叶斯模型建立在属性之间相互独立性的基础上,各个类别之间不存在任何依赖关系。朴素贝叶斯算法对于样本数量小的数据表现较优,能够处理多分类任务,比较适合增量式训练。
3 数据及处理过程
3.1 数据来源
本研究中的数据来自北京华兆益生健康体检,包含108 386名用户。为了保持数据的完整性和规范性,选取了2011年1月至2014年12月的体检记录。
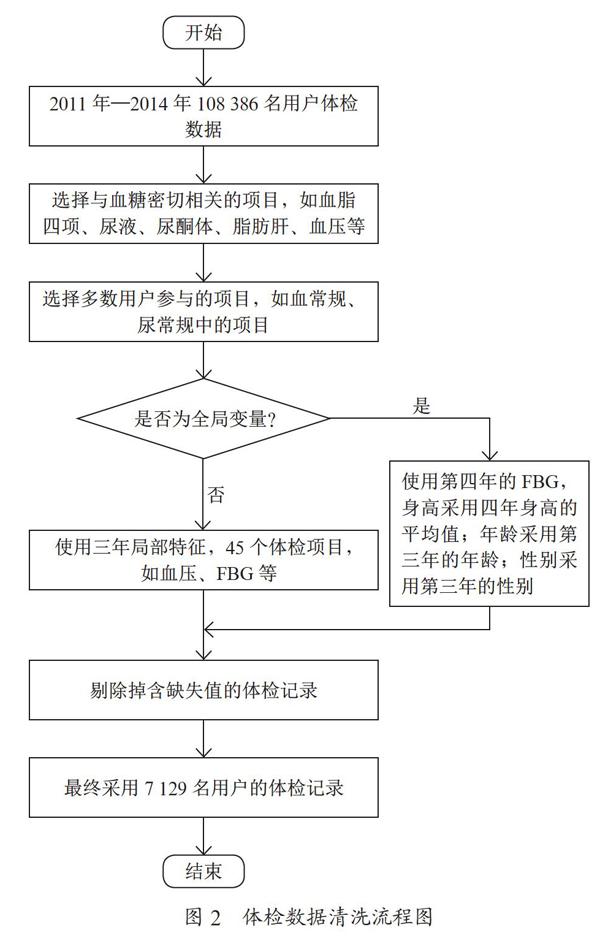
本研究整个过程包含数据清洗、特征提取、建立模型和预测四部分,流程图如图1所示。
3.2 数据清洗
数据清洗过程分为有效数据选择、体检项目选择、建立特征、清洗结果四部分。
3.2.1 有效数据选择
某些记录中的ID与体检项目无法匹配,为保证数据的准确性,这些记录被删除。对于含有缺失值的记录,为保证数据质量,这类记录也被删除。某些特征表达方式不规范,如用“+”、“++”表示,用文字或非标准符号表示。为解决上述情况,将特殊符号用数字代替;将相似术语用相同值代替;将特征中非标准术语和符号删除。
3.2.2 体检项目选择
体检信息包括用户基本信息(如年龄、性别等)和体检项目。体检项目不包含敏感身份信息,选择标准为:一方面,选择与血糖密切相关的项目,如血脂四项、尿液、尿酮体、脂肪肝、血压等;另一方面,选择用户参与较多的项目,如血常规、尿常规中的项目。
3.2.3 建立特征
特征分为两类:一类是全局特征,几乎不随时间变化或只有一年的项目有意义,如身高、年龄;另一类是局部特征,其体检结果可能随年份变化,如体重、FBG、血压等。全局特征在数据集中唯一存在,局部特征在每一年都存在。
3.2.4 清洗结果
数据库中共有108 386名用户,体檢记录9 073 312条,记录时间为2011年1月至2014年12月。经数据清洗,最终采用7 129名用户记录。数据集有139个特征,包括三年的局部特征,45个体检项目。每年项目主要有血常规、尿常规、血生化、内科、心电图等。数据集还包括第四年的FBG、身高、年龄、性别四个全局特征。第四年的FBG作为因变量,身高采用四年身高的平均值;年龄采用第三年的年龄;性别采用第三年的性别。
体检数据的清洗过程如图2所示。
3.3 特征提取
体检数据中包含多项体检项,但也有一些体检项与空腹血糖的预测无关。本研究采用PCA来进行主成分分析,从而达到降维的目的。
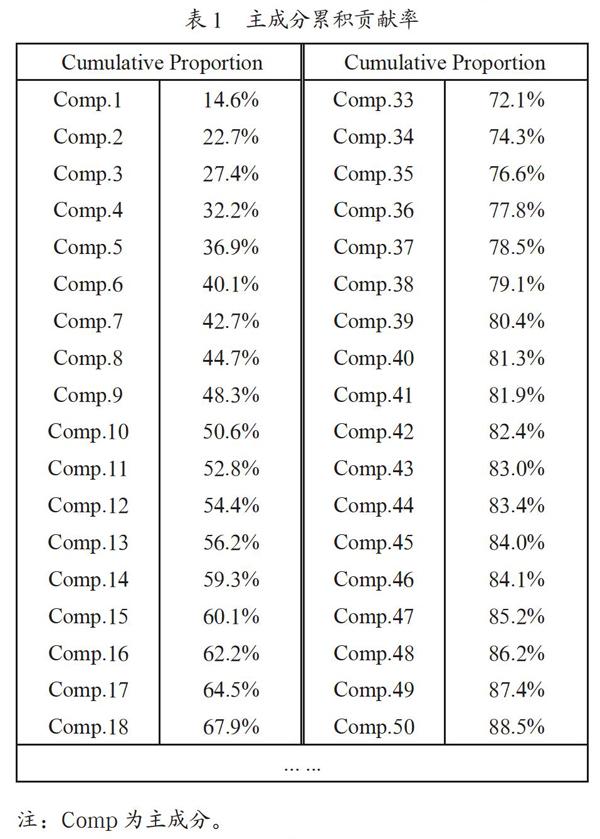
主成分分析是一种常用的统计方法,可以处理大量过程参数间的关系与变化,排除次要因素,提取主要因素。数据采用7 129名用户的体检记录,保留前三年每年45项体检项以及第四年年龄、身高、性别(其中,男性用0表示,女性用1表示)共138项体检量作为自变量,记为X1,X2,…,X138,第四年的FBG作为因变量Y。为避免不同医学指标单位带来的偏差,对自变量进行标准化,然后对训练集中自变量进行主成分分析,分析结果如表1所示。
由表1可知,降维后的指标中前47个新指标的累积贡献率超过85%,也就是说前47个新指标能够解释85%的原指标,因此我们使用前47个新指标作为自变量进行后续分析。
3.4 建模及预测
本研究提出依据前三年体检数据,预测第四年用户是否患有糖尿病的模型,模型建立过程为:
(1)建立包含四年体检数据的数据集,将第四年空腹血糖体检值转换为0~1表示,具体规则为空腹血糖小于7 mmol/L的数据[20]设置为0,大于等于7 mmol/L的数据设置为1。
(2)将特征转化为特征选择中选出来的47个新指标。
(3)将数据集分为训练集和测试集两部分,比例为2:1,训练集包含4 754人,测试集包含2 375人。使用训练集和五种算法(随机森林、朴素贝叶斯、决策树、逻辑回归、支持向量机)生成血糖预测模型。
(4)将测试集输入步骤(3)所得的模型中,得到第四年的预测值,用ROC曲线下方的面积大小(Area Under Curve,AUC)评价模型预测的性能,使用敏感度、特异度评价模型预测的准确性。
4 模型对比结果
为了比较不同算法的性能,分别计算不同模型的敏感度、特异度和AUC值,结果如图3、图4所示。
从图3中可知,逻辑回归和随机森林对于血糖数据的分类都有较高的敏感度和特异度,其中,逻辑回归算法的敏感度和特异度分别为88.51%和92.10%,随机森林算法的敏感度和特异度分别为86.49%和85.05%,两者敏感度差异不大。但从图4的实验结果来看,随机森林对于血糖数据的分类AUC值达到了0.931,相较于逻辑回归的AUC值更高。这说明随机森林模型对于血糖数据分类效果更好。
5 结 论
本研究提出了一种基于三年体检数据来预测用户第四年是否患有糖尿病的风险预测模型。该模型通过PCA技术降低了自变量(特征变量)的维度,同时削减了变量间的高度重叠和高度相关性,能够保证新指标之间互不相关或相关性弱。通过5种方法的实验结果对比,随机森林算法对于体检数据糖尿病预测结果最佳,随机森林算法的敏感度和特异度分别为86.49%和85.05%,AUC值达到了0.931。但由于数据本身存在着变量数据缺失的问题,很多数据不足四年,且在特征选择中使用了新的综合指标,可能会丢失掉与空腹血糖相关的体检信息。在未来的研究中,我们将使用其他技术来改善模型的性能,选取作用更大的医学检查项目。
参考文献:
[1] 刘子琪,刘爱萍,王培玉.中国糖尿病患病率的流行病学调查研究状况 [J].中华老年多器官疾病杂志,2015,14(7):547-550.
[2] 张占林,孙勇,妥小青,等.随机森林算法对体检人群糖尿病患病风险的预测价值研究 [J].中国全科医学,2019,22(9):1021-1026.
[3] KAVAKIOTIS I,TSAVE O,SALIFOGLOU A,et al. Machine Learning and Data Mining Methods in Diabetes Research [J]. Computational and Structural Biotechnology Journal,2017,15:104-116.
[4] POLAT K,G?NE? S. An expert system approach based on principal component analysis and adaptive neuro-fuzzy inference system to diagnosis of diabetes disease [J]. Digital Signal Processing,2006,17(4):702-710.
[5] HAN L F,LUO S L,YU J M,et al. Rule Extraction From Support Vector Machines Using Ensemble Learning Approach:An Application for Diagnosis of Diabetes [J]. IEEE Journal of Biomedical and Health Informatics,2015,19(2):728-734.
[6] TRESP V,BRIEGEL T,MOODY J. Neural-network models for the blood glucose metabolism of a diabetic [J]. IEEE Transactions on Neural Networks,1999,10(5):1204-1213.
[7] GEORGA E I,PROTOPAPPAS V C,ARDIGO D,et al. Multivariate Prediction of Subcutaneous Glucose Concentration in Type 1 Diabetes Patients Based on Support Vector Regression [J]. IEEE Journal of Biomedical and Health Informatics,2013,17(1):71-81.
[8] 余麗玲,陈婷,金浩宇,等.基于支持向量机和自回归积分滑动平均模型组合的血糖值预测 [J].中国医学物理学杂志,2016,33(4):381-384.
[9] GANI A,GRIBOK A V,RAJARAMAN S,et al. Predicting Subcutaneous Glucose Concentration in Humans:Data-Driven Glucose Modeling [J]. IEEE Transactions on Biomedical Engineering,2009,56(2):246-254.
[10] PRADHAN M,BAMNOTE G R. Design of classifier for detection of diabetes mellitus using genetic programming [C]//Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing:Theory and Applications (FICTA),2014:763-770.
[11] 魏芬芬.灰色预测模型在血糖预测中的研究 [D].郑州:郑州大学,2016.
[12] 丰罗菊,王亚龙,张建陶,等.糖尿病肾病空腹血糖预测值筛选 [J].中国公共卫生,2008,24(6):727-729.
[13] 林震,王威.基于决策树的数据挖掘算法优化研究 [J].现代计算机(专业版),2012(28):11-14.
[14] 侯玉梅,朱亚楠,朱立春,等.决策树模型在2型糖尿病患病风险预测中的应用 [J].中国卫生统计,2016,33(6):976-978+982.
[15] 曹文哲,应俊,陈广飞,等.基于Logistic回归和随机森林算法的2型糖尿病并发视网膜病变风险预测及对比研究 [J].中国医疗设备,2016,31(3):33-38+69.
[16] 肖文翔.基于电子病历分析的糖尿病患病风险数据挖掘方法研究 [D].青岛:青岛大学,2016.
[17] 付阳,李昆仑.支持向量机模型参数选择方法综述 [J].电脑知识与技术,2010,6(28):8081-8082+8085.
[18] 黄衍,查伟雄.随机森林与支持向量机分类性能比较 [J].软件,2012,33(6):107-110.
[19] 龚谊承,都承华,张艳娜,等.基于主成分和GBDT对血糖值的预测 [J].数学的实践与认识,2019,49(14):116-122.
[20] 中华医学会糖尿病学分会.中国2型糖尿病防治指南(2017年版) [J].中国实用内科杂志,2018,38(4):292-344.
作者简介:马文彬(1994—),男,汉族,山东菏泽人,硕士在读,研究方向:醫疗大数据。
