基于豆瓣网某系列电影数据采集与可视化分析
2020-07-09黄蓉毛红霞
黄蓉 毛红霞

摘 要:文章基于Python程序设计实现了对豆瓣网站上《小时代》系列电影影评、剧照、歌曲的爬取,并针对爬取的影评做出相应的数据清洗以及数据可视化的展示。通过爬取豆瓣网站电影影评及相关剧照,分析大众对电影的态度以及电影本身的特色,并对影评数据进行清洗,进而通过数据可视化的具体形式直观的展现观众的评价,从而解释某种关于影视作品的现象。
关键词:网络爬虫;数据采集;影评;可视化
中图分类号:TP393.09 文献标识码:A 文章编号:2096-4706(2020)23-0004-04
Data Collection and Visual Analysis of a Series of Films Based on Douban.com
HUANG Rong,MAO Hongxia
(School of Computer and Software,Jincheng College of Sichuan University,Chengdu 611731,China)
Abstract:Based on Python program design,this paper realized crawling of film reviews,stills and songs of Tiny Times series on Douban.com,and made corresponding data cleaning and data visual display for crawling of film reviews. Through crawling the film reviews and relevant stills on Douban.com,analyze the publics attitude towards the film and the characteristics of the film itself,and clean the film review data,and then intuitively show the audiences comments through the specific form of data visualization,so as to explain a certain phenomenon about film and television works.
Keywords:web crawler;data collection;film review;visualization
0 引 言
目前国内影视行业存在一种“烂片高票房”的现象,而《小时代》这个系列电影就是“烂片高票房”的一个典型例子,从《小时代》上映后就遭到很多著名的影评人的批评,大家一致认为这部影片质量不高,但仍有大部分人选择花钱、花时间去观看。为更好的解释这一现象,笔者基于学校专业课程学习的Python内容与网络爬虫内容,选择利用爬虫技术对电影影评、剧照以及歌曲进行爬取,对电影本身及观众感受逐一分析,并通过可视化将数据展示出来。
1 数据采集
1.1 网络爬虫技術
网络爬虫又通常被人们称为网页蜘蛛,它是用特定规则去爬取静态或者动态网页中所需要的数据或内容的一种方法[1],换而言之网络爬虫的本质就是自动抓取网页信息的一段代码。爬取数据的基本过程可以分为四步,分别是:发送一个requests字样请求,通过HTTP库向目标服务器站点发送请求,等待对方服务器的响应;获取响应内容,如果服务器能做出正常响应,那么就会得到一个response回应,里面所包含的内容便是希望得到的网页页面内容;解析网页内容,由于得到的内容可能是HTML代码,一般需要用到正则表达式或者XPath等等进行网页解析;保存需要的数据,可以将内容存为文本、表格,也可以保存在数据库里。本文所用方法是基于Python语言进行的网页数据爬取,利用Python本身提供的众多数据库,高效、精准的进行网页抓取、网页解析、数据存储等操作[2]。
1.2 应对反爬策略
爬虫的速度是远远高于人类的速度的,所以在使用爬虫的时候会占用相当一大部分服务器的带宽,这就增大了服务器的负载,甚至在大量用户访问的情况下会造成网络拥堵,并且如果网络爬虫被滥用,会出现网络上数据内容雷同甚至一模一样的情况,使得原创作品得不到保护,于是,很多网页会设置反爬虫机制,来打破这样的局面。那么当用户真正需要爬取数据的时候,就必须对爬虫进行伪装。以下便是本项目应对反爬的策略:
(1)伪装用户代理,将请求头部User-Agent字段改为浏览器的User-Agent后再发送请求User-Agent[3]。
(2)设定休眠时间,人为浏览网页总是会停顿几秒,为了使爬虫与人类相似,一般在爬取的时候会将爬虫设置特定的休眠时间从而模拟人为登录状态[4],由此会使用time库中的sleep函数,在Selenium登入时模拟用户的点击延时行为。
(3)使用代理IP访问网站,豆瓣网页在爬虫频繁登陆后会封禁该IP一段时间,而利用代理IP,使得同一IP访问豆瓣服务器的频率相对减小,服务器难以检测[5],避免IP被封。
(4)伪装Cookie,一般情况下,网站会通过检验请求信息中是否存在Cookie,以及利用Cookie的值来判断该请求到底是真实用户还是爬虫[6],所以需要在用户某次登录时获取Cookie,将其加入到请求头中,达到模仿用户登录获取数据的效果。
1.3 模拟登录豆瓣网
模拟登录网页通常有两种方式,一种是requests请求,一种是Selenium模拟浏览器自动登录,本项目选择第二种方式登录豆瓣网。第一步,找到登录界面的网址,利用driver= webdriver.Chrome()启动浏览器,将找到的网址放入driver.get()方法中;第二步,利用driver.find_element_by_xpath()方法定位到密码登录的位置:用f12打开开发工具,利用鼠标点击可以找到其位置,代码表示为://*[@id="account"]/div[2]/div[2]/ div/div[1]/ul[1]/li[2];第三步,依次定位账号密码框,利用send_keys()输入内容,第四步,获取登录按钮的位置,click()点击登录即完成模拟登录。
主要代码为:
#点击密码登陆,豆瓣登陆框默认手机号登陆
password_login=driver.find_element_by_xpath('//*[@id="account"]/div[2]/div[2]/div/div[1]/ul[1]/li[2]')
password_login.click()
#找到账号框
username=driver.find_element_by_css_selector('#username')
username.click()
username.clear()
username.send_keys('***')
time.sleep(2)
#找到密码框
password=driver.find_element_by_css_selector('#password')
password.click()
password.clear()
password.send_keys('***')
time.sleep(2)
#找到登录框
submit=driver.find_element_by_xpath('//*[@id="account"]/div[2]/div[2]/div/div[2]/div[1]/div[4]/a')
print('准备登陆...')
submit.click()
time.sleep(5)
1.4 影評爬取
在影评爬取之前,需要找到电影的链接,因为《小时代》系列电影有四部,所以考虑利用Selenium定位获取四部电影的名字以及链接,在利用Selenium自动搜索电影名称的时候,发现当跳出新窗口时,driver定位的还是上一个窗口展现的页面,导致不能正确的输入想要的字段使得结果报错或者元素定位错误,所以利用driver.window_handles[1]切换页面句柄,让driver自动定位到新的窗口上,最后将名字和链接存放在字典里一一对应。每部电影需要爬取前500条数据,每页有20条数据,则需要爬取25页,这里涉及到翻页处理问题,通过网页链接的规律可知,在这25页中,只有start的值在发生变化,则可以用循环语句来代替人工翻页,代码为:link=v+'comments?start={}&limit=20&status=P&sort=new_score'.format(page*20),这里的page表示0到24,v
代表前面电影的链接,然后用xpath提取所需要的内容,具体代码为:
l = s.get(url=link, headers=headers,proxies=proxies)
html = l.content.decode('utf-8')
html = etree.HTML(html, parser=etree.HTMLParser (encoding='utf-8'))
#名字
host = html.xpath('//span[@class="comment-info"]/a/text()')
# 评分
gra = html.xpath('//span[@class="comment-info"]/span[2]/@title')
#内容
for c in range(1, 21):
con=html.xpath('//*[@id="comments"]/div[{}]/div[2]/p/span/text()'.format(c))
1.5 剧照爬取
在爬取剧照时,同样涉及到翻页问题,网页链接的规律与影评一致,都是只有start参数改变,可将翻页处理写成:url_photo=v+photos?type=S&start={}&sortby=like&size=a&subtype=a'.format(page * 30),主要代码为:
# 解析网页
print("开始爬取{}页".format(page + 1))
response = requests.get(url_photo, headers=headers,proxies=proxies)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "lxml")
imgTags = soup.find_all("div", attrs={"class": "cover"})
# 获取图片链接以及名字
for imgTag in imgTags:
src = imgTag.img.get("src")
name = imgTag.parent.get("data-id") + movie_name[i]
# print(src)
resp = requests.get(src, headers=headers,proxies=proxies)
1.6 音乐爬取
音乐与影评、剧照所不同的是,四部电影音乐总和较少,一共15条,所以不涉及翻页处理,直接在音乐界面获取即可,代码为:
def get_message(response):
html=response.content.decode('utf-8')
html=etree.HTML(html,parser=etree.HTMLParser (encoding='utf-8')) res_url=html.xpath(r'//*[@id="content"]/div/div[1]/div[3]/div[2]
//a/@href')#网址 res_song=html.xpath(r'//*[@id="content"]/div/div[1]/div[3]/div[2]//a/text()')#歌名
res_text=html.xpath(r'//*[@id="content"]/div/div[1]/div[3]/div[2]//p/text()')#歌曲简介
return res_song,res_text,res_url
2 数据清洗
在数据收集时或者收集之后需要对其进行清洗,为后续数据可视化做准备,对此,本项目采用的数据清洗步骤为:
(1)在爬取影评时,因为数据较多,循环过程中,利用xpath定位的节点位置有时会不一致:评分为空时节点位置是没有显示的,会导致抓取的元素为日期。为评分出错,导致后面无法分析,在抓取时直接利用循环遍历,将错误元素赋值为null,具体代码为:
grade = []
for i in gra:
if len(i) > 4:
i = "null"
grade.append(i)
(2)影評主要由作者,评分和内容三部分组成,如果内容存在缺失,不仅会导致错位,而且会导致最终一一对应时报错,则需要对每一页内容循环遍历,如若为空列表,则赋值为null,具体代码为:
content = []
for c in range(1, 21):
con=html.xpath('//*[@id="comments"]/div[{}]/div[2]/p/span/text()'.format(c))
if con == []:
con = ['null']
content.append(con[0])
(3)对于爬取下来的评分等级,需要进行计数处理,方便之后的可视化展示,则需要用到pandas的value_counts()方法对等级进行计数统计,其方法可以自动忽略空值,并且也避免了if…else的冗余。
3 数据可视化
3.1 数据可视化的作用
数据可视化的作用可以体现在多方面,而本项目则主要有以下三个作用,分别为:
(1)更加直观的参观数据,比如利用饼图来分析评分等级,繁冗的文字数据就被图形替代,能直观看到大众对电影的评价分布。
(2)统计效率更快,比如利用jieba库分词来统计词频,与人工统计相比,速度提升了不少。
(3)更加美观的展现数据,在(2)的基础上,如果想要统计出来的词频以特定形态呈现出来,那么就需要用到imageio库,否则它的形状就是一个普通的矩形。
3.2 设计需求
在如今的大信息时代,数据量急剧增加,数据本身的信息价值被不断冲刷,导致有价值的信息被无价值的信息淹没,所以我们需要一种更形象、具体的方式来处理这些数据,使得有价值的信息被展现出来,而数据可视化就完全符合要求。从某种意义上来说,数据可视化就是寻找数据本身中隐藏的某种规律及现象,通过图表的方式来总结复杂数据,要比书面信息更利于人脑的吸收[7]。所以本项目对数据做了以下处理:
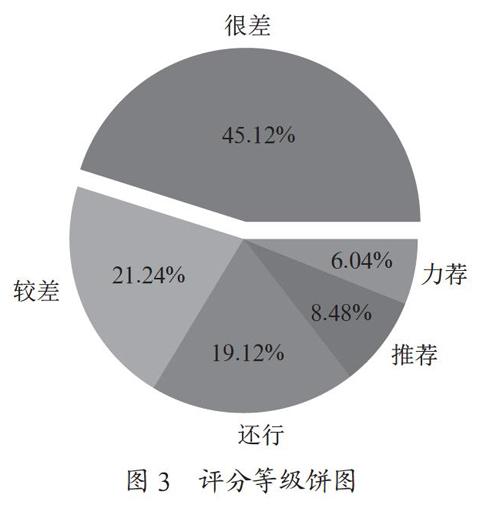
对爬取下来的每部电影前500条,四部共2 000条短评内容存入csv文件,然后读取评分等级那一列数据,利用pandas的value_counts()方法对五个不同的评分等级“很差、较差、还行、推荐、力荐”进行数据统计,由得到的统计数据绘制饼图来体现大家对《小时代》系列的评星看法。
运用jieba库对爬取到的短评内容进行词频统计,将统计结果存入txt文件,再利用wordcloud库绘制词云图,然后用Matplotlib库出现频率排行前十的词语做一个直方图的绘制。
3.3 相关技术
数据可视化部分利用codecs.open(filepath,method,encoding)打开文件;jieba库进行分词便于后续利用wordcloud做词云图,利用Imageio控制词云图形状。最后利用matplotlib库做数据的条形图draw_barh()、饼图draw_pie()。
3.4 具体实现
3.4.1 词频条形图
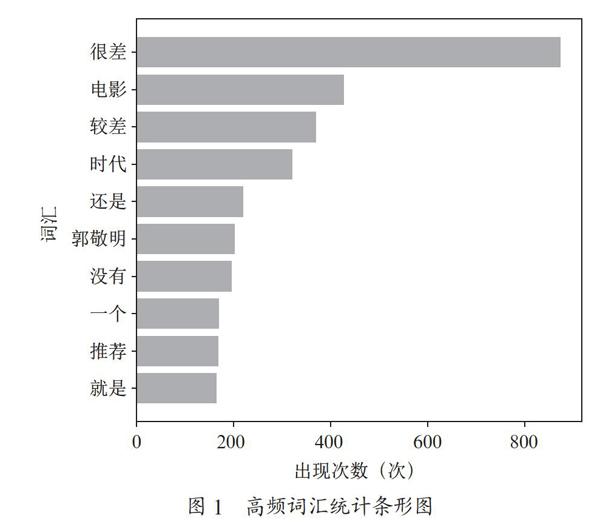
利用jieba中文词库自动进行分词处理,并利用Counter()方法统计其出现的次数,将非中文字符的分词删除,将处理好的词频存放在文件里面并绘制频率为前十的条形图,条形图的X轴设置为出现次数,呈现方式如图1所示。
3.4.2 词云图
为了将之前分割的词以特定的形式呈现出来,需要使用一张背景图片来加工,利用pac_mask = imageio.imread (r'xiaoshidai.png')增加一个背景图片,并在WordCloud()中加入参数mask,以此可自定义绘制词云图,呈现形式如图2所示。
3.4.3 饼图
由数据清洗得到大众对电影的5个等级,用这5个等级绘制出饼图,突出显示百分比最高的一个等级,呈现形式如图3所示。
3.5 可视化结论
利用饼图绘制评分等级后发现等级为“很差”的占比最多,这说明在大众心里这一系列电影无疑是非常烂的电影,利用jieba词库及条形图统计出来影评中高频率词语中有作者人名,同时他也是这系列剧的导演,据了解,他之前是一名青春文学作家,不少人读过他的小说,算得上是他的粉丝,可以说名气很大,意味着可能大部分观众是冲着这位名气甚大的作家去看的;通过抓取下来的剧照可以发现,剧中场景华丽,明星阵容超强,通过抓取下来的歌曲可以发现,演唱者大多在当时名气不小,正是因为有了强大的粉丝团以及明星效应引起的轰动,再加上小说的渲染,才成就了这系列电影的高票房。这也就是为什么如今频繁出现烂片高票房的原因了。
4 结 论
本文以豆瓣网站《小时代》系列电影为例,完成了对特定主题网络爬虫的数据采集、数据清洗以及数据可视化展示三部分,阐明了具体的设计背景以及设计思路,并编写完成了数据采集、数据清洗、数据可视化三个部分的代码。根据对系列电影影评、剧照及音乐的爬取,对其数据进行清洗并将部分数据进行可视化分析,可以解释部分影视作品评价不高却任然能够吸引观众去观看。因为在爬取影评时内容较多,虽然在代码中加入了多线程爬虫,但可以后期加以调试,对比得到时间花费较短的结果,以此来提高网络爬虫的效率。另外豆瓣网在同一账户登录频率较高时会设置滑块验证,本项目虽然利用了Selenium模拟浏览器进行自动登录,但是不能解决滑块验证即还会手动点击滑块获取验证,针对这一问题,后期可以通过自主学习,设计全自动化板块,以此来消除人工参与问题,达到自动化效果,进而提升效率。
参考文献:
[1] 温佐承,贾雪.基于Python的网络爬取 [J].电脑编程技巧与维护,2020(12):23-24+32.
[2] 赵文杰,古荣龙.基于Python的网络爬虫技术 [J].河北农机,2020(8):65-66.
[3] 刘石磊.对反爬虫网站的应对策略 [J].電脑知识与技术,2017,13(15):19-21+23.
[4] 伏康,杜振鹏.网站反爬虫策略的分析与研究 [J].电脑知识与技术,2019,15(28):28-30.
[5] 陈利婷.大数据时代的反爬虫技术 [J].电脑与信息技术,2016,24(6):60-61.
[6] 张岩.大数据反爬虫技术分析 [J].信息系统工程,2018(8):130.
[7] 朱寅非.数据可视化应用领域及作用 [J].电子技术与软件工程,2020(16):149-150.
作者简介:黄蓉(1999—),女,汉族,四川成都人,本科在读,研究方向:大数据分析;毛红霞(1981—),女,汉族,宁夏石嘴山人,副教授,硕士,研究方向:大数据、人工智能。
