一种最小化数据中心网络流延迟框架研究
2020-07-09赵正伟任祯琴赵旭鸽
赵正伟 任祯琴 赵旭鸽

摘 要:延迟是数据中心网络及其承载应用的一个关键性能度量指标,越来越受到学术界和工业界的关注。文章提出一种综合的协调机制,把负载均衡和拥塞控制统一起来,在多条等价路径上均匀分布流量,利用ECN并结合流的优先级自适应地对拥塞做出反应。实验结果显示,该机制与目前采用的TCP和基于哈希的多路径传输机制相比,对延迟敏感的流,应用吞吐率提高了30%,流完成时间的99th分位数降低了90%;对背景流量,流的平均完成时间降低50%~80%。
关键词:拥塞控制;负载均衡;多路径传输;数据中心网络;显式拥塞通告;时限
中图分类号:TP393 文献标识码:A 文章编号:2096-4706(2020)23-0044-07
Study on a Kind of Network Flow Latency Framework of Minimizing Data Center
ZHAO Zhengwei,REN Zhenqin,ZHAO Xuge
(School of Information Technology,Luoyang Normal University,Luoyang 471934,China)
Abstract:Latency is a key performance measurement index of data center network and its load bearing application,which is getting more and more attention from academic circles and industrial circles. This pager proposes an integrated coordinated mechanism to unite load balancing and congestion control,and evenly distribute flow in several equivalent paths,uses ECN and combining priority level of flow to adaptively respond to congestion. Experimental results show,comparing to existing multi-path transmission mechanism based on TCP and Hash,the mechanism achieves an improvement of 30% in application throughput rate and an reduction of 90% in 99th percentile of flow completion time for latency-sensitive flow,and achieve a reduction of 50%~80% in average completion time of flow for background flow.
Keywords:congestion control;load balance;multi-path transmission;data center network;explicit congestion notification;time limit
0 引 言
近年來,随着互联网和云计算的快速发展,数据中心已经成为许多商业服务的关键基础设施,如Web搜索、在线零售、社交网络和广告推荐系统等。这些服务通常是面向用户的在线服务,延迟对用户体验有重要影响,并最终影响服务提供商的运营收入。例如,平均访问延迟增加100 ms将使Amazon的收入减少约1%[1,2];增加100 ms的延迟会使Google的搜索请求减少0.2%~0.4%,并最终导致其收入减少[3]。此外,数据中心主存、外存和计算的分离也加剧了对低延迟网络通信的要求[4-6]。
然而,在目前的数据中心网络中,满足流的时限约束非常困难,具体原因有:
(1)划分-聚合负载模式:划分-聚合设计模式(partition- aggregate workloa d)是目前许多大规模互联网应用的基础,如搜索引擎等。在该负载模式下,大量的小流在短时间内汇聚到交换机的一个端口上,导致端口缓冲溢出,继而发生丢包和重传[7-10]。
(2)顺序依赖性的负载模式:顺序依赖性的负载模式(dependent-sequential workload)是数据中心中另一种常见的通信模式,例如,为了构建一个用户页面,Facebook需要进行100~200次数据请求,其中很大一部分请求之间存在时序依赖关系[12]。文献[12]指出,同一机柜内,约有10%的通信往返时间大于1 ms,也就是说,在最坏情况下,2~3个RTT就会导致一条流错过时限。
(3)公平共享的传输层协议:TCP公平对待所有的流,拥塞发生时,在最小化流的完成时间以及错过时限流的比例方面,远不是最优的,不仅不能满足应用的延迟要求,还会造成网络带宽浪费。
(4)基于随机的负载均衡策略:目前数据中心大都采用ECMP在多条路径之间均摊流量,通常会导致热点的出现,多条流可能被调度到一条拥挤的路径上,其他的路径几乎没有流量。这会大量增加流的平均完成时间以及高分位数完成时间。
为此,本文提出一种综合的协调机制,把数据中心网络多路径传输和拥塞控制有机地结合起来,减小数据中心网络流延迟。该机制既能充分利用现代数据中心的多根树拓扑,又能保证随着拥塞的加剧,系统仍然能够像TCP一样收敛。同时在小规模的真实环境和大规模的仿真环境进行实验,结果显示该机制能够大幅降低流延迟。
1 背景和相关工作
1.1 数据中心的网络拓扑和负载均衡
为了提高性能和可靠性,现代数据中心大都采用多路径的拓扑结构[13-16],任意两个节点之间有多条等价路径,但是路由和转发层面没有有效利用这些等价路径。数据中心的多路径传输机制,根据粒度的不同,大致可以分为以下3类:
(1)以流为粒度的多路径传输机制。目前,ECMP[17]是数据中心中多路径传输的事实上的标准,但是经常发生负载分布不均[12,18,19]的情况。Hedera[18]、MicroTE[20]、Mahout[21]和BCube[13]根据当前的网络状况来选择路径,当网络状况随时间变化时,被选择的路径可能已不是最优。VL2[15]和Monsoon[22]采用per-flow的Valiant Load Balancing(VLB),但是,这两个工作都不在多条路径上对单条流进行分割。
(2)以子流(sub-flow)为粒度的多路径传输机制。MPTCP在主机端把一条TCP流分割成多条sub-flow,对于长度大于70 kB的流来说,MPTCP非常有效,然而对于长度小于10个分组的流来说,MPTCP的性能不如TCP[19]。FLARE[23]把一条流分解为一系列的突发(Flowlet),并把Flowlet路由到不同的路径上。但是不能有效解决数据中心的同步突发问题,Flowlet会导致更大幅度队列长度变化[22]。
(3)以分组为粒度的多路径传输机制。Cisco的一些商用交换机[24]已经采用了比较成熟的分组喷射技术(packet spray),以分组的目的地址为单位进行轮循调度(round-robin)。文献[25]提出在主机端以分组为单位在多条路径之间进行分发,扩展性不是很好。DeTail[25]以分组为单位进行自适应的多路径传输,但是,它几乎全部废弃了TCP层的功能,并且受到优先级数目有限的限制[10,26]。RPS[27]把一条流的分组随机指派给多条等价路径中的一条,尽管这可以降低复杂性,但RPS仍然会造成热点问题。
1.2 数据中心的拥塞控制
同步突发是数据中心流量的一个基本特性,但是目前的数据中心网络不能很好地处理这种情况,导致应用错过时限,具体为:
(1)TCP/IP协议栈在网络发生拥塞时,使用丢包作为对发送端的反馈,超时重传机制经常导致丢包的流错过时限。
(2)TCP平等对待所有的拥塞流,拥塞发生时,不能优先处理某些特殊的流,这对时延敏感流极其不利。RCP[28]、XCP[29]和DCTCP[7]在高速网络中性能都获得显著的提升,然而,这些都是公平共享的,在减小流完成时间上远不是最优的[8,9,20]。
更严重的是,由于TCP不能很好地满足应用的时限要求,开发人员转而寻求其他解决途径。例如,据报道,Facebook正在开发基于UDP的拥塞控制协议,来满足应用的延迟要求[7,14,15]。
2 系统设计与分析
2.1 系统概述
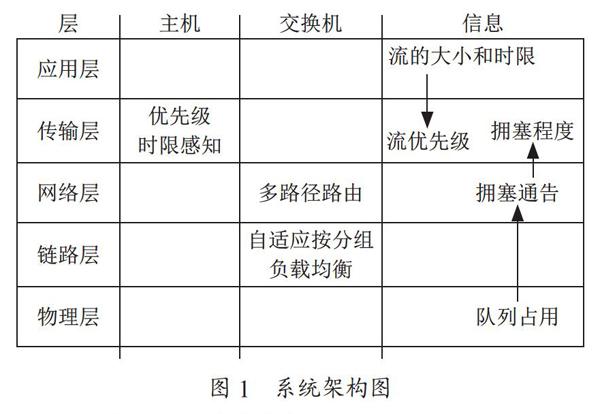
图1展示了系统的设计方案及其信息交换过程。该系统的主要设计思想是,通过基于交换机队列长度阈值的信号机制和ECN标记机制,把数据中心网络多路径传输和拥塞控制协调起来,主要目标是利用多路径和提高小流的优先级来满足小流的延遲需求。该机制由两部分组成:
(1)在网络侧,我们在交换机上监控其端口队列的瞬时长度,当超过阈值时,触发一个拥塞信号并通告给网络层,作为其多路径路由选择的依据,同时对队列中的分组进行ECN标记。
(2)在主机侧,接收端仅把ECN标记完整地写入ACK,并反馈给发送端。发送端根据在每个RTT内接收到的ACK分组中的ECN标记信息,计算网络的拥塞程度,根据这个拥塞程度和流的优先级动态调整其发送速率。
2.2 自适应的负载均衡
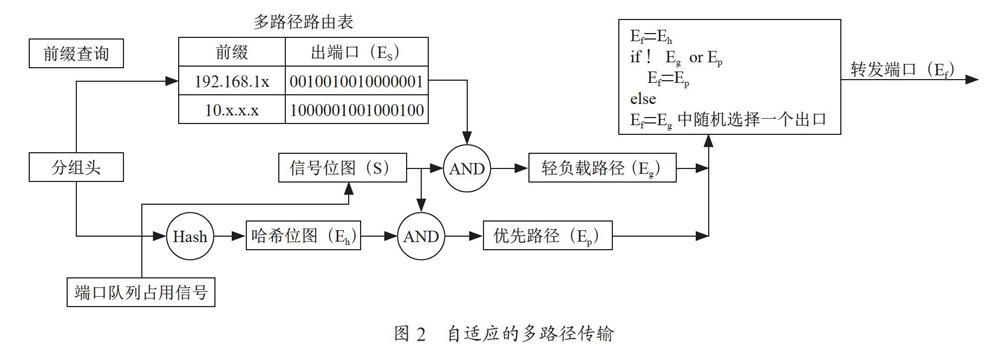
为了把分组转发到队列长度最短的等价路径上,并且不带来额外的计算开销,本文提出一种自适应的多路径传输机制。我们为交换机的每个缓冲队列关联一个信号,一旦队列占用小于某个预先设置的阈值,就把信号置为有效,一旦队列占用长度超过这个阈值,就把信号置为无效。这个信号反映的是网络的拥塞状况,所有端口的信号构成一个信号位图,称为信号位图,如图2所示。
当分组到达交换机时,交换机从多路径路由表中取出所有可能的转发端口Es同时获取信号位图S。接着把Es和S做按位与操作,得到所有可能的负载较轻的路径Eg,并对分组头做哈希操作,得到默认的ECMP的转发端口Eh。如果Eh的负载也较轻(即Eh∈Eg),就把Eh作为转发端口。否则,交换机就从Eg中随机选择一个端口转发该分组。当没有负载较轻的路径时(即Eg=?),交换机还要对分组设置ECN标记。这里优先选择ECMP计算出来的路径,其主要目的是为了和传统的ECMP保持一致,在一定程度上减小分组乱序的发生。
2.3 基于优先级的自适应的拥塞控制
2.3.1 网络的拥塞程度
和DCTCP[7]一样,我们采用ECN机制来获取网络的拥塞程度。发送端维护一个变量α,用来估计已标记分组的比例,每发送完一个窗口的数据(大概是一个RTT时间)更新一次:
α=(1-g)·α+g·F (1)
其中,F为最后一个窗口中被标记的分组的比例。0
2.3.2 基于时限的优先级划分
为了优先处理时延敏感的流,我们引入了优先级的概念。优先级越高,拥塞时其拥塞窗口退避幅度越小。流的优先级定义为:
(2)
其中RD为在时限截止前发送完一条流剩余数据的期望速率,RA为从流开始到当前时刻的平均速率。
2.3.3 拥塞窗口的调节
为了根据网络的拥塞程度和流的优先级来调节拥塞窗口,我们定义惩罚函数:
P=αp (3)
这个函数被称为Gamma校正函数。这个函数的一个优良特性是当自变量α在[0,1]之间变化时,其函数值也在这个区间变化,这就可以保证,当拥塞加剧时或者时限即将结束时,PDTCP可以像TCP一样收敛。
接下来,根据惩罚函数P调节拥塞窗口:
(4)
可以看出,在网络拥塞程度相同的情况下,优先级越高,惩罚函数P越小,窗口W退避得越少,从而保证能够以较快的速度发送完毕。在所有的流中,拥塞程度相同时,延迟不敏感的流窗口退避程度最大,从而为延迟敏感的流腾出带宽,满足后者的时限约束。
2.3.4 提前优先级翻转
当可以确定流不能满足其时限约束时,提前将其优先级降为最低,为其他延迟敏感流腾出带宽。
2.4 理论分析
假定N条无限长的流共享M个链路,N?M所以M条链路就是瓶颈链路。因为采用按分组的多路径传输,所以在任何时刻,M条链路的队列长度都是相同的。进一步假设N条流完全同步,锯齿窗口完全一致,并且都有相同的RTT。这种通信模式是由数据中心中常见的划分-聚合设计模式产生的。
根据文献[30],在t时刻,队列长度由式(5)决定:
Q(t)= (5)
这里N条流共享一条瓶颈链路。RTT是往返时间,没有排队延迟。假设TCP进入到AIMD的拥塞避免阶段。Wi(t)为第i条流在时间t时的窗口大小,C为链路带宽,ε为被丢弃的分组数目。
这里N条流完全同步,其锯齿窗口完全相同。我们忽略ε,因为PDTCP的设计初衷之一就是避免分组丢弃。所以,可以把式(5)变为:
M·Q(t)=N·W(t)-(RTT·C·M) (6)
式(6)的物理意义是这样的:所有发出的分组,要么是在M条链路的队列里,要么在M条链路上。
为了刻画锯齿窗口的特性,我们重点关注以下几个变量:交换机队列的最大长度Qmax、队列的震荡幅度A、震荡的周期TC。其中最关键的是震荡幅度A,因为算法的目标之一就是尽量维持队列长度在其阈值K附近,震荡幅度越小越好。因为N条流是完全同步的,所以交换机队列也是锯齿状,只是震荡幅度和发送端拥塞窗口不同,如图3所示。
因为所有的发送者是完全同步的,考虑其中的一个。令PS(W1,W2)为发送者的窗口从W1增加到W2期間,一共发送的分组数目。这个过程需要W2-W1个RTT,并且期间的平均窗口大小为(W2-W1)/2,因而可以得到:
PS(W1,W2)=(W2-W1)·(W1+W2)/2=(W22-W12)/2 (7)
令W*=M·(C·RTT+K)/N,其为队列长度接近K时的临界窗口大小,超过这个之后,交换机开始设置CE代码点。在下一个RTT,发送窗口增加到W*+1,发送端接收到CE标记。因此:
(8)
将式(7)带入式(8),得:
α(P-P2/4)=(2W*+1)/(W*+1)2 (9)
假设惩罚函数P的值很小,忽略高次项,得:
αP=(2W*+1)/(W*+1)2 (10)
假定W*?1,式(10)右边近似等于2/W*,将窗口退避惩罚函数的定义式P=α p带入式(10),得:
αp+1≈2/W* (11)
由此得到α的近似值:
α=(2/W*)1/(p+1) (12)
下文计算队列的震荡幅度QA。定义WA为一条流的窗口震荡幅度,如图3所示。因为N条流是完全同步的,QA只是WA的简单放大,即:
(13)
因为N条流共享M条链路,故:
M·QA=N·WA (14)
(15)
式(15)展示了PDTCP在多路径下的一个重要特性:当N比较小时,队列的震荡幅度为O((M·C·RTT)1/(p+1))。
當p=1,N较小时,振幅为,这就是DCTCP
在自适应多路径传输下的情形。当p=0时,就是TCP在多路径下的情形。
到此,我们得到:
TC=WA(inRTTs) (16)
最后,根据式(5),可以计算Qmax:
(17)
门限值K。交换机队列长度的最小值计算为:
(18)
Qmin对N求导,并让导数取0,求解N,得:
N=(1/2)(p/(1+p))1+p[M(C·RTT+K)] (19)
带入式(18),并令Qmin>0,得到K的下界:
(20)
3 实验结果
3.1 关键参数设置
我们根据文献[5]来设置DCTCP,D2TCP和PDTCP的关键参数。对1 Gbps的链路,设置g=1/16。对PDTCP,和文献[6]一样,我们限制了流的优先级P的取值范围在[0.5,2.0]之间。对所有的协议,我们把RTOmin设置为20 ms。
流的时限服从指数分布,均值分别为20 ms(tight)、30 ms(median)和40 ms(lax)[8]。我们用应用吞吐率即满足时限的流的比例,作为这些时限约束流的性能度量指标。
3.2 真实环境结果和模拟器验证
为了验证模拟器的参数设置,我们同时在真实环境和ns-2中构建了一个36节点的Fat-tree拓扑,并使用相同的负载流量。结果显示,真实实现和仿真实验下各个指标的绝对值和相对差值都非常小,并且变化趋势一致,这些关键的相似性说明模拟器的参数设置是可信的,能够反映系统在真实实现下的性能。
3.3 仿真实验结果
划分-聚合负载模式。图4(a)展示了当同步突发流数目从5增加到40时,应用吞吐率的变化情况。可以看出,与TCP+FH相比,PDTCP+AM有明显的性能提升,例如,当并发的同步流数目是40时,PD2TCP+AM下95%的流满足时限,而TCP+FH只能满足65%流的时限。图4(b)展示了流完成时间的99th分位数,我们把流完成时间归一化到最优值上。PD2TCP+AM能够获得接近最优的性能,因为归一化的流完成时间的99th分位数在1.0~1.2之间。TCP+AM与PD2TCP+FH比TCP+FH稍好,其值分别在1.4~2.5和1.1~1.6之间。TCP+FH表现最差,当并发流数目是40时,其归一化的完成时间超过6,亦即最优值的6倍。同样,对背景流量,PD2TCP+AM也能获得接近最优的表现,如图4(c)所示。
顺序依赖负载模式。在该流量模式下,PD2TCP+AM的性能提高比在划分-聚合流量下更明显。如图5所示,当工作流的达到速率在1 600个/秒时,PD2TCP+AM和TCP+ FH的应用吞吐率分别是96%和70%,归一化流完成时间的99th分位数分别是1.5和45。对背景流,在1 600工作流/秒时,归一化的流完成时间分别是1.6和9.5。
这些结果说明,与TCP+FH相比,PDTCP+AM在性能上有明显的提升,其原因是自适应的多路径机制充分利用了拓扑结构中的多条等价的最短路径,并且以分组为粒度选择最不拥堵的路径。这种机制能同时降低流的排队延迟,并提高流的吞吐率。此外,在拥塞时,PDTCP优先处理延迟敏感的流,进一步降低了这类流的排队延迟。
4 结 论
延迟是数据中心网络主要的性能指标之一,降低数据中心网络流延迟面临许多挑战。本文提出一种协调一致的数据中心网络拥塞控制和多路径传输机制,同时解决数据中心网络对高带宽和低延迟的要求。同时在真实和仿真环境中,采用真实的数据中心流量模型对该机制进行评价。实验结果显示,该机制与目前数据中心采用的TCP和基于哈希的多路径传输机制相比,能够有效提高延迟敏感流的应用吞吐率和99th分位数完成时间,并能同时提高背景流的吞吐率。
参考文献:
[1] HOFF T. Latency is Everywhere and it Costs You Sales-How to Crush it [EB/OL].(2009-07-25).http://highscalability.com/blog/2009/7/25/latency-is-everywhere-and-it-costs-you-sales-how-to-crush-it.html.
[2] KOHAVIR R,LONGOTHAM R. Online experiments:Lessons learned [J] Computer ,2007,40(9):103-105.
[3] BRUTLAG J. Speed matters for Google web search [EB/OL].[2020-10-15].https://services.google.com/fh/files/blogs/google_delayexp.pdf.
[4] GAO P X,NARAYAN A,KARANDIKAR S. Network requirements for resource disaggregation [C]//Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation.Berkeley:USENIX Association,2016:249-264.
[5] SHAN Y Z,ZHANG Y Y,CHEN Y L,et al. LegoOS:a disseminated,distributed OS for hardware resource disaggregation [C]//13th USENIX Symposium on Operating Systems Design and Implementation.Berkeley:USENIX Association,2018:69-87.
[6] KUMAR G,DUKKIPATI N,JANG K,et al. Swift:Delay is Simple and Effective for Congestion Control in the Datacenter [C]//Proceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications,technologies,architectures,and protocols for computer communication.New York:Association for Computing Machinery,2020:514-528.
[7] VASUDEVAN V,PHANISHAYEE A,SHAH H,et al. Safe and Effective Fine-grained TCP Retransmissions for Datacenter Communication [J].ACM SIGCOMM Computer Communication Review,2011,39(4):303-314.
[8] CHEN Y P,GRIFFITH R,LIU J D. Understanding TCP incast throughput collapse in datacenter networks [C]//Proceedings of the 1st ACM SIGCOMM 2009 Workshop on Research on Enterprise Networking.Barcelona:Association for Computing Machinery,2009:73-82.
[9] ALIZADEH M,GREENBERG A G,MALTZ D A,et al. Data center TCP (DCTCP)[J].ACM SIGCOMM Computer Communication Review,2010,40(4):63-74.
[10] WILSON C,BALLANI H,KARAGIANNIS T,et al. Better Never than Late:Meeting Deadlines in Datacenter Networks [J].ACM SIGCOMM Computer Communication Review,2012,41(4):50-61.
[11] OUSTERHOUT J K,AGRAWAL P,ERICKSON D,et al. The case for RAMClouds:Scalable high-performance storage entirely in DRAM [J].ACM SIGOPS Operating Systems Review,2009,43(4):92-105.
[12] ZATS D,DAS T,MOHAN P,et al. DeTail:reducing the flow completion time tail in datacenter networks [J].ACM SIGCOMM Computer Communication Review,2012,42(4):139-150.
[13] GUO C X,LU G H,LI D,et al. BCube:A High Performance,Server-centric Network Architecture for Modular Data Centers [J].ACM SIGCOMM Computer Communication Review,2009,39(4):63-74.
[14] GUO C X,WU H T,TAN K,et al. DCell:A scalable and fault-tolerant network structure for data centers [J].ACM SIGCOMM Computer Communication Review,2008,38(4):75.
[15] GREENBERG A G,HAMILTON J R,JAIN N,et al. VL2:A Scalable and Flexible Data Center Network [J].Communications of the ACM,2009,54(3):95-104.
[16] MYSORE R N,PAMBORIS A,FARRINGTON N,et al. PortLand:A Scalable Fault-Tolerant Layer 2 Data Center Network Fabric [J].ACM SIGCOMM Computer Communication Review,2009,39(4):39-50.
[17] Cisco.Cisco Data Center Infrastructure 2.5 Design Guide [EB/OL].[2020-10-15].http://www.cisco.com/univercd/cc/td/doc/solution/dcidg21.pdf.
[18] AL-FARES M,RADHAKRISHNAN S,RAGHAVAN B,et al. Hedera:dynamic flow scheduling for data center networks [C]//Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation.San Jose:USENIX Association,2010:19.
[19] RAICIU C,BARR? S,PLUNTKE C,et al. Improving Datacenter Performance and Robustness with Multipath TCP [J].ACM SIGCOMM Computer Communication Review,2011,41(4):266-277.
[20] BENSON T,ANAND A,AKELLA A,et al. MicroTE:Fine Grained Traffic Engineering for Data Centers [C]//Conference on emerging Networking Experiments and Technologies.New York:Association for Computing Machinery,2011:1-12.
[21] CURTIS A R,MOGUL J,TOURRILHES J. DevoFlow:Scaling Flow Management for High-Performance Networks [J].ACM SIGCOMM Computer Communication Review,2011,41(4):254-265.
[22] GREENBERG A G,LAHIRI P,MALTZ D A,et al. Towards a next generation data center architecture [C]//Proceedings of the ACM SIGCOMM 2008 Workshop on Programmable Routers for Extensible Services of Tomorrow.New York:Association for Computing Machinery,2008:57-62.
[23] SINHA S,KANDULA S,KATABI D. Harnessing TCPs Burstiness using Flowlet Switching [C]//Hot Topics in Networks HotNets-Ⅲ.San Diego:2004.
[24] Cisco. Per-packet load balancing [EB/OL].[2020-10-15].https://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipswitch_cef/configuration/15-s/isw-cef-15-s-book/isw-cef-load-balancing.html#GUID-C725A4B8-9263-4D2C-95FB-F31D14E477C4.
[25] GEOFFRAY P,HOEFLER T. Adaptive Routing Strategies for Modern High Performance Networks [C]//2008 16th IEEE Symposium on High Performance Interconnects.Stanford:IEEE,2008:165-172.
[26] HONG C Y,CAESAR M,GODFREY P B. Finishing Flows Quickly with Preemptive Scheduling [J].ACM SIGCOMM Computer Communication Review,2012,42(4):127-138.
[27] DIXIT A,PRAKASH P,HU Y C,et al. On the impact of packet spraying in data center networks [C]//2013 Proceedings IEEE INFOCOM.Turin:IEEE,2013:2130-2138.
[28] DUKKIPATI N. Rate control protocol (rcp):congestion control to make flows complete quickly [D].Stanford:Stanford University,2007.
[29] KOHAVI R,LONGBOTHAM R,SOMMERFIELD D,et al. Controlled experiments on the Web:survey and practical guide [J].Data Mining and Knowledge Discovery,2009,18:140-181.
[30] APPENZELLER G,KESLASSY I,MCKEOWN N. Sizing Router Buffers [J].ACM SIGCOMM Computer Communication Review,2004,34(4):281-292.
作者簡介:赵正伟(1982—),男,汉族,河南渑池人,讲师,博士,主要研究方向:数据中心网络;任祯琴(1983—),女,汉族,河南焦作人,讲师,博士,主要研究方向:非线性系统;赵旭鸽(1992—),女,汉族,河南汝州人,助教,硕士,主要研究方向:大数据。
