基于近红外建立荞麦营养成分快速检测模型
2020-07-07张美莉鄂晶晶
张 晶 郭 军 张美莉 张 鑫 鄂晶晶
(内蒙古农业大学食品科学与工程学院,呼和浩特 010018)
关键字 荞麦 营养成分 近红外 快速检测模型
荞麦是蓼科荞麦属的一种双子叶作物,栽培历史悠久,常见的栽培品种为甜荞和苦荞[1-3]。荞麦营养全面,富含蛋白质、膳食纤维、维生素及黄酮类化合物等其他生物活性物质[4]。能够降低患痔疮、便秘、结肠癌和憩室病的风险,调节血糖和血胆固醇水平,对冠状动脉心脏疾病甚至癌症有抑制作用[5,6]。目前国际上对食品中各种营养成分的测定大多采用经典方法,蛋白质是反映荞麦品质的主要指标,国际上通常用凯氏定氮法测定蛋白质含量,具有准确度和精密度高的优点,但存在着费时费工、污染环境的缺点[7-9];淀粉是荞麦的核心成分,占比60%~70%,淀粉含量的测定主要是水解滴定法,该方法步骤繁琐、耗时且滴定结果易受试验条件的影响,误差较大;脂肪的测定主要是索式抽提法,该方法精确度高,但存在用时长、溶剂消耗量大且需要索氏抽提器等缺点[10];水分及灰分的测定主要通过干燥法和灼烧法,该方法耗时长、对操作者要求高,人为误差因子较大[11,12]。因此,亟需一种快速、准确的荞麦营养成分含量检测方法。
近红外是指波长介于780~2 526 nm的电磁波,主要用于有机物的定性和定量分析[13]。近红外光照射到物质后,会发生吸收、透射、散射、全反射和漫反射,能反映物质分子中含氢基团的种类和数量,可以体现出不同基团或者同一基团在不同的环境中产生的光谱在吸收峰值位置和强度上的不同,随着样品内部成分组成或结构的变化,其光谱特征也发生相应变化[14-17]。近红外光谱技术具有分析速度快、适用性广、样品无需前处理、不用试剂、不污染环境、操作简单和廉价等优点,还可实现全自动操作,减少人工测试带来的随机误差,具有较高的精密度和重现性,在农作物品质分析方面广泛应用[18,19]。目前有学者利用近红外光谱技术采集小麦、燕麦、荞麦、藜麦等的近红外光谱图,并对光谱图进行预处理后建立了相应的蛋白质、脂肪、纤维等含量的快速检测模型[20-26];Arazuri S等[27]利用近红外软件自带分析模块,建立了小麦流变学参数预测模型,预测效果较好。近红外光谱技术已经成熟运用到农产品品质检测中,但利用近红外光谱技术建立荞麦营养成分含量快速检测模型的相关研究鲜有报道。
本研究利用PE近红外光谱仪采集甜荞近红外漫反射光谱图,对原始光谱进行预处理,结合甜荞水分、灰分、脂肪、蛋白质、淀粉的化学值,利用Spectrum Quant软件的PLS分析模块建立甜荞各营养成分的近红外快速检测模型,并比较化学测量值与模型预测值的差异性从而验证模型的准确性。本研究对荞麦营养成分高效、快速检测具有一定的参考价值。
1 材料与方法
1.1 材料
样品:从内蒙古及其他省区采集甜荞样品共66份。
仪器:PerkinElmer SP8000近红外光谱仪;K9860全自动凯氏定氮仪;SH220N石墨消解炉;HK-08多功能粉碎机。
1.2 方法
1.2.1 样品处理
荞麦种子和荞麦米清理除杂后粉碎过80目筛,荞麦面粉直接过80目筛,密封,-20 ℃冷藏备用。
1.2.2 营养成分的测定
水分测定:参照GB 5009.3—2016;灰分测定:参照GB 5009.4—2016;脂肪测定:参照GB 5009.6—2016;蛋白质测定:参照GB 5009.5—2016;淀粉测定:参照GB 5009.9—2016;每个样品测定3次,取平均值。
1.2.3 样品光谱采集
使用PerkinElmer近红外积分球光谱分析仪在室温下对样品进行光谱采集,将样品置于样品杯中,避免产生空隙,在波数为12 500~4 000 cm-1范围内扫描,分辨率16 cm-1,每个样品重复3次,每次扫描32次。
1.2.4 样本集的划分
将样品随机分为训练样本集和验证样本集,训练样本集用于建立模型,验证样本集用于验证模型的准确性。
1.2.5 光谱预处理
在建立模型前需要对光谱进行预处理以消除光谱偏移或基线变化等对模型的影响。导数处理可以有效的消除基线和其他背景的干扰,提高灵敏度和分辨率;标准正态变量变换、多元散射校正可以消除粒度分布不均匀及散射影响;去趋势算法用于消除漫反射带来的基线漂移。
1.2.6 模型的建立
训练样本集样品近红外扫描光谱图经过预处理之后与相应的水分、灰分、脂肪、蛋白质、淀粉含量结合,利用软件Spectrum Quant偏最小二乘模块建立各营养成分快速检测模型。以交叉验证决定系数R2、标准分析误差和标准预测误差为参数来确定最佳建模方法,R2越大说明实测值与预测值相关性越好,模型的准确度越高,SEE、SEP值越小,说明模型预测精度越高。
1.2.7 模型的验证
利用所建立的各营养成分快速检测模型对验证样本集样本的水分、灰分、脂肪、蛋白质和淀粉含量进行预测,将预测值与真值进行T检验,判定预测值与真值的显著性差异,并以外部验证决定系数R2为指标来评价模型的预测能力。
2 结果与分析
2.1 甜荞营养成分测定结果
甜荞水分、灰分、脂肪、蛋白质及淀粉含量测定结果见表1。
从表1可以看出,甜荞水分10.30~14.32 g/100 g,灰分0.62~2.53 g/100 g,脂肪1.11~4.00 g/100 g,蛋白质6.68~18.15 g/100 g,淀粉56.03~77.60 g/100 g,各营养成分含量分布较广,说明甜荞样品具有较高的代表性和差异性,适合建立近红外光谱分析模型。
2.2 甜荞原始近红外光谱图
66个甜荞样品原始近红外漫反射光谱图见图1。
甜荞在光谱10 000~4 000 cm-1范围内存在多个吸收峰,样品近红外光谱变化趋势一致但是不重合,表明不同样本间重现性良好又存在差异。样品之间的差异可能是受到噪声和操作的影响,需要对光谱进行预处理。
2.3 模型的建立
2.3.1 样本集的划分
训练样本集和验证样本集随机划分结果见表2。可以看出训练样本集和验证样本集样品各营养成分含量的最大值、最小值及均值与总样本接近,表明训练集和验证集的分组合理,具有代表性;验证样本集样品各营养成分含量的均值与标准差与训练样本集相似,且验证样本集包含在训练样本集内,表明验证样本集所选的样本合理,可以用于模型的验证。
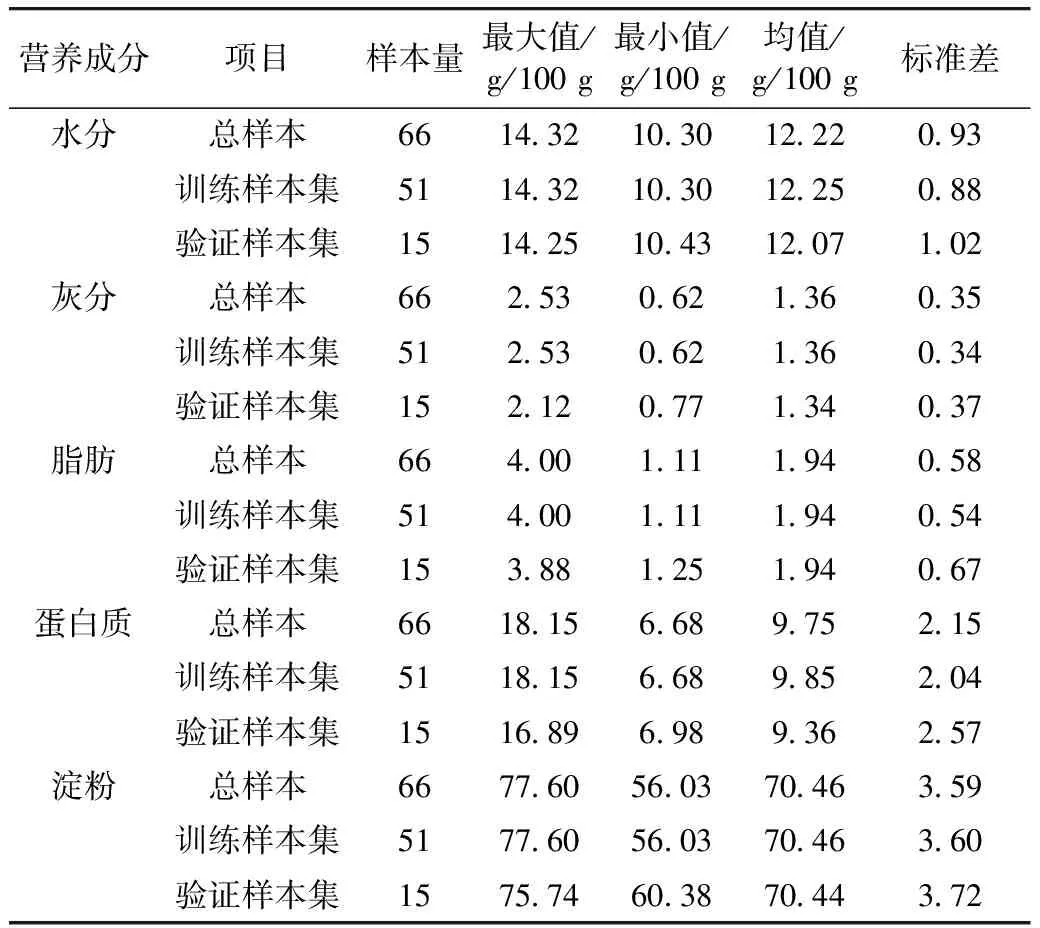
表2 样本集划分结果
2.3.2 不同光谱预处理方试对模型的影响
光谱采集过程中受到仪器状态、外界环境及人员操作等因素的影响,光谱数据中除了测定样品的结构和组成信息,也包含了噪声、散射和基线漂移等背景以及其他干扰信息,这些干扰会影响模型的可靠性和稳定性,因此在建立模型前需要对光谱进行预处理以消除光谱偏移或基线变化等对模型的影响[13,28]。不同预处理方式对模型效果的影响见表3。可以看出,不同的光谱预处理方式对模型的准确度有影响。可能是计算方法的不同,一阶或二阶导数处理是近红外常用的基线校正方法,一阶求导可以消除光谱中扁平的基线,二阶求导可消除光谱中倾斜的基线;SNV用于消除固体颗粒大小、表面散射和光程变化的影响;MSC可以消除粒度分布不均匀及散射影响;去趋势算法常用于SNV法处理之后,用于消除漫反射带来的基线漂移。
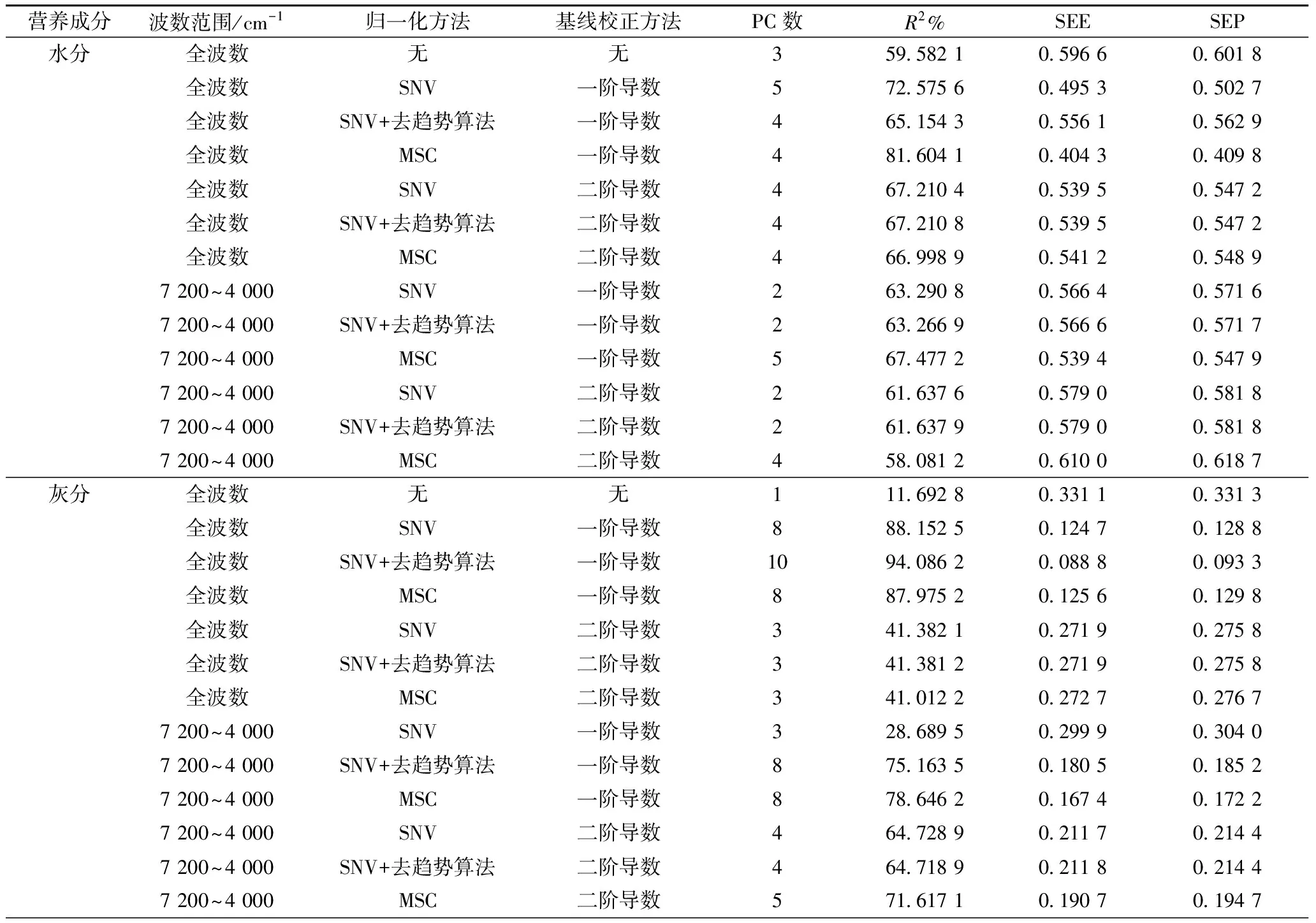
表3 不同预处理方式对模型的影响
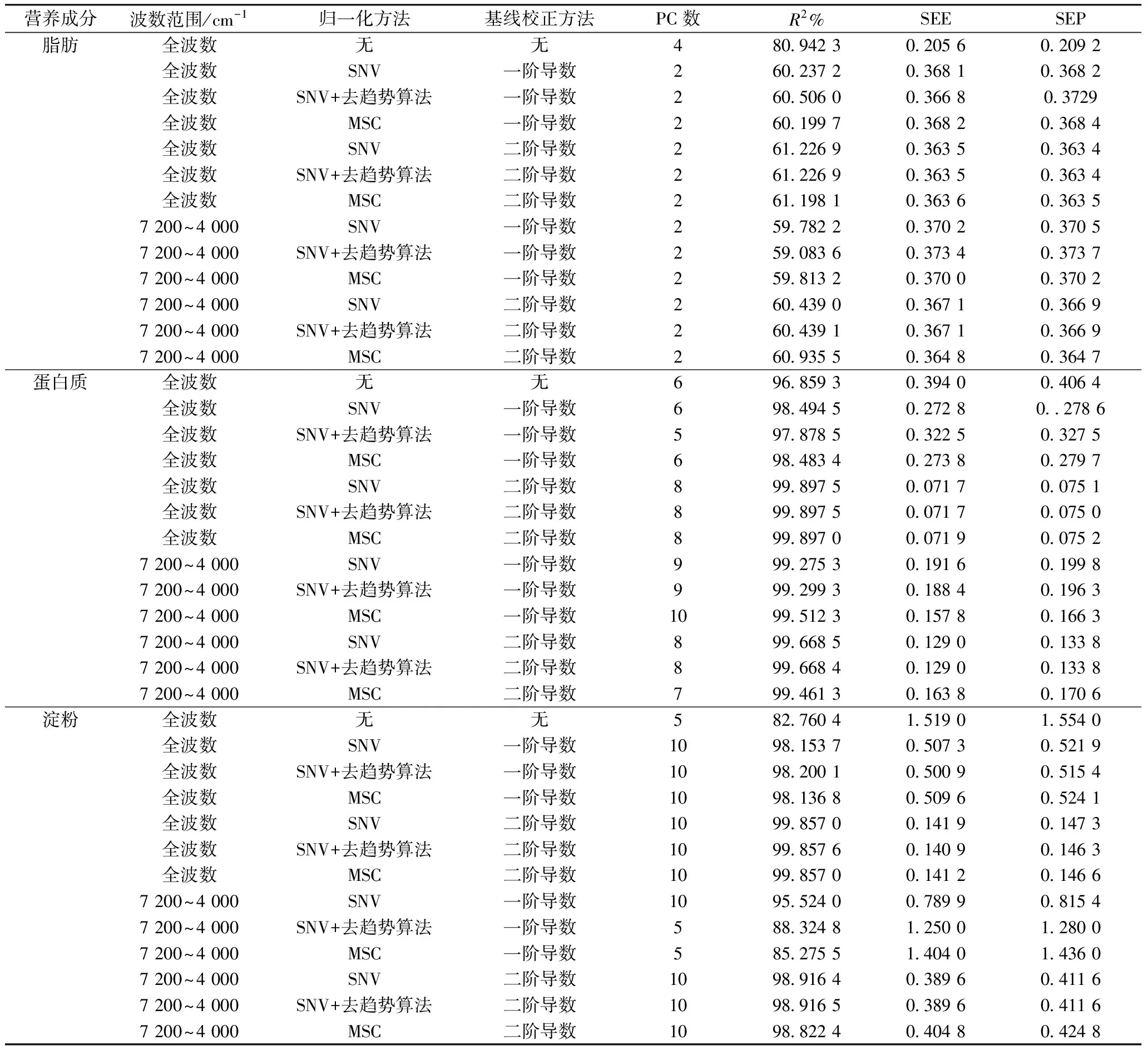
续表3
对样品进行建模不是由一个特定的方法来确定的,有的处理方法可以改善建模效果,有的方法可能由于本身处理的特点而带入其他信息,使建模效果降低。因此,建模时应根据不同检测目的、样品状态、仪器性能等情况,选择适宜的数据处理方法,以期获得最佳建模效果。训练样本集样品原始近红外漫反射光谱图进行最佳预处理后的光谱图见图2。
荞麦灰分含量快速检测模型建立的最佳光谱预处理方式为全波长范围内进行一阶导数处理、SNV及去趋势算法,此时模型的交叉验证决定系数R2可达94.086 2,SEE值为0.08;蛋白质快速检测模型的最佳光谱预处理方式为SNV、去趋势算法及二阶导数处理,建立的模型交叉验证决定系数R2可达99.897 5%,SEE值为0.072,与原始光谱相比,选择光谱范围对模型的校正并没有得到改善,可能是蛋白质成分复杂,选择光谱范围会造成信息的遗漏[29];淀粉快速检测模型的最佳预处理方式为SNV、去趋势算法及二阶导数处理,建立的模型交叉验证决定系数R2可达99.857 6%,SEE值为0.141。
水分含量快速检测模型建立的最佳光谱预处理方式为全波长范围内进行MSC及一阶导数处理,模型的交叉验证决定系数R2为81.604 1%,SEE值为0.40。R2相对较低,由于模型的准确性与训练样本集化学测定结果的准确性高度相关[30],水分测定过程中对数据精确度要求较高,且环境温度的变化、测量时间的长短及仪器本身能量可能不稳定,这也会影响分析结果的准确,导致R2值相对较低。
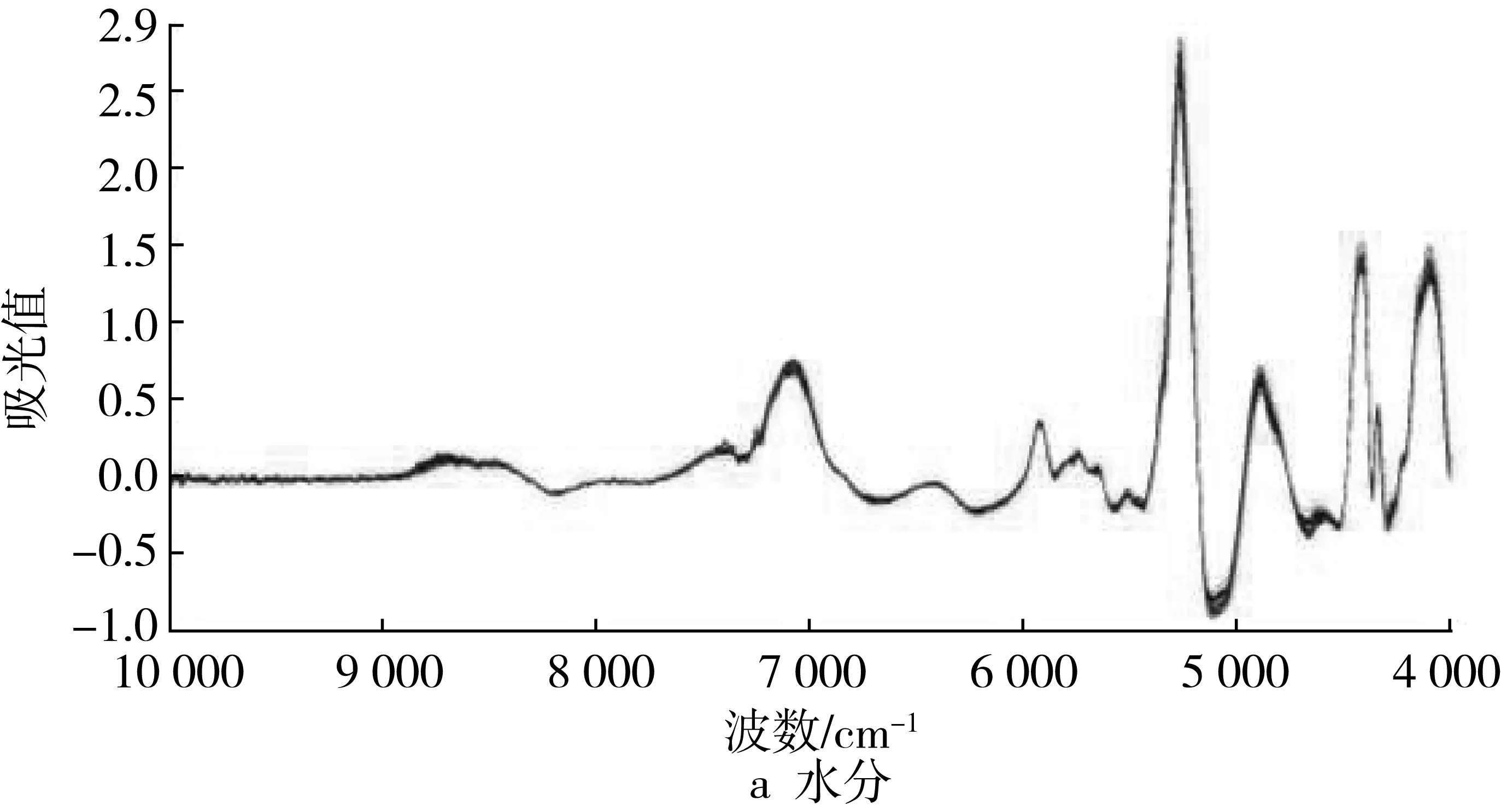
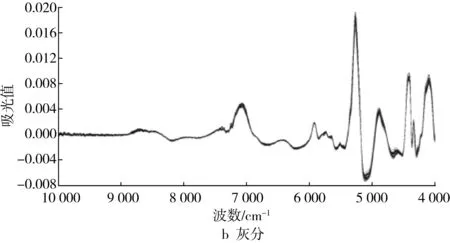
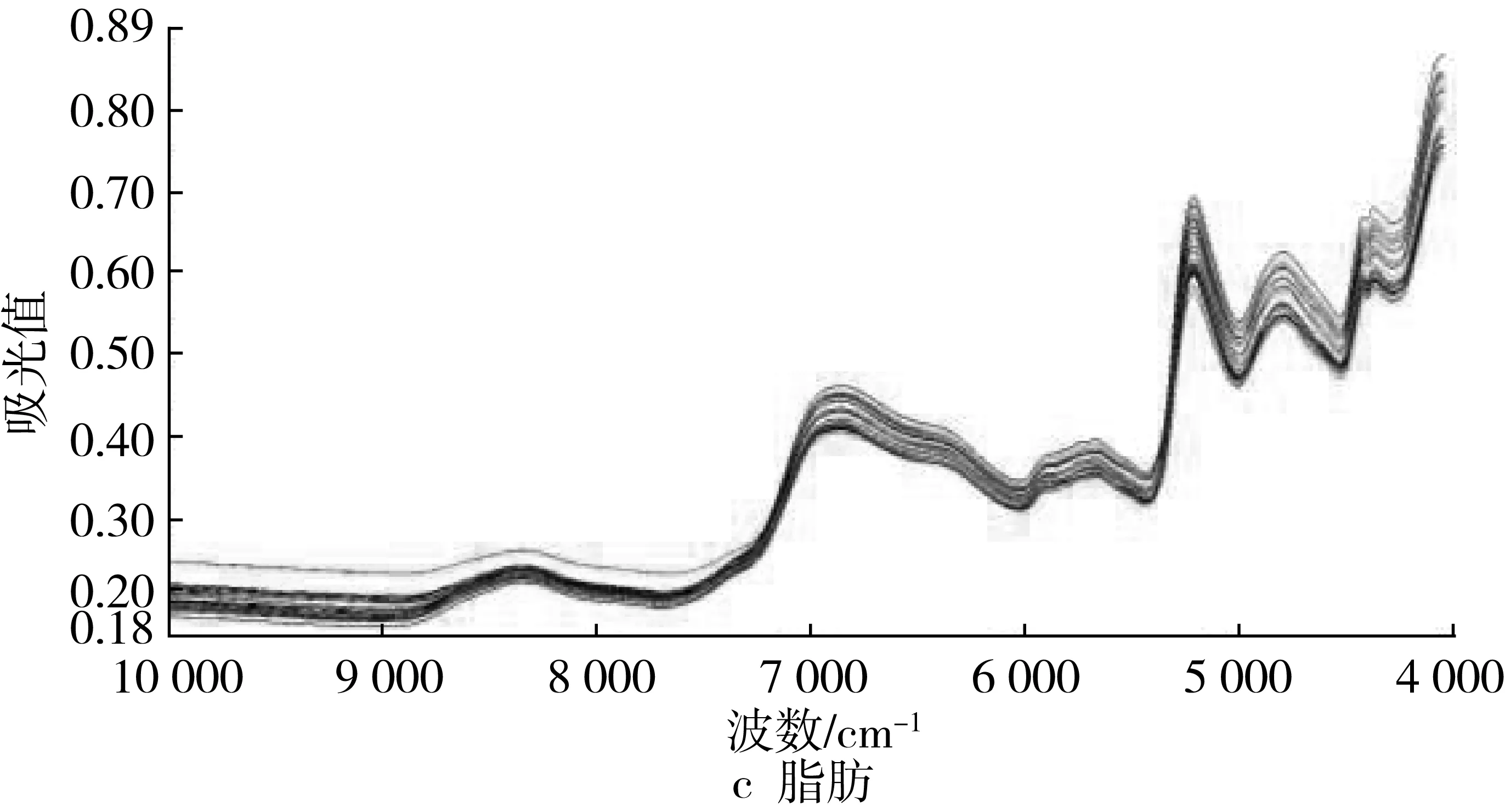
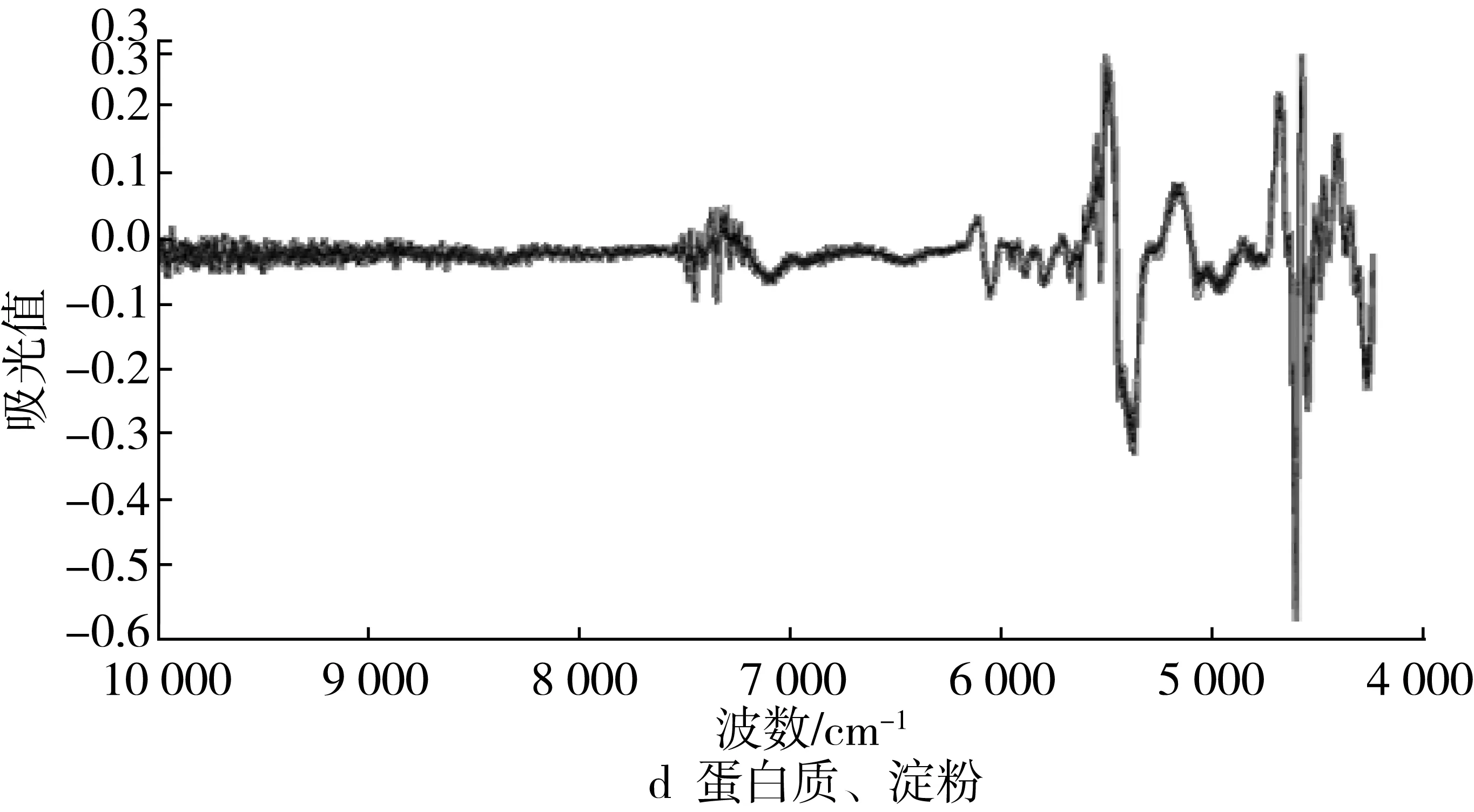
图2 最佳预处理后光谱图
脂肪含量快速检测模型的建立过程中,不进行光谱预处理的模型优于进行预处理的模型,可能是由于样品容量和脂肪含量阈值的扩大使建模效果显著提高,以至于在不经过光谱预处理的情况下就能获得比较理想的校正模型[29]。建立的脂肪快速检测模型交叉验证决定系数R2为80.942 3%,SEE值为0.21;R2低于其他营养成分快速检测模型的交叉验证决定系数,可能是索氏抽提法测定脂肪含量误差较大,还有人指出可能是参与建立模型的高脂肪含量的样品少,这种情况下为最好去掉极值,先建立较低脂肪含量的模型,这样模型的代表性较好,一个好的模型是需要不断优化的,等到收集较多的高脂肪含量的样品时再纳入建立模型[30]。
2.4 模型的验证
采用未参与模型建立的完全独立的、各营养成分含量已知的验证集样品对所建模型的实际预测效果进行评价,水分、灰分、脂肪、蛋白质、淀粉外部验证决定系数R2分别为81.60%、94.09%、80.94%、99.97%、99.86%,验证结果见表4。
各营养成分预测值、真值及预测值与真值偏差见表4。对验证样本集荞麦水分、灰分、脂肪、蛋白质和淀粉含量的预测值和化学测定值分别进行T检验,根据T检验的双边检验结果P值分别为0.074、0.210、0.852、0.212、0.132,各营养成分T检验P值均大于0.05,说明在5%的显著水平内,荞麦水分、灰分、脂肪、蛋白质、淀粉含量预测值及化学值差异不显著,建立的荞麦水分、灰分、脂肪、蛋白质及淀粉含量快速检测模型测定荞麦中水分、灰分、脂肪、蛋白质和淀粉含量是可行的。
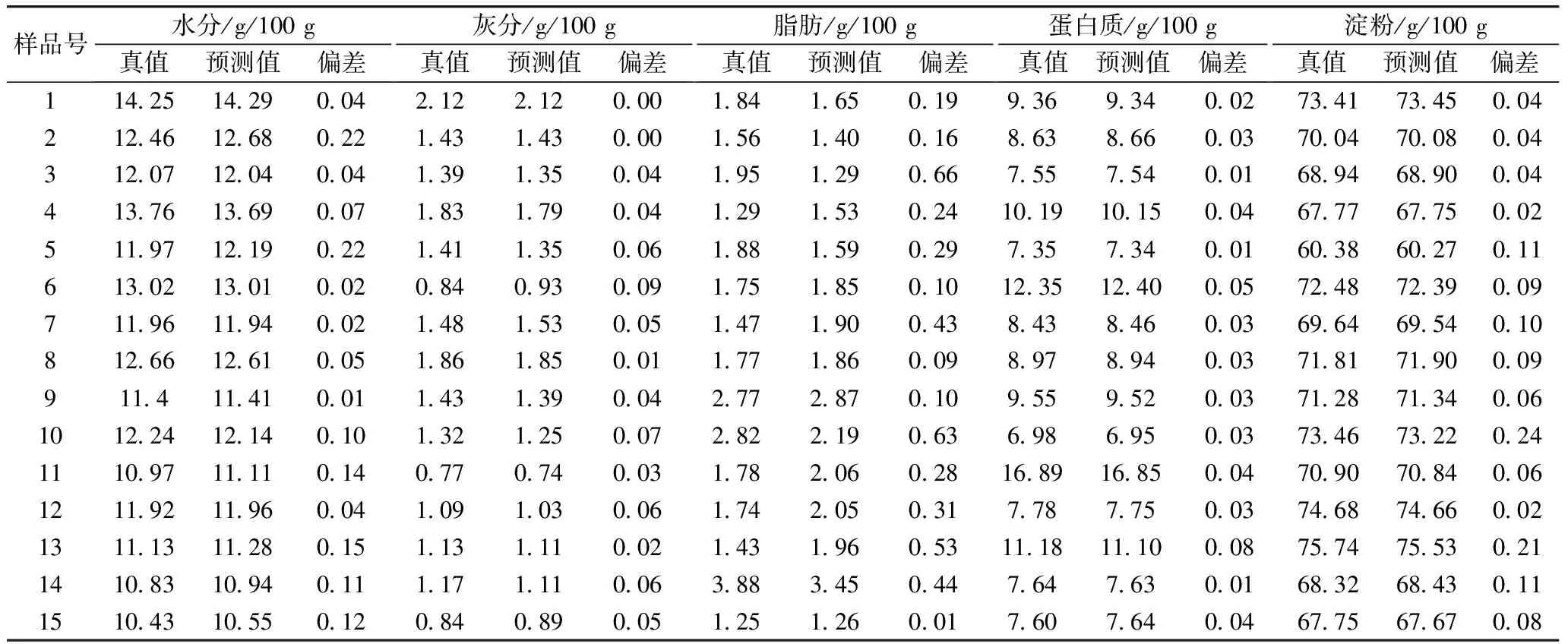
表4 荞麦各营养成分快速检测模型的验证
4 结论
本研究利用66份荞麦样品的近红外光谱指纹结合荞麦营养成分化学测定值,建立的荞麦水分、灰分、脂肪、蛋白质和淀粉含量近红外快速检测模型交叉验证决定系数R2分别为81.601%、94.086 2%、80.942 3%、99.897 5%、99.857 6%,R2较高,且验证结果预测值及化学值差异不显著,建立的模型可以满足大量样品水分、灰分、脂肪、蛋白质、淀粉快速高效检测的要求,极大地缩短了工作周期,减少了工作量。
