基于Fat-Tree的虚拟分片负载均衡算法
2020-07-06赵阿群赵晨辉
王 莉,赵阿群 ,2,赵晨辉
1.北京交通大学 计算机与信息技术学院,北京 100044
2.东南大学 计算机网络和信息集成教育部重点实验室,南京 211189
1 引言
在现代互联网应用和云计算技术的推动下,数据中心正在全球范围内得到极大的发展。数据中心由大量服务器和交换机组成,这些服务器和交换机连接在一起形成数据中心网络(DCN)。目前,数据中心已成为许多企业提供各种服务的关键基础设施,许多应用程序都已托管在数据中心内,因此数据中心在数据传输方面的要求越来越高。
为了获得高带宽并实现容错,数据中心网络(DCN)通常在任意两台服务器之间设计有多条路径[1-3]。多条路径不仅可用于处理潜在的故障,还可用于提高网络性能。特别是,当网络的流量负载变大时,可以使用多条路径来降低延迟并有效提高吞吐量。因此,平衡数据中心网络上的工作负载,实现多路径的有效使用,提高吞吐量以及减少流完成时间对于提高数据中心网络的整体性能来说是非常重要的。
2 研究背景
目前,在工业界应用最广泛的数据中心网络拓扑是以交换机为中心的三层级联的多根树拓扑架构,称为Fat-tree结构[4]。它具有简单易部署等优点,同时该拓扑使得任意两台服务器间存在多路径,数据包进行通信时若一个结点瘫痪底层结点还可以通过其他路径进行转发,具有很好的容错性。Fat-tree 网络拓扑结构分为三层,分别为核心层、聚合层及边缘层,所有的服务器与边缘层的交换机相连。如图1为4-port胖树模型。
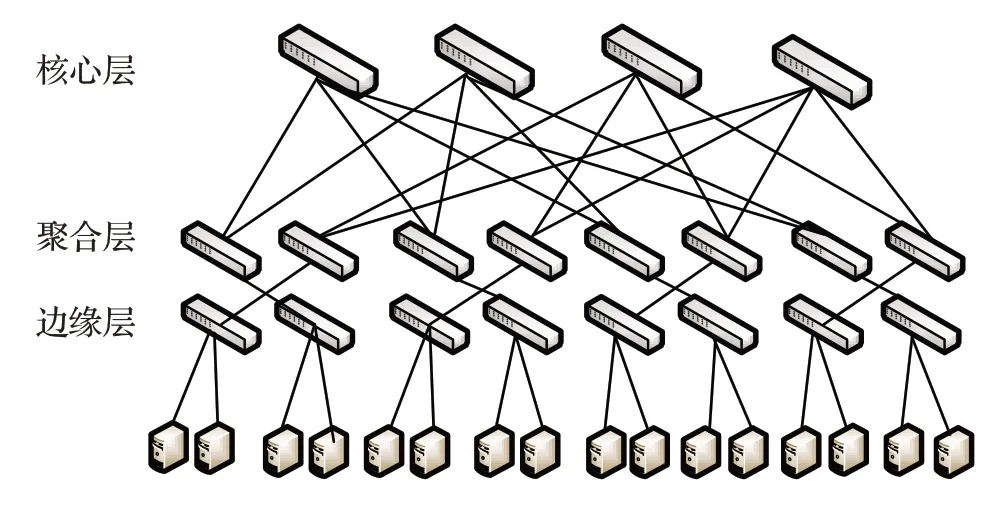
图1 4-port胖树网络拓扑
一般来说,数据中心的流量可以分为两种类型:大流,它们携带大量数据并且存在时间较长;小流,通常是对延迟敏感的流,它们数量很多但携带的数据量较少[5]。由于大流将占用大量网络资源,因此如果没有合理的进行大流调度,数据中心网络可能会发生拥塞,目前已经提出了许多解决方案来调度大流[2,6-7]。
传统的负载均衡算法是等价多路径路由算法(ECMP)[5,8]。ECMP 易于实施,不需要在交换机上进行流量统计。然而,ECMP 还存在两个缺点[9-10]:首先,ECMP不区分小流和大流。因此,经常发现小流排在出口端口的队列中,遭受长排队延迟从而影响流完成时间(FCT)[10-11]。其次,由于哈希冲突,ECMP 无法有效利用可用带宽,从而导致“大流碰撞”的问题[12-13]。除了ECMP之外,还提出了许多其他解决方案。Hedera是利用控制器收集从数据平面交换机的流量统计信息,采用启发式的算法对大象流进行路由[4]。SD-LB是根据网络链路状态对多路径进行动态加权,并结合交换机中的组表信息对大象流进行分配路径,从而缓解大象流造成的网络拥塞[14]。Fincher是收集全网信息形成流与交换机的偏好列表,从而对所有的流分配较合适的路径[15]。TinyFlow是将大流切分成多个小流,从而减少大流对链路的负载[7]。CONGA 利用了分布式技术来感知网络状况,依赖边缘路由器来对网络链路状况进行拥塞探测及负载调度[16]。这些解决方案相较于ECMP 都可以提高网络的性能,但还存在一些问题。例如Hedrea、SD-LB、Fincher在进行流处理时都需要交换机做一些额外的操作,影响交换机的转发效率。TinyFlow等将大流切分成小流的方法则会导致数据包的重组问题,从而导致更多的开销。CONGA则对交换机的要求过高,并且也对边缘交换机的负载过大,不利于部署。
负载均衡算法的设计对数据中心网络的性能有着重要影响。另一方面,随着网络规模和带宽需求的增加,数据中心网络的成本和功耗迅速增长,对于整个数据中心网络的整体性能也会有较大影响。传统的数据中心网络使用的是基于交换机转发的方式,交换机需要参与到数据包的转发决策中,因此交换机中需要存储并维护转发表。文献[17]提出了一种基于端口编址的DCN 体系架构。不同于传统的转发方式,该方法不需要交换机每次查表进行分组转发。数据包在发送时就记录了转发路径的所有端口号序列(PA),端口号序列是由控制平面在数据包生成时就已经计算得出。因此交换设备不需要做任何的处理,让交换设备只专注于基于端口的转发数据,而不用判断任何的状态信息,完全契合了未来网络“胖终端,瘦网络”的思想[17],实现了交换机“哑交换”,大大提高了转发效率。
结合以上,本文提出了一种基于Fat-Tree 的虚拟分片负载均衡方法(Virtual Slice Load Balance,VSLB)。该方法利用基于端口编址的转发方式,并且将大流分为多个子流,为了解决包排序的问题,本文根据文献[8]TSO 原理将小流的上限定为64 KB,并为这些小流分别选取更优的路径进行转发,从而解决了大流碰撞的问题。
3 整体设计
本章主要从整体上来介绍VSLB的设计。如图2为VSLB概述图。
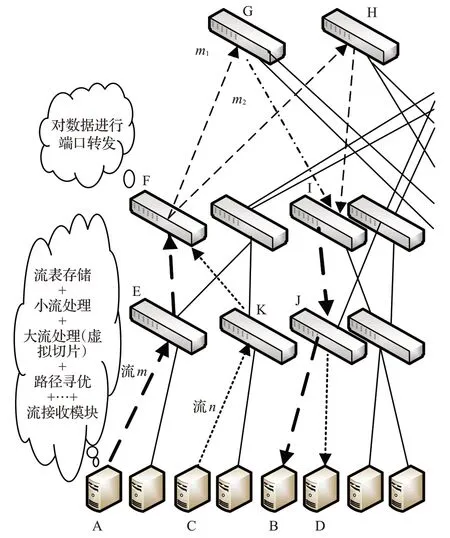
图2 VSLB整体概述图
图2 为4-port Fat-Tree 的半结构图,服务器A 向服务器B发送数据流m,服务器C向服务器D发送数据流n,假设m和n均为大流,流m沿着路径A→E→F→G→I→J→B 发送,流n沿着 C→K→F→G→I→J→D 发送,显然m和n在F→G→I→J链路发生了重合,如果两条大流在同一时间到达,这样就会产生“大流碰撞”的问题。本文提出的VSLB的思想是把大流进行分片处理,拆分出多个小流。如图中所示,子流m1沿着原路径发送,而子流m2沿着A→E→F→H→I→J→B 发送,同理流n也进行同样的子流选路处理。在5.2节中本文还提出了基于端口编址的全路径计算和路径寻优的方法,确保所选路径为网路中最优的路径。
从图2 还可以看出,VSLB 的几乎所有的部署都在在服务器端,这样就可以大大减少交换机的负载,交换机只需要进行流数据的转发即可,从而提高整个网络性能。
4 负载均衡设计
4.1 存储表的设计
为了更好地对大流和小流进行决策,需要在服务器终端上部署和维护三种存储表。三种表分别为小流轮询表RR_M、大流轮询表RR_E 和总的流记录表Flow_All。其中,RR_M 的作用是维护小流的发送路径;RR_E记录了该大流的所有可能发送路径,发送路径是根据全路径计算模块来进行计算,并且会根据路径探测包的探测结果对路径做优先级的排序。全路径计算及路径寻优将会在下文5.2.1小节和5.2.2小节中详细介绍;Flow_All是记录所有经过本服务器终端出去的消息流,以便更好地维护RR_M和RR_E。
4.2 VLSB的设计
VSLB 设计部署在服务器端,本节将从单个服务器的角度进行介绍,具体详细步骤如下:
(1)当一个流达到时,由于流是由多个数据包组成,因此每个数据包到达时,首先由包处理模块对数据包进行包到流的映射(这里是通过Hash 来实现),得到流的“名字”,然后根据总的流存储表Flow_All判断该流是否存在,如果存在进入步骤(2),否则进入步骤(3)。
(2)从Flow_All 取出该流并更新此流的大小,接着判断此时流大小是否大于64 KB,如果大于则此流被判定为“大流”,调用大流处理模块进行处理。若小于64 KB,则此流被判定为“小流”,根据小流轮询表取出该流的PA值,同时更新总的流记录表,进入步骤(4)。
(3)若总的流记录表Flow_All 中不存在该流的记录,则判定此流为一个新流并按小流处理,调用小流处理模块中的流初始化模块进行处理,本文将在4.1 节中详细介绍小流处理模块,然后进入步骤(4)
(4)无论是进行大流处理还是小流处理,结果都会返回一串PA值,接着调用消息发送模块,即利用服务器的发送机制进行数据包的转发。
5 流处理模块
上章介绍了VSLB的整体设计架构,本章主要介绍流处理模块。流处理模块可以拆分为分为大流处理模块(包括全路径计算和路径寻优)和小流处理模块(流初始化和地址轮询)。这样拆分既实现了整体方法的解耦和,并且在一定程度上提高了VSLB整体的性能。
5.1 小流处理
在一个流没有被判定为大流之前这个流都按小流来处理。当一条流到达时,根据RR_M表来判断此流是否存在,如果不存在则调用流初始化模块进行初始化;若存在且此流为小流则调用地址轮询模块对此小流分配新的发送路径。
5.1.1流初始化
在进行流初始化时,首先需要判断源服务器和目的服务器是否在同一个子网内(连接同一个边缘交换机)或者是否在同一个pod 内。表1 是针对以上不同情况RR_M 表存储的PA值,其中RR代表 RR_M 中的实体项,x代表边缘层交换机的上行端口,y代表聚合层交换机的上行端口,x,y∈[k/2,k-1],k值是由DCN的端口值决定。

表1 RR_M流初始化取值表
5.1.2地址轮询
5.1.1 小节中介绍了小流初始化。如果一条流达到时,且经过验证此流为小流,则需要对此流进行重路由,这里采用ECMP的思想来对端口进行轮询,即让不同的流沿着不用的路径发送,需要对此流计算新的PA 值。计算新的PA值要根据源PA值进行判断,表2为针对不同情况计算出的新的PA值。
如表2,分为四种情况,如果源服务器与目的服务器在同一子网,则PA为原PA值;如果在同一pod 中,则需要对对边缘交换机的上行端口进行轮询;如果在不同pod,则根据聚合层交换机的上行端口号是否为边界值分两种情况进行端口的轮询操作。

表2 RR_M地址轮询取值表
5.2 大流处理
大流处理作为整个负载均衡算法的核心部分,不仅包含将大流拆分成多个小流,更重要的是对流做全路径计算和路径寻优。当一条大流达到时,按每个小流最大64 KB 来切分成多个小流并对每个小流分配最优的转发路径。其中路径寻优算法采用“动态规划”的思想,保证所选路径能够在有效时间内为最优的路径。
5.2.1全路径计算
大流处理过程中,路径寻优模块需要对多路径进行路径拥塞程度探测,因此首先要先得到这些可能的发送路径并存储到大流轮询表中RR_E 中。为了快速的计算出所有的路径,本文提出了一种全路径的计算算法,如算法1。
算法1 全路径计算算法
输入:source locator and destination locator
输出:the path array P of from source to destination
1. ifs0=d0then
2. ifs1=d1then
3.p[0]←{0,d2}
4. else
5. fori=k/2 →kdo
6.p[i-k/2]={0,i,d1,d2}
7. end if
8. else
9.index←0
10. fori=k/2 →kdo
11. forj=k/2 →kdo
12.p[index+ +]←{0,i,j,d0,d1,d2}
13. end if
14. returnp
如算法1所示,当“源”服务器和“目的”服务器在同一个子网时,路径是唯一确定的。当不在一个子网内时,所求路径会根据数据中心网络的交换机端口个数k动态计算。
5.2.2 路径寻优
路径寻优算法采用了“消息反馈”机制,对所有可能发送的路径进行探测处理,然后对所有反馈的探测包的往返时延进行排序处理。在这里排序策略采用的是“大顶堆”的堆排序的思想,当交换机端口数量k大到一定程度时,使用堆排序可以更好地提高排序性能。此外,大流切分为多个子流的数量要远小于全路径的数量,因此使用堆排序的思想还可以根据不同的交换机端口数灵活的设置“大顶堆”的节点数。具体的路径寻优算法如算法2。
算法2 路径寻优算法
输入:source locator,destination locator and path arrayp
输出:the new path arrayPof from source to destination after sort
1. ifs0=d0then
2. ifs1=d1then
3.probePath[0]←{0,d2}
4. else
5. fori=k/2 →kdo
6.probePath[i-k/2]←{0,i,d1,i,s1,s2}
7. end if
8. else
9.index←0
10. else
11. fori=k/2 →kdo
12. forj=k/2 →kdo
13.probePath[index+ +]←{0,i,j,d0,d1,i,j,s0,s1,s2}
14. end if
15. Send allprobePacketwithprobePath
16. Collect all RTT and sortpwith RTTs
17. returnp
6 仿真实验及分析
6.1 仿真环境及评价指标
本文在OMNET++软件上进行实验的仿真。OMNET++是一款强大的网络仿真工具,利用它可以构建包括交换机、链路和主机在内的数据中心网络[18]。本文实验搭建的网络环境为16-port的Fat-tree数据中心网络,共包含了1 024台服务器与320台交换机,其中交换机包括了64 台核心交换机;128 台汇聚层交换机及128台边缘交换机。整个Fat-tree网络拓扑包含了16个pod,每一个pod包含了8台汇聚层交换机;8台边缘层交换机和64 台服务器。本文提出的VSLB 算法将与基于端口编址的ECMP(Port-Base ECMP、PB-ECMP)与基于端口编址的CONGA(Port-Base CONGA、PB-CONGA)方法进行对比,仿真结果将从平均吞吐量、小流的平均流完成时间和平均端到端时延三个方面进行评估。具体计算如下:
(1)平均吞吐量
采用单个可用服务器多次仿真的平均吞吐量。假设仿真时可用服务器为n个,进行了m次的仿真,则平均吞吐量的计算公式如公式(1)所示:

其中ATj为第j次仿真的平均吞吐量,ATj的计算如公式(2)所示:

其中Ti为第i个服务器的吞吐量,通过统计平均吞吐量,由此作为评价网络性能的一项指标。平均吞吐量越大,说明数据中心网络的整体性能越好,进而说明负载均衡方法越高效。
(2)小流完成时间(Flow Complete Time)
小流FCT值取多个服务器的多个小流的平均值,假设仿真时可用服务器为n个,第i(1 ≤i≤n)个服务器在一次仿真中接收了s条小流数据,共进行了m次仿真,则FCT的计算公式如公式(3)所示:

其中tj为第j此仿真的平均流完成时间,tj的计算如公式(4)所示:

其中tk为第k个小流的流完成的时间,小流的FCT 作为评估数据中心网络的性能指标,如果负载均衡方法没有很好地解决大流碰撞问题,则大流造成的网络阻塞问题同时会影响小流的传输性能,故当FCT 值越小,负载均衡方法越好。
(3)平均端到端时延(End-to-end Delay)
数据中心网络在一定周期内会产生很多的数据流,而从网络层看来,这些都是大量的数据包,平均端到端时延就是计算数据包发送时延的平均值,假设可用服务器依然为n个,做m次仿真,第i台服务器接收的数据包为s个,则:

其中τj为第j此仿真的平均时延,τj的计算如公式(6)所示:

其中ti为第i台服务器的平均时延,ti的计算如公式(7)所示:

大量的数据包如果遇到了大流碰撞引起的链路带宽问题,会产生长时间的阻塞,所以当平均端到端时延越小,则说明负载均衡的效果越好。
6.2 实验参数设置
由于目前很难获得实际可用的数据中心网络的trace数据集,本文参考文献[19]的思想,通过模拟多种通讯模式的方式来模拟实际的数据中心网络。通讯模式主要分为两大类,分别是One_To_One和Multi_To_Multi 模式,其中这两类又分别包含了Stride、incoming、outgoing、Random 模式。具体模式如下,其中服务器位置标识为(s0,s1,s2),s0(s0∈[0,k-1])代表该服务器所在的pod 编号,s1(s1∈[0,k/2-1])代表该服务器所在pod 中与其相连的边缘交换机的编号,s2(s2∈[0,k/2-1])代表该服务器是边缘交换机连接的第几个服务器,k代表该数据中心网络的交换机端口数。
(1)One_To_One通信模式
Stride:每台服务器(s0,s1,s2)向服务器((s0+1)modk,s1,s2)进行通信。
Same-pod incoming:多个 pod 的任意k24 台服务器向集中向一个pod 中的k24 台服务器进行随机的一对一通信。
Same-pod outgoing:一个 pod 中的k24 台服务器随机的向其他任意pod 中的k24 台服务器进行一对一通信。
Random:整个拓扑中k34 台服务器随机挑选一个服务器对象进行一对一通信。
(2)Multi_To_Multi通信模式
Stride:每台服务器(s0,s1,s2)向pod((s0+1)modk)中的k24 台服务器分别进行通信。
Same-pod incoming:多个 pod 的任意k24 台服务器分别向一个pod中的k24 台服务器进行通信。
Same-pod outgoing:一个pod中的k24 台服务器分别向其他任意pod中的k24 台服务器进行通信。
Random:整个拓扑中k34 台服务器分别向其他k34 台服务器进行通信。
具体模式参数设置如下:
(1)One_To_One通信模式下,链路宽带和时延初始化值分别设置为1 024 Mb/s和0.05 μs,单周期内任意服务器随机产生的大流和小流的个数比为1∶4,大流与小流总的大小比为4∶1,从而保证了大流始终占有80%左右的带宽。每个周期的时间根据随机产生的流的个数和大小而发生变动,仿真次数设定在10~20次。
(2)Multi_To_Multi模式下,服务器和边缘交换机之间的链路带宽初始初始化值设置为16 Mb/s,其他参数同One_To_One模式,为了实现流量突发性,参照实际数据中心网路,仿真过程中随机产生同一个服务器发往不同目的服务器的时间差值。
6.3 实验结果分析
(1)One_To_One
图 3、图 4 和图 5 为 One_To_One 模式下,VSLB 和PB-ECMP 和PB-CONGA 在不同指标值下的实验结果对比图。

图3 One_To_One平均吞吐量对比图

图4 One_To_One小流FCT对比图

图5 One_To_One端到端时延对比图
根据图3、图4、图5 可以看出,不论是在Stride、Incoming、Outgoing,还是在 Random 模式下。VSLB 在吞吐量、小流完成时间及时延方面均优于PB-ECMP 和PB-CONGA。这是由于VSLB 对大流进行了“细粒度”的划分处理,并且还通过路径寻优的策略大大减少了大流碰撞的概率。相比于CONGA,VSLB 不需要总是接受链路的反馈包,只有在进行大流处理时,才需要进行链路探测,因此交换机不需要解析数据包来维护转发表。另一方面VSLB中利用了端口编址的方法,使得交换机不需要参与转发决策,只进行包转发操作即可,大大加快了数据包的转发效率。因此VSLB 在性能上都优于PB-ECMP与PB-CONGA。
(2)Multi_To_Multi模式
图6、图7和图8为Multi_To_Multi模式下,VSLB和PB-ECMP在不同指标值下的实验结果对比图。
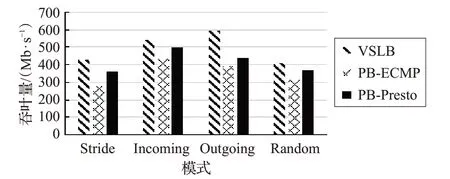
图6 Multi_To_Multi平均吞吐量对比图

图7 Multi_To_Multi小流FCT对比图

图8 Multi_To_Multi端到端时延对比图
根据图6、图 7、图 8 可以看出,在Multi_To_Multi 模式下,四种子模式的各个结果都与One_To_One 模式有所差别。这是因为在Multi_To_Multi模式下,每台服务器都会以一对多的方式发送数据,因此会有更多的流碰撞现象发生。但从以上图中可以看出,VSLB的性能也明显优于PB-ECMP和PB-CONGA。
7 总结
本文针对“大流碰撞”提出了一种基于Fat-Tree的虚拟分片负载均衡算法。通过对大流进行“细粒度”的分片处理,并对切片后的子流进行路径寻优处理,大大降低了“大流碰撞”的概率。通过实验对比,验证了VSLB相比于ECMP 与CONGA 能够大大提升数据中心网络性能。
随着研究的逐渐深入,发现还有许多工作值得后续的关注和研究。由于本文所提出的负载均衡方法更偏向于对大流的处理,因此小流处理部分相对比较简单,未来的工作将针对小流处理模块提出更好的解决方法。
