结合注意力机制和句子排序的情感分析研究
2020-07-06刘发升徐民霖邓小鸿
刘发升,徐民霖,邓小鸿
1.江西理工大学 信息工程学院,江西 赣州 341000
2.江西理工大学 应用科学学院,江西 赣州 341000
1 引言
随着计算机技术的发展,电商等平台的出现愈演愈烈,而人们对该平台的依赖性也越来越强,人们不断地使用电商来购买物品,并对物品的质量等提出自己的意见。在这种情况下,文本数据呈现出爆发式的增长,人工操作难以提取出有效的情感信息。因此,在众多的文本数据中,如何有效地提取出情感信息变得尤为重要。
情感分析是指使用自然语言处理和文本分析等技术自动的提取或分类出某些评论的情感极性。一般的情感分析方法有基于情感词典的情感分析方法[1]和基于机器学习的情感分析方法[2],但在大量的数据处理需求下,两种方法都显得有所欠缺。在这种情况下,深度学习方法[3-4]逐渐浮出水面,其有着很强的泛化能力,并且能够自动提取特征,轻松处理海量的数据。深度学习方法主要致力于如何改进模型和对模型的输入进行优化以提高情感分类效果。Yang 等人[5]利用网络术语和维基中文数据集扩展原始词汇,并根据句子的长度对CNN(卷积神经网络)的池化层进行优化实现了情感分析任务。Hyun 等人[6]提出一种依赖于目标的卷积神经网络方法(TCNN),利用目标词与邻近词之间的距离信息来学习每个单词对目标的重要性,达到了较好的分类效果,但其未考虑文本的上下文依赖关系。AI-Smadi等人[7]将RNN(循环神经网络)与支持向量机在相同的数据集上进行了比较,结果显示RNN 在运行速度和二次任务上取得了优势。RNN虽然能够获得上下文依赖关系,但是会出现梯度消失或梯度爆炸的问题,而LSTM(长短期记忆网络)利用记忆单元和门机制很好地解决了该问题。Tang 等人[8]提出了两个依赖目标的LSTM 模型,该模型能够自动的考虑目标信息,取得了较好的分类效果。Tai等人[9]提出一个2-layer LSTM模型,在相同的时间步中,将第一层LSTM 中的隐藏状态作为第二层LSTM的输入,让第二层LSTM捕捉输入序列的长期依赖性,进行情感分析任务,但其未考虑文本的局部特征和输入的优化。Wang等人[10]提出一个堆叠残差的LSTM 模型,在每个LSTM 层引入残差连接,构造了一个8 层的神经网络进行情感分析任务。Xu 等人[11]提出了一个高速缓存的长短期记忆网络(CLSTM)捕获长文本中的全局语义信息,其引入一种缓存机制,将内存划分为几个具有不同遗忘率的组,从而使网络能够在循环单元内更好的保持情感信息,并在3个数据集上取得了明显的效果,但其未考虑文本的后向语义信息和输入优化。Shuang 等人[12]提出一个基于神经网络的情感信息收集-提取器(SICENN),包含一个情感信息收集器(SIC)和一个情感信息提取器(SIE),SIC 由BiLSTM(双向长短期记忆网络)构成,用来收集句子中的情感信息并生成信息矩阵。SIE 将信息矩阵作为输入,并通过3 个不同的子提取器精确地提取情感信息,并且应用新的结合策略来组合不同子提取器的结果,且在多个数据集上取得了较好的分类结果,但其未考虑输入的优化。Zhang等人[13]提出两种基于注意力的神经网络,分别为内部注意力模型和外部注意力模型,通过自动评估词之间的相关性来得到更好的话语表达,得到了明显的效果。Song 等人[14]提出一种基于注意力机制的LSTM网络情感词典嵌入方法用于情感分析任务,但其未考虑文本的双向语义信息和输入优化。随着情感分析的深入研究,图神经网络也逐渐被应用在该领域。Yao等人[15]基于单词共现和文档单词关系为语料库构建单个文本图,然后为语料库学习文本图卷积网络(Text GCN)。该模型利用one-hot词表示对文本进行初始化,并且共同学习单词和文档的嵌入。Peng 等人[16]研究基于图长短期记忆网络(graph LSTMs)的关系提取框架,其可以很容易地扩展到跨句子n元关系提取。图形公式提供了一种探索不同LSTM 方法并结合各种句内和句间依赖关系的统一方法,能够利用相关关系进行多任务学习。
针对上述文献的不足,本文主要工作如下:
(1)利用情感词典对文档数据集进行优化,使模型尽可能捕获到更多的情感信息。
(2)将CNN、BiLSTM模型与注意力机制进行融合,充分考虑文本的局部特征和上下文特征,由于模型确定了文档数据中句子的具体数量,所以不仅能够处理长文本序列并且能够处理较短的文本序列和捕获更多的词与词之间、句子与句子之间的语义信息。
(3)融合CNN、BiLSTM模型和注意力机制,并结合优化的输入,提出一个结合注意力机制和句子排序的双层CNN-BiLSTM模型(DASSCNN-BiLSTM),该模型可以对句子之间的语义信息进行编码,提升情感分析精度。
2 相关知识介绍
2.1 CNN(卷积神经网络)
CNN 的提出源于生物中感受野这一概念,是一个典型的前馈神经网络,起初CNN 被运用在计算机视觉领域,随后因CNN强大的特性,逐渐被运用在了各个方面,其中则包括了NLP(自然语言处理)领域。CNN 可以在无需人为干预的情况下自动的学习到文本的隐藏特征进行情感分析任务,也可将学习到的特征作为其他模型的输入进行更加精准的分类。CNN相对于传统的神经网络具有明显的优势,因其采用局部连接、权值共享的方式大大的减少了传统神经网络因采用全连接方式所带来的网络参数巨大,训练时间长等问题,并且使用下采样的方式更加精准的抓取了文本的主要特征和进一步地缩小了网络维度。通常情况下,CNN 包含了卷积层和池化层,如图1所示。
(1)卷积层
该层主要目的是通过固定大小的卷积核对输入的特征矩阵进行卷积操作,得到新的特征矩阵。给定x1,x2,…,xn为句子d所对应的嵌入向量,将嵌入向量x1,x2,…,xn输入该层,通过卷积操作得到序列y1,y2,…,yn-h+1,如式(1)所示:
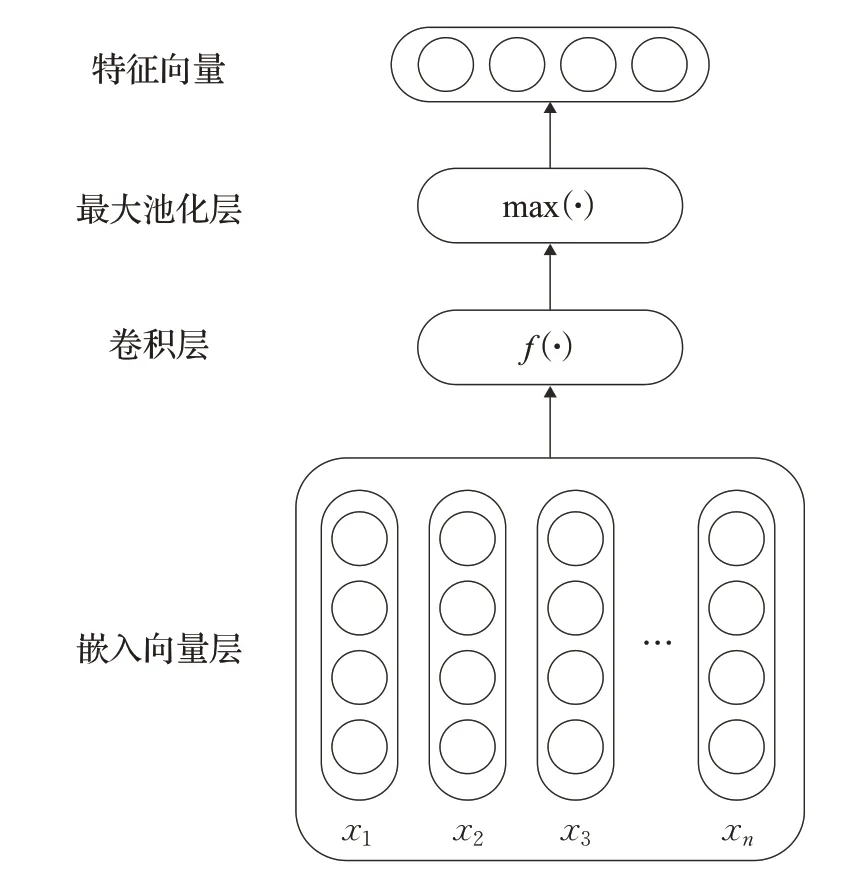
图1 卷积神经网络

其中xi:i+h-1指的是向量xi,xi+1,…,xi+h-1的结合,h是卷积核的维度大小,f(⋅)是非线性激活函数tanh(x)=W是权重矩阵,b是偏置向量,由训练获得。
(2)最大池化层
卷积神经网络中的池化层一般包括两种,分别为平均池化层和最大池化层,本文使用的是最大池化层。将卷积层输出的序列y1,y2,…,yn-h+1输入该层,不仅获取到文本的主要特征,且降低了向量维度,减少训练复杂度,最终得到固定维度大小的向量,如式(2)所示:
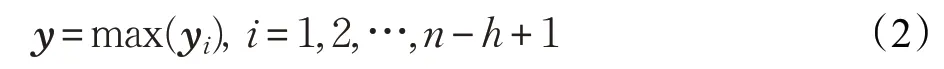
2.2 LSTM(长短期记忆网络)
LSTM是一个循环神经网络,通过利用细胞状态和门机制修改了RNN 的tanh 层,使其能够记忆上一步的信息,并融合当前的信息向下一步传输,解决了RNN所存在的梯度消失和梯度爆炸问题,如图2所示。
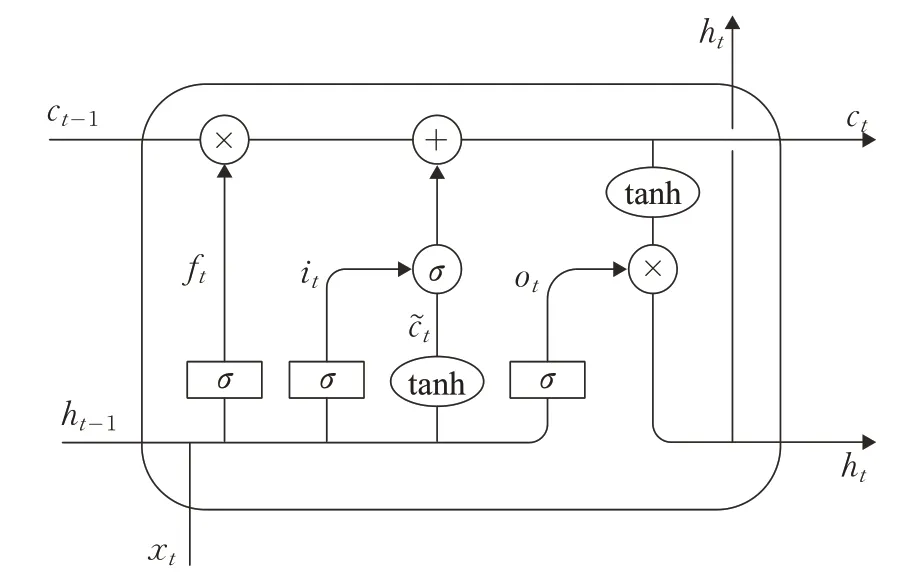
图2 长短期记忆网络
LSTM运行机制如式(3)~(8)所示:
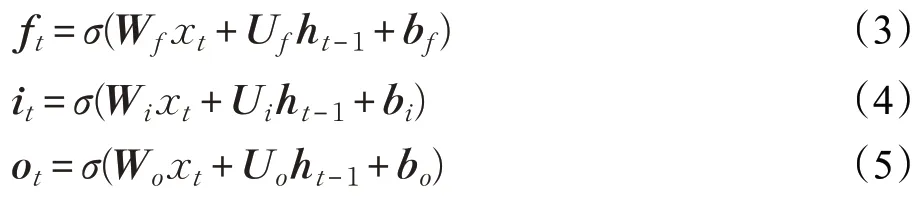
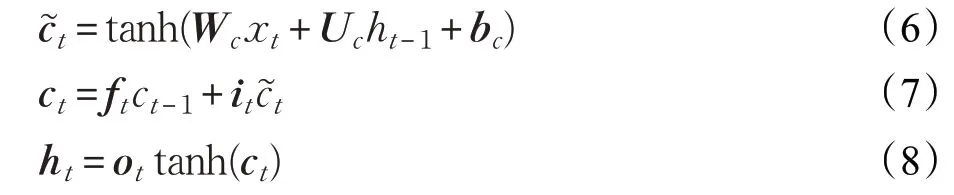
其中i、o、f分别代表着门机制内的输入门、输出门、遗忘门,c是记忆细胞,在t时刻,网络接收到当前输入向量xt和t-1 时刻遗留的隐藏向量ht-1作为3 个门机制的输入,it、ot、ft分别为输入门、输出门、遗忘门在t时刻所得到的激活向量。σ是指非线性激活函数tanh 是非线性激活函数Wf,Wi,Wo,Wc和Uf、Ui、Uo、Uc分别是遗忘门、输入门、输出门和细胞状态所对应的权重矩阵,bf,bi,bo,bc是偏置向量,由训练获得。
3 结合注意力机制和句子排序的双层CNNBiLSTM模型(DASSCNN-BiLSTM)
本文结合了CNN、BiLSTM 和注意力机制,提出一个双层的情感分析模型,能够捕获句子之间的语义信息,且利用情感词典优化模型输入,使模型能够处理不同长度的文档数据,进一步提升模型的效率,具体如图3所示。
众所周知,文档包含了一系列句子,句子包含了诸多词语,句子的意义由词语和词语之间的语义规则形成,而文档的意义则由诸多句子组成。通过Word2vec对文档中所有的词进行预训练,将每个词表征为低维度向量,并将其堆放在一起,形成每个句子所对应的词嵌入矩阵Sw∈Ra×|V|,其中a指的是词嵌入维度,| |V指的是词汇的大小,之后利用情感词典对其进行优化,作为本文模型第一层的输入。由于CNN能够抓取文本的局部特征,LSTM每一步输入都是上一步的输出和当前步输入的结合,能够充分的捕获文本的语义依赖性,所以能够利用CNN和BiLSTM生成本文所述的连续句子表示,之后连接两个句子表示生成全局句子表示,作为第二个BiLSTM 层的输入,并且利用注意力机制,更加精确的捕获句子特征,生成文档表示,进行最终的情感分类任务。
3.1 模型输入的优化
使用NLP管道将句子分成词和短语,并对词性进行标记,该方法的优势在于简单并且工作量小。判断一个句子的情感极性通常是比较句子中情感词的数量,如果积极的词比消极的词更多,那么句子就判定为积极的,反之亦然。另外一种方法就是利用句子中的词和短语,计算它们的情感分数来判定句子的情感极性,本文使用的是第二种方法。该方法相对于传统的机器学习和神经网络方法,未考虑词与词之间、词与句子之间的语义信息,所以并不适合用于文档级的情感分类任务,但是用于句子级别的情感分类还是可以接受的。
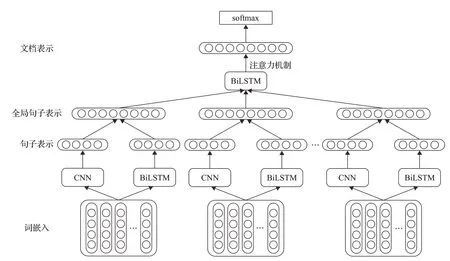
图3 结合注意力机制和句子排序的双层CNN-BiLSTM模型
为了提升情感分类的效果,本文定义Max为每个文档中句子的最大数量,若文档中句子数量超过了Max,则去除一部分句子,使句子的数量达到输入的要求。若文档中句子的数量少于Max,则使用0 对其进行补充。值得注意的是,当句子数量大于Max,对文档末尾的句子进行去除时,被去除的句子中可能包含了文档的主要信息,这样会错过重要的语义信息。基于这样的情况下,本文在不改变句子顺序的条件下,根据情感极性对其进行排序处理。
为了判断句子的情感极性,本文首先使用上述的方法将句子分为词和短语,并用情感词典SentiWord-Net3.0得到每个词的情感分数,短语的情感分数则是通过将所有相同单词同义词的情感值平均化获得。如果有副词存在,则将短语的情感分数乘以一个权重。然后将所有部分的得分求和,得到句子的情感分数。正数代表积极,负数代表消极,并且将分数的绝对值用来作为句子排序的依据。
最终,若文档中的句子数量大于Max,则根据上述方法取得情感极性强的Max 个句子,作为DASSCNNBiLSTM 模型的输入,若文档中的句子数量少于Max,则将空余部分补0,作为模型的输入。
3.2 CNN句子表示的生成
将上述优化的文档句子d通过Word2vec 编码成x1,x2,…,xn作为该部分的输入,且使用多个不同大小的卷积核对其进行卷积处理生成卷积序列yi(i=1,2,…,n-h+1),其中h指的是卷积核的维度。然后,经过最大池化层得到句子表示y=max(yi)。
3.3 BiLSTM句子表示的生成
BiLSTM 是双向LSTM 的合成,相对于传统的LSTM,其不仅掌握了前向语义信息,也掌握了后向语义信息,更加充分地捕获了文本的上下文信息,具体如图4所示。
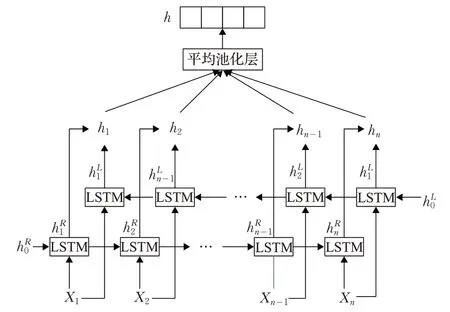
图4 双向长短期记忆网络
将词嵌入x1,x2,…,xn作为输入,通过前向LSTM和后向LSTM分别获得了hL和hR,如式(9)和(10)所示:

之后连接hL和hR获得隐层向量hi(i=1,2,…,n) ,最后通过平均池化层获得最终的句子表示h,如式(11)所示:

3.4 文档表示的生成
该部分由BiLSTM和注意力机制构成,充分的抓取了文档句子之间的语义信息。注意力机制来自于人类的视觉注意力,人类在看事物时,总是会把注意力集中在某一点上,以便在众多的事物中获取更加关键的信息。对于一个文档,每个句子的贡献都是不同的,有的句子占有更多的语义信息,有的句子则占有较少的语义信息,基于此,本文引入了注意力机制,为每个句子表示都赋予一个注意力权重,使得模型能够注重更加关键的语义信息,具体如图5所示。
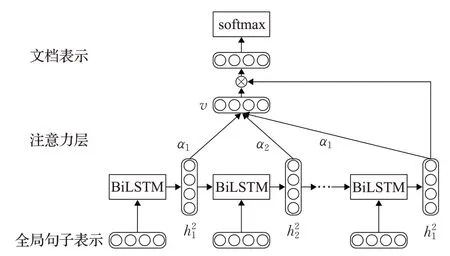
图5 基于注意力机制的BiLSTM模型
连接上述由CNN 和BiLSTM 所生成的句子表示得到全局句子表示SG=[y,h] 作为该部分的输入,得到BiLSTM隐层向量并结合注意力机制得到文档表示D,如式(12)~(15)所示:
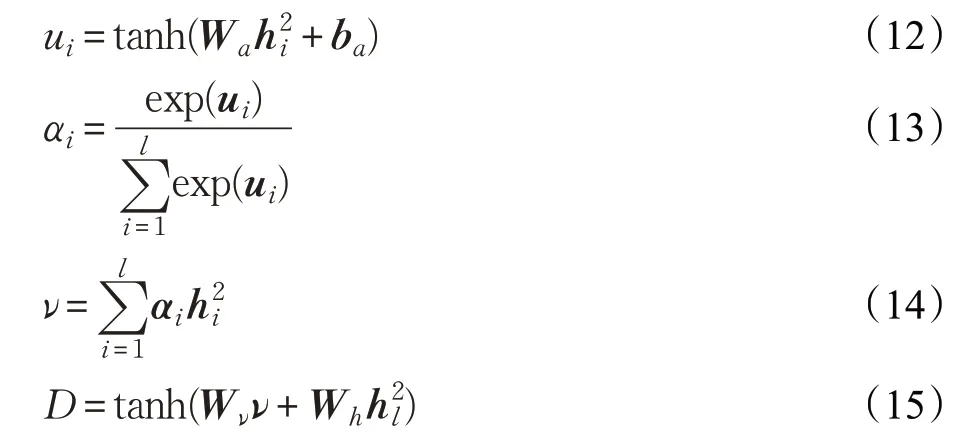
3.5 模型训练
本文使用有监督学习对模型进行训练,训练目标为最小化负对数似然函数,损失函数为交叉熵函数,且加入L2正则化,防止训练过拟合,如式(16)所示:
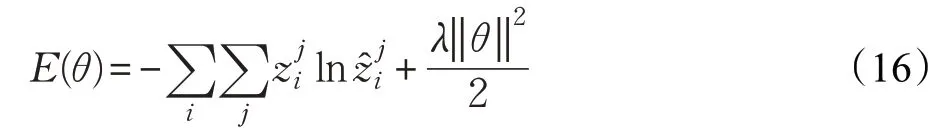
其中,z为文档的目标分类,ẑ为文档的预测分类,i为文档的索引,j为类别索引,λ是正则化参数,θ是参数集合。
且采用反向传播算法和随机梯度下降法[17]计算参数θ,如式(17)所示:

其中η为学习率,t为时间步。
4 实验结果与分析
4.1 数据集
本文采用 IMDB[18]、Yelp 2014[11]和 Yelp 2015[19]数据集对模型进行多分类实验,IMDB是大型的电影评论数据集,共84 919,Yelp2014和Yelp 2015是餐馆评论数据集,分别为231 163 和243 353,且将三个数据集按照80%、10%和10%的比例分成训练集、验证集和测试集,其中IMDB 数据集的训练数、验证数和测试数分别为67 426、8 381和9 112,平均每个文档中句子数为16.08,单词数为394.6,分为1到10级。Yelp 2014数据集的训练数、验证数和测试数为183 019、22 745和25 399,平均每个文档中句子数为11.41,单词数为196.9,分为1 到5级。Yelp 2015 数据集的训练数、验证数和测试数为194 360、23 652和25 341,平均每个文档句子数为8.97,单词数为151.9,分为1 到5 级。每个级别的数据量相同,即数据集 IMDB、Yelp2014 和 Yelp2015 中的数据平均分为10、5和5个级别,训练集、验证集和测试集同理。
4.2 评价标准
本文使用精度(accuracy)和均方误差(Mean Squared Error,MSE)作为评价标准。精度是衡量整体情感分类结果的标准指标,即文本正确分类的比例,值越大结果越好。均方误差用来衡量真实分类和预测分类之间的差异,值越小说明分类结果越好,如式(18)所示:

其中,zj为真实分类为预测分类,j为类别索引,N为类别数。
4.3 模型参数设置
(1)本文利用谷歌开源的Word2vec训练词向量,词向量维度为300,CNN部分使用卷积核大小分别为3、4、5,卷积核数量为150,BiLSTM 部分隐藏层向量维度为120,学习率为0.01.对于IMDB、Yelp 2014和Yelp 2015数据集,批尺寸分别为128、64和64。
(2)对于本文中所提及的文档中最大句子数量,根据平均每个文档中的句子数分别设置为22(IMDB)、14(Yelp2014)和13(Yelp2015)。
(3)对于模型的初始化,本文使用均匀分布[−0.1,0.1]随机初始化所有参数矩阵,并使用随机梯度更新所有参数。
参数具体情况如表1所示。

表1 参数设置
4.4 模型对比实验
将本文提出的DASSCNN-BiLSTM模型与RNN[20]、LSTM[21]、BiLSTM[20]、2-layer LSTM[9]和 CLSTM[11]模型在IMDB、Yelp 2014和Yelp 2015三个数据集上进行了对比,并且与本文模型的变体模型DASCNN-BiLSTM进行了对比。
模型对比方法参数设置如表2所示。
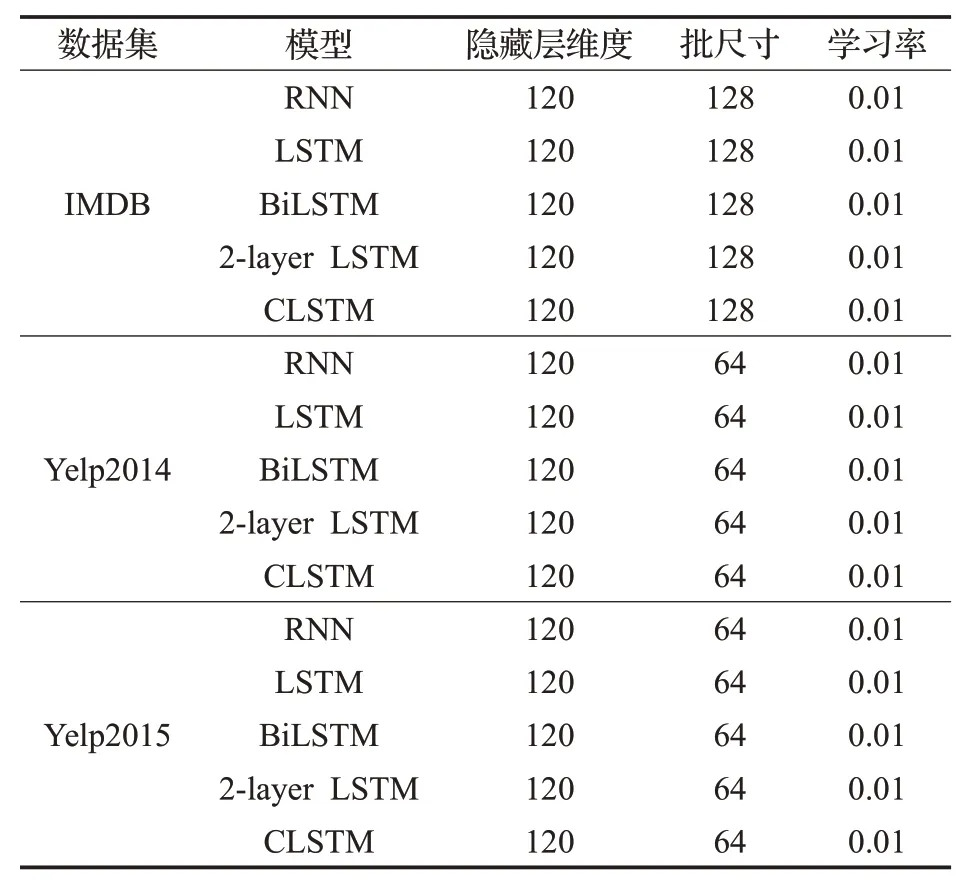
表2 对比模型参数设置
(1)RNN:典型的循环神经网络,能够捕捉文本的上下文依赖关系。
(2)LSTM:RNN模型的变体,通过门机制和细胞状态,对RNN 的tanh 层进行了改进,解决了RNN 模型存在的梯度消失或梯度爆炸问题。
(3)BiLSTM:双向LSTM 的结合,单纯的LSTM 只能够捕捉文本的前向语义信息,而BiLSTM模型能够同时捕捉文本的前向语义信息和后向语义信息。
(4)2-layer LSTM:在相同的时间步中,将第一层LSTM中的隐藏状态作为第二层LSTM的输入,让第二层LSTM捕捉输入序列的长期依赖性。
(5)CLSTM:引入了一种缓存机制,将内存划分为几个具有不同遗忘率的组,从而使网络能够在循环单元内更好地保持情感信息。
(6)DASCNN-BiLSTM:本文提出DASSCNN-BiLSTM 模型的变体,使用未经过情感词典优化的文档数据作为输入。
如表 3、表 4 和表 5 所示,在 IMDB 数据集下的分类精度明显低于Yelp2014 和Yelp2015 的分类精度,原因在于IMDB 数据集分为10 类,而Yelp2014 和Yelp2015分为5类,分类的难度随着类别数的增加而增加。且在三个数据集下,RNN 的分类结果相对于LSTM 明显较差,原因在于RNN 在较长文本中产生了梯度消失或爆炸的问题,欠缺足够的长文本特征捕获能力,而LSTM弥补了该问题,提升了较长文本特征捕获能力。BiLSTM的分类效果略好于LSTM,原因在于其同时捕获了文本的前向语义和后向语义信息,相对于LSTM,提取了更多的语义信息。2-layer LSTM 在IMDB 数据集中精度为0.401,MSE为3.18,在Yelp2014中精度为0.613,MSE为 0.51,在 Yelp2015 中精度为 0.625,MSE 为 0.45,分类效果明显优于LSTM 在三个数据集中的0.398、3.21,0.610、0.57 和0.617、0.55,原因在于利用了双层LSTM,提取了更多的文本特征,证明了多层LSTM 的有效性。CLSTM则因为利用了缓存机制,通过不同的遗忘率,得到了更好的分类效果。在Yelp2015 数据集中,BiLSTM的分类效果和2-layer LSTM、CLSTM 几乎一致,而在IMDB和Yelp2014中,BiLSTM的分类精度和MSE分别为 0.432、2.21 和 0.625、0.49,2-layer LSTM 的分类精度和MSE分别为0.401、3.18和0.613、0.51,CLSTM的分类精度和 MSE 分别为 0.429、2.67 和 0.624、0.49,BiLSTM的分类效果明显高于二者,原因在于对前后向语义信息的捕获,进一步证明了捕获文本前后向语义信息的有效性。
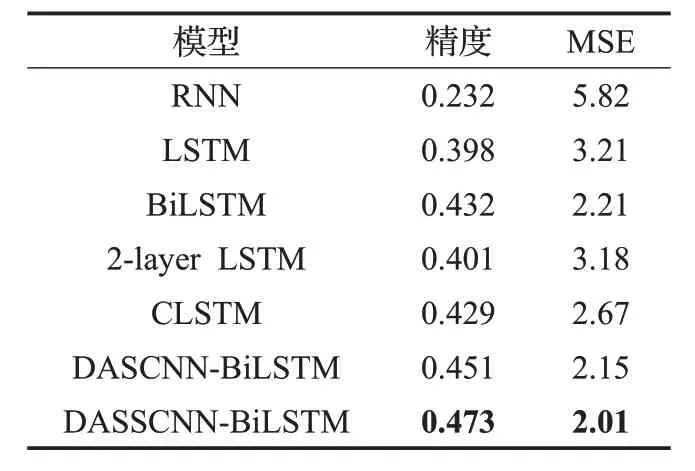
表3 在IMDB数据集下模型对比结果
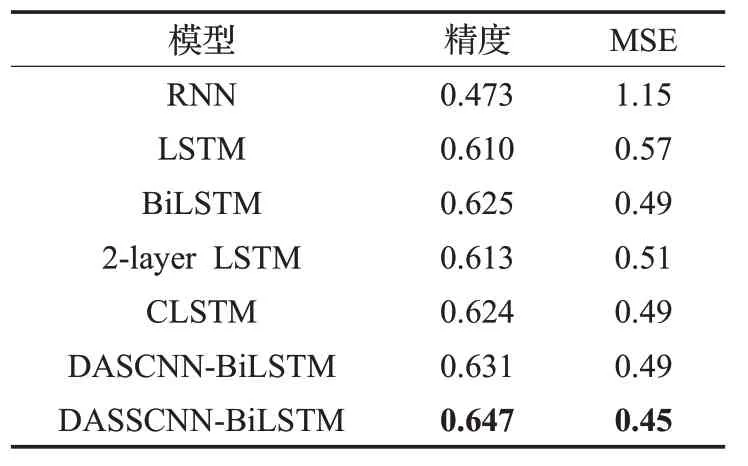
表4 在Yelp 2014数据集下模型对比结果
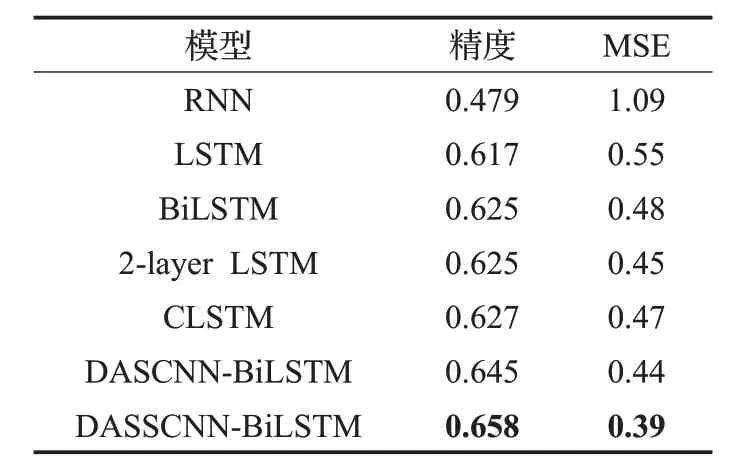
表5 在Yelp 2015数据集下模型对比结果
在本文提出的模型中,变体模型DASCNN-BiLSTM在 IMDB 中,分类精度达到了 0.451,MSE 为 2.15,在Yelp2014 中,分类精度达到了 0.631,MSE 为 0.49,在Yelp2015 中,分类精度达到了0.645,MSE 为0.44,分类效果明显优于上述所有模型,原因在于其不仅利用BiLSTM 获取了文本的上下文依赖关系,也通过CNN获取了文本的局部特征,且利用2 层架构,获取了句子之间的语义关系,并利用注意力机制进一步的捕获了文本特征。
由于本文提出的最终模型(DASSCNN-BiLSTM)利用了情感词典对模型输入进行了优化,在IMDB、Yelp2014 和Yelp2015 数据集中,分类精度与 MSE 分别为0.473、2.01,0.647、0.45 和0.658、0.39,分类效果优于DASCNN-BiLSTM,证明了DASSCNN-BiLSTM 模型能够更好的用于文档级情感分析任务。
本文还对不同大小的Max 值所产生的结果进行了精度对比,如图6、7和图8所示。
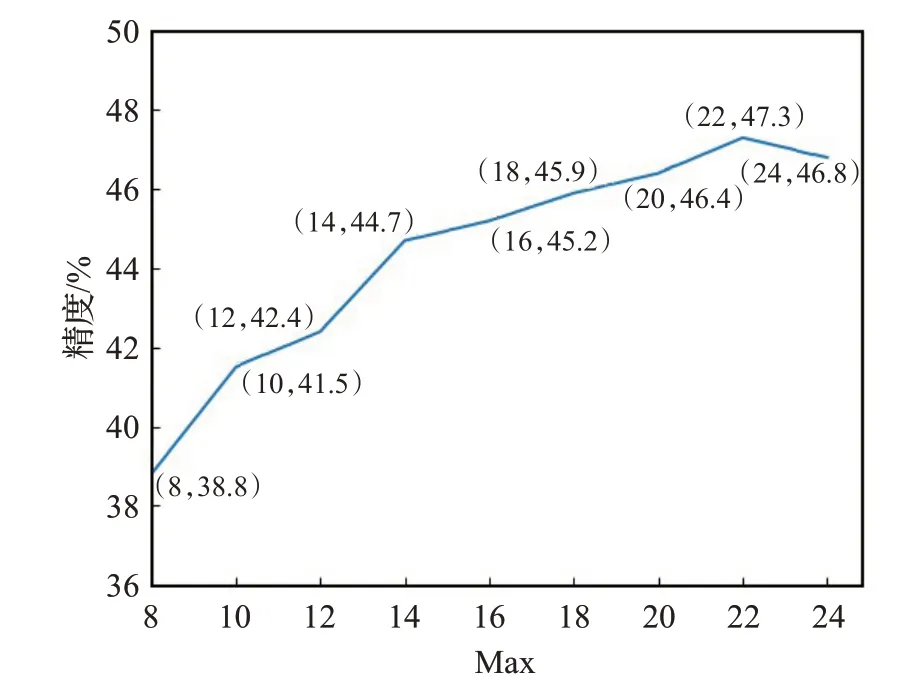
图6 不同Max结果比较(IMDB)
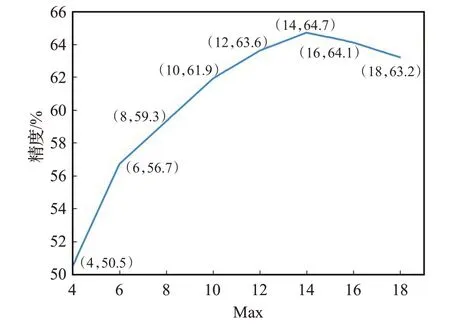
图7 不同Max结果比较(Yelp2014)
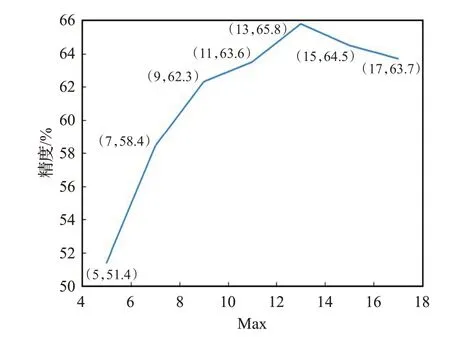
图8 不同Max结果比较(Yelp2015)
如图6、7和8所示,在IMDB数据集下,分类精度随着Max的增大逐步增高,8到16这一段尤为明显,之后增加幅度降低,直到Max为22时,达到最高。在Yelp2014数据集下,分类精度在4 到10 这段提升尤为明显,之后略有减少,且当Max为14时,达到最高。在Yelp2015数据集下,分类精度在5到9这段提升尤为明显,且当Max为13 时,达到最高。原因在于,当Max 过小时,文档中包含的句子数过少,所提取的特征信息过少,而当Max增大时,特征信息越来越多,分类精度也随之增加。由此可见,本文所选择的Max数值是合理的。
5 结束语
为解决传统深度学习作文本情感分析未充分考虑文本特征和输入优化的问题,本文提出结合注意力机制和句子排序的双层CNN-BiLSTM 模型(DASSCNNBiLSTM)做文本情感分析,利用情感词典对输入进行优化,并利用CNN、BiLSTM 和注意力机制生成句子表示和文档表示。实验表明,本文提出的DASSCNNBiLSTM 模型对文本情感分析具有较好的可行性和有效性。未来的工作,将致力于如何进一步提升模型的分类效果以及如何将其运用在其他的NLP任务中。
