基于BERT模型的中文舆情文本分类应用
2020-07-04谢剑辉
谢剑辉


摘 要:BERT、ULMFiT等模型均采用了预训练联合微调的架构,能够更深刻的解读语句内涵,其在微调整阶段表现出快捷、有效等特征,且模型的泛化性进一步增强,逐渐演变成自然语言处理领域中的最强、最新颖模型。文章在介绍BERT模型的基础上,基于简易的迁徙学习策略,将该模型用于中文舆情文本分类领域中,在比较中证实BERT模型的优越性。
关键词:文本分类;BERT;网络舆情
在很长的一段时间内,自然语言处理(NLP)为人工智能領域中研究的重点、热点,其面对的是繁杂多变的自然语言,希望基于精致的数学模型深度解读语句内涵,进而实现人和机器之间的自然交互。2018年年末,谷歌团队对外发布了以双向Transformer预训练语言模型(BERT),通过查阅相关文献资料后发现[1],BERT用于中文NLP的研究处于早期探索阶段,舆情数据类别划分是该领域研究的热点之一,若能利用一种较科学、完善模型,微调现存模型,则可早短期能提升对任务运作需求的适用度,优化研究工作质量。本文主要探究BERT模型在舆情文本分类任务执行中的训练成效。
1、 BERT模型介绍
从本质上分析,BERT语言模型就是 Transformer 模型的编码器部分。于在BERT的论文内,科研人员共计训练了两个BERT模型,即BERTBASE和BERTLARGE,参数量不同是以上两个模型的主要区别,前者持有12个多头自注意力层(L=12),各层均分布12个头(A=12)中间向量维度768(H =768);参数量有110M。BERTLARGE有24个多头自注意力层(L=24)各层有16个头(A= 16),中间向量维度是1024(H = 1024),参数量340M。既往在诸多测试中,BERTLARGE的结果均优于BERTBASE,这提示在预训练任务和模型结构等同时,参数提高取得的成效是极为显著的。
1.1输入处理
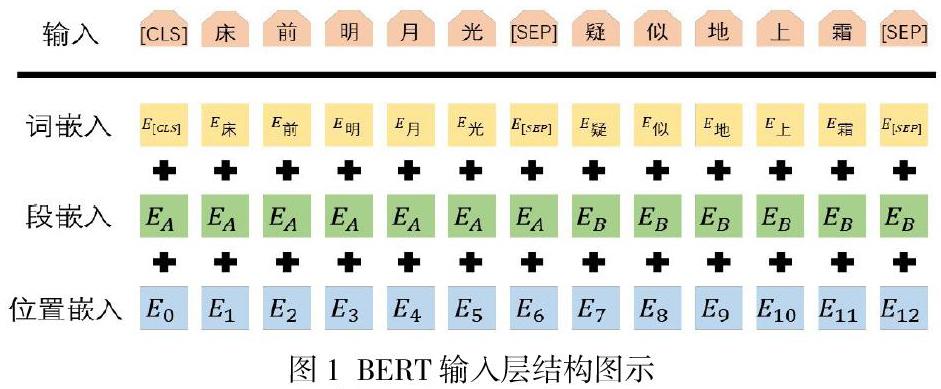
BERT作为语言模型需面对众多任务,督促要谨慎采用BERT进行输入处理,基于词向量增设位置向量,还需添加段落向量以应对一些和句子对相关的问题。图1 为该过程的可视化图[2]。
可以观察到,一个特别表示被加入到序列首位,针对部分句子或句子对分类任务,该标识的最后输出即是整个句子或句子对的表象特征。针对其他类型的任务,该标识尽管参与了序列编码过程,但最后输出情况不被重视。BERT能够依照图1所示的形式对句子对行“打包”处理,形成单一句子再做处置,且使用特殊标识[SEP]分隔句子、整合段向量,进而使模型精确区分两个不同的句子。
1.2预训练
(1)预测遮蔽词
BERT模型采用的是双向编码器,综合考虑前文以及后文词,且在多层注意力机制的作用下,促使从第二个层面开始,各此的编码均能捕获到所有词的信息。为更严格的训练语言模型,创设新的预训练法——遮蔽词语言模型训练。在该训练内,特殊标识[MASK]会随机取代输入序列内的元素,借此方式屏蔽某一词于层次编码阶段的所有信息。
(2)判断下一句
很重关键的下游任务运作阶段均需深度解读不同句子对之间的关联性,比如语义类似度、翻译质量测评等。若只应用遮蔽词训练形式,则难以保证模型能精确捕获句子对的关系,故而需基于另一种预训练任务去强化模型在该方面的能力。预测一个句子是不是衔接另一个句子的下一句,实质上便是下一句判断任务。该任务的达成过程较为简易:经语料库内提取任一语句A,并捕获其下一句B,基于50%的概率用B将语料库内无关联的句子C取代。
1.3微调
基于BERT模型能够有效落实多样化的NLP任务。而在面对不同NLP任务的处理需求时,无需调整BERT模型的内部结构,其只需要将指定的网络层添加至最后编码层上即可满足任务处理要求,这在很大程度上也为BERT模型在处理众多任务阶段迁徙学习创造便利条件。
在处理不同的下游任务时,BERT模型会作出微调整。比如,针对句子对分类任务而言,可以将这两个句子拼接成一个长句,而后依照上文阐述的方法处理后进行输入,也可以对句子开头部位的特别标识[CLS]作出编码处理后,将获得的向量设为语句表征。而若面对的是类似于智能问答任务时,要可以忽视特别标识[CLS]产出的编码结果,也可以采用和单词相配套的编码结果去判断准确答案的起始、终止位置[3]。
综合如上论述的内容,我们发现BERT模型应用过程表现出较高的灵活度,可以结余不同的任务需求整顿差异性的输出策略。尽管全部参数需要参与到微调整过程,但事实上其于预测训练环节成熟度就已抵达较高水平了,可以较精准的捕获语句的抽象特征,故而微调操作等同提升BERT模型应对不同人物的速度与准确度。
2、 BERT模型的训练
笔者在研究阶段,将全衔接网络添加至BERT模型的输出结果上,并且联合使用softma作为分类器。选定的训练数据是微博舆情数据,数据集共计有10大类,涵盖民生、文化、娱乐、体育、财经、房地产、汽车、教育、科技、军事。对应的样本数依次为2116、、2258、6043、6192、4640、2102、5935、4505、5740、2780。
本模型的Fine-turning于Tesla K80 GPU内完成训练,一轮训练活动历史大概为6min。表1是BERT模型后的记录情况[4]。
笔者针对本次研究中模型训练结果和杨艳等[5]提出的文本分类模型进行比较分析,采用双向LSTM衔接卷尺神经网络(CNN),设定CNN的一维卷积核长为3,卷积核数是64,最大值池化层与softmax 衔接并作为分类器。表2是模型训练期间数据的记录情况[5]。
对比表1、2内数据信息整体分析后,发现BERT模型训练时在准确率、召回率指标上均优于基于LSTM衔接CNN模型的训练结果,这可能是因为BERT对句子长距离特征持有更强的捕获能力,且确保了被捕获语言特征的相对完整性与多样性。
3、 结束语
BERT模型基于特有的双向编码,在各层内部均形成了双向逻辑关系,能够完成十余个语言处理领域的任务,利用BooksCorps、英文维基百科量大语料库,灵活的迁徙到下游各个任务内,接受以字作为embedding的输入结果,单难以完全规避部分语义信息遗失的问题。这提示在后续研究中,应加大BERT 的 Transformer构思的参考力度,训练出对词语有强大动态编码能力的模型,进而最大限度的强化语义阐述与特征提取能力。
参考文献:
[1]龚韶,刘兴均.网络舆情安全监测语义识别研究综述[J].网络安全技术与应用,2019,14(07):52-57.
[2]顾凌云.基于多注意力的中文命名实体识别[J].信息与电脑(理论版),2019,41(09):41-44+48.
[3]朱昶胜,孙欣,冯文芳.基于R语言的网络舆情对股市影响研究[J].兰州理工大学学报,2018,44(04):103-108.
[4]王璟琦,李锐,吴华意.基于空间自相关的网络舆情话题演化时空规律分析[J].数据分析与知识发现,2018,2(02):64-73.
[5]杨艳,徐冰,杨沐昀,等.一种基于联合深度学习模型的情感分类方法[J].山东大学学报(理学版),2017,52(09):19-25.
