基于加权特征子空间的支持向量机核函数研究
2020-06-29梁礼明盛校棋
梁礼明, 郭 凯, 盛校棋
(江西理工大学电气工程与自动化学院, 赣州 341000)
支持向量机(support vector machine,SVM)作为机器学习的重要组成部分,它通过利用数据间的角度与距离来表示映射到高维空间的数据,避免了“维数灾难”的问题,同时它还兼备稀疏矩阵的特性。但核函数所具备的稀疏矩阵的特性较为简单,在处理重叠子空间[1]问题时仍显不足。当下核函数的研究主要在寻找更多适合不同特征关系的核函数,这样的方法并没有改变交叉空间数据点之间的关系。
文献[2]将随机核函数与线性核函数进行结合,研究出了线性随机核大大提高了运算速度,同时使得核函数可以满足训练样本远远小于样本量。该文还指出特征在运算中的重要性,但是并没有对特征的权重进行研究。文献[3-4]分别提出了模糊相似度量的核函数的构造与孪生核函数的研究,这两种方法只是对特征集合的描述进行了改变,只是增大或减小了每两个数据点间关系并没有根据数据特征的特性对数据进行优化改变。
基于以上核函数优化的不足,提出一种将聚类算法与分类算法结合的方法来优化核函数。该方法引入了对特征子空间加权处理的方法,针对不同类别、不同特征的区分度,对样本数据进行特征子空间加权处理,改变部分数据点间的关系,缩小了数据点之间的重叠空间。同时利用优化的稀疏条件下的重叠子空间聚类算法[1],将数据集中同类数据间隔稠密化和不同类别数据间隔稀疏化以达到提高核函数泛化能力和学习能力。该方法融合稀疏矩阵的数据稀疏化特性、子空间[5-6]的不同类别以及不同数据特征空间的规划能力,对各种核函数的学习能力与泛化能力得到显著提升,能够获得较好的分类效果。
1 理论基础
1.1 核函数
核函数的构造需要满足Mercer定理[7],而Mercer定理主要是通过核函数确定核矩阵的要求。
定理1(Mercer定理)要保证Frobenius范数下的对称函数K(xi,xj)为正数ak>0,将对称函数展开为
(1)
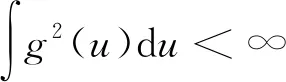
SVM在获得分类标签时,使用的决策函数为
(2)
式(2)中:αi、b是通过求解式(3)最优化问题获取的;yi表示数据xi的对应标签。
(3)
由式(1)可知,φ(xi)φ(xj)描述的是将低维空间映射到高维空间数据点间的表达方式,进一步可以转化为K(xi,xj),利用数据特征空间数据间内积或者距离关系通过函数的关系达到能够反映高维数据空间关系的形式。常用核函数类型有:①以距离为衡量标准的核函数,如高斯核函数、二次有理核、多元二次核和逆多元二次核等;②以内积为衡量标准的核函数,如线性核函数、多项式核函数等。
研究表明以距离为主的核函数实用性相较于以内积为主的核函数在现实生活中泛化性和学习性更强[8]。以距离为主的核函数与聚类算法相似,依靠计算数据点间的距离的远近来进行预测分类,因此将两者结合在一起是可行的。
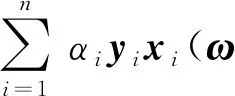
1.2 加权特征子空间
1.2.1 特征子空间重叠率描述
对于一组数据集每一个类别空间可以看作一个子空间,每一个数据的特征也可以看作一个特征子空间。利用超球体的思想将不同类别、不同特征的数据建立超球体模型,以最小超球体间的交叉范围来计算空间的重叠率[9]。
超球体描述的目标函数为
(4)
式(4)中:a为球心;R为超球体半径;C为惩罚参数;ζi为松弛变量。
利用建立的不同类别及特征超球体的球心及半径计算相同特征下不同类别的超球体的交叉体积与公共体积。其空间重叠描述为[10]
(5)
式(5)中:Q为重叠率;L1,i为类别1在缺少特征i中所占空间;L2,i为标签2在缺少特征i空间中所占空间;FC为L1,i与L2,i的交叉空间;FA为L1,i的空间;FB为L2,i的空间长度。式(2)与文献[11]文本特征重要度相似,是利用特征的重叠率初步评估特征的重要程度的度量。
1.2.2 特征子空间信息熵描述
对于任意数据集(x1,x2,…,xn)T,其用每一列特征可以表示为(T1,T2,…,Tn), 经过对每一列特征加权可以表示为(ω1T1,ω2T2,…,ωnTn)。确定每一特征的加权系数是特征加权的重中之重,采用空间重叠率与信息熵的结合使用。
信息熵H的大小决定数据的有序程度,信息熵H的数值越接近0说明数据的有序程度越高,相反信息熵的数值越大说明数据的有序程度越低[12],因此通过信息熵的大小判断数据的有序程度可以进一步说明该组数据在分类中占的重要性。信息熵H的计算公式如式(6)所示:
(6)
式(6)中:pi为数据(x1,x2,…,xn)T的输出概率函数。
1.2.3 特征子空间加权
对数据集的样本特征Ti设置权值:
(7)
最后,对所有所有的特征子空间权值归一化,即
(8)
1.3 加权混合范数的距离空间模型
1.3.1 距离模型
数据点间距离的表达方式来作为衡量分类的一类重要标准,在分类实验中常用的是明可夫斯基距离(Minkowski distance)[13]。设数据点P(x1,x2,…,xn)T和Q(y1,y2,…,yn)T∈Rn那么,明可夫斯基距离可以表示为
(9)
式(9)中:d为数据点P、Q间的明科夫斯基距离。
在传统的核函数中对数据点间的描述主要以Frobenius范数与数据点间的内积为主,结合SVM与稀疏矩阵的思想,提出一种混合范数的特征子空间模型,目的是在保障类间间距稀疏性的同时增加类内间距的紧密性。对于一个训练样本数据,其中包含N个特征,M个数据点,利用核函数在表示数据点之间的关系时组成一个M×M矩阵,该矩阵为一个对称矩阵同时也是个正定矩阵。引入L1范数来增加矩阵间的稀疏性,具体距离表示模型可表示为
(10)
1.3.2 加权方式
在处理数据问题时,由于数据的复杂多样化的问题,只是引入L1正则化来保障核矩阵的稀疏性其效果并不是很理想。文献[14-15]提出对L1正则化加权的方法,通过迭代更新的方法对L1范数进行改变,并且通过大量实验证明了该方法优于单独使用L1范数的效果,能够得到更具有稀疏性的核矩阵,使得L1更逼近L0。通过式(11)进行求解[16]:
(11)
式(11)中:δ为控制参数;A为由已知数据求向量平均值确定的向量矩阵;c为给定的限制参数。
其加权方式为
(12)
式(10)可以表示为
(13)
2 实验仿真与分析
支持向量机核函数分类算法流程如图1所示。实验仿真数据均来自UCI(UC Irvine machine learning repository)数据库,并且每组数据均带标签。SVM分类器应用Lib-SVM工具箱,仿真环境运用MATLAB R2018a,运行于Intel (R) Core (TM) i5-7200U/2.50 GHz、8 GB内存的计算机。实验随机选取每组样本的80%为训练样本,其余20%为测试样本。
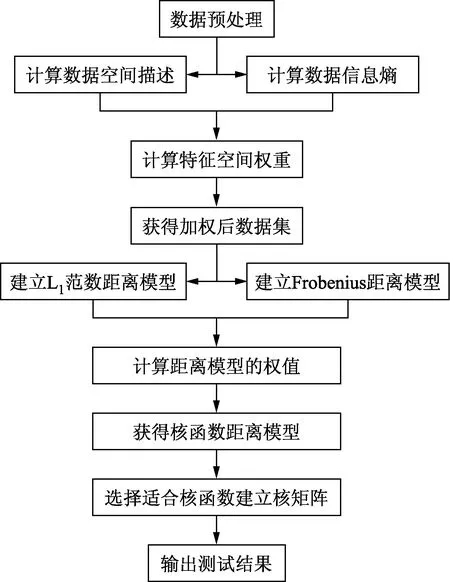
图1 支持向量机核函数分类流程图Fig.1 Support vector machine kernel function classification flow chart
2.1 建立加权特征子空间
在UCI数据库中随机抽取一组数据实验,该数据为User Knowledge Modeling Data Set,即学生对直流电机的知识水平数据集,数据集STG表示目标对象素材的学习时间输入值,SCG表示目标对象用户重复次数输入值,STR表示与目标对象相关的用户学习时间输入值,LPR表示与目标对象相关的用户考试成绩输入值,PEG表示用户对目标对象的考试成绩输入值,UNS表示用户知识水平目标值。
首先对样本数据进行归一化处理,使得各个数据点的各特征值小于1,并保证各特征间的相对关系;然后利用式(4)、式(5)对各特征进行重叠空间描述;再根据式(6)~式(8)与各特征重叠空间的关系对样本数据进行加权处理;最后通过对实验数据进行分析建立加权特征子空间的必要性与可行性,具体的实验内容及数据如表1所示。
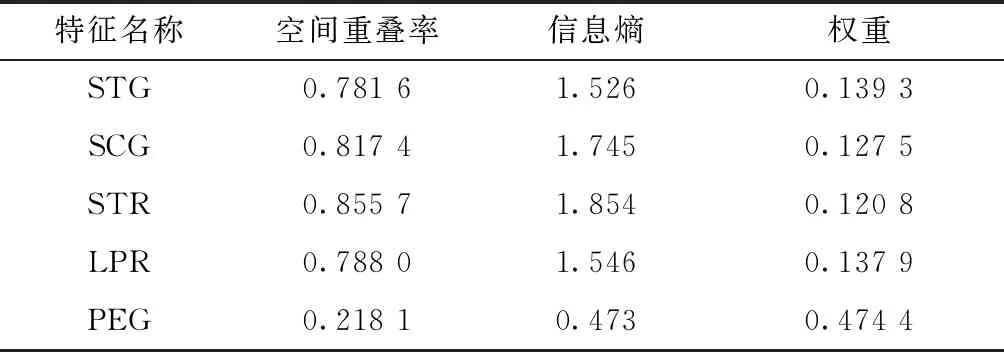
表1 数据集各特征空间的重叠率、方差和加权比例Table 1 Overlap rate, variance and weighted ratio of each feature space of the data set
从表1可知,无论是信息熵还是空间重叠率特征PEG的数值最低,即特征PEG在数据分类的过程起到了比较重要的作用。
2.2 距离矩阵的建立与仿真测试
该实验以评估对称距离矩阵内的重复率进行评估对核函数的影响。通过引入L1范数减少了矩阵内部元素的重复率,同时增加数据点间的距离,进一步增加了核矩阵的稀疏性,使得大部分数据更接近0,增大了数据间的区分度。在UCI中随机抽取四组数据进行实验分析。各数据集分类结果对比如表2所示。
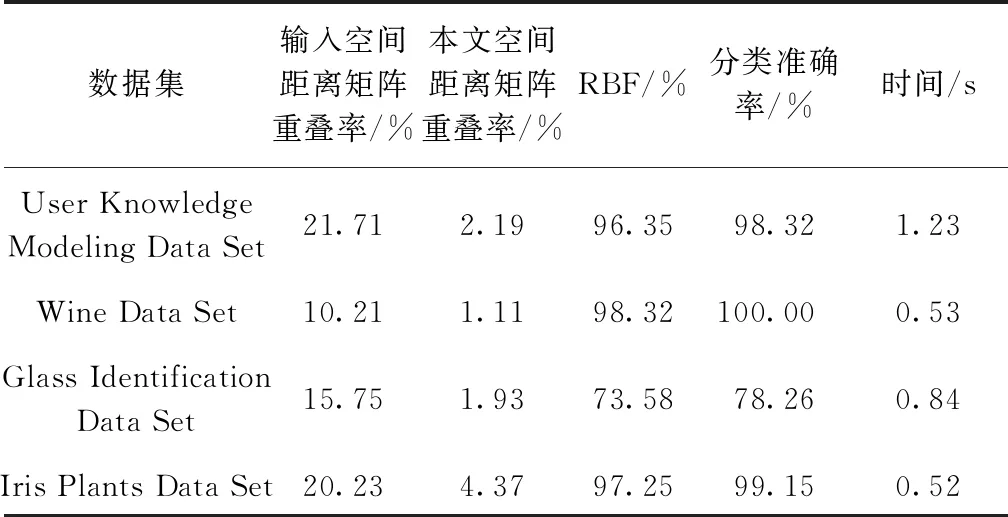
表2 各数据集分类结果对比Table 2 Comparison of classification results of each data set
通过实验仿真可知,对于核函数中引入L1范数可以减少距离数据的重复率,同时可以增加类内间距的紧密型和类间间距的稀疏性,以达到更好的泛化效果。为了更好地阐释核函数通过引入L1范数能够更好地增强核函数的泛化性,通过对部分以距离为衡量标准的核函数进行研究,同时对引入L1范数的输入距离矩阵进行分析,来说明该方法的可行性与有效性。
从图2分析可知,以距离为主要评判方式的核函数(如高斯核函数、二次有理核核函数和逆多元二次核函数等),随着距离的增加该距离所对应的核矩阵的数值越接近0。
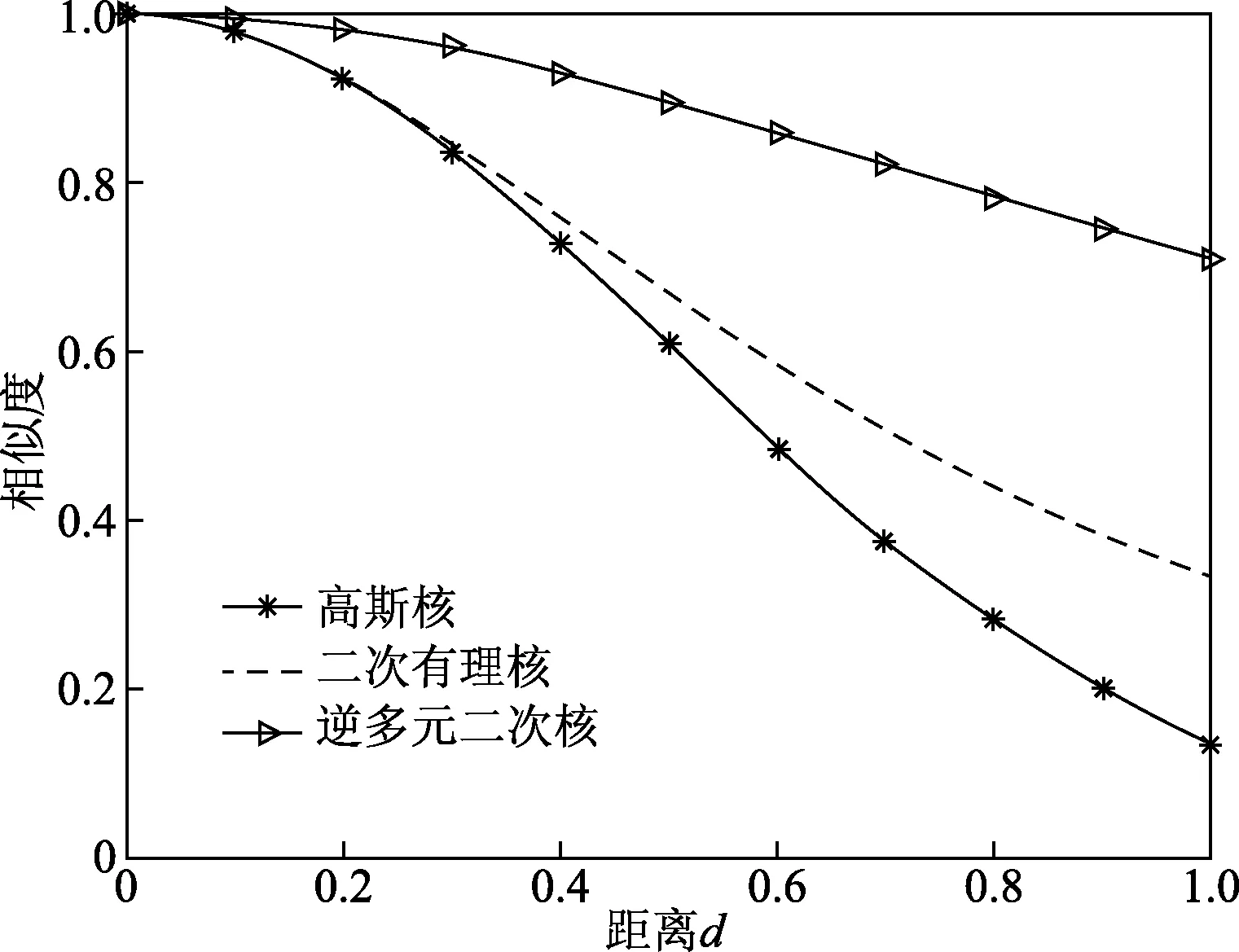
图2 核函数特性比较Fig.2 Kernel property comparison
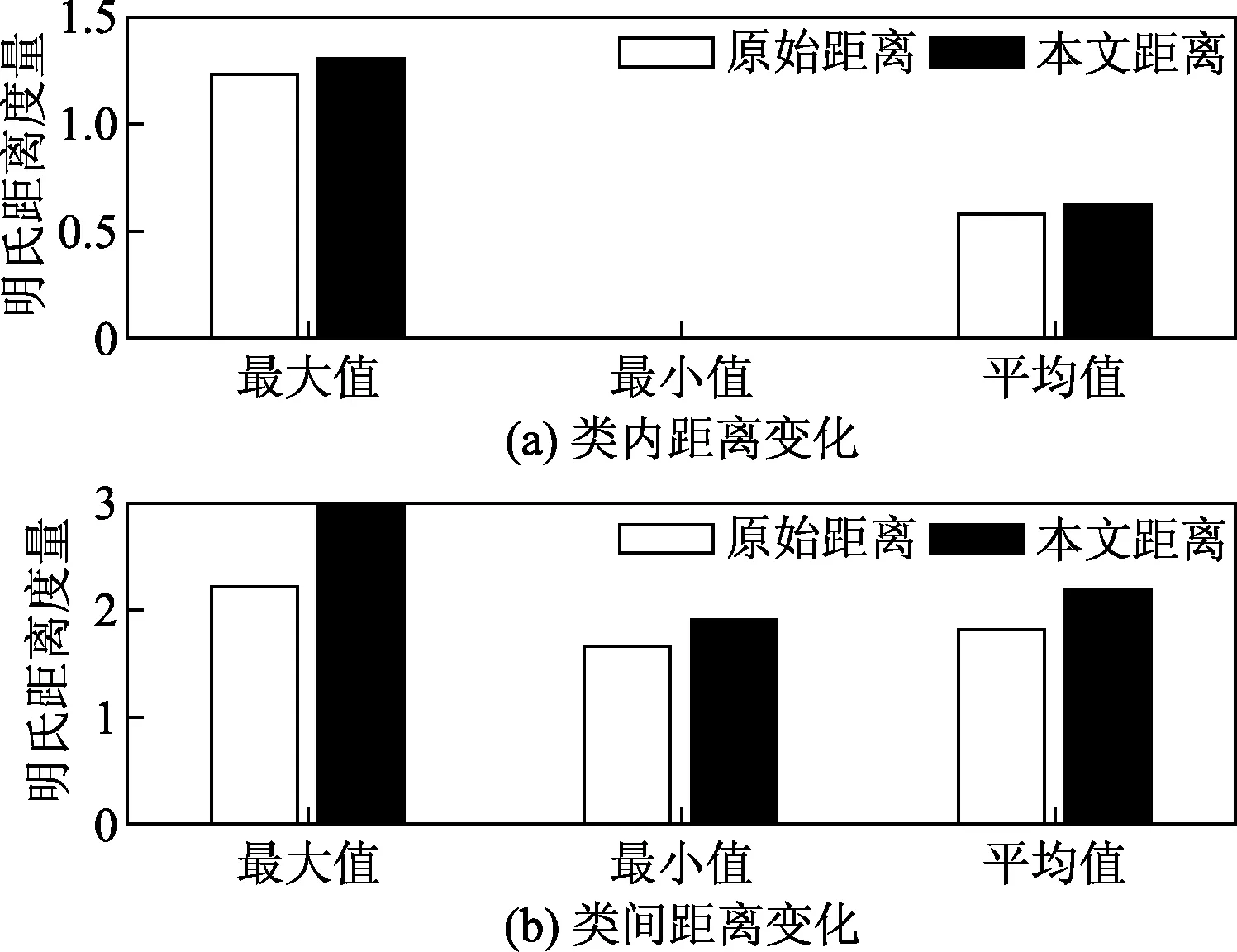
图3 引入L1范数距离变化Fig.3 Introducing L1 norm distance variation
图3(a)、图3(b)分别为同一数据集同类标签类内特征距离和不同类标签特征距离经过引入L1范数距离变化的情况分析图。由图3可知,通过引入L1范数使得类内、类间距离均得到提高,但是类内间距提升的幅度较小,而类间间距变化较大。所以通过引入L1范数能够有效地提升数据类内紧密型和类间稀疏性的特点。再与以距离为分类手段的核函数,该类核函数可以通过增大距离的方式来达到核矩阵稀疏化的目的,进而达到拉大同类数据与异类数据的距离关系,从而可以提高核函数的学习能力与泛化能力。
2.3 样本数据对比分析
随机选取文献[5,17]中所用的数据集进行对比试验,数据集包括:Breast Cancer Wisconsin、Fisheriris Data Set、Wine Data Set、Heart Disease Data Set、Indian Liver Patient Data Set、Australian Credit Approval Data Set六组,对六组数据分别进行特征子空间的加权处理与引入L1范数的稀疏化处理。分类结果采用5次实验取平均值的方式与文献[5,17]的分类结果进行对比,结果如表3所示。
通过与其他文献的分类效果以及利用经过优化与非优化的二次有理核的分类结果对比分析。从核函数的角度分析,RBF核函数相对于二次有理核函数有较大的优势,如何选择正确的核函数对实验的结果起到一定作用;从核函数内部间分析,经过本文算法优化过的核函数能够显著地提高核函数的分类效果,无论是在RBF核函数间的对比,还是在二次有理核函数间的对比,本文算法在一定程度上提高了核函数的分类准确率。从理论上分析,对一组数据中的各个特征进行了挖掘,利用科学的手段对不同特征对分类结果的影响进行了分析,更进一步使得核函数挖掘出数据潜在的信息,进而提高分类准确率。同时,还引入了L1范数,使得同类数据间更加紧密,异类数据间更加稀疏,增大了数据间的可区分性,进而提高了分类效果,增强了核函数的学习能力与泛化能力。
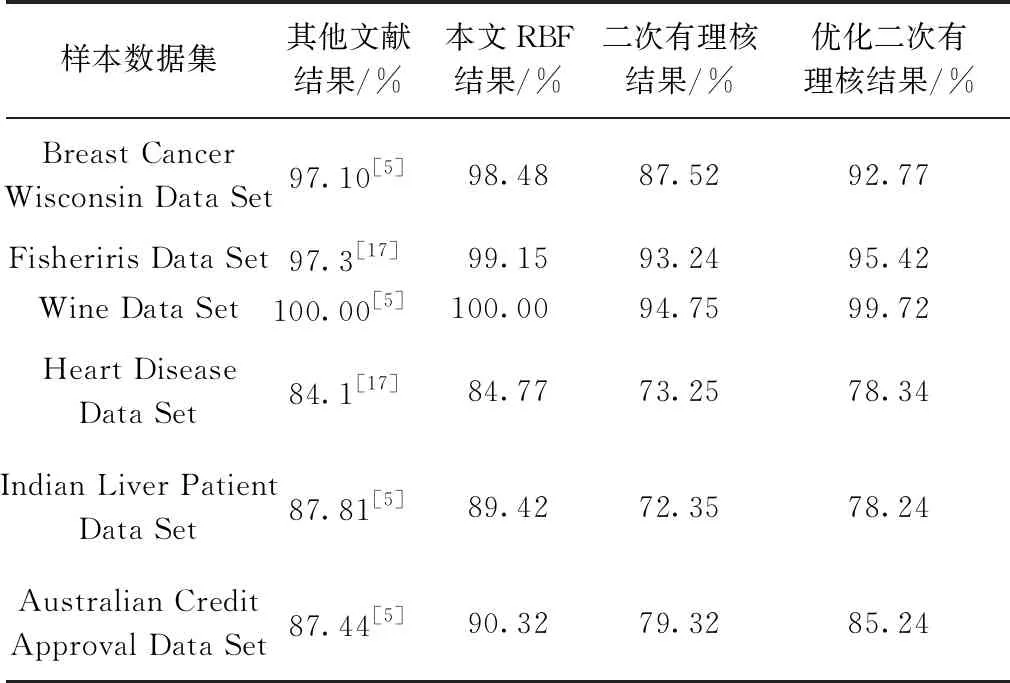
表3 本文算法与其他文献分类效果对比Table 3 Comparison of the classification effect between the proposed algorithm and other documents
3 结论
利用特征子空间加权的方式,较好地解决了特征对分类决策的影响不明确的问题,使得核函数能够更好地挖掘数据集一些潜在的关系。为充分发挥数据本身的价值属性,针对一些以距离为主要衡量标准的核函数进行的优化与改进,通过引入L1范数使得数据输入空间距离得到一定程度的扩大。同时由于类内间距与类间间距不同的变化效果达到稀疏化核矩阵的目的,使得类内间距与类间间距的重合率更小,同时类间部分核矩阵数值更接近0。通过仿真实验证明该方法的可行性和有效性。本文算法融合核函数、稀疏矩阵与特征加权等有效地提升核函数的学习能力与泛化能力,但是在一些数据集中仍存在不小的交叉空间距离,这样的交叉空间是优化核函数的主要矛盾之一,故下一步主要研究如何减少距离空间的重叠率。
