基于主成分分析的PSO-ELM_Adaboost算法耦合模型在极震区泥石流物源动储量计算中的应用
2020-06-29巨能攀王昌明
李 桥, 巨能攀, 黄 健, 王昌明
(成都理工大学地质灾害防治与地质环境保护国家重点实验室,成都 610059)
泥石流是一种在山区非常普遍的地质灾害。中国山地面积分布广泛且人口聚集,决定了泥石流灾害的多发性和致灾性[1]。尤其是在高强度高烈度地震后,极震区产生了大量的滑坡和崩塌,为泥石流的形成提供了充足的物源条件。故而极震区内泥石流活动呈现出频率增高、规模增大,并具有区域群发性、雨季突发性和周期复发性等特点,成为了众多专家和学者们重点关注的焦点[2]。
泥石流动储量作为设计泥石流防治工程中不可或缺的参数,传统的物源动储量计算方法有:人工经验法、比例统计法和遥感解译法等[3-5]。但与普通泥石流相比,极震区泥石流的物源类型在规模、数量和分布方式上都有极大差别,更为重要的是,极震区泥石流物源在后期强降雨的作用下启动方式发生了明显改变,采用传统方法获取泥石流动储量可信度不高。为此,相关学者在该领域提出了多种方法来解决这一问题,并取得了诸多成果。Dong等[6]通过收集1999年“9·21”集集地震后中国台湾地区台中县区域内泥石流沟在两次台风影响下的物源量变化数据,提出了基于判别因素的多元回归模型。乔建平等[7]调查统计汶川地震极震区内44条泥石流沟的物源信息,总结出了汶川地震灾区泥石流物源的主要类型和启动地质模式,基于数学统计的方法发现总物源量与动储量呈线性相关。顾文韬等[8]以四川安县高川乡区域内多条泥石流沟为研究对象,提出了“地震高程指数放大经验模型”,通过多元统计拟合法提出了极震区震后泥石流的动储量计算公式。方群生等[9]基于震后泥石流调查踏勘资料,将泥石流流域内物源分解成崩滑体、沟道物源和坡面物源,分别进行单因子回归分析再叠加,建立了新的泥石流动储量计算模型。以上计算模型均取得了较好的效果,但具有一定的局限性,不利于推广。
极震区泥石流物源动储量影响因素众多,属于复杂的非线性问题,笼统的对其进行数学分析,无法达到理想的计算精度。而神经网络具有很强的非线性信息处理能力、自适应学习能力和容错性,可以很好地解决这一问题。极限学习机(extreme learning machine, ELM)作为一种单隐层前馈神经网络算法,具有结构简单、适应性强和训练学习速度快的特点[10],在各工程领域取得了不错的效果。廉城[11]运用经验模态分解(ensemble empirical mode decomposition, EEMD)将滑坡位移曲线分解成多个子序列,分别运用ELM进行预测分析,预测结果精度较高。Xu等[12]基于生存分析模型和ELM从定量的角度对文家沟泥石流治理工程效果进行了分析评价。李骅锦等[13]通过岩移数据决策和ELM,提出了一中矿山开采最大下沉值的新方法。同时相关研究也表明使用智能优化算法对ELM进行参数选取可进一步提高预测精度并提升网络稳定性[14-15]。因此,提出一种基于ELM的极震区泥石流物源动储量计算方法,并且使用粒子群算法(particle swarm optimization, PSO)对ELM进行优化,并与AdaBoost算法进行耦合。
采集汶川极震区区内60条泥石流沟的物源信息作为样本数据,从泥石流物源形成与启动方式入手,提出了流域面积、相对高差、主沟长度、较发震断裂带距离、沟床平均纵比降和物源总储量作为泥石流物源动储量的影响因子,运用Person相关系数(Pearson correlation coefficient,PCC)、灰色关联度(grey relational grade,GRG)和最大互信息系数(maximal information coefficient,MIC)对影响因子进行了敏感性分析;为了避免信息冗余,基于主成分分析(principal component analysis,PCA)对样本数据进行处理,再采用AdaBoost算法和粒子群优化的极限学习机(PSO-ELM)相结合的PSO-ELM_AdaBoost耦合模型进行训练和预测,并将结果与BP(back propagation)、支持向量机(SVM)、ELM、PSO-ELM模型和传统计算 模型计算值进行比较;最后从每个子研究区中抽取一条泥石流沟和其他极震区的三条泥石流沟应用PSO-ELM_AdaBoost模型进行泥石流物源动储量预测,验证了本文模型的准确性和适宜性。
1 理论与方法
1.1 最大互信息系数
现实世界数据之间的不一定总是呈现线性关系,采用余弦相似度(cosine similarity,CS)和Person相关系数等线性相关性系数,可能会造成关联度误判。为此Reshef等[16]基于互信息理论提出一种具有普适性和公平性的新型变量关联评价指标:最大互信息系数,有效地解决了变量间的非线性关联分析。
对于给定的两个变量A=(a1,a2,…,an)和B=(b1,b2,…,bn),n为样本个数,构建一个二元数据集D,利用一个x×y的网格G将D进行网格化,那么关于D的MIC可定义为
(1)
式(1)中:B(n)为网格划分x×y的最大值,一般取B(n)=n0.6;M(D)为D的特征矩阵,其计算公式为
(2)
式(2)中:MI*是D双变量间的最大互信息,即
MI*(D,x,y)=max[MI(D|G)]
(3)
式(3)中:D|G为每个单元网格的概率分布。
换言之,MIC是一种归一化的最大互信息,其取值区间为[0,1]。MIC越大,表明两个变量的相关性越强;反之,则表明两个变量间的相关想越弱[17]。通过计算各因子与极震区泥石流动储量的MIC,综合PCC和GRG,就是为了全面地了解不同因子的影响能力,进而进行敏感性分析。
1.2 主成分分析
主成分分析可以有效处理输入因子间存在一定相关性,对问题的反应存在一定的信息重叠问题[18]。经PCA处理后生成的新变量可以包含原变量大部分的信息,且相互之间不存在相关性。对于有n个样本,每个样本含有p个变量的原始数据矩阵Xn×p,具体分析过程如下。
(1)为消除量纲影响,对样本各数据进行归一化处理,并作为输出样本数据Yn×p。
(2)计算相关系数矩阵R,Rij(i,j=1,2,…,p)为原始变量间的相关性系数:
(4)
(3)根据矩阵R求出其特征值λi和特征向量ui,并按照从大到小排列。
(4)计算主成分贡献率em和累计方差贡献率Em,从而确定主成分的个数。
(5)
(6)
式中:m取值标准是使Em达到设定阈值,一般要求Em≥90%。
(5)输出主成分样本值Z:
(7)
用主成分样本值Z代替原来数据样本X,消除了原始数据间的相关性,从而达到了简化结构的效果。
1.3 极限学习机
极限学习机是由Huang等[19-20]提出的一种基于单隐层前向反馈型神经网络(SLGNs)的监督型学习算法。相较于传统的神经网络,该算法随机产生输入层与隐含层的连接权值及隐含层神经元的阈值,且在训练过程中只需要设置隐含层神经元的个数,便可以获取唯一的最优解。
设有n个任意的样本(xi,ti),其中xi=(xi1,xi2,…,xin)T∈Rn,ti=(ti1,ti2,…,tin)T∈Rn,Rn为n元矩阵。对于一个有L个隐层节点的单隐层神经网络可以表示为
(8)
式(8)中:wi=(wi1,wi2,…,win)T为输入权重;βi为输出权重;bi为第i个隐层单元的偏置;Oj为网络输出值;g(x)为激活函数;激活函数均采用sigmoid方程,其形式如式(9)所示:
(9)
(10)
用矩阵表述为
Hβ=T
(11)
式(11)中:H为隐含层输出矩阵;β为输出权重矩阵;T为期望输出矩阵。网络训练中,由于锁定了随机选择的wi和bi,H为固定矩阵。此时β可通过求解式(11)最小二乘解进行求解,即:
(12)
此线性方程的最小二乘解为
(13)
式(13)中,H†是矩阵H的Moore-Penrose广义逆[20]。
1.4 粒子群算法优化极限学习机
粒子群算法是一种全局优化算法[21]。其主要思想为将每个优化问题的潜在解设为一个粒子,在初始化阶段每个粒子都被赋予初始位置和速度,并且为了衡量每个粒子的优越性,定义一个适应度函数,并设定迭代次数。在每次迭代中,所有粒子向全局最优解pbest(整个种群目前搜索到的最优解)与个体最优解qbest(个体自身所能达到的个体最优解)进行逼近,并比较适应度,以更新自己的速度和位置,最终获得全空间搜索最优解。
因此在ELM预测模型中,基于PSO优化网络参数w、β和b,可以避免参数的盲目试算,提高了预测模型的准确性。
1.5 PSO-ELM_AdaBoost耦合模型
AdaBoost算法是基于弱学习定理的一种Boosting应用算法[22],可以提高任意给定弱预测器的预测精度。模型采用PSO-ELM作为弱预测器,多次调用PSO-ELM,并根据每次训练样本预测的优劣,更新对应的权重,再将改变权重后的样本重新对弱预测器进行训练,最后采用AdaBoost算法对这些弱预测器训练结果进行集成,输出最终结果。建立基于PCA的PSO-ELM_AdaBoost模型的步骤如下。
(1)数据选择与网络初始化。首先将原始数据样本集X进行归一化处理得到数据集Y,再利用PCA将Y降维,得到了消除冗余信息的新数据样本集Z。从Z中随机选择m组训练数据,初始化测试数据的分布权值Dt(i)=m-1,并确定预测误差阈值。
(2)弱分类器预测。利用训练数据训练PSO-ELM并且预测训练数据输出,得到预测序列g(t)的预测误差和et:
(14)
式(14)中:Dt(i)为第t次迭代权值;g(t)为预测结果且g(t)≠y,其中y为预测期望误差。
(3)计算预测序列权重。权重at的计算公式为
(15)
(4)更新样本权重。根据权重at调整下一轮训练样本权重:
(16)
式(16)中:Bt为归一化因子;g(t)为预测结果。
(5)强预测器函数。将训练得到的多个弱分类函数集合成强预测函数h(x)。
(17)
式(17)中:ft(x)为弱分类函数。
根据上述步骤,基于PCA的PSO-ELM_AdaBoost预测模型算法流程如图1所示。
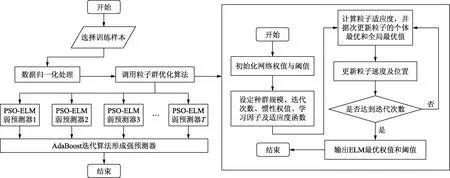
图1 基于主成分分析的粒子群优化极限学习机和AdaBoost算法耦合模型流程图Fig.1 Modeling flow chart of the PSO-ELM_AdaBoost based on PCA
2 研究区概况及影响因子选取
2.1 研究区概况
2008年“5·12”汶川地震发生后,极震区内泥石流呈现出频率高、规模大和周期复发等特征,泥石流沟间物源类型、启动方式也和发育特征各有不同,对该区域进行震后泥石流物源动储量特征研究具有代表性。主要选取汶川地震极震区震后泥石流物源量较多、启动条件较低、危险性较大的泥石流作为研究对象(部分样本现场航拍图如图2所示)。泥石流样本数据来源于汶川县映秀镇(13条)、G213公路沿线(5条)、都江堰市龙池镇(10条)、绵竹市清平乡(9条)、安州区高川乡(20条)和北川县县城附近(3条),共计60条样本,样本分布如图3所示。

图2 部分样本现场航拍图Fig.2 Aerial photos of some sample sites
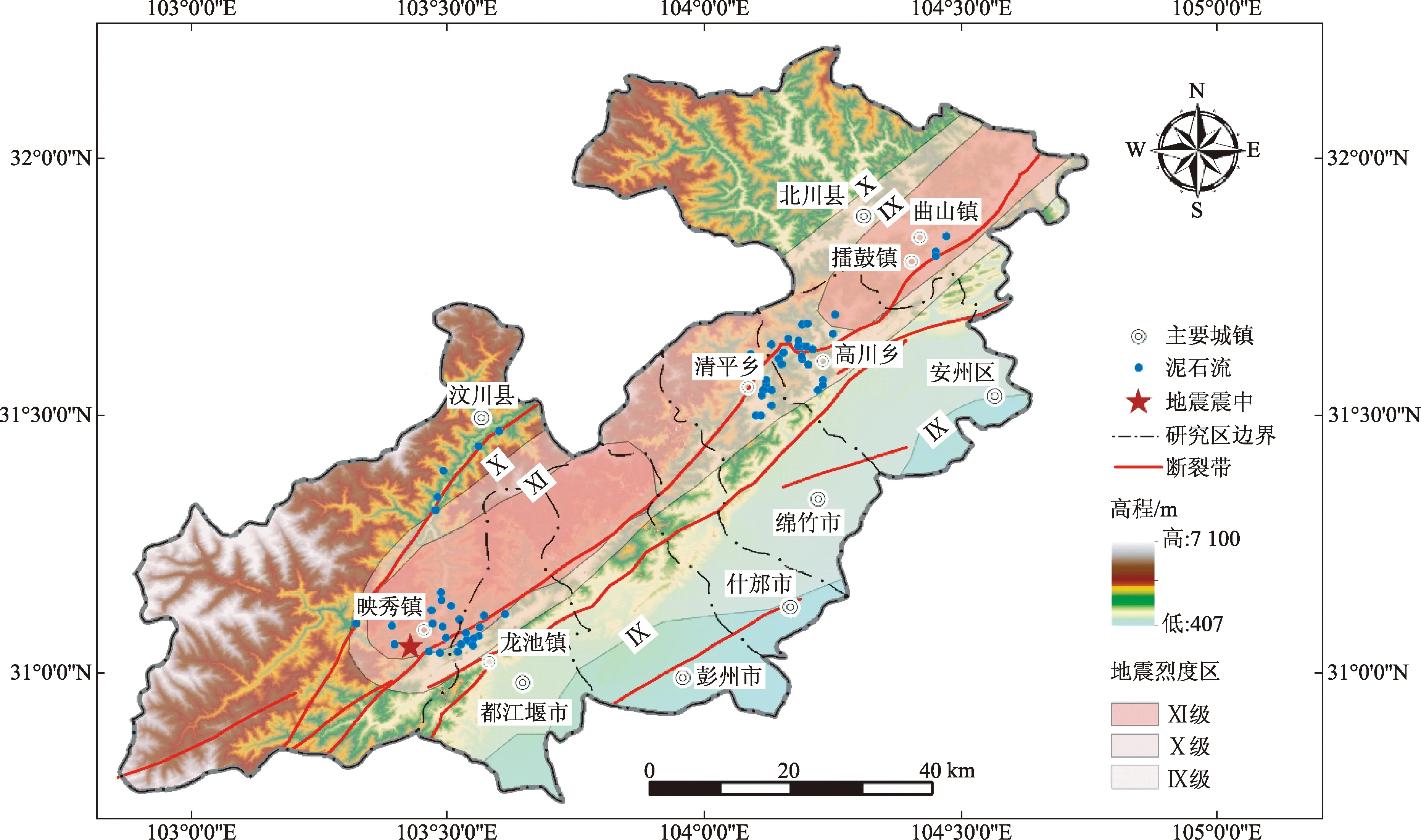
图3 研究区地形地貌、地震烈度及泥石流沟分布Fig.3 Geomorphologic,seismicity and distribution of debris flow in research area
2.2 影响因子的选取与敏感性和响应分析
影响因子的选取既要考虑因子的是否具有代表性,也要确保各因子之间相互独立且选取因子易量化。极震区震后泥石流动储量主要来源有:①由强震效应诱发可参加泥石流活动的沟道崩滑堆积体;②先前沟内潜在物源及震后破碎不稳定山体经强降雨条件下导致的洪水冲刷以及侵蚀等作用累积产生的补给性和次生性物源。因此,综合考虑泥石流沟的流域规模、地质环境背景和地震效应等条件下初步选取流域面积(A)、相对高差(h)、主沟长度(l)、距发震断裂带距离(d)、沟床平均纵比降(J)和物源静储量(V)作为泥石流物源动储量(V0)的影响因子。为了进一步研究各影响因子对极震区震后泥石流物源动储量的敏感程度,分别采用Person相关系数(PCC)、灰色关联度(GRG)和最大信息系数(MIC),以收集到的汶川地震极震区区内60条泥石流沟的物源信息为样本(表1),对各因子与极震区泥石流物源动储量进行相关性分析。为消除量纲影响,对样本各数据进行归一化处理,灰色关联度[23]计算中分辨系数取ζ=0.5,最大信息系数基础参数取∂=0.6,c=15,得到的计算结果,如表2所示。
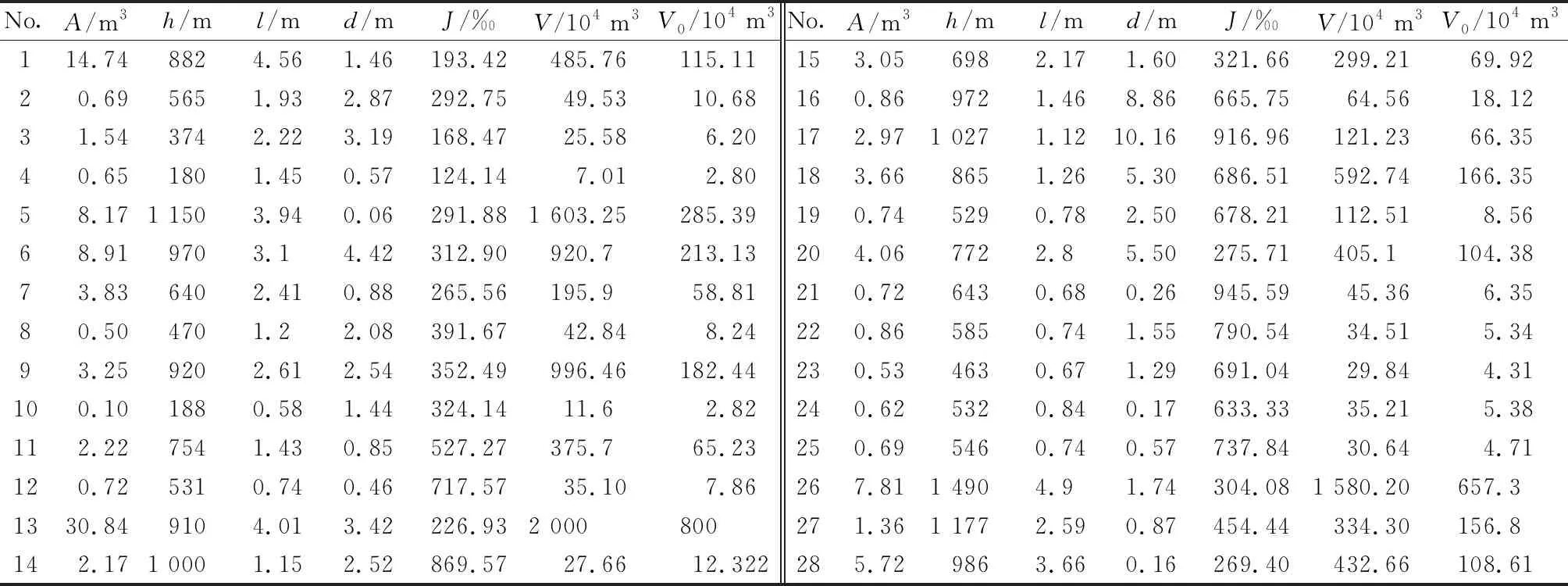
表1 汶川极震区泥石流沟物源信息样本Table 1 Material source parameters of the debris flow gully sample in the Wenchuan meizoseismal area
续表1
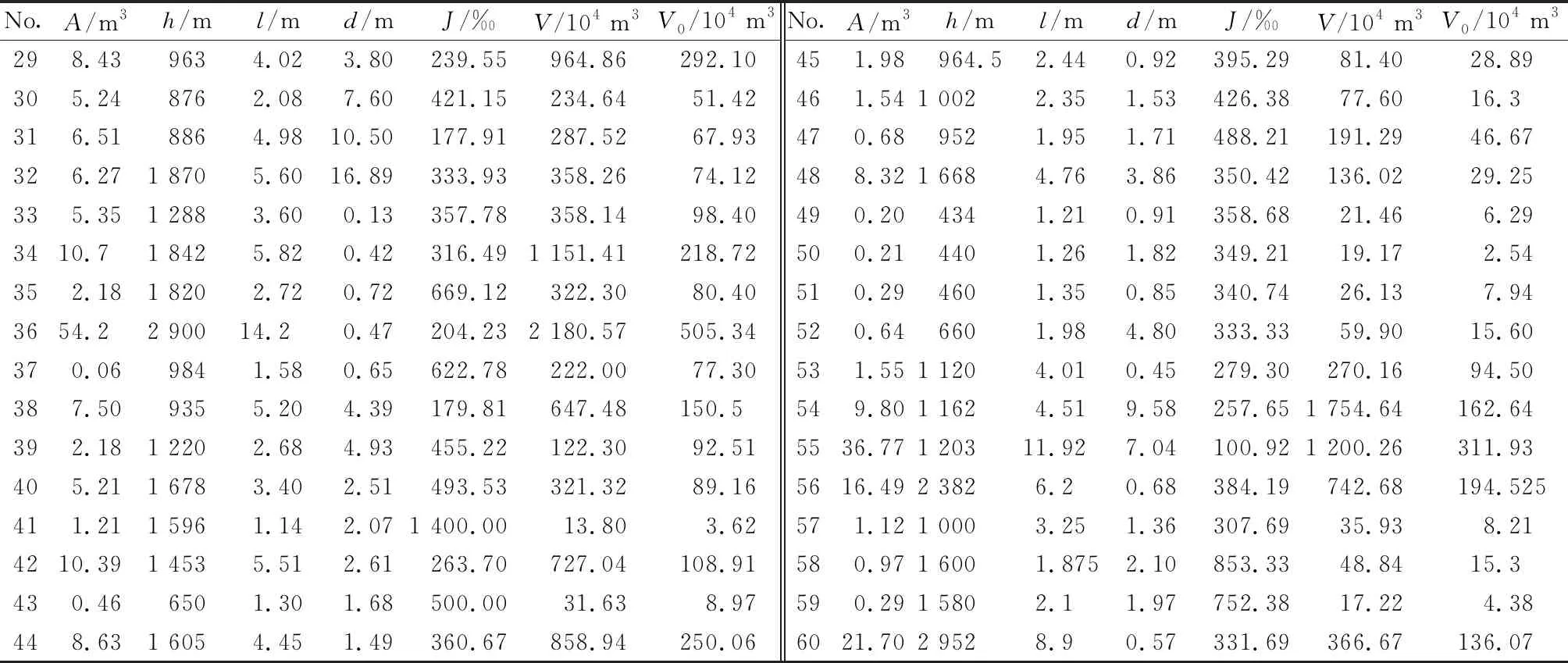
No.A/m3h/ml/md/mJ/‰V/104 m3V0/104 m3No.A/m3h/ml/md/mJ/‰V/104 m3V0/104 m3298.439634.023.80239.55964.86292.10305.248762.087.60421.15234.6451.42316.518864.9810.50177.91287.5267.93326.271 8705.6016.89333.93358.2674.12335.351 2883.600.13357.78358.1498.403410.71 8425.820.42316.491 151.41218.72352.181 8202.720.72669.12322.3080.403654.22 90014.20.47204.232 180.57505.34370.069841.580.65622.78222.0077.30387.509355.204.39179.81647.48150.5392.181 2202.684.93455.22122.3092.51405.211 6783.402.51493.53321.3289.16411.211 5961.142.071 400.0013.803.624210.391 4535.512.61263.70727.04108.91430.466501.301.68500.0031.638.97448.631 6054.451.49360.67858.94250.06451.98964.52.440.92395.2981.4028.89461.541 0022.351.53426.3877.6016.3470.689521.951.71488.21191.2946.67488.321 6684.763.86350.42136.0229.25490.204341.210.91358.6821.466.29500.214401.261.82349.2119.172.54510.294601.350.85340.7426.137.94520.646601.984.80333.3359.9015.60531.551 1204.010.45279.30270.1694.50549.801 1624.519.58257.651 754.64162.645536.771 20311.927.04100.921 200.26311.935616.492 3826.20.68384.19742.68194.525571.121 0003.251.36307.6935.938.21580.971 6001.8752.10853.3348.8415.3590.291 5802.11.97752.3817.224.386021.702 9528.90.57331.69366.67136.07
注:1~20为安州区高川乡内泥石流沟;21~29为绵竹市清平乡内泥石流沟;30~42为汶川县映秀镇内泥石流沟;43~52为都江堰市龙池镇内泥石流沟;53~55为北川县境内泥石流沟;56~60为汶川县G213公路沿线泥石流沟。
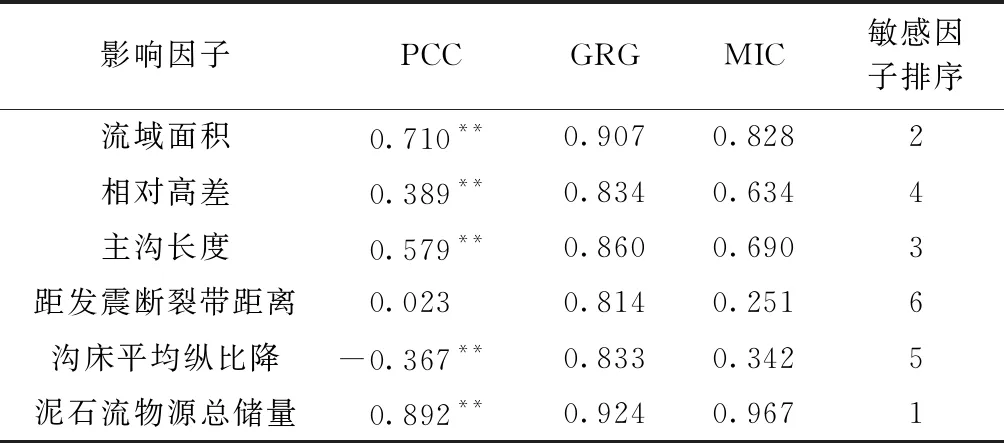
表2 影响因子与极震区泥石流物源动储量敏感性分析Table 2 Sensibility analysis between impact factors and dynamic reserve of the debris flows
注:**表示在0.01水平(双侧)上显著相关。
由表2可知,基于PCC的相关性分析中,只能判定泥石流物源总储量和流域面积两个因子与泥石流物源动储量有明显的线性关系。而在灰色关联度计算中,各因子的GRG均大于0.6,可认为各影响因子与泥石流物源动储量密切相关[23]。MIC相较于GRG区分度十分明显,更能有效地反映极震区泥石流物源动储量对各影响因子的敏感性。最终判定,泥石流物源总储量因子最敏感,而距发震断裂带距离因子最末,选取的各因子均会在不同程度上影响极震区泥石流物源动储量,验证了影响因子选取的合理性。需要指出的是,通过对5个影响因子之间进行相关性系数计算,结果表明:流域面积与主沟长度、流域面积与相对高差和主沟长度与相对高差Person相关系数值分别为0.624、0.814和0.715,相关性较高,其他各影响因子之间Person相关系数值均小于0.419,相关性较弱。在此考虑使用PCA,对输入因子进行降维,避免信息冗余。
3 泥石流物源动储量计算
以汶川地震极震区区内60条泥石流沟的物源信息为样本,从每个子研究区中抽取一条泥石流沟作为测试样本,另外的所有样本作为训练样本和验证样本,其中验证样本采用“留一法”交叉验证方式得到。对样本数据进行PCA降维处理后分别基于五种神经网络算法对研究区内泥石流动储量分别建立计算模型,样本数据如表1所示。
3.1 PCA对原始数据进行预处理
利用PCA求得的原始样本数据得出的特征值(从大到小)和累计贡献率如表3所示。
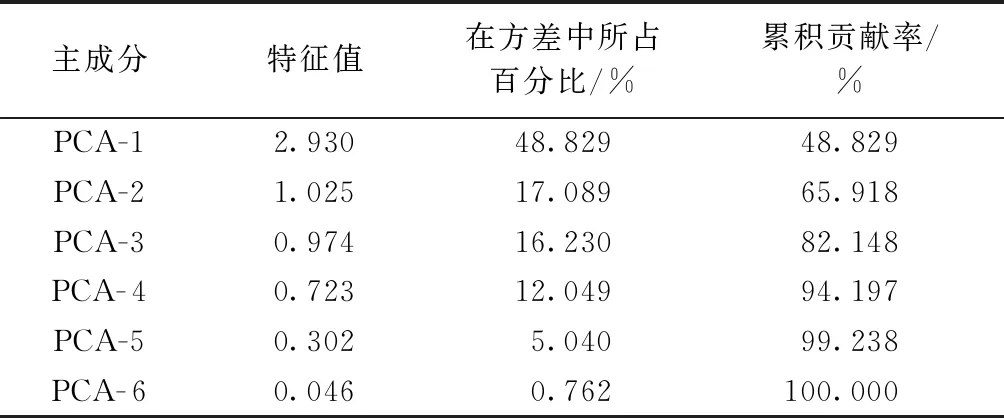
表3 各主成分因子的特征值及累积贡献率Table 3 Eigenvalues of each principal factor and its cumulative contribution rate
计算得到前4个主成分的累积贡献率达到94.197%,因此可以选取第1主成分(PCA-1)、第2主成分(PCA-2)、第3主成分(PCA-3)和第4主成分(PCA- 4)作为神经网络模型的输入,这4个主成分因子特征根对应的特征向量如表4所示。将上述特征向量与原始样本数据对应相乘,即可得到PCA处理后的样本数据。
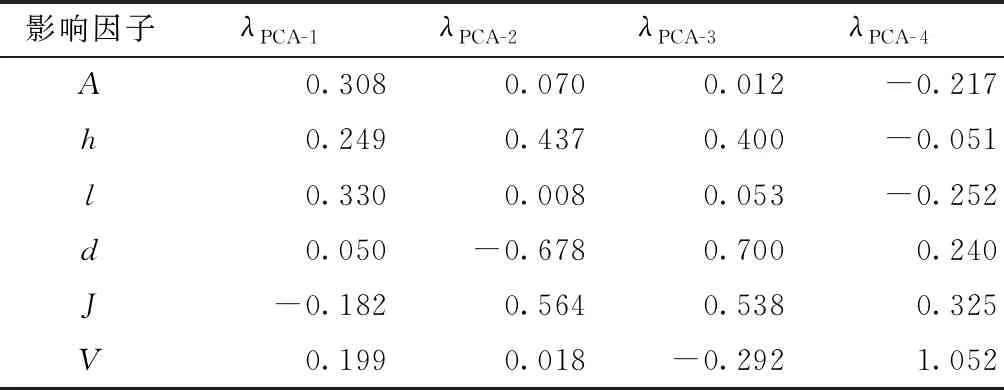
表4 前4个主成分因子特征值对应的特征向量Table 4 Eigenvectors of 4 big eigenvalues
3.2 各神经网络模型参数的设置
3.2.1 BP神经网络模型
网络设置为4- 4-1三层结构,即输入层节点为4,隐含层节点数按照经验公式[24]确定取值范围后经试算,设置为4,输出层节点为1。在训练过程中,学习率Lr=0.05,训练精度Ggoal=0.01,最大训练次数为5 000。
3.2.2 SVM模型
网络核函数设置为RBF(radial basis function),基于五折交叉验证法(5-cross validation)的参数选取结果如图4所示。最终选取惩罚函参数c和核函数参数g分别为5.656 9、0.062 5。
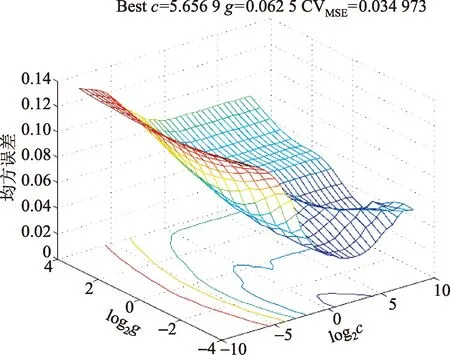
CvMES表示寻优过程中的均方误差图4 基于交叉验证法的SVM参数选取结果Fig.4 The results of SVM parameters selection based on cross validation
3.2.3 ELM模型
网络设置sigmoid为激活函数,设置隐含层节点个数为一个循环数列,在[1,100]中寻找最优隐含层节点数。选择不同的隐含层节点数对ELM模型的计算准确性有较大影响,最终模型计算得到不同隐含层节点数下均方误差(MSE)归一化后的变化曲线。由图5(a)可知,ELM模型隐含层节点数到达57后MSE(归一化后)收敛到0.03以下,且随着节点数的增多,节点数达到76后,MSE(归一化后)呈振荡趋势。
3.2.4 PSO-ELM模型
同样建立以sigmoid方程为激活函数的PSO-ELM计算模型,并在[1,100]中搜索最优隐含层节点数。模型MSE(归一化后)随着隐含层节点数变化曲线如图5(b)所示。在PSO算法中:学习因子c1=1.5、c2=1.7,惯性权重w=1,种群规模Zsizepop=20,最大进化代数为Gmaxgan=100。由图5(b)可知,PSO-ELM模型隐含层节点数达到40后MSE(归一化后)收敛到0.03以下,之后趋于平稳。说明PSO算法减少了“无用的”隐含层节点,获得了更为紧凑的网络体系结构,提升了模型的稳定性。
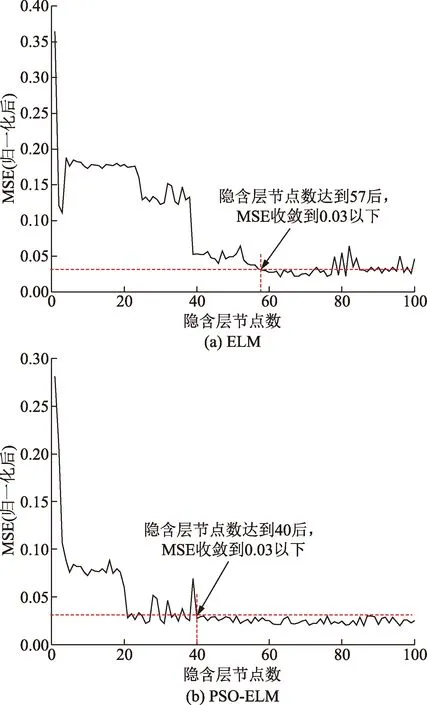
图5 MSE与隐含层节点数关系图Fig.5 Relationship diagram of the number of hidden neurons with MSE
3.2.5 PSO-ELM_Adaboost耦合模型
PSO-ELM参数设置与模型4相同,基分类器数经试算设置为10。
3.3 预测结果与误差分析
各模型的训练样本拟合结果如图6所示,测试样本预测结果如图7所示,各样本间误差比较如表5 所示。
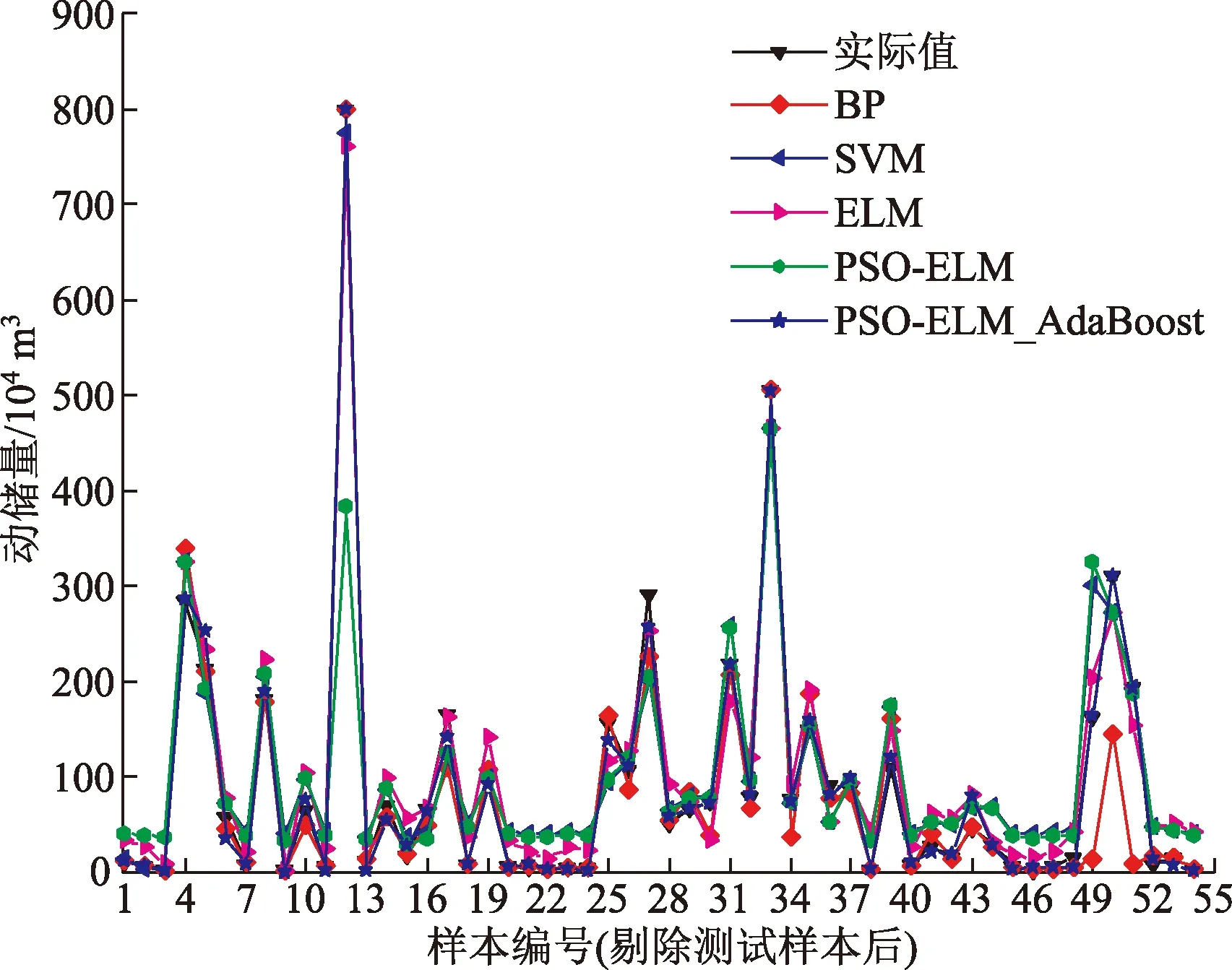
图6 训练样本预测结果对比Fig.6 Comparison of test sample training results
为比较各模型之间的可靠性与准确性,模型误差采用均方根误差(RMSE)和平均绝对百分误差(MAPE),计算公式为
(18)
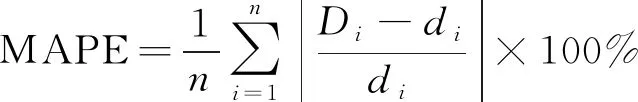
(19)
式中:di为实际值;Di为预测值;n为样本个数。
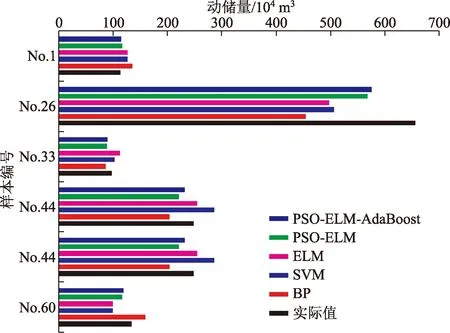
图7 测试样本预测结果对比Fig.7 Comparison of test sample prediction results

表5 各神经网络模型误差对比Table 5 Comparison of error of each neural network model
注:模型计算用时基于Intel i7-7700K、16GB DDR4内存和windows 7 64位系统的MATLAB R2016a 平台。
由表5可知,在单一神经网络模型中,ELM计算效果最好,优于BP和SVM。并且在模型用时方面,ELM计算用时为0.042 s,显著低于BP和SVM(用时分别为3.024、1.431 s),说明了ELM方法具有耗时短,效率高的优点。接着将两种耦合模型与单一神经网络模型进行对比,发现在计算精度上PSO-ELM和PSO-ELM_AdaBoost具有显著优势,训练样本和测试样本的误差评价参数RMSE、MAPE均小于前两者。在两种耦合模型中,由于AdaBoost算法“能够提高任意给定弱预测器的预测精度”的特点, 训练样本和测试样本RMSE分别降低了4.17和4.43,MAPE分别降低了1.20%和1.86%,模型误差有较大程度的减小,所以PSO-ELM_AdaBoost的计算精度优于PSO-ELM。但由于网络结构复杂程度的提升,模型用时有不可避免的增加。最后将PSO-ELM_AdaBoost模型的精度与其他计算模型[4-9]相比,精度也相对更高,可以有效地对汶川极震区内泥石流物源动储量进行计算。
对模型产生的误差进行分析,可能的原因有:①由于仪器、方法或人为原因造成野外采集的样本数据不准确,样本数据的准确性直接影响模型的精度;②流域地质环境背景有所差异。例如,测试样本中No.26和No.53在震时分别诱发了两个巨型滑坡,从而影响了模型预测精度,总体上各模型计算值均小于实际动储量,剔除后测试样本的各模型的RMSE为23.02、21.59、16.79、13.63和9.91,MAPE为16.32%、14.31%、13.94%、9.73%和6.69%;③坡体结构和岩性组合方式的区别:地层岩性对形成崩滑体具有重要的作用,其主要影响基岩和堆积体的物理力学性质;同时,不同地层岩性中崩滑体发育的规模、类型特征也不尽相同,而崩滑体多寡正是动储量形成的重要内部因素[25];④其他影响因素:物源组成颗粒的级配、密实度和泥石流沟坡向等。
3.4 模型在其他极震区的适宜性检验
为检验模型在其他极震区的适宜性,随机选择玉树地震极震区结古镇布庆隆沟、芦山地震极震区冷木沟和中岗沟作为通用适宜性检验样本,将数据进行PCA降维处理后,根据所得的PSO-ELM_AdaBoost耦合模型,进行动储量计算及误差分析。通用适宜性检验样本具体参数及预测值如表6所示。

表6 通用适宜性样本预测结果及误差Table 6 Prediction results and errors of suitability samples outside the study area
由表6可知,预测精度依然较好,能够满足实际要求。但与汶川地震极震区内预测误差相比,误差相对较大,且计算动储量均大于实际值。分析考虑是:玉树地震和芦山地震强度不及汶川地震且区域内平均降雨量较汶川地震极震区少[26-27]。因此,此处产生的误差不仅与3.3节提出的误差相关可能还与地震强度的高低和区域降雨条件的不同等因素有关。
4 结论
(1)以泥石流沟的流域面积、相对高差、主沟长度、沟床平均纵比降、较发震断裂带距离和物源总储量作为泥石流物源动储量的影响因素,对采集的汶川极震区区内的60条泥石流沟的物源信息数据,经PCA降维后,进行训练与预测,建立的PSO-ELM_AdaBoost耦合模型具有精度高、可控性强和稳定性好的特点。计算精度显著优于BP、SVM、ELM和PSO-ELM,与其他计算模型相比这些误差也相对较小,并且对其他极震区泥石流物源动储量的预测精度依然较高,满足实际要求。因此该模型可以在极震区泥石流动储量计算中发挥一定的作用,为设计泥石流防治工程提供有价值的参考。
(2)通过对模型误差的分析,在同一极震区内考虑是地质环境背景、坡体结构、岩性组合、物源组成等因素的影响。 而在不同极震区内误差的产生可能还与地震自身强度和区域降雨条件等因素有关。因此,下一步工作的重点就是如何对以上因素进行量化再分析,以继续提升本模型的适宜性和精度。
(3)随着神经网络等机器学习技术的不断发展,算法预测模型精度越来越高,但准确的泥石流实测数据是建立好的算法预测模型的基础,因此建立泥石流多发区域的泥石流沟数据库具有重要意义。
