基于改进模型RP-YOLOv3的洗扫车扫盘避障系统研究
2020-06-28龚雪1颜仁喆2
龚雪1 颜仁喆2
1.甘肃省建设投资(控股)集团有限公司 甘肃兰州 730050
2.甘肃建投重工科技有限公司 甘肃兰州 730000
1 前言
随着我国城市道路清洁作业机械化的大力推进和发展,洗扫车以其作业高效、路面清洗效果好等特点被广泛投放在城市道路清洁作业中,然而受到城市道路多样性和复杂性的影响,经常发生洗扫车在清洁作业过程中,伸出车体两侧的扫盘对站在路边的行人或停放在路边停车区域的车辆造成碰撞伤害,或者是扫盘因碰撞到路边护栏或石墩等物体造成扫盘结构件损坏的情况。虽然市面上某些品牌的洗扫车已经安装了接触式扫盘避让感应装置,但是车辆工作时仍然会因为对障碍物的识别不清导致车辆与人或障碍物体发生碰撞。
笔者通过对洗扫车工作环境的主要障碍物进行数据采集,建立了道路作业面主要障碍物数据集,并对基于深度学习的目标检测算法进行改进,提高了洗扫车道路作业时对主要障碍物目标检测的准确性和实时性。
2 道路障碍物数据集研制
2.1 数据集的研制
为了提高城市道路清洁环境障碍物数据集的质量和增加数据样本的多样性,本文试验数据集的研制采用人工拍摄、网上搜索并筛选以及COCO数据库选取这3种方式来获取,其中,人工拍摄时将相机放置于扫盘的前端进行水平拍摄,共获得各类原始数据图像1 000张,大致分为:护栏、人、石墩和汽车4类,每一类障碍物250张。
本文所采用的数据集格式为VOC数据集格式,首先在python环境下采用labelimg对每张图片的障碍物所在区域进行人工数据标注,得到障碍物的ground truth,经过labelimg标注后形成.xml文件,数据标注结果示例如图1所示。
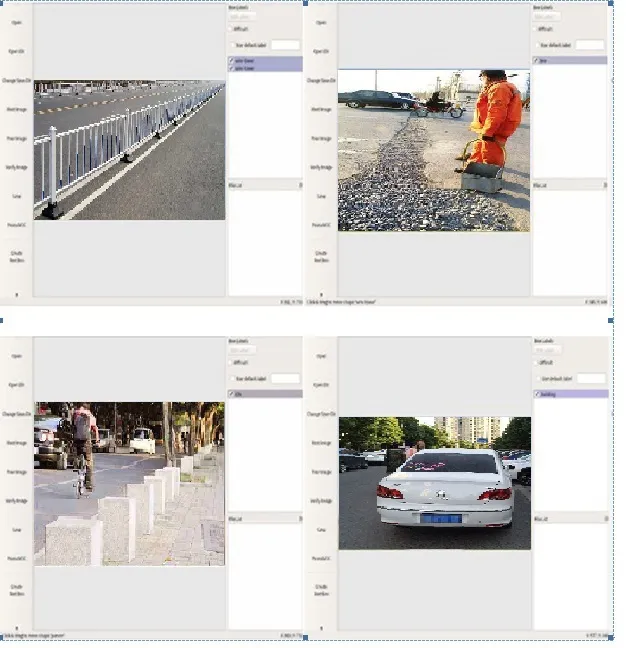
图1 数据标注示例
完成数据标注工作后建立文件夹VOCdevkit,该文件夹中包含一个VOC2018 文件夹,并在VOC2018中建立3个文件夹:JPEGImages、Annotations和ImageSets,其中JPEGImages是专门存放所收集的原始数据集,Annotations文件夹中存放完成数据标注的所有.xml文件,ImageSets文件夹中存放一个子文件夹.Main,这一文件夹中包含test.txt和train.txt文件,这些.txt文件中包含的分别为测试集图片名和训练集图片名。然后根据自己所建立数据集的障碍物分类名称修改并运行voc_label.py,则可以在VOCdevkit中自动生成各个待训练数据图像具体位置信息的.txt文件。
2.2 数据增强
为了进一步增加农田障碍物试验数据集的数量和多样性,本文采用增加噪声、改变亮度以及cutout(即随机将图像的一块或者几块位置设置为黑色)3种随机组合的方式对数据标注后的1 000幅图像进行数据增强,增强后共获得图像数据2 000幅,其中训练集选用1 600幅,测试400幅。
3 无需区域提名的障碍物检测算法
3.1 YOLOv3目标检测算法
实时目标检测模型YOLOv3由1×1的卷积层和3×3的卷积层交替连接构成53个卷积层的基础网络darknet-53。在整个YOLOv3检测模型中没有池化层和全连接层,网络通过调整卷积核的步长进行降维[1]。它将所输入图像数据,通过回归分析得到目标位置和目标所属类别,YOLOv3网络结构图如图2所示。

图2 YOLOv3 网络拓扑图
由图2看出,DBL表示卷积层和BN层以及Leaky relu层,在YOLOv3中除了最后一个卷积层之外所有的卷积层均与BN层和Leaky relu层相连接,构成一个最小单元,其中BN层起到加速网络收敛、避免训练模型过拟合的作用;resn表示图中res1,res2,...,res8的大单元,其中数字代表每一个大单元里有几个小单元的res,且每一个小单元的基本组成部分也是DBL单元[2]。YOLOv3的输出特征图分为3个不同的尺度,即为图中的y1,y2和y3。它借鉴了(FPNFeature Pyramid Network)多尺度特征提取的思想,以上采样的方式将不同尺度的特征相融合,其中细粒度的特征图可以获取尺寸较小的障碍物信息。
3.2 道路障碍物检测算法的改进和优化研究
基于Two stage类型目标检测模型的准确率优于one stage的特点,twostage类型目标检测在检测之前先生成一些候选区域,再进行目标分类和bounding box预测,从而提高了检测的准确率[3];而onestage类型的目标检测是将图片输入后经过卷积运算直接输出目标类型和bounding box。所以为了在保持实时性的情况下提高one stage类型的准确率,借鉴two stage先产生候选区域的思想实现准确率、高实时性好的检测目的[4],本文采用区域候选网络RPN(egion Proposal Network)生成候选区域对YOLOv3进行改进。
改进的网络RP-YOLOv3将输入图像大小统一归一化为416×416,采用基本网络darknet-53进行特征提取,本文改进的障碍物检测模型RP-YOLOv3网络基本构架如图3所示。图中虚线部分即为darknet-53网络基本结构,通过卷积层步长的调整,分别以stride=23、stride=24和stride=25对输入的图片进行特征提取,并获得大小分别为52×52、26×26和13×13三种尺度的特征图。

图3 RP-YOLOv3网络构架
4 优化改进检测算法的性能分析实验
4.1 改进算法的目标检测及结果分析
本文模型训练及测试平台为:Linux使用Ubuntu 16.04、GPU采用NVIDIA Tesla K40 、Python版本为3.6.5、CUDA采用9.0版本、CUDNN版本为7.0。
Learning_rate设置为0.001,Momentum为0.9,Decay设置为0.000 5,max_batches为10 000,改进后的障碍物检测模型训练过程中损失函数的变化曲线如图4所示。
从loss曲线图可以看出模型训练过程中batch在0~2000阶段下降较为明显,当batch超过8000时loss基本处于稳定状态不再下降。训练得到改进的目标检测模型后,对测试集进行测试,测试结果示例如图5所示。

图5 测试结果示例图
4.2 不同阈值检测模型的测试结果分析
θ1分别采用0.1~0.9共9组阈值训练模型RP-YOLOv3,并通过设置不同的阈值θ2对训练好的模型进行测试,其测试结果mAP如图6所示。

图6 不同阈值设置的 mAP 测试结果(/%)
图6中横坐标表示不同的训练阈值θ1,曲线变化表示同一测试阈值θ2在不同训练阈值θ1所得模型中测试所得结果mAP。从图6中纵向比较可以看出,不同测试阈值θ2对相同训练阈值θ1训练得到的模型进行测试时,随着θ2的增大,mAP在随之减小,这主要是由于测试阈值θ2越大,对预测边框与ground truth重叠率要求越高,所以阈值越大,达到指定重叠率的指标越少,从而导致mAP的下降;从图6中横向比较可以看出,同一测试阈值θ2对不同训练阈值θ1训练得到的模型进行测试时,随着θ1的增大mAP先增大,当增大到θ1=0.6附近后开始减小。根据以上分析,本文选用θ1=0.6时训练得到的目标检测模型作为最终的障碍物检测模型。
5 结语
针对基于区域提名的目标检测算法障碍物检测mAP较高,无需区域提名的目标检测算法检测速度较快的优势,提出了结合二者优势的改进优化目标检测算法RP-YOLOv3,在此基础上通过调整训练阈值和测试阈值观测 mAP的变化,并采用同一测试集对各个检测算法模型进行测试对比试验,结果表明本改进检测算法的障碍物检测准确率更高,实时性更好。
