基于多视角RGB-D图像帧数据融合的室内场景理解
2020-06-23李祥攀孙凤池
李祥攀 张 彪 孙凤池 刘 杰
1(南开大学计算机学院 天津 300750)2(南开大学软件学院 天津 300750)3(南开大学人工智能学院 天津 300750)
近年来,场景理解成为机器视觉以及智能机器人领域备受关注的一个重要问题.对于工作在人居环境的服务机器人来说,通过检测、识别场景中的各种物体并提取物体之间的关系,有助于更好地理解其所在环境,从而实现任务规划、物体搜索、人-机器人交互等自主行为.
可想而知,机器人必须全面地掌握环境中的信息,才能正确地理解环境.但是机器人搭载的视觉传感器,例如RGB-D(RGB depth)传感器,通常视野有限,无法直接采集到覆盖整个场景的图像数据帧.因此,机器人需要游走到不同视角位置采集多帧数据,并将多帧数据中的信息进行综合,才能获得其所在场景的全面信息.
为实现多帧图像数据间的信息融合,常见的做法是通过图像拼接方法将多帧图像数据整合成为一幅全景图像[1],进而进行物体检测等信息提取工作.但是图像拼接算法[2]对视角变化较为敏感,效果不稳定.另外一些做法是通过3维重建算法[3-4]进行多帧数据的信息融合,这需要进行大量复杂计算,而服务机器人工作在动态变化多发的室内环境中,维护3维模型的计算及存储代价较高.
基于以上背景,本文提出了一种基于多视角RGB-D图像帧信息融合的场景理解算法.该算法的目标在于通过物体实例检测将不同图像帧的物体检测结果、关系提取结果进行融合,最终得到表征整个场景理解结果的物体关系拓扑图.该算法流程如图1所示,首先对多帧图像逐帧进行物体检测与关系提取,随后将每帧图像物体检测结果与场景中已知的同类物体进行实例检测,将重复的物体实例去除,将新发现的物体实例与原有的物体关系图进行融合,根据融合结果对物体关系图进行更新,以此迭代完成整个场景的物体检测和关系提取.
本文主要贡献有2个方面:1)对RGB-D图像帧进行划分并提取图像单元的颜色直方图特征,基于此提出了基于最长公共子序列的跨帧物体实例检测算法,以支持多视角图像帧的融合;2)完成了面向室内整体场景、融合多视角RGB-D图像帧的场景理解,并生成物体关系图作为场景理解的结果模型.
1 相关工作
1.1 物体检测
物体检测是计算机视觉领域的研究热点,也是机器人领域场景理解任务的关键问题.近年来,深度卷积神经网络(convolutional neural network,CNN)已经成为物体检测任务的基础工具[5].深度神经网络在提取图像高层抽象特征方面性能优越,早期的工作如R-CNN[6](region-based convolutional neural network)以及其加速版本Fast R-CNN[7]使用深度卷积神经网络提取特征,结合候选框提取算法实现物体检测.后续工作Faster R-CNN[8-9]提出候选框提取网络(region proposal network, RPN)将候选框提取过程囊括至端到端的网络模型中.Mask R-CNN[10]在Faster R-CNN的基础上添加了用于分割物体实例的网络分支,实现了集物体检测和语义分割于一体的网络模型.
1.2 物体实例检测
物体实例检测算法的目标是检测出现在不同图像帧中的同一物体的实例.一些使用纹理特征(例如灰度共生矩阵[11])的算法通过描述物体表面纹理分布来进行物体实例判别.Bao等人[12]使用基于部件的表示方式对物体实例进行建模,并通过物体的部件外观和几何特征进行比较来判断物体对象的外观一致性.通过特征点匹配进行物体实例检测[13-14]是另一种算法思路,这种算法对于平面的形变具有一定的鲁棒性,但同时受视角变化影响较大.
图像检索问题[15]与物体实例检测具有关联性,同时也存在明显差异.图像检索算法通常对图像整体进行相似度评估,而物体实例在不同视角下往往会在整体上产生较大的差异.
1.3 环境建图
地图构建是智能机器人领域的一个经典问题,近年以来,集成了空间几何信息和物体属性信息的语义地图成为主流的地图格式.Silberman等人[16]将室内RGB-D数据解析为地板、墙壁、支撑面和物体等区域,然后恢复不同区域之间的支撑关系.Koppula等人[17]利用各种特征和上下文关系,包括局部视觉外观、形状、物体共现和几何关系等,对点云数据进行语义标注,同时抽取不同语义点云之间的邻近或者上下关系.
语义地图可用于导航和各种操作任务,但其存在存储消耗大、构建及维护计算量大的问题,且在环境发生动态变化时鲁棒性较差.因此Ikehate等人[18]定义了一系列的图结构生成室内环境的结构化模型,如以图节点表示房间、墙和物体等元素,以实线表示2个节点具有公共边界,以虚线表示没有边界约束的附着关系等,与语义地图相比,这种地图具有结构简单、易于构建和维护的优点.类似地,本文提出结构简单、易于构建和维护的物体-关系拓扑图作为场景理解的表达.
2 物体实例检测算法
本文算法在融合多图像帧中的物体检测结果时,需要识别出现在不同图像帧中的相同物体实例,物体实例是指在不同视角图像帧中出现的同一个物体的样本.在识别物体实例时,物体的颜色特征比结构特征更加具有区分性,但在不同图像帧中,物体的完整性与视角均可能发生变化,因此,同一个物体实例在不同图像帧中的整体颜色特征可能产生较大差异,在此背景下本文采用基于图像单元的颜色特征提出了物体实例检测算法.
2.1 图像划分和LCS算法描述
在不同视角下,物体实例的完整性与位姿均会发生变化,因此,同一物体实例的颜色直方图在不同图像中也会有较大差异.但同时,不同图像帧中的相同物体实例会具有一定的共同部分,为了更好地表达这种跨帧、跨视角的部分对应关系,划分为若干个细胞单元,则其细胞单元之间具有相应的对应关系,如图2所示:
本文引入最长公共子序列算法(longest common subsequence, LCS)描述2个图像的细胞单元序列的相似程度[19-20].LCS算法在文本分析中常用来计算2个字符串的相似度.对于2个字符序列(S1,S2),记S1i,S2j分别为序列S1,S2的子序列(S10,S11,…,S1i),(S20,S21,…,S2j),则VLCS(S1i,S2j)计算方式为

(1)
LCS算法可以通过动态规划进行优化,即引入状态数组对中间状态进行记录以避免多层递归.假设字符序列(S1,S2),其长度分别为(l1,l2),其状态数组记为c[l1,l2].在计算过程中,首先将数组的第1行和第1列初始化为0,表示2个序列其中之一长度为0的情况.随后从c[1,1]开始,按照从左向右、从上到下的顺序,计算数组中每个位置的值:
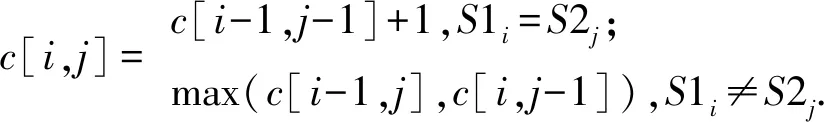
(2)
最后,数组右下角的数值c[l1,l2]即为序列(S1,S2)的最长公共子序列长度.在本文中,2幅图像分别被均等划分为n个细胞单元,则在获取2个图像单元序列的最长公共子序列长度后,即可计算2个图像单元序列的相似度:
similarity(S1,S2)=VLCS(S1,S2)/n.
(3)
当2个图像子单元序列之间的相似度大于某阈值时,则认为2个图像序列代表的是同一个物体,实验中阈值选择为0.55.
2.2 图像细胞单元相似度定义
图像单元并不像字符一样可以直接比较是否相等,因此本文提取图像细胞单元的颜色特征以描述2个图像单元的相似性.颜色直方图是反映颜色分布的重要特征.本文使用RGB颜色空间统计颜色直方图,以R(红色)、G(绿色)、B(蓝色)这3种基本色为基础,进行不同程度的叠加来表示不同的颜色模型,其中每种基本色按亮度的不同分为256个等级.
由于在不同视角处光照条件也存在差异,因此同一物体实例在不同图像中成像亮度可能发生变化.为减少亮度变化带来的影响,在统计颜色直方图时将256个亮度等级平均划分为8个区间,每个区间大小为32,即每个通道将产生一个8维直方图向量.随后,每个通道的直方图向量被归一化至区间[0,1],记为r,g,b.为了更加精细地表达颜色分布,将3个直方图向量r,g,b两两对比,计算其差的绝对值,形成通道之间的颜色对比向量,计算方法为
cmp(α,β)=abs(α-β).
(4)
将3个颜色通道RGB各自像素值的总和记为SR,SG,SB,记SA=SR+SG+SB,则图像的颜色直方图特征为
feature=(r,g,b,cmp(r,g),cmp(r,b),
cmp(g,b),SR/SA,SG/SA,SB/SA),
(5)
其中包含6个8维向量和3个实数.当2个图像单元进行比较时,对于颜色直方图特征中的6个8维向量,分别计算对应向量之间的欧氏距离,对于特征中的3个实数,分别计算对应实数之间差的绝对值,最终将计算结果串联为9维向量,该向量即用来描述2个图像单元间的相似性.通过训练支持向量机(support vector machine, SVM)来判断2个图像单元是否能够视为同一个“字符”.
3 融合多视角图像帧的场景理解
本文基于第2节给出的物体实例检测算法,实现基于多视角图像帧的场景理解,即通过物体实例检测算法将多帧图像中的物体检测结果进行融合,构建场景中的物体关系拓扑图.下面对物体检测和物体关系图构建2个方面的内容进行详细介绍.
3.1 基于Mask R-CNN模型的单帧图像物体检测
随着深度学习在物体检测领域的应用,各种深度网络模型被相继提出,物体检测的精度也逐渐提高.Mask R-CNN是用于物体检测与语义分割的深度网络模型,该模型在Faster R-CNN的基础上添加了物体实例分割分值,因此能够同时进行物体检测与语义分割.本文使用在数据集上预训练好的Mask R-CNN模型,在NYUv2(NYU depth dataset v2)数据集[15]上微调,进行物体检测.
NYUv2数据集包含1 449张标注的RGB-D图像,来自3个城市中484个不同的商业和住宅区域.本文将该数据集手工划分为610个场景片段,表1展示了含有不同数量图像帧的场景片段分布情况.其中,包含图像帧数量为1的场景片段即为独立的单帧图像,包含图像帧数量超过4的场景片段多采集于商场等大型场景.考虑到本文的研究背景,将包含图像帧数量为2,3,4的图像划分为测试集,其他图像划分为训练集.本文在划分后的数据集上使用经过微调的Mask R-CNN模型进行物体检测.

Table 1 Statistics of Scene Fragments表1 分布情况
3.2 基于物体实例检测的多帧图像融合
对于同一场景采集的多帧图像,首先使用3.1节给出的算法对单帧图像进行物体检测,然后使用前述物体实例检测算法将单帧图像中的每个物体与当前场景中已有的物体进行比对以进行去重复处理,从而获取对场景中所有物体的检测与识别结果.
3.3 物体关系图构建
在基于多视角图像帧完成对整个场景中的物体进行检测识别之后,提取物体之间的关系,构成物体-关系拓扑图,作为场景理解结果的呈现形式.简单起见,本文仅考虑物体之间的相对位置关系.
随着深度传感器的普及使用,能够方便地获取场景的深度数据.深度图像包含了显式的空间信息,为提取物体之间的相对位置关系提供了方便.与文献[21]类似,本文定义了物体之间最常见的2类空间关系,分别是“邻近”与“上下”关系.在获取深度图像后,首先使用中值滤波对图像进行降噪以去除边界处的毛边,随后计算每个物体框之间的豪斯多夫距离.对于点集A和B,豪斯多夫距离计算过程是:首先计算点集A中的任一点ai到点集B中任一点bi的最短距离di,然后选取其中的最大值,即为点集A和B之间的豪斯多夫距离,表示为
H(A,B)=max(a∈A){min(b∈B)d(a,b)}.
(6)
对于某个物体O而言,周围物体与其关系存在如图3所示的2种情况.
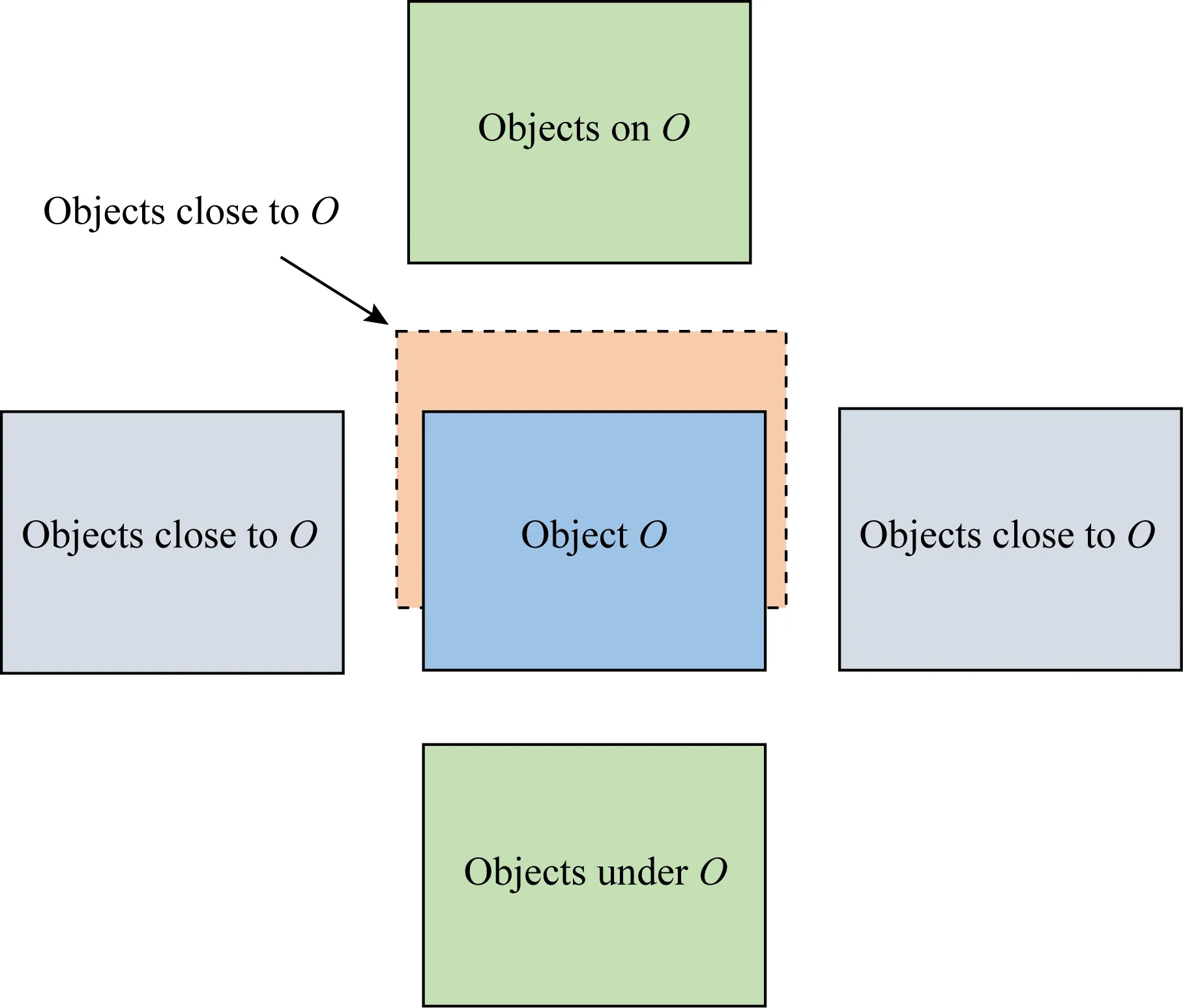
Fig.3 The relationship between objects图3 物体关系示意图
对于“邻近”关系,2个相互邻近的物体在图像中可能表现为左右相邻和前后相邻,由于存在视角变化,左右相邻和前后相邻能够在不同视角下互相转化,因此统一表现为“邻近”关系.而“上下”关系不受视角的影响,只存在一种情况.然而,对于 “邻近”关系和“上下”关系,其整体豪斯多夫距离可能是十分相近的,因此对于2个物体框只计算水平方向和深度方向的距离,最后以2个物体框垂直方向上的中点距离以及垂直投影重叠度来判断其上下关系.同时,由于存在透视现象,距离传感器越远的物体在图像上成像越小,因此在计算水平方向的距离时设置了一个与深度大小相关的系数,即:
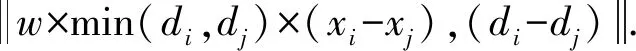
(7)
当2个物体框之间的豪斯多夫距离小于某个阈值T1时,则认为其存在关系,否则认为其距离很远,相互之间影响力较小,不产生关系.当2个物体框靠近且2个物体框之间的垂直中点距离大于某阈值T2,并且二者水平向下的投影重叠度超过某阈值T3时,判断其为“上下”关系,否则为“邻近”关系.
本文使用有向图结构构建物体关系图.对于物体关系,本文设置了语法规则构建物体关系图:
1) 有向图中每个节点表示一个物体;
2) 节点具有颜色属性,该属性表示了物体的类别信息;
3) 具有“邻近”关系的物体之间使用虚线无向边进行连接;
4) 具有“上下”关系的物体之间使用实线有向边进行连接,有向边由上方的物体指向下方的物体;
5) 不存在任何关系的物体之间不存在边.
可见,与经典的机器人地图相比,物体关系图不保留原始图像数据、不进行3维环境模型重建,因此所需计算量、存储量大大减少,且图的表达形式更为直观,可以较好地支持语义导航、物品搜索等机器人典型任务.例如物品关系图中的邻近关系,可以帮助机器人根据已经发现的物品定位未知相关物体的搜索区域.
4 实验结果与分析
4.1 物体检测实验
本文使用在NYUv2数据集上微调的Mask R-CNN模型检测其中的物体.该实验中,物体类别共有21类,训练图像832张、测试图像617张.表2展示了物体检测实验效果:
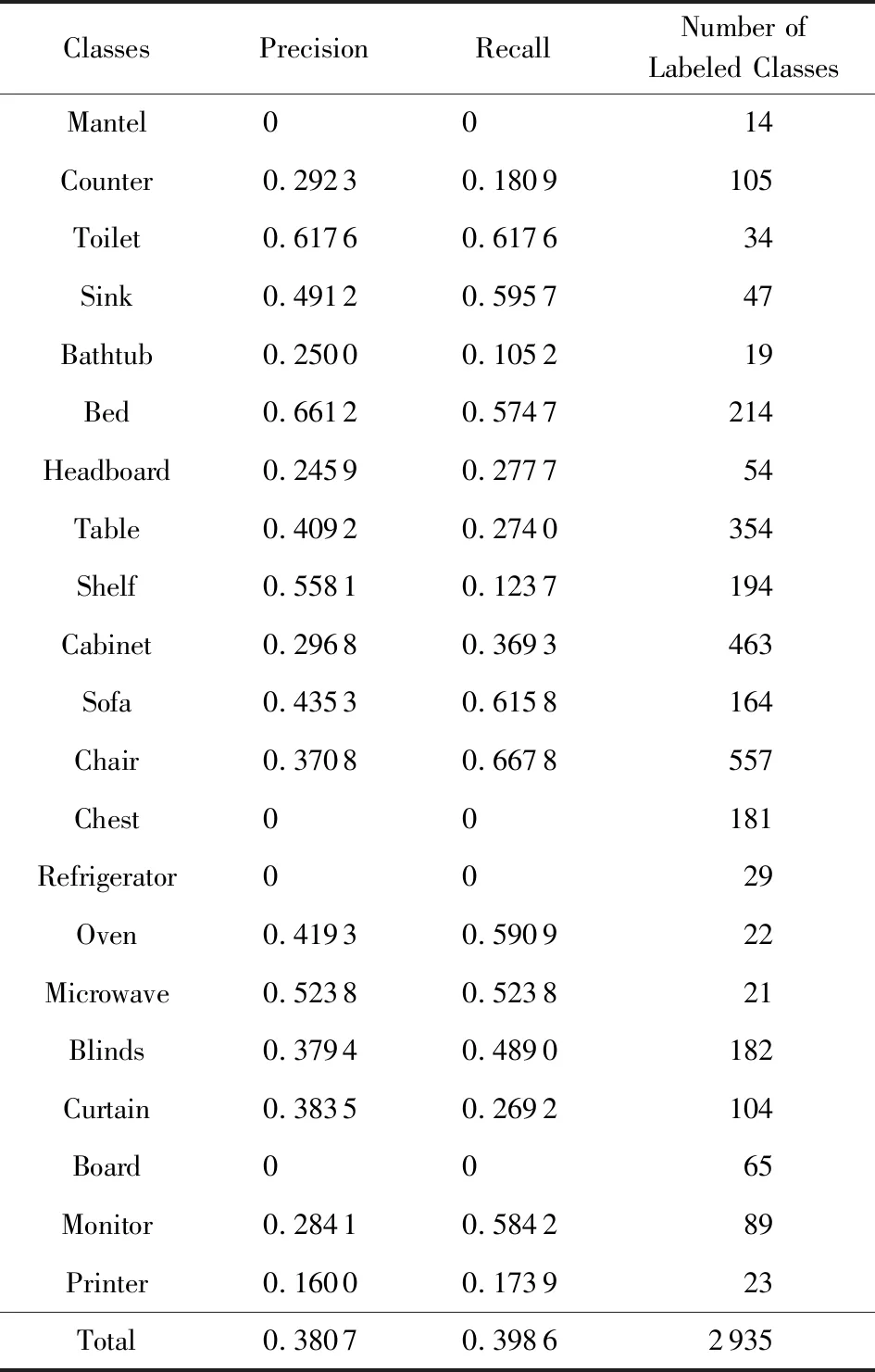
Table 2 Results of Object Detection表2 物体检测结果展示
4.2 物体实例检测实验
本节描述了2个实验.第1个实验在NYUv2数据集中选取了207对正样本、142对负样本,对比本文提出的基于图像细胞单元的颜色直方图特征算法与整体颜色直方图特征算法(记为SimColor)和基于ORB(oriented FAST and rotated BRIEF)特征匹配的算法(记为ORB-Match)的实例检测效果,展示本文算法的有效性.正样本为出现在不同图像帧中同一物体实例对,负样本则为随机选取的不同物体实例.
整体颜色直方图算法统计样本对的整体直方图,并计算对比向量,然后训练SVM分类器来判断其是否为同一物体实例.基于ORB特征匹配[14]的算法通过统计样本对中高质量ORB特征匹配点的数量,判断是否同一物体实例,本文设定匹配点数量大于等于4即表示同一物体.
表3展示了不同算法的检测结果,由表3可见本文提出的算法在该样本集上表现出了更好的效果.此外,实验表明该算法对视角、光照条件等因素的变化所带来的影响具有更好的鲁棒性.
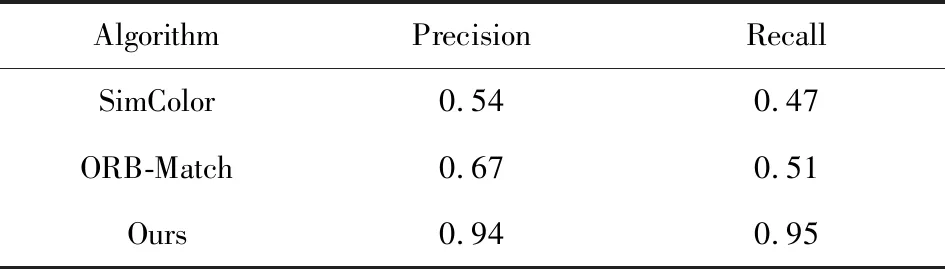
Table 3 Results on Positive-Negative Samples表3 正负样本集实验
第2个实验对NYUv2数据集中的58个场景片段进行了标注与实验,每个场景片段包含几帧不同视角的图像,包含379对物体实例对.表4展示不同算法检测结果的精确率与召回率,并使用F-Score对精确率与召回率进行综合评估.F-Score是精确率(precision,P)和召回率(recall,R)的加权调和平均,常用来评估分类模型的好坏,计算为

(8)
其中δ=1.
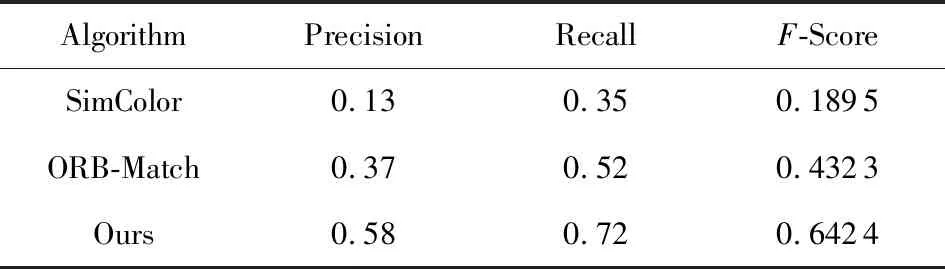
Table 4 Results on NYUv2表4 综合实验
实验结果如表4所示,可以得出,本文基于图像细胞单元的颜色直方图物体实例检测算法精确率和召回率均优于整体颜色直方图算法及基于ORB特征的匹配算法.
4.3 场景理解与关系图构建实验
本实验展示了实例检测结果和建立物体关系图的过程.表5,6展示了融合计算过程,其中Monitor1_added代表已经加入到场景中的显示器实例1,使用Monitor1_f2代表第2帧图像中的显示器实例1.表5,6中仅列出对比的物体实例.表7给出了某个具有3帧图像的室内场景的理解与建图过程.
在表7中,第1帧图像有4个物体被检测出来.由于物体关系拓扑图初始状态为空,因此4个节点均被添加至关系图中,使用3.3节中描述的方法判断显示器2和打印机1是相邻的关系,显示器2和打印机1之间用无向虚线连接.
在第2帧图像中4个物体被检测到,其中显示器和打印机已经出现,因此使用第2节描述的物体实例检测算法比较同类别物体的相似性.从表5中可看到,第2帧中的显示器与场景中已有的显示器实例1匹配度更高,且大于阈值0.55,所以认为第2帧图像中的显示器为已有显示器实例1,打印机实例的判别过程类似.使用3.3节中描述的方法判断打印机1位于桌子1上,所以打印机1和桌子1之间使用有向实线连接,箭头由打印机指向桌子,其余判定相邻的物体使用虚线连接.第3帧图像的融合过程类似,融合计算参考表6.

Table 5 Multi-Frame Fusion Process Step 1表5 多帧融合过程-第1步
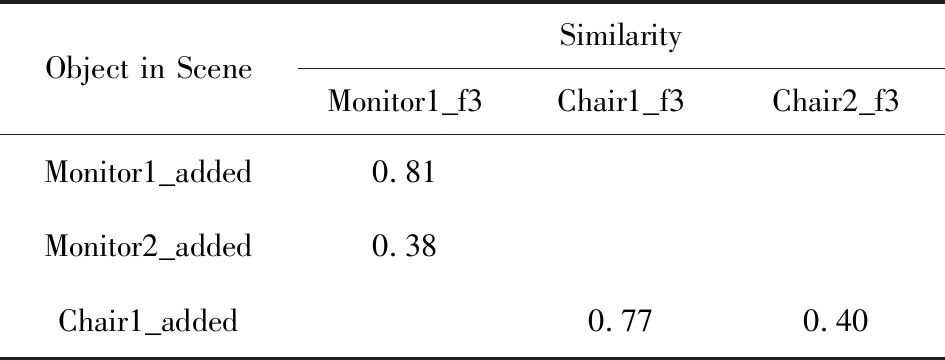
Table 6 Multi-Frame Fusion Process Step 2表6 多帧融合过程-第2步

Table 7 Result of Scene Understanding and Map Building表7 场景理解与建图结果

5 总 结
本文提出了一种直观有效的跨帧物体实例检测算法,并在此基础上实现了基于多视角RGB-D图像帧信息融合的室内场景理解,融合多帧图像中的物体检测结果,并提取物体间的拓扑关系,构建场景内的物体关系图.该算法能够有效集成多帧图像中的场景信息,实现整体场景理解.如何进一步提高算法的实时性,并应用于移动机器人的在线运行及具体任务,是下一步的研究方向.
