通用图形处理器缓存子系统性能优化方法综述
2020-06-23谢竟成沈凡凡汪吕蒙何炎祥
张 军 谢竟成 沈凡凡 谭 海 汪吕蒙 何炎祥
1(东华理工大学江西省放射性地学大数据技术工程实验室 南昌 330013)2(东华理工大学信息工程学院 南昌 330013)3(东华理工大学创新创业学院 南昌 330013)4(武汉大学计算机学院 武汉 430072)5(南京审计大学 南京 211815)
图形处理器(graphics processing unit, GPU)最初是一种专门用于图像处理的微处理器,随着图像处理需求的不断提升,其图像处理能力也得到迅速提升.2006年12月4日英伟达(NVIDIA)公司发布新一代显卡Geforce 8800时,首次在公开发布的技术参数中使用了流多处理器(streaming multi-processor, SM)的概念.自此统一的渲染部件颠覆了传统可编程部件组织的像素渲染管线(pixel pipelines)和顶点着色单元(vertex pipelines),形成了当今通用图形处理器(general purpose graphics processing units, GPGPU)[1]的基本雏形.随后,流式图形处理器为GPU在通用计算领域的发展奠定了基础.随着CUDA和OpenCL这些编程模型的出现,在GPU中设计并行程序进行通用计算已经不再困难.
在如今的高性能、高通量通用计算领域,GPGPU已经得到极其广泛的应用,并正在日益扩大其应用范围.强大的并行计算能力和高能效比亦使GPGPU成为构建高性能计算系统的首选.2019年11月公布的超算Top500中,位于榜首的Summit[2]由美国IBM公司制造,它使用近28 000块NVIDIA Volta GPU,为其提供了95%的算力.榜单的第2名Sierra也使用了17 280个NVIDIA Tesla V100 GPU构建异构计算平台.在GPGPU强大算力的帮助下,它们的计算能力均超越了我国排在榜单第3位的神威·太湖之光,尤其是Summit在理论计算能力上超越了神威·太湖之光计算能力的60%[注]1SC19世界超算大会发布第53届超算TOP500榜单:美国超算Summit蝉联世界超算冠军,https://www.top500.org/lists/2019/11/.
现代GPGPU支持单指令多数据流(single instruction multiple data, SIMD)[3-4]的执行模式.目前主流的GPGPU内部内置了大量的寄存器,其大小通常达到数KB,能够很好地支持数以万计的并发线程的同时执行,因此,其执行模式又可以称为单指令多线程(single instruction multiple thread, SIMT)[5-6]执行模式.该执行模式下,执行同样任务的线程被组织在一起,以获得很高的线程级并行(thread level parallelism, TLP).
与CPU相比,GPGPU内部的流水结构可以有效实现3个并行级别[7-8],即指令级并行(instruc-tion level parallelism, ILP)、数据级并行(data level parallelism, DLP)与TLP,从而很好地满足高性能、高吞吐量应用场景的计算需求.
通过设立大量的寄存器和片上缓存,GPGPU支持成千上万高度并发线程的执行.如有线程出现长延时操作,则立即切换至其他活跃的并发线程执行,从而实现对长延时访存操作的隐藏.然而,如此多的并发线程可能会同时发出大量的访存请求,容易出现对片上缓存资源的争用现象.同时,不规则访存模式的存在使得并发线程的访存变得离散,并导致产生更多的访存请求,使得片上缓存资源的争用现象会进一步加剧,严重时甚至会产生访存“抖动”现象.这使得GPGPU缓存中的数据局部性受到破坏,影响整个存储子系统的访问效率.另外,片上的访存队列资源也因此会迅速用尽,造成部分线程后续的访存操作无法得到及时的服务而被阻塞.当SM产生空闲时,整个GPGPU的性能将会下降.因此,优化缓存子系统的性能,对保证GPGPU稳定发挥高计算性能具有重大意义.
采用更合理的线程调度策略、存储访问策略、更优秀的缓存子系统架构设计,可有效改善GPGPU缓存子系统的访问性能.有学者早在十年前就展开了能增强GPGPU缓存子系统性能的调度方法优化研究[9-10]和体系结构优化研究[11].本文从优化TLP调节、优化访存顺序、数据通量增强、LLC优化、基于NVM的新型缓存架构设计等方面,重点分析并讨论近几年来国内外关于提升GPGPU缓存子系统性能的优化方法.
1 GPGPU结构及相关概念
目前,主流GPGPU生产厂商主要有NVIDIA、超微半导体(AMD)和英特尔(Intel),它们的产品有着相似的宏观结构.为统一论述,本文以NVIDIA公司发布的GPGPU体系结构为基础,并使用其术语进行问题的描述和分析.
1.1 GPGPU线程的组织和调度
为了高效地管理和调度GPGPU中线程的执行,GPGPU并发执行的线程被组织为线程网格、线程块、线程组3个层次结构[12-13],如图1[13]所示.
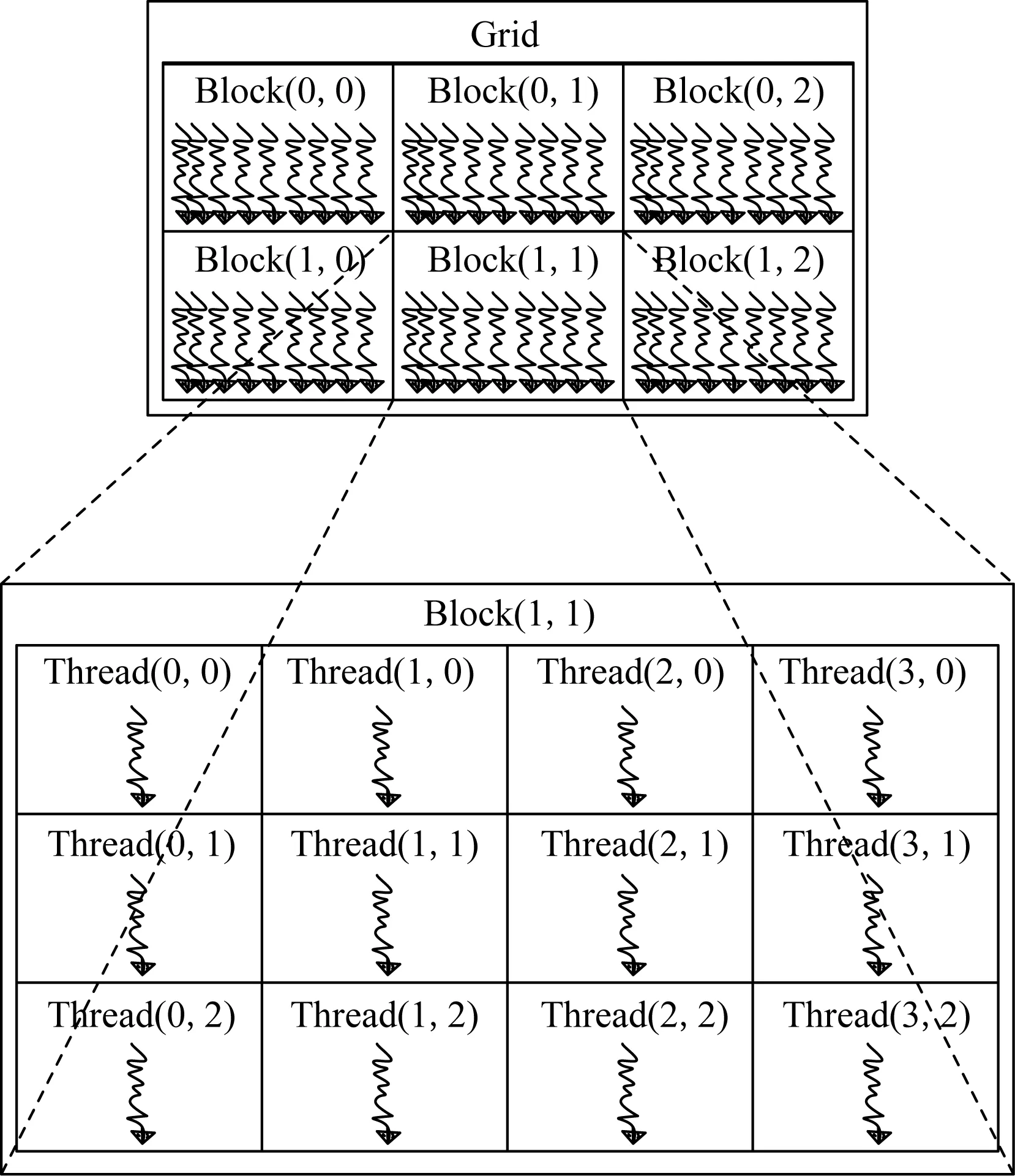
Fig.1 Organization of threads in GPGPUs图1 GPGPU中线程的组织
GPGPU中32个相邻的、执行同一条指令的多个线程组成一个线程组,称之为warp,它是GPGPU调度任务并行执行的基本单位.在同一个warp中,所有线程均按照锁步方式执行.当某个warp中不同的线程执行不同的分支指令,需要该warp中所有的线程均执行完各自分支路径上的所有指令后,该warp才能继续向后执行.
多个相互协作的warp被组织成一个CTA(collaborate thread array).同一个CTA中的线程之间可以相互通信.同时,CTA是被分发调度的任务单位.通常情况下,CTA通过轮转的方式被依次分配到各个SM中执行,每个SM独立对CTA中的数个warp调度执行.CTA的大小通常由程序员指定,其规模一旦确定就不再变化.为了更好地组织、管理和调度线程,多个CTA又被组织成线程网格(thread grid, TG).
关于GPGPU的宏观和微观架构,已有诸多文献[14-19]详细描述,在此不再赘述.
1.2 缓存子系统的层次结构
通常,GPGPU的缓存子系统主要由片上一级缓存(L1 cache)、二级缓存(L2 cache,由于主流的GPGPU中只设计了两级的片上缓存,因此又可以称为LLC)和片上互联网络(network-on-chip,NoC)组成.如图2所示,每个SM都具有4种不同的片上一级存储器,包括可以存放CTA内共享数据的共享存储器(shared memory)、为本地访存服务的私有数据缓存(private data cache)、存放纹理数据的纹理缓存(texture cache)以及存放常量和参数的常量缓存(constant cache).其中,前两者是可读写的,后两者是只读的(在现有的GPGPU性能优化研究中,后者基本未被分析考虑).
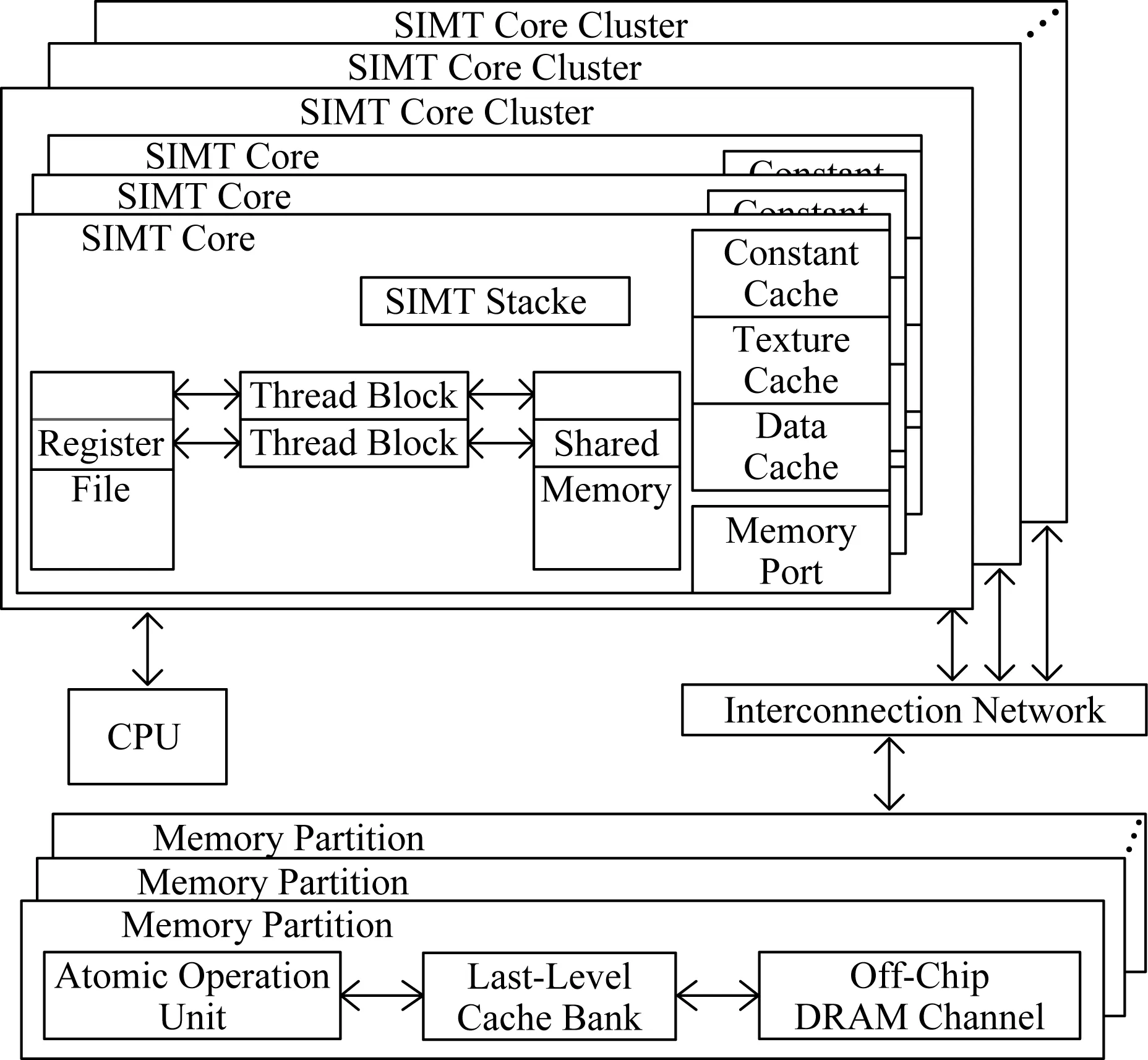
Fig.2 The basic logical structure of GPGPUs图2 GPGPU的基本逻辑结构
正常情况下,GPGPU上的数据缓存每周期至少能处理一个访问请求.当访问请求未命中时,通过有限规模的访问失效状态保留寄存器(missing status hold register, MSHR)记录和合并对同一缓存行的失效请求,并据此向低一级的缓存进行访问.MSHR被设计为一个包含多个表项的全相联寄存器,其中的每个表项服务一个缓存行的访问失效.
从图2可以看出,GPGPU中的数个SM组成一个簇,并通过NoC连接到LLC.NoC只传递4种类型的数据:1)从SM发送到LLC的读请求和;2)写请求;3)从LLC发送到SM的读应答和;4)写确认.通过NoC,可以实现片上一级缓存和二级缓存之间的数据访问.
2 缓存子系统性能优化方法
GPGPU中的运算部件所需要的数据如果无法从寄存器中得到,则会直接从片上缓存子系统中申请访问.因此,缓存子系统的性能高低对GPGPU的性能影响很大.
GPGPU缓存子系统性能的下降通常是由缓存资源竞争和访存行为不规则这2个主要原因引起.虽然GPGPU片上的缓存容量较大,但由于GPGPU上同时执行的并发线程数量过于庞大,使得GPGPU的缓存资源显得非常紧张.如果执行访存密集型应用程序,则很容易引起GPGPU片上资源的争用.另外,目前有很多应用在GPGPU上执行的过程中,即使是在同一个warp内部,也存在不同线程访问的数据属于不同的数据块,这种离散的访存行为进一步加剧了片上缓存资源的争用.
目前解决上述问题的常用方法主要包括:1)通过TLP调节技术,使得片上可以执行合适数量的并发线程;2)在TLP一定的条件下,通过调整线程的执行顺序,改变线程间的访存顺序,从而有效提升GPGPU缓存子系统隐藏访存长延迟的能力;3)通过数据通量增强技术,提高NoC的数据访问服务能力,从而提高服务密集访存行为的能力;4)提高LLC对片上一级缓存数据访问服务的能力;5)利用NVM新型存储材料存储密度高、读性能好的优势,优化GPGPU缓存子系统结构设计,可以大大提高GPGPU的片上缓存容量,从而更好地提升缓存子系统的数据访问效率.因此,本节将从上述5个方面展开论述.
2.1 TLP调节技术
在一个SM中,只要有一个warp可以继续执行计算任务,其他线程的访存延迟就可以被有效隐藏.并行线程数量的上升将有利于提升GPGPU隐藏访存延迟的能力,并且更多的并发线程也可以更好地保持资源的高利用率.因此,GPGPU应尽量维持高的TLP.但是,当出现片上缓存资源的争用加剧时,应适当降低TLP.
在现有针对TLP调节技术的研究中,更多的是倾向于基于不同类型任务的特点,充分利用GPGPU隐藏长延时访存操作的能力,既可以有效提升系统计算资源的利用率,又能使有限的缓存资源满足尽可能多并发线程的访存需求.
根据不同任务的计算/访存占比,大致可以将任务分为计算密集型任务和访存密集型任务2类[20].其中,计算密集型任务的计算操作次数相对访存操作次数更多,访存密集型任务则与计算密集型任务相反.对于访存密集型任务,如遇到缓存命中率低的情况,则会频繁地更新缓存(尤其是一级缓存)中的数据.
为了很好地分析说明TLP对GPGPU性能的影响,我们使用目前流行的GPGPU性能分析模拟器GPGPU-Sim[19]开展了相关实验.实验中采用的基准体系架构基于NVIDIA的Fermi[15,21]架构,基准测试程序包括BFS,MUM,NN.图3描述了在每个SM上逐步增加可并发执行的CTA数量时这3个应用程序性能的变化情况.此处的性能用每周期指令数(instruction per cycle, IPC)表示.从图3可以看出,BFS的性能随TLP的变化不大;MUM的性能则是当SM中并发的CTA数量为2时最大,随着CTA数量的继续增加,其性能呈现不断下降的趋势;NN的性能则随着TLP的增大而不断提升.通过分析发现,MUM的访存次数明显高于其他2个应用,TLP的增加会加剧片上缓存资源的争用.
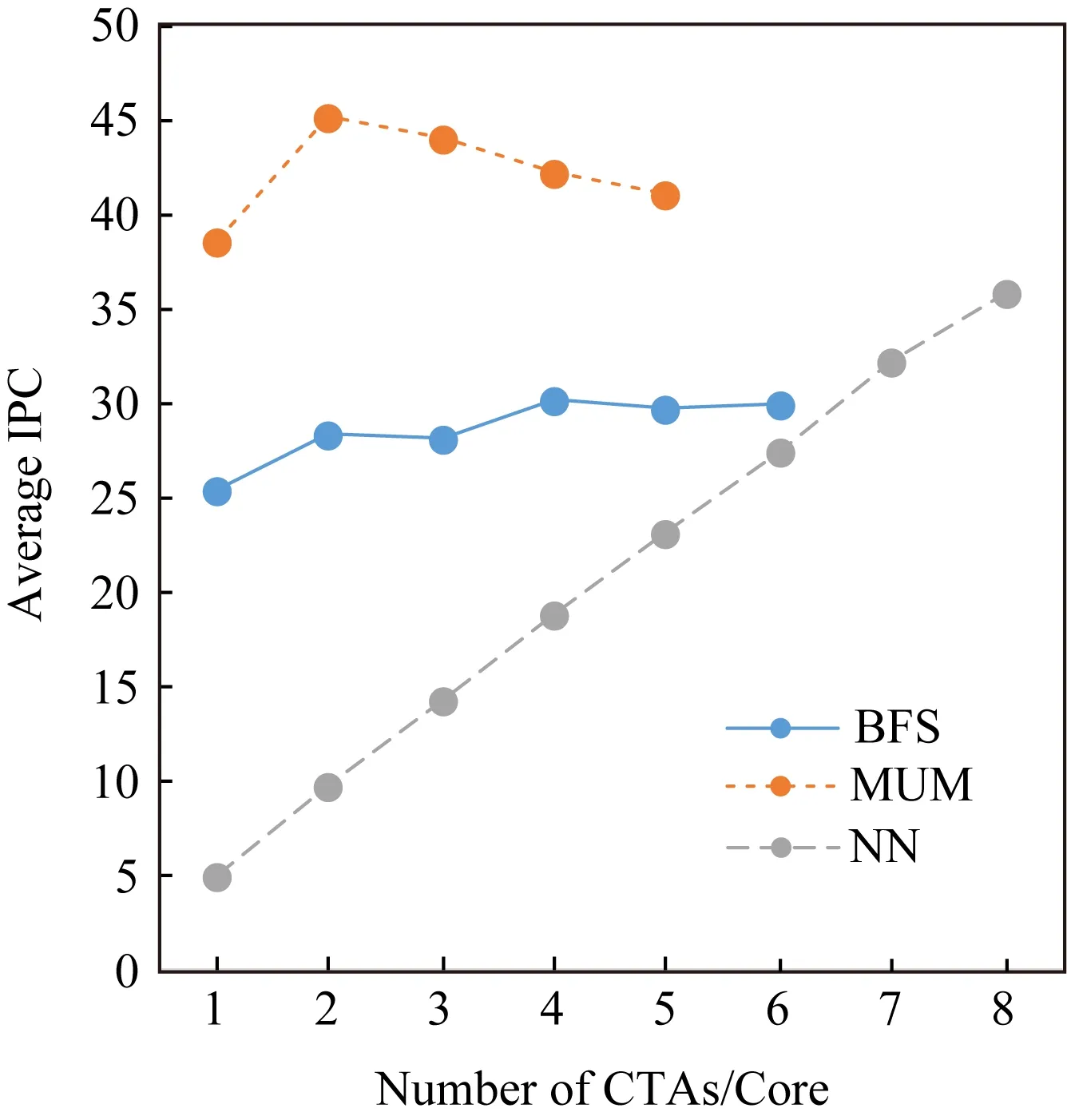
Fig.3 Changes in average IPC with CTA number图3 平均IPC随CTA数目的变化
对于多应用并发执行的情形,应针对不同应用的特点,为不同的应用分配不同的资源.对于计算密集型任务,可以适当调高TLP,让其能更好地利用计算资源.而对于访存密集型任务,应适当调低其TLP,从而在保持高资源利用率的情况下,防止片上缓存资源被过度地争用.因此,此类问题的研究中,通常都倾向组合不同特性的任务并发执行,这样的技术被称为CKE(concurrent kernel execution)技术.该技术也是目前TLP调节技术的研究热点.
目前,针对GPGPU缓存子系统性能提升的TLP调节技术主要从CTA和warp两个不同的粒度层次进行研究.这些研究主要集中在3个方面:1)增大TLP;2)通过cache绕行技术,在不降低TLP的前提下避免稀缺资源拥塞;3)限制各并行任务的TLP,以避免过度的资源争用.
2.1.1 提升TLP技术
正如图3所示,对于有的应用程序来说,增大计算任务的TLP可以带来更强的延迟隐藏能力,可以容忍更长的访存延迟和更密集的访存请求,这意味着可以增强对不规则访存行为的处理能力.
近几年,不少研究人员发现提升TLP可以有效提升GPGPU的性能,此类研究主要集中于CKE技术.
在Fermi架构之前,单一时刻一个GPGPU上只支持单kernel的运行,片上资源的利用率普遍较低,甚至可能造成某些硬件资源剩余.在推出Fermi架构后,可以利用片上的剩余资源运行其他的kernel.较早的CKE技术[22-24]主要关注多kernel的并行性和公平性,但未注重片上缓存子系统的状态,因此GPGPU的整体性能难以达到最大.
为了使不同类型的kernel互补性地使用SM的片上资源,Xu等人[25]和Wang等人[26]分别提出了Warped-Slicer及SMK算法,实现了对不同类型kernel的组合优化执行.在SM资源分配接近耗尽时,SMK会将大量占用最稀缺资源的CTA换出,换入占用稀缺资源较少的、规模更大的CTA,进一步提高TLP.同时,SMK使用的抢占技术需要在GPGPU中进行上下文切换,产生了大量的缓存数据交换[27],造成性能损失.Park等人[28]提出精确控制开销的协同抢占方法Chimera,采用了CTA的flush、上下文切换和drain等3种抢占方式,有效降低了由于抢占带来的性能开销.Li等人[29]提出提前保存状态的方法PEP,也较好地减少了上下文切换的开销.Park等人[30]则在SMK的基础上,与空间多kernel并发处理框架[22]相结合,使资源分区更合理,超过了SMK性能的13.9%.此外,Liang等人[31]提出了将不能充分利用的资源分配给其他已经正在运行的kernel,提升了整体的运行速度.
CKE技术通常会受到固定的资源分配方案和任务组织方案的限制,灵活调整这些规则,有利于提升片上资源利用率.分立结构的片上存储器各自固定不同层次的缓存容量,使用可调节的统一片上存储器[32]替代,可以根据任务需求调节不同类型存储器的容量,有利于将SM上的CTA数量分配到极限.但SM上并发的CTA数量是受到严格限制的,若所有并发CTA所使用的缓存资源都较少时,片上的缓存等资源将得不到充分利用,造成片上资源的浪费.Yoon等人[33]提出了一种虚拟线程(virtual thread, VT)体系结构,将每个SM上并发执行的CTA数量分配至硬件容量的极限,并将这些并发的CTA置为活动和非活动状态,活动并发执行的CTA数量仍然符合硬件物理限制.当处于活动状态的某个CTA中的所有warp到达一个较长的访存延迟时,该CTA的状态变为不活跃,下一个就绪的处于不活跃状态的CTA将取代它,从而有效地保持缓存资源的利用率.相比SMK,VT避免了保存和恢复块状态以及交换大量缓存数据所产生的较大开销.此外,与VT相似的VTB技术[34]将2个CTA合为一个大的CTA,考虑到shared memory资源访问的压力,只有在CTA中的warp访问shared memory时才予以分配shared memory,一旦使用完毕,则立即释放对shared memory的使用.
在提升TLP水平的同时,还要使并发执行的线程保持高度活跃的状态,才能保持片上资源的高利用率.Kim等人[35]提出warp预执行,对处在长延迟访存操作的warp继续对后续指令进行获取和解码,识别并预先执行不依赖长延迟访存操作的指令,能够更好地保持处于活跃状态的线程数量.Xiang等人[36]指出资源的分配和回收若总是采用CTA级,它所占用的全部资源则需等到最后的warp之行结束才能回收,其占用的缓存在第一时间未得到及时释放.因此,他们提出了warp级的资源分配回收机制,使得更多的warp得到提前执行的机会,可以更大限度地提升片上资源的利用率.
表1对比了5种提升TLP技术的主要特征.从表1可以看出,Park等人提出的Maestro多任务调度框架从空间和时间上同时考虑多任务调度资源分配的合理性,使得其资源的利用率和性能收益在这5个方法中最好.Warped-Slicer方法主要是使用了更小的任务调度单位,使得资源利用率得到了较好的提升.但是,由于需要CTA的换入换出,其性能收益也不高.SMK由于需要在上下文之间切换,开销很大,其性能收益相对最低.
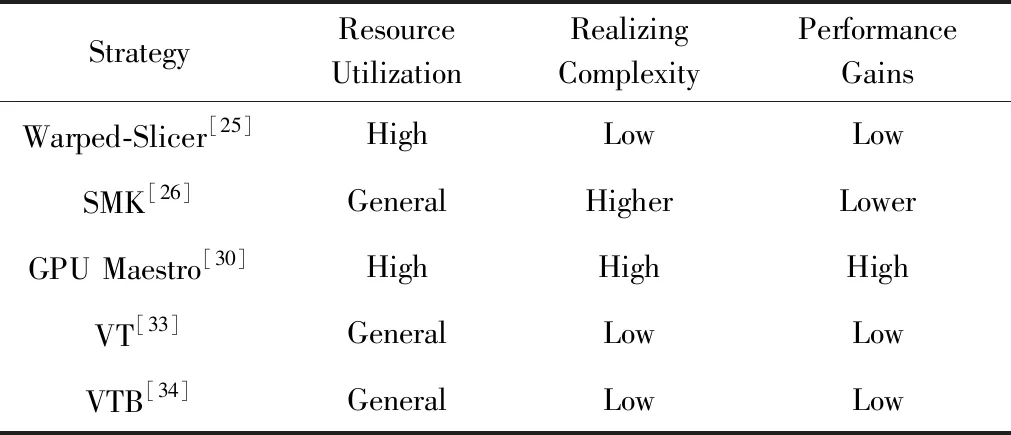
Table 1 Features Comparison of the Main Strategies with TLP Enhancing表1 提升TLP的主要策略的特点对比
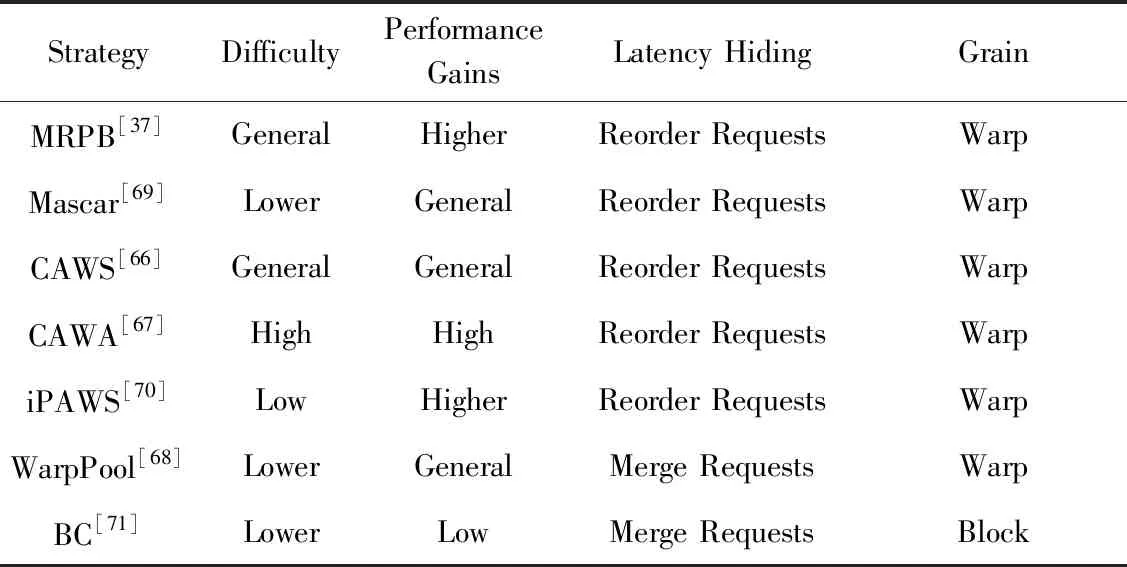
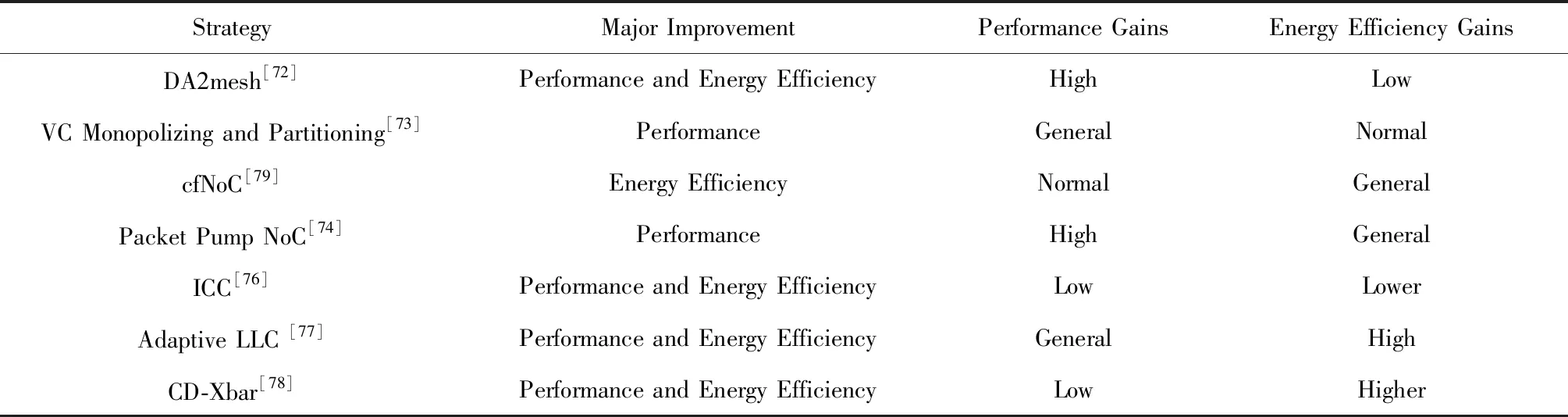
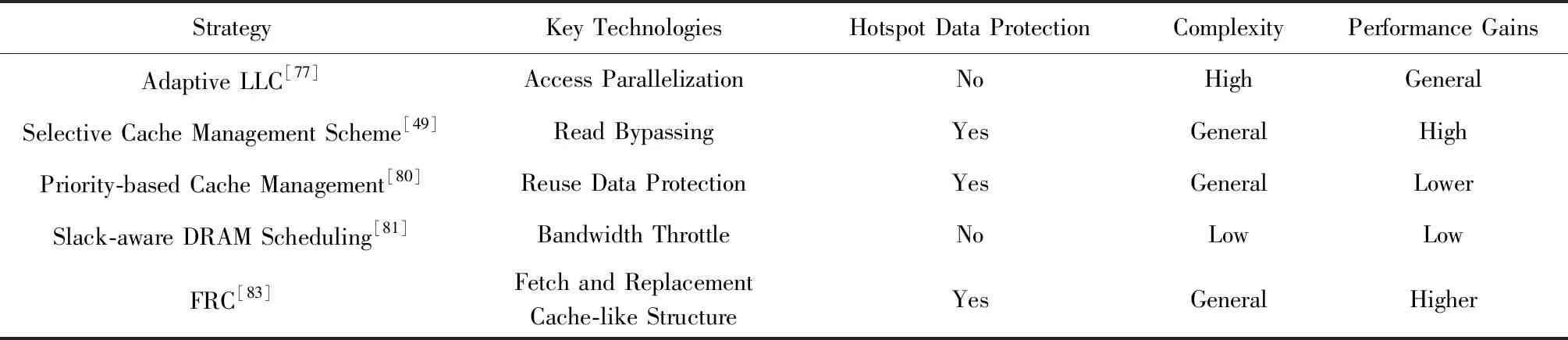
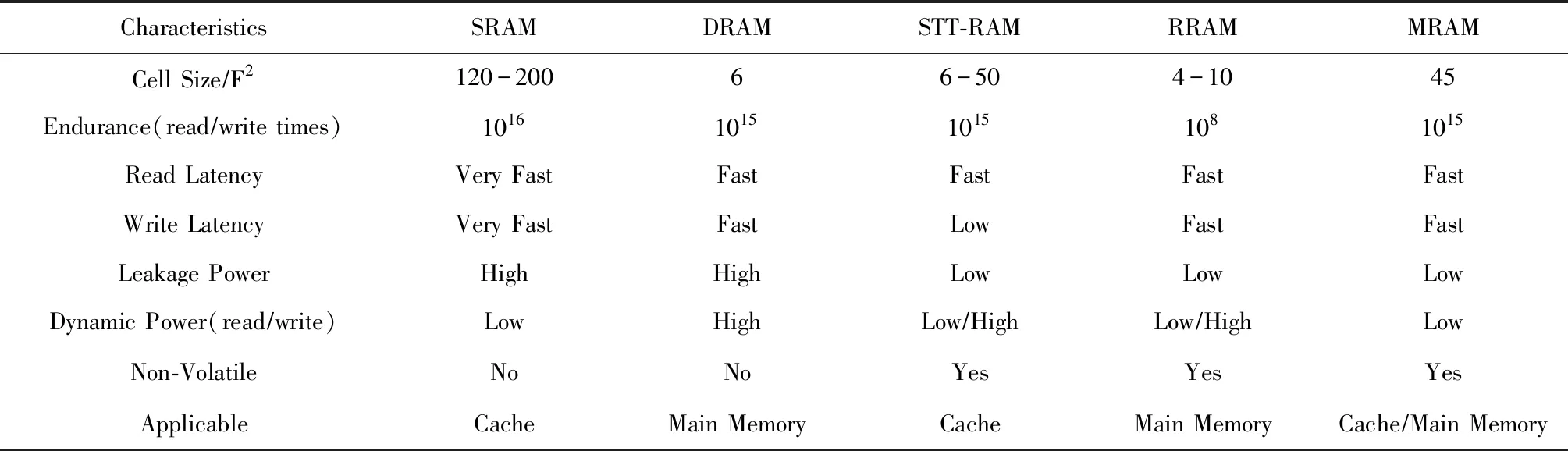
特此说明,各表中程度由低到高依次表示为:Lower 2.1.2 保持TLP技术 提升TLP可以有效地保持甚至提高片上资源的利用率.但是,TLP的提升也可能带来更激烈的缓存争用,甚至会造成无法迅速解除的访存阻塞.cache绕行技术可在缓存出现访问失效时,将访问下一级存储器所获取的数据直接传送给寄存器.因此,在出现片上缓存资源激烈争用时,采用cache绕行技术既可以有效保持SM上的TLP及NoC等片上其他资源的利用率,又能有效避免片上缓存资源争用的加剧. 由于采用cache绕行访问得到的数据保存在寄存器中,其获得的数据可重用性很低.因此,对低重用的数据访问更适合采取cache绕行技术.及时分析掌握运行时的访存行为特征,可以动态地找出绕行缓存的合适时机.Jia等人[37]提出内存请求优先级缓冲(MRPB)策略,通过区分请求的来源分析预测为其提供服务是否会导致缓存抖动或阻塞,并判断相应的访存请求是否绕行cache.但是,MRPB并未真正分析访问请求的数据是否被重用,也即并未根据请求访问数据的特征来选择被绕行的对象.Koo等人[38]提出访问模式感知的缓存调度架构APCM,则依据warp load指令的特征识别低重用的数据,并选择需要绕行cache的访存请求.Lee等人[39]提出Ctrl-C cache绕行框架,通过访存指令感知算法更细致地识别每条指令的缓存重用行为,并做出cache绕行决策.Li等人[40]和Chen等人[41]提出的cache绕行策略则主要考虑了访存数据的重用距离特征.不同于预测重用,Dai等人[42]提出通过预测是否能命中缓存来决定是否绕行,其实验结果表明,该方法优于Chen等人[41]提出的cache绕行策略.与直接识别数据的重用特征不同,Liang等人[43]在并行的多任务中,以CTA为单位采取绕行,通过对增加绕行块带来的效果进行采样分析,逐步找到最合适的绕行方案. 也有学者通过编译技术静态分析访存的行为特征,可以提前识别是否适合采取cache绕行的访存操作.Liang和Xie等人[44-48]分别提出了一种编译时框架和一种编译运行时相结合的缓存绕行框架.后者在编译时识别局部性好和局部性差的访存指令,并标识需要cache绕行的load指令,其余的访存指令则在运行时分析处理. 有一类应用程序,它们在运行过程中使用的运算数据绝大部分都只被访问一次,其访问的数据通常被称为流式数据.流式数据的局部性非常差,因此对这种类型的数据访问非常适合采用cache绕行技术.Choi等人[49]提出了一种针对于读取操作的cache绕行方法,避免没有重用特征的流式数据进入LLC.Tian等人[50]提出的自适应cache绕行策略,有效预测并避免流式数据进入一级缓存. 此外,有一些综合性的缓存管理方案[51-52]也有效结合了绕行技术. 表2对比了6种主要的使用cache绕行技术的优化策略的特点.从表2中可以发现,利用数据的重用特征选择合适的绕行cache对象是提高cache绕行效率的重要方式.其中,MRPB和TLP modulation and cache bypassing未采用重用特征提取机制,其性能收益相对一般.APCM精细地利用了每个load指令的局部性特征,获得了较高的性能收益.Liang和Xie等人利用编译时预测和运行时感知的重用特征提取机制实现的Coordinated static and dynamic cache bypassing缓存绕行策略获得了不错的性能收益. Table 2 Features Comparison of the Main Strategies with Cache Bypassing表2 使用cache绕行的主要策略的特点对比 2.1.3 TLP限制策略 随着SM上的TLP逐渐升高,缓存资源也逐渐变得紧张.若在硬件资源的限制范围内继续提升TLP,缓存争用将加剧,甚至出现缓存访问“抖动”,直至出现访存阻塞.此时缓存子系统性能出现严重损失,而TLP的升高带来的隐藏访存延迟的好处不足以弥补这一损失,GPGPU总体性能将会受到下降的影响.因此,在缓存资源竞争加剧的情况下适当限制TLP,可以有效防止GPGPU的性能下降. 通过前面对图3的分析可以知道,有些任务运行时因大量消耗其他硬件资源只能产生有限的TLP,TLP即使达到物理上限,也不足以使缓存产生抖动;有些任务虽可继续增加TLP,但由于其占用的片上资源过多,继续提升TLP,反而导致系统性能下降.Bakhoda等人[19]观察到一些任务通过降低TLP减少了缓存争用,并提高了系统性能. 另外,Narasiman等人[57]提出的两级warp调度策略将SM上所有活跃的warp分为2组.同一时刻只有一组warp执行,当活跃warp组中所有的warp被阻塞时,另一组warp才被调度执行.两级调度策略使得活跃的并发线程数减少了一半,因此片上缓存的争用将得到有效的降低.与他们稍有不同的是,Jog等人[58]提出的线程调度策略OWL以CTA为粒度进行两级调度. 当前,多任务并发执行已成为GPGPU性能优化研究的热点.多任务并发执行无疑会大大增加线程对片上缓存资源的争用.动态分析不同任务的执行特点,实时调节不同任务对不同资源的使用度,可以实现不同执行任务对各种硬件资源进行互补性地使用.尤其是对片上资源占用率高的执行任务,应动态限制其并发执行的线程数量,并通过利用限制TLP调节技术,有效减少片上资源的访问争用情形.Dublish等人[59]针对多任务情形下的缓存争用,提出了线程调度策略Poise,利用了机器学习的方法,分析出不同特征任务运行时的最佳TLP,取得了较好的性能效果. 另外,一些综合性的缓存管理方案[51-52]和线程调度方法[60]也有效结合了TLP限制策略.表3归纳了4种TLP限制策略的主要特征.其中,CCWS和Poise都是在运行时对数据的重用特征进行被动感知,获得的性能提升较为有限.DAWS和CBWT则是在运行时主动预测重用特征,其准确性更佳,因此获得了相对较好的性能提升. Table 3 Features Comparison of the Main TLP Limitation Strategies表3 几种TLP限制策略的特点对比 对GPGPU缓存子系统来说,增强访存延迟的隐藏能力是改善访存效率的一种重要方式.除了使用TLP调节技术,还可以通过访存顺序调节技术增强隐藏访存延迟的能力,而预取和访存请求重排序正是2种主要的访存顺序调节技术. 2.2.1 预取 预取技术利用当前warp的访存操作,一并将该warp或其他warp后续访存的数据提前读取到片上缓存中,其本质上是改变了后续访存操作的顺序.通过预取,一方面可以有效降低cache的强制失效率,避免过多的计算停顿;另一方面,由于一次访存操作可以满足当前和后续多次访存请求的需要,整体上也降低了对片外访存的开销.因此,预取技术在某种程度上可以有效提升存储子系统的访问效率. 预取面临准确性和及时性两大主要问题,这两大问题可以通过准确计算预取地址和选择合适的预取时机来解决. 如果预取地址计算错误,该失效的预取操作会带来缓存资源争用的压力.有些应用的访存请求体现出了明显的规律,例如大量使用线程ID引用内存地址[9]、运行相同代码的线程具备相似的访存特征[61]等.这些规律方便对访存预取的步长进行分析,从而可以准确计算预取数据的地址. 对于计算比较规则的应用来说,预取策略可以实现非常高的准确度.Lee等人[9]提出了多线程感知预取的策略,利用应用程序中大量使用线程ID访问内存地址的特点,为其他线程预取所需数据,并自适应地限制预取,以避免预取带来过大的缓存压力.Oh等人[61]提出了WASP的预取机制,在了解了相关warp之间的访存差异后,选择执行相同访存指令且比当前warp执行速度慢的warp进行数据预取.Koo等人[62]提出的CAPS预取策略,则使用了每个CTA的基地址来计算后续warp的预取偏移量,其预取准确率超过了97%,并通过定期发出访存请求的方式,获取了更多合并访存请求的机会,可为大部分任务带来平均8%的性能提升. 然而,预取到缓存中的数据不一定能立即被传送到寄存器参与运算,通常需要等待任务执行到相应的指令时才能被访问,这样则有可能被后续的访存数据置换出去.因此,预取的时机选取很重要.预取过早,对应需求的任务还未被调度执行,可能导致预取访问的数据还未被使用就被置换掉.预取过晚,任务发出访存请求时,数据未被及时预取至缓存中,导致相应任务访问cache失效. 为连续warp执行预取时,由于片外访存的延时相对较大,预取的时机往往过晚.Jog等人[63]提出了预取感知的warp调度策略,在两级warp调度的基础上,为不连续的warp选择合适的预取时机,使得系统平均性能提高了7%.Caragea等人[10]提出的数据预取机制RAP,可根据资源使用情况动态调整预取距离,使资源紧张状态下的预取更为有效.与他们不同的是,Oh等人[64]提出的warp调度框架APRES将访存特征相似的warp成组调度,若组中的第1个warp访问cache失效,则由该warp为全组其他的warp进行数据预取. 此外,Jog等人[58]提出的数据预取机制中重点考虑如何提高片上二级缓存的命中率.Sethia等人[65]提出的自适应预取技术则重点考虑了如何提高GPGPU的能效. 表4对主要的缓存预取策略进行了对比.其中,CAPS,WASP和MT-prefetching预取准确度较高,因此获得了较好的性能收益.RAP虽然实现了较为复杂的软件预取,但只考虑了预取步长因素,其预取准确度较低,由此获得的性能收益相对较低. Table 4 Features Comparison of the Main Strategies with Prefetching表4 主要的应用数据预取策略的特征对比 2.2.2 访存请求重排序 当计算所需的数据无法命中片上cache时,将产生片外访存请求.由于片外访存的延时大大超过缓存提供数据服务的时间,因此应尽可能减少片外访存次数.对此,GPGPU实现了两级访存合并机制,即warp内的访存合并和warp间的访存合并. 当片上缓存访问失效增多时,warp的执行性能必然受到影响.同时,片外访存请求会相应增加.根据每个片外访存的特点,适当调整发出片外访存的顺序,及时满足需求量大的访存请求或局部性好的访存请求,可以有效提升及时服务后续计算任务的能力,访存延迟也可以更有效地隐藏在计算过程之中. 通常情况下,CTA中所有的warp运行结束后,才能给SM调度分配新的CTA执行.但是,CTA中有些warp的执行速度比较慢,会拖累整个CTA的执行,可以把它们称为CTA中的关键warp.因此,应优先服务CTA中关键warp的访存请求.Lee等人[66]提出的线程调度CAWS,就是优先服务CTA中的关键warp,使其利用缓存的机会大大增加,加速了关键warp的执行,从而也加速了整个CTA的执行.为了提升CAWS的适应性,Lee等人又联合Arunkumar[67]提出了CAWA线程调度策略,将线程调度与缓存使用的优先级进行了结合. 通过对访存请求重排序,可以增加访存请求的合并机会,并减少对下一级存储器的访问,从而降低GPGPU缓存子系统的访存压力.Jia等人[37]提出了一种内存请求优先级缓冲(MRPB)的硬件结构,采用数个队列对访存请求重新排序,将来自同一warp的访存请求分组,很好地开发了warp内的数据局部性.Kloosterman等人[68]提出WarpPool合并来自多个warp的缓存请求,开发了warp间的数据局部性,也有效减少了多次发出同一访存请求的概率.与他们的思想不同的是,Sethia等人[69]提出了基于访存感知的线程调度策略Mascar,当片上访存排队资源处于饱和状态时,通过打破严格按照队列次序进行访存服务的限制,优先服务缓存可以满足数据访问请求的warp,提升了缓存中数据的重用能力. 另外,每一种线程调度方式都有自己的局限性和优势,例如对于具有warp间局部性的工作负载,公平的轮转调度器性能要比贪婪的warp调度器更优秀.为此,Lee等人[70]提出了iPAWS,根据warp的指令发射模式在2种调度器之间进行动态适配,实质上也是对warp间的访存顺序进行动态调整.此外,对各个SM轮转分配CTA的调度方法在均衡硬件负载的同时,也可能破坏了连续block之间存在的局部性.为此,Lee等人[71]提出的线程调度策略BCS,尽量将2个连续的CTA分配给同一个SM,使连续warp的访存数据可以更好地重用,开发了CTA间的数据局部性. 表5对比了主要的访存请求重排序策略的特征.其中,BC的优化粒度是线程块级的,获得访存请求合并的机会最少,因此性能收益相对最低.iPAWS通过对访存指令Load模式的分析,动态调正warp调度策略,获得了较高的性能收益.MRPB通过对访存请求进行重排序,开发了warp内的数据局部性,并结合缓存绕行机制,也获得了较高的性能收益. Table 5 Features Comparison of the Main Strategies with Memory Accesses Reordering表5 主要的访存请求重排序策略的特征对比 随着GPGPU的计算性能逐渐增强,SM可以支持更高的TLP,运算所需的数据量大大增加,这要求缓存子系统能够承载更高的数据通量.然而对GPGPU缓存子系统而言,简单增加其容量,会使硬件规模急剧上升.为此,研究者们提出了数据通量增强的技术,利用更优秀的结构改进缓存子系统,实现了更高的访存效率. NoC在缓存子系统中担负着传递数据的任务,增加单位时间内数据传输的通量有助于应对更密集的访存请求. 通常情况下,数据的请求和应答都在同一网络上传输.Kim等人[72]提出DA2mesh网络架构,将访存请求和访存应答在不同的片上网络上传输,使得系统整体性能提升了36%,同时片上网络的能耗降低了15%.在实际的片上网络中,访存请求的数据量明显低于访存数据回传的数据量.Jang等人[73]采用不对称片上网络的设计,较好地提升了片上缓存子系统的数据访问效率,使得系统性能提高了25%.另外,Cheng等人[74]试图在不增加规模的情况下最大化不对称NoC设计的性能.Ziabari等人[75]对几种不对称的NoC设计进行了比较. 来自各个SM的访存请求中,可能存在访问同一行LLC的、可以被进一步合并的访存请求.Zhao等人[76]提出簇内合并访存请求的策略,降低了NoC的通信压力,提升了缓存子系统承载高数据通量的能力.Zhao等人还提出了2种二级路由设计[77-78],缩减了NoC的总体规模. 表6对比了7种主要的NoC优化方案的特点.其中,Zhao等人[77]的方法还涉及对LLC的优化.一些为进一步降低NoC成本的方案[11,72]试图在资源分配更少的情况下最小化性能丢失,而Zhao等人[79]试图在减小功耗的情况下保持性能. 从表6可以看出,将访存请求和访存应答在不同的片上网络上传输,对提升NoC的性能较为有利,这是因为可以针对2个网络所传数据的不同特点进行优化,DA2mesh NoC和Packet Pump NoC都因此获得了相对较高的性能收益.而采用二级路由的NoC设计方案利于带来较好的能效收益,Adaptive LLC和CD-Xbar都因此受益.另外,Adaptive LLC可以动态地绕行靠近LLC的路由结构,可以获得比CD-Xbar更高效的访问速度. Table 6 Features of Seven NoC Optimization Strategies表6 7种NoC优化策略的特征 与目前主流的CPU不同的是,目前主流的GPGPU通常只包含二级片上缓存.因此,GPGPU中的L2缓存也即LLC. 由于数据在LLC中只存在唯一的一份,LLC一次不能服务访问对同一数据的多个请求,因此,这些访存请求只能串行执行.Zhao等人[77]提出的方法可以动态改变LLC的状态,支持将集中访问的数据复制多份,并放在不同的位置同时进行访存,从而实现了对这些数据串行访问的并行化,提高了对LLC的访问效率. 保护LLC中数据的局部性同样可以提高访存效率.Choi等人[49]提出了一种读取绕行的策略,可以有效避免局部性差的流数据进入LLC.Mu等人[80]提出的缓存管理方案也考虑提高LLC重用数据的驻留机会.Dublish[81]提出将更多的LLC带宽提供给那些片上缓存争用不激烈的SM.为了减小LLC的带宽压力,Dublish等人[82]又提出将一级缓存通过轻量级环形网络连接以支持数据共享,减少了29%的LLC流量,这些带宽可以用于服务其他的访存请求.Candel等人[83]提出在LLC中加入类缓存的缓冲结构(FRC,Fetch and Replacement Cache-like structure),延缓LLC中被置换数据的换出,提高了这部分数据的访问命中率.此外,为了打破有关数据局部性利用方法的层次局限,Vijaykumar等人[84]协调NUMA与CTA调度,将访问同一批数据的CTA集中在同一个SM运行. 另外,一些研究者们还谋求将少量计算单元集成在较低层次的存储器件(如主存[85])中,避免移动低计算需求的数据集,减少了SM对LLC的访存数量.类似地,Pattnaik等人[86]提出的NDP解决方案将少量计算单元集成在LLC中,也减少SM与LLC之间的数据传输.与基准GPU相比,该策略减少了44%的片上数据移动,提供了平均31%的性能提升和16%的能效改进. 表7比较了5种LLC性能改进策略的特点.其中,Mu等人基于对重用数据的保护提高LLC性能,由于LLC中的数据重用特征会受到数据频繁替换的影响,因此获得的性能提升相对有限.而FRC利用添加类似于缓存的结构,减小了数据频繁替换的影响.虽然增加了硬件开销,但是FRC换取了良好的重用特征提取能力,因此获得了相对更好的性能提升. Table 7 Five Features of LLC Performance Improvement Strategies表7 5种LLC性能改进策略的特点 采用传统SRAM设计的缓存子系统规模和功耗都很大,且容量小.随着NVM(non-volatile memory)非易失性存储器件的广泛应用,为GPGPU上的缓存系统架构设计注入了新的活力.NVM具有更高存储密度和良好的读数据性能,但是其存在着写功耗大、写速度慢、寿命相对有限的缺陷. 随着研究人员的不断努力,NVM的性能缺陷和寿命缺陷有了很大改善,研究人员试图将NVM融入到GPGPU上的缓存子系统设计架构中,并逐渐形成了NVM混合传统缓存材料、完全使用NVM材料构建缓存子系统的两大发展方向.表8列举了近几年5种具有代表性的应用于GPGPU缓存的NVM材料的特性,并与传统存储材料作了对比. Table 8 Five Features of NVM Material Used on GPGPU Cache表8 5种使用在GPGPU缓存上的NVM材料的特性 多数NVM材料在写入速度方面达不到传统材料的水平,但在读取速度方面十分接近传统材料.对此,研究者们考虑在传统缓存中混合使用NVM,利用NVM存储读取频次更高的数据,发挥其读取速度的优势;同时使用传统材料缓存,为写入次数较多的数据提供缓存,平衡NVM写入寿命和写入速度的缺陷.设计这样的混合缓存,需要充分考虑使用的NVM种类、NVM缓存的容量比例等因素,满足缓存在整体规模、寿命、容量和功耗等方面的要求. Goswami等人[87]提出将STT-MRAM作为只读存储器件融入到SRAM缓存系统中,充分利用了STT-MRAM较好的读性能,显著改善了shared memory的只读数据访问性能.Zhang等人[88]提出的SRAM与STT-MRAM混合的缓存结构,通过在运行时识别数据在读写次数方面的特征,预测和推断需要缓存的数据应该使用哪种材料的缓存. 采用NVM与传统材料混合的解决方案较好地平衡了NVM的优势与缺陷.然而,完全采用NVM构建缓存可以更好地利用其高密度的优势,其进一步扩大的缓存空间带来的不只是更长的数据保持时间和更小的缓存抖动,还有利于支撑更高的TLP. Satyamoorthy等人[89]提出了一种在固定规模和功率约束下用MRAM代替SRAM shared memory的设计,并通过设计写缓冲区隐藏写入延迟.Zhang等人[90]提出使用电阻随机存取存储器(RRAM)取代基于SRAM的LLC缓存,将片上缓存的空间扩大了30倍,很好地缓解了LLC的抖动问题.Samavatian等人[91]设计了一种基于STT-RAM的LLC,也带来了系统16%的平均性能增幅. 传统SRAM的替代方案之中,DWM是极少数在读写性能上近乎持平于传统存储材料的电子自旋式存储技术.Venkatesan等人[92]提出了一种新的片上缓存架构STAG,首次尝试以DWM组织GPGPU的片上存储.DWM通过访问晶体管共享电路实现了数据存储的高密度,但由于对其访问需要做出类似移动磁带带头的动作,也会带来一定的访问延迟. 另外,NVM技术也可独立用在更高层次的寄存器中.基于STT-RAM的寄存器[93-94]和混合寄存器[95]均已被提出.Mittal等人[96]更是提出了一种基于SOT-RAM的寄存器设计方案,它在保持与SRAM寄存器相同性能的同时,比SRAM和STT-RAM寄存器提供了更高的能效比.Gebhart等人[32]提出的统一片上存储器结构将存储器静态地划分为寄存器和L1数据缓存.Jing等人[97]提出将寄存器和数据缓存融合在一起,通过对寄存器地址转换实现缓存仿真寄存器的功能,具有统一寻址和管理策略,大大提高了访存敏感型任务的性能. 表9对比了应用于GPGPU缓存组织架构的6种主要NVM技术的特征.从表9可以看出,通过传统材料混合NVM的缓存组织方式能获得较佳的性能提升.在STAG中,DWM代替了传统的cache,虽然DWM材料存储密度高,有利于增加片上缓存的容量,但是其访问时需要移动磁带带头,因此其带来的性能提升相对较低. Table 9 Features Comparison of Several NVM Technologies Used on GPGPU Cache表9 几种GPGPU缓存上使用的NVM技术的特征对比 研究者们提出的不同缓存子系统性能优化方法均在一定程度上提升了GPGPU缓存子系统的效率,有利于GPGPU的性能提升.但由于各种方法考虑问题角度的局限性,缓存子系统的性能潜力仍未得到充分开发. GPGPU的不断发展使得缓存子系统性能优化方法在5方面还存在挑战: 1) 随着单GPU计算能力的不断提升以及GPU集群技术的不断发展,GPU上支持的并发kernel数的增长速度远远超过缓存容量的增长速度,片上缓存资源争用问题愈发突出.对此,需对高并发的多个计算任务进行更有效地调度,并有效结合编译技术,从时间和空间上更好地开发缓存中数据的局部性,有效解决片上缓存争用问题. 2) 由于写性能、功耗以及寿命方面的缺陷,传统缓存的替代方案依然存在不足,部分材料的读性能和寿命虽然能与传统材料相媲美,但大大牺牲了其存储密度和功耗方面的优势.在此方面的研究中,一方面可以开发密度更高、功耗及读写性能与传统缓存相当甚至超越的新型存储材料,以全面替代现有的传统存储器件;另一方面,针对传统材料和新型材料融合的片上缓存子系统解决方案,需要开发更有效的任务调度算法,并有效结合编译技术,更好地利用传统存储材料和新型存储材料各自的优势,在保证性能的前提下,提高存储密度和使用寿命,同时有效降低片上存储子系统的功耗. 3) 目前,为了更有效地解决CPU与GPGPU之间的数据传输长延时问题,不少研究提出CPU和GPGPU融合的体系架构,且目前已有相关的商用处理器产品.在该体系架构下,CPU和GPGPU共用片上存储,片上存储资源的争用问题变得更加突出,对其进行性能优化需要面对更高的复杂性,目前针对此类体系结构中缓存子系统的优化工作并不多. 4) 由于GPGPU上并发执行的线程数以万计,片上数据传输的数据量也非常巨大,现有的片上网络NoC由于其结构问题,当遇到访存请求过多的情况下,存在传输效率不高、功耗较大、无法有效区分冗余访存请求等问题,使得访存请求的数据传输时延增加,降低了片上缓存子系统的性能.为此,一方面可以对现有的NoC结构进行优化设计;另一方面需要更好地对冗余访存进行合并,提高NoC的数据传输效率,以更好地提升片上缓存子系统的数据访问效率. 5) 功耗问题始终是制约GPGPU发展的重要瓶颈.众多研究表明,片上缓存是GPGPU功耗产生的主要来源之一,这很大程度上限制了GPGPU片上缓存子系统的发展.结合任务调度,利用DVFS以及门控功耗等技术,实现对片上缓存子系统的功耗优化,以有效提升GPGPU片上缓存子系统的容量,从而缓解片上缓存的争用问题.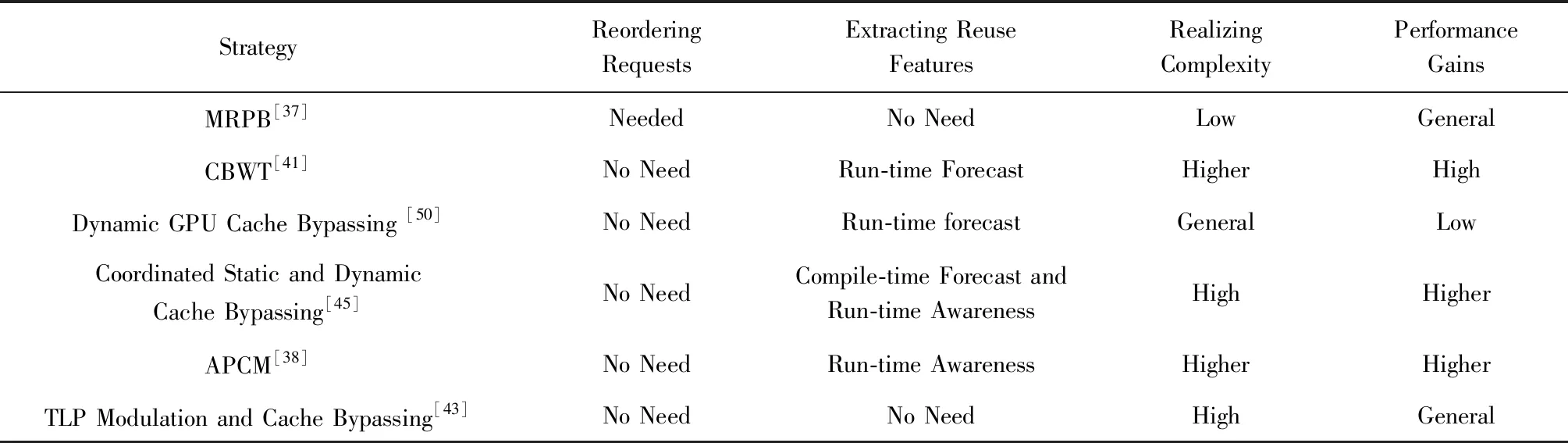

2.2 访存顺序调节技术

2.3 数据通量增强技术
2.4 针对LLC的优化
2.5 NVM在GPGPU缓存子系统中的应用

3 结束语
