改进SSD的交通标志目标检测算法
2020-06-22肖丹东陈劲杰
肖丹东 陈劲杰


摘 要:以Faster R-CNN为代表的two-stage目标检测算法检测速度慢,而one-stage目标检测算法中的SSD算法虽然检测速度快,但对交通标志类小目标的检测效果不佳。因此在SSD算法VGG16骨干网络上引入感受野块(RFB)结构,既提升检测速度又可在小目标检测上达到良好的检测精度。与此同时,为提高网络分类精度,在损失函数中加入中心损失。将SSD算法与改进的SSD算法在VOC数据集上进行训练,对比其性能可知,改进后算法mPA值达到80.7%,相比SSD300(VGG16)算法提高了3.5%。该算法在LISA traffic sign数据集上训练,在迁移学习的基础上得到的mPA值为78.4%,检测单张图像平均耗时为20.5ms,可满足实时性要求。
关键词:交通标志;小目标检测;RFB结构;中心损失
DOI:10. 11907/rjdk. 191977 开放科学(资源服务)标识码(OSID):
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2020)005-0048-04
0 引言
交通标志信息是交通场景中的重要环境信息,是保证先进驾驶辅助系统(Advanced Driver Assistant System, ADAS)正常运行的必要条件。目前基于计算机视觉的目标检测算法可部分满足场景信息检测需求[1],但在实际应用中还存在一些缺陷。基于OpenCV的目标检测方法,如HOG(histogram of oriented gradient)、SIEF(scale-invariant feature transform)等方法使用人工设定先验条件的方式进行检测,导致算法鲁棒性差,难以适应交通标志类复杂的交通场景检测;如果算法应用到大范围的智能化作业,不仅算法耗时、监管人力消耗较大,同时算法实时性指标也难以满足[2]。
近年来,CNN网络在ImagNet中表现卓越,基于深度学习的目标检测方法在图像目标检测领域成为应用热点,相比基于OpenCV的目标检测方法,基于CNN网络的算法模型可检测到图像不同深度的特征,且可自主学习,获得更丰富的特征。在基于深度学习的目标检测领域有两种类型的算法,一种是以Fast R-CNN、Faster R-CNN、R-FCN为代表的two-stage卷积神经网络算法[3-4];另一种是以YOLO、SSD、Retina-Net为代表的one-stage卷积神经网络算法[5-7]。这两类算法各有优劣,one-stage算法模型在检测效率上更有优势,考虑到交通标志目标检测实时性要求,SSD算法更贴合需求。但交通标志目标检测属于小目标检测,SSD算法在该类检测中的检测精度较差,小目标特征信息主要依赖于网络高层特征信息,因此本文选择在SSD算法网络高层特征提取过程中进行改进。
综上所述,本文在高层特征的提取过程中,参照RFB结构,通过RFB感受野提取卷积层输出的Feature Map特征,从而减少特征损失[8]。与此同时,为提高网络分类精度,在损失函数中添加Center Loss损失项[9]。
1 改进SSD算法
1.1 SSD算法
SSD算法作为one-stage算法中的代表,是目前主流的目标检测框架之一[10]。SSD网络骨干是VGG16,修改的部分是将VGG16全连接层fc6和fc7转换成[3×3]的卷积层conv6和[1×1]的卷积层conv7,同时为减小特征图大小,将池化层pool5中stride=2的[2×2]卷积核改成stride=1的[3×3]卷积核,然后删除VGG16网络中的dropout层和fc8层,在此基础上增加辅助卷积层,处理fine-tuning工作[11]。
SSD算法通过浅层CNN网络提取多尺度特征,进而对目标进行检测,其核心设计理念分为两点:
(1)使用卷积后的特征作为检测。相较于YOLO最后采用全连接层作为网络预测输出,SSD直接提取不同尺度的Feature Map,然后卷积输出预测结果。这样,对于形状为[m×n×p]的Feature Map仅需[3×3×p]的小卷积核即可得到预测结果,减少计算量。
(2)设置先验框。SSD在预测多个bounding box时,区别于YOLO在训练过程中自适应目标的形状,参照Faster R-CNN中的anchor,设置长宽比不同的先验框,从而减少训练难度[12]。
SSD算法在训练过程中,因为目标检测需得到两类信息,分别是目标位置信息和目标分类信息,所以损失函数针对位置误差(Locatization Loss,loc)与置信度误差(Confidengce Loss,conf)这两类进行计算回归[13]。Loss函数是这两类误差函数的加权和:
1.2 SSD算法改进
SSD算法采用多尺度预测的观念,在特征提取上有所改进,但是在构建多尺度特征图时使用VGG16网络的conv4_3卷积层作为特征提取,对Input图像进行缩放,因此大小为[32×32]的小目标物体图像在conv5_3卷积层中的Feature Map上只有[2×2],位置信息損失较大。交通场景中的交通标志属于小目标,所以SSD算法对该类目标检测时会出现目标特征信息丢失的情况。针对在conv4_3和conv5_3卷积层特征部分丢失的问题,对SSD算法从两方面进行改进:①VGG16网络中引入感受野块(Receptive Field Block,RFB),在conv4_3和conv5_3的特征提取和后续的特征传递中作出修改;②考虑到交通标志小目标的特征信息较少,所以在损失函数中添加Center Loss损失项,改善网络类别置信度预测[14]。
1.2.1 RFB结构
RFB结构从生物学角度,根据生物视觉成像原理,模拟不同大小的感受野。RFB结构是以Inception为基础,具体演变过程是Inception、Aspp和Deformable conv。
Inception主要采用3×3conv、9×9conv和15×15conv等不同尺寸卷积核的卷积层构成多分支结构,从而扩大感受野。
Aspp在网络中构成多分支结构,在卷积核大小不变的同时改变每个分支卷积核的rate大小,从而扩大感受野维度。
Deformable conv来自Deeplab,膨胀卷积可在保持参数不变和感受野大小一致时,获得更高分辨率特征[15]。
RFB综合了以上几种结构的理念,主要结构参照Inception模型。具体流程是由Previous layer传入Input图像,先分别经过2个1×1conv,输出的Feature Map一部分分别经过1×1conv、3×3conv、5×5conv,然后再对应经过rate=1的2×2conv、rate=3的3×3conv、rate=5的3×3conv,最后融合由layer传出的特征,经过1×1conv,把shortcut的1×1conv特征融合,通过激活函数Relu给出预测结果。可以看出RFB核心采集不同感受野的特征,然后通过膨胀卷积和rate的方式进一步扩大感受野,接着考虑过程中的信息损失,将最后和最初的特征进行融合,在尽可能丰富特征信息的同时保证特征信息不会丢失。
RFB结构在网络中在conv4_3和conv7_fc的特征提取中替代原有方式,如圖1所示。
改进部分将conv4_3和conv7_fc卷积层提取特征换成RFB模块,同时把Extra layers中卷积层前两层也替换成RFB结构。在特征提取过程中,conv4_3和conv7_fc的Feature Map在RFB结构中把特征信息小目标部分的特征放大,然后将多阶段的放大特征与原特征融合,再处理骨干网络各个阶段特征,最后进行分类和定位预测。
1.2.2 Center Loss部分
原SSD算法是对每一个Default生成一个4维Localization向量和一个Object_number维度的分类向量。为了更好地识别和分类,引入Center feature,它可以让每个Default box进行中心点回归。不同类别的中心点相隔较远,相同类别的中心点靠近。
通过在SSD算法的前向传播和后向传播过程中计算center部分的loss梯度,得出loss极值情况,然后和SSD算法的原loss部分结合,得出置信度分类预测。
2 实验分析
2.1 实验平台与数据
实验电脑硬件采用戴尔工作站,配备NVIDIA 1080Ti作为GPU加速卡。操作系统为Ubuntu16.04,深度学习框架选择Tensorflow。
为验证改进SSD算法在目标检测中的效果,首先使用VOC2007与VOC2012混合数据对模型进行评估。VOC2007和VOC2012数据集包含1 674张图片,可用于训练和验证。通过训练结果测试调整算法超参数,在算法收敛速度和精度上可获得优化[16]。在此基础上,使用迁移学习的方法,在LISA Traffic Sign数据集上进行训练,得到最后模型的weight文件。
2.2 算法训练分析
首先是数据集预处理,为保证算法鲁棒性,将图片进行随机旋转,对称映像,然后增加图片对比度。算法初始学习率设定为0.004,后续学习率变化如公式(8)所示。
然后在VOC2007和VOC2012数据集上进行预训练,bitch_size设为16,epoch设为50次。其中参数momentum和weight decay分别设为0.9和0.000 5。模型训练结果精度使用平均准确率均值(mAP)作为评价标准[17]。在交通标志目标检测中每个类别均可根据召回率(recall)和准确率(precision)组合成一条曲线,而mAP是多个类别AP的平均值。
使用Tensorflow中tensorboard工具动态对比观察每个Feature Map给出的loss变化情况,观察loss收敛情况。
2.3 实验结果分析
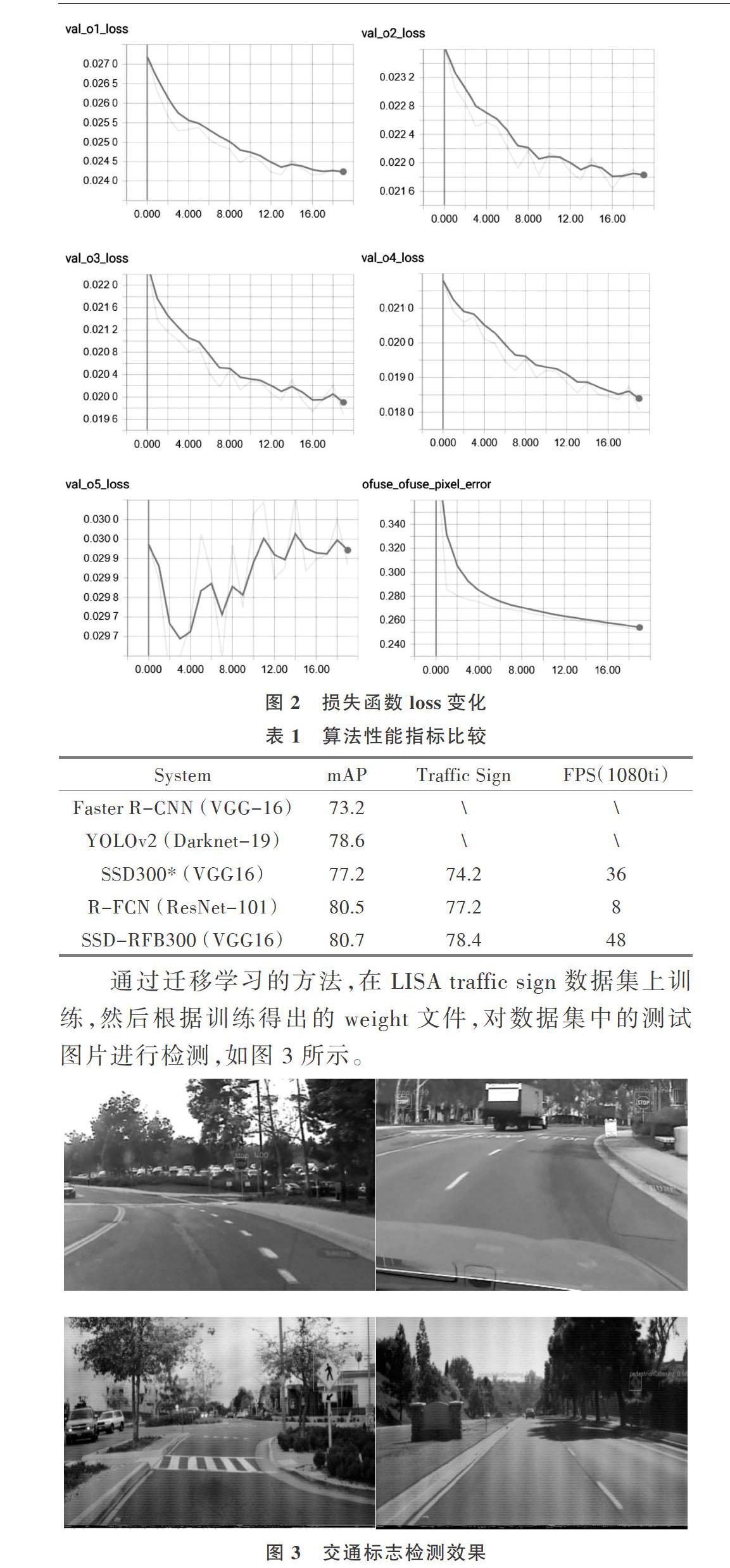
在服务器上根据VOC数据集进行训练,然后采集前16个epoch的feature Map loss情况,观察函数曲线收敛情况,如图2所示。
从图2中可以看出算法val_loss从feature_1到feature_4处于收敛状态,而在feature_5中loss出现震荡,从加权loss和pixel_error看出整体上算法处于收敛状态,改进的算法在损失函数上表现良好。
同时将改进的SSD算法在数据集上的表现与SSD算法、one-stage典型算法、two-stage典型算法相比较(见表1),可看出改进算法在mAP、FPS上均有提高,检测效果虽没有大的提升,但是在小目标场景下检测效果没有下降,同时在FPS指标上效果明显,实时性有较大提高。
从图3中可以看出,无论对于近景还是远景、单个交通标志或多个交通标志,改进后的SSD算法均能准确定位和识别场景中的标志,证明该算法达到预期检测效果。
3 结语
本文对SSD算法进行改进,一方面保留了原网络低深度、轻量化的特性,另一方面在原网络中引入RFB结构,在损失函数中中加入Center Loss损失项。因此,算法在位置预测精度和分类预测精度上得到优化,而在检测速度上没有受到明显影响。在VOC2007和VOC2012数据集上进行验证可知,改进后的SSD算法结构合理,在LISA Traffic Sign数据集中对交通标志类小目标检测可取得较好效果。然而RFB结构虽然可以扩大特征的感受野,但是基于VGG16的浅层网络本身无法获得较多的特征信息,而且低层网络特征并没有得到优化处理,所以下一步需在网络骨干上进行改进,从而保证目标特征信息可被充分提取[18],进一步提高算法精度和效率。
参考文献:
[1] 钱建轩,朱伟兴. 基于计算机视觉的动物跛脚行为识别[J]. 软件导刊,2018,17(10):14-17.
[2] 张三友,姜代红. 基于OPENCV的智能车牌识别系统[J]. 软件导刊,2016,15(5):87-89.
[3] REN S,HE K,GIRSHICK R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[4] DAI J,LI Y,HE K,et al. R-FCN:object detection via region-based fully convolutional networks[C]. Proceedings of the 30th International Conference on Neural Information Processing Systems,2016:379-387.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]. IEEE Conference on Computer Vision & Pattern Recognition,2016:109-125.
[6] LIU W,ANGUELOV D,ERHAN D,et al. SSD:single shot multibox detector[J]. European Conference on Computer Vision,2016:21-31.
[7] LIN T Y,GOYAL P,GIRSHICK R,et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,99:2999-3007.
[8] LIU S,HUANG D,WANG Y. Receptive field block net for accurate and fast object detection[J]. European Conference on Computer Vision,2017:1711-1720.
[9] WEN Y,ZHANG K,LI Z,et al. A discriminative feature learning approach for deep face recognition[C]. Computer Vision–ECCV ,2016:499-515.
[10] 李超凡,陳庆奎. 基于学习算法SSD的实时道路拥堵检测[J]. 软件导刊,2018,17(6):12-16.
[11] 徐乐,刘翔,张华. 基于SSD的道路前方车辆检测[J]. 软件导刊,2019(5):27-30.
[12] 莫宏伟,汪海波. 基于Faster R-CNN的人体行为检测研究[J]. 智能系统学报,2018,13(6):107-113.
[13] 徐智康,李旸,李德玉. 基于可变最小贝叶斯风险的层次多标签分类方法[J]. 南京大学学报(自然科学),2017,53(6):39-48.
[14] 张骏,梅魁志,赵季中. 基于置信度评估的Cache污染过滤技术[J]. 高技术通讯,2011,21(6):644-651.
[15] 徐峰,郑斌,郭进祥,等. 基于U-Net的结节分割方法[J]. 软件导刊,2018,17(8):165-168.
[16] 华夏,王新晴,王东,等. 基于改进SSD的交通大场景多目标检测[J]. 光学学报,2019,38(12):221-231.
[17] 唐聪,凌永顺,郑科栋,等. 基于深度学习的多视窗SSD目标检测方法[J]. 红外与激光工程,2018,3(1):290-298.
[18] SZEGEDY C,LIU W,JIA Y,et al. Going deeper with convolutions[C]. IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
(责任编辑:江 艳)
