基于云量子花朵授粉的极限学习机算法
2020-06-20牛春彦夏克文张江楠贺紫平
牛春彦,夏克文,张江楠,贺紫平
(河北工业大学电子信息工程学院,天津 300401)
(∗通信作者电子邮箱2053807967@qq.com)
0 引言
在石油产业发展和管理方面,油气层识别已经成为石油开发的不可缺少的依据[1]。近年来,研究者多采用拟合公式法来识别油气层,但由于油井的油气层识别是一门非线性的研究,因此采用拟合公式法进行识别的误差非常大,精确度不高。因此,本文利用极限学习机(Extreme Learning Machine,ELM)来识别油气层,验证极限学习机在油气层识别的可行性。
极限学习机算法由于输入权值和偏置值的随机选取,稳定性较差,且分类误差大[2-5],因此对极限学习机的参数进行优化显得非常重要。目前用来优化极限学习机输入参数的智能优化算法有很多,如:文献[6]将粒子群优化(Particle Swarm Optimization,PSO)算法应用到极限学习机中,但是PSO 算法易陷入局部最优,使其泛化性能不高。文献[7]利用蚁群优化(Ant Colony Optimization,ACO)算法来优化极限学习机的算法,但是蚁群算法本身较复杂,搜索时间长。因此本文利用改进的花朵授粉算法(Flower Pollination Algorithm,FPA)优化极限学习机的输入参数,通过实验验证了改进的花朵授粉算法优化的极限学习机具有很高的识别精度和识别效率。
花朵授粉算法利用莱维飞行机制,在寻优方面取得了较好的效果;但该算法也存在易陷入局部最优的问题,在寻优过程中,后期收敛速度较慢。为了解决以上问题,本文提出云量子花朵授粉算法(Cloud Quantum Flower Pollination Algorithm,CQFPA)。Sun 等[8]将量子行为应用到粒子群优化(PSO)算法中,改善了粒子群优化算法易陷入局部最优的问题,并扩大了搜索空间;但是粒子群优化算法在种群的不同搜索方式上存在模糊性、不能准确找出全局最优点、容易造成早熟等问题。因此,本文将量子系统引入花朵授粉中扩大搜索的空间范围,使其避免陷入局部最优。同时,加入云模型对其收缩扩张因子进行改进,平衡了收缩扩张因子对花朵授粉算法的影响,从而提高了收敛精度。通过六个经典测试函数,将本文算法与量子粒子群优化算法进行对比,验证了本文改进的云量子花朵授粉算法的有效性。
1 云量子花朵授粉算法
1.1 花朵授粉原理
花朵授粉算法(FPA)是由Yang 等[9]提出的一种群智能优化算法,受自然界中花朵授粉的启示,花朵授粉算法分为异花授粉和自花授粉。异花授粉过程要借助鸟、昆虫、蜜蜂等载体协助完成授粉过程,在这个过程中,这些传播者具有莱维(Levy)飞行机制,它们的行为服从莱维飞行分布,能飞行到较远的地方,因此把此过程又称为全局授粉。自花授粉过程是在同一种植物花朵上进行授粉过程,因为搜索范围小,将这种过程称为局部授粉。为了方便研究,需设置4个理想假设[10]:
1)在全局授粉过程中由携带花粉的传播者采取莱维(Levy)飞行机制来进行传播,计算式如下:

2)自花授粉过程是在小范围内进行的自身局部授粉过程。配子的位置按式(2)进行更新:

1.2 云量子花朵授粉模型
花朵授粉算法虽然引入了Levy 飞行机制在一定程度上避免陷入局部最优解,但仍存在易陷入局部最优且收敛速度慢的问题。量子系统的粒子处于量子束缚的状态,能以特定的概率出现在量子空间中的任意位置;同时它满足聚焦态的性质,因此能够搜索空间中的任意位置,这样使得加入量子系统的花朵授粉的全局搜索能力优于传统的FPA。
云量子花朵授粉算法(CQFPA)利用δ势阱束缚花朵个体的行为。在量子空间中,粒子具有波动二象性,无法同时确定粒子的位置和速度,因此粒子的位置状态只能利用波函数来表示[11]。为了得到粒子的位置,使粒子具有聚焦态的性质,进一步得到粒子的位置:
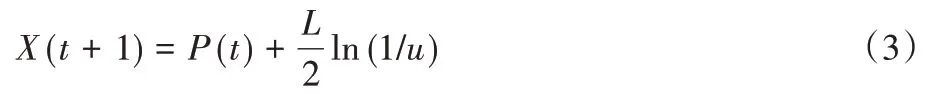
其中:u=rand(0,1);L表示δ势阱的特征长度;P(t)为粒子在t时刻的δ势阱。
假设种群当前最优解为gbest,用种群的平均最优解表示:

其中:Pi表示第i个粒子的当前最优解;M表示种群的个数;D为粒子的维度。
则势阱长度L表达式为:

式中:φ为收缩扩张因子,若φ的值选取不当会对FPA 的收敛性和寻优精度有很大的影响。因此本文将云模型与量子系统的花朵授粉算法结合,提出云量子花朵授粉算法。根据文献[12]给出的结论,花朵授粉转换概率p=0.8 时,更有利于种群寻优。本文利用转换概率p∈[0,1]调节个体进行全局搜索或者局部搜索:
1)当转换概率p<rand时,表明花朵个体之间的转换率较低,种群不需要全局授粉,应加快局部收敛速度,所以取收敛因子φ为0.4。
2)当转换概率rand≤p≤0.8,采用云模型对其进行改进:假设种群在第l次迭代中xi的适应度值为fi(l),全局最优解的适应度值为fgbest(l),种群个体的数学期望为EX=fbest(l),b1=b2=2,粒子的熵为En=(fgbest(l)-fbest(l))/b1,个体的超熵与熵的关系值为He=En/b2。则在此区间内的收缩扩张因子β为:
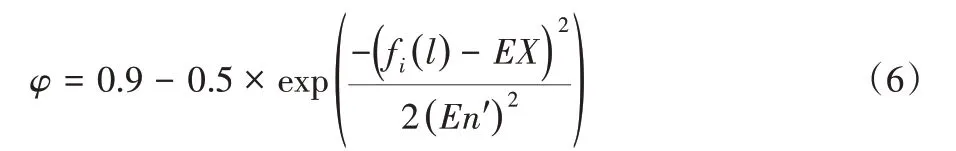
其中,En'=normrnd(En,He)。
3)若转换因子p>0.8 表明花朵个体间的转换率很高,需扩大全局搜索能力,因此取φ=0.9。
1.3 CQFPA的仿真验证与分析
为了测试改进算法的正确性和有效性,本文选取了6 个经典的标准测试函数进行对比测试,分别与FPA、量子粒子群优化(Quantum Particle Swarm Optimization,QPSO)算法、蝙蝠算法(Bat Algorithm,BA)进行对比分析,验证了CQFPA 的优越性。6个测试函数分别如下:
1)Schwefel函数(单峰函数):

2)Sphere函数(单峰函数):

3)Rastrigin函数(多峰函数):
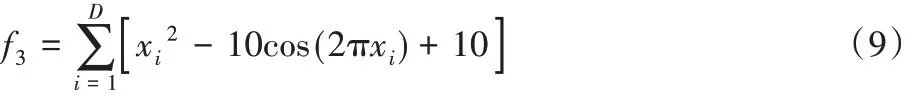
4)Ackley函数(多峰函数),含大量的局部优点:
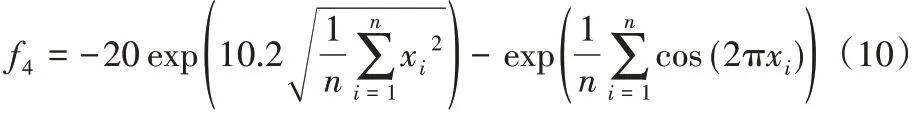
5)Griewank函数(多峰函数):
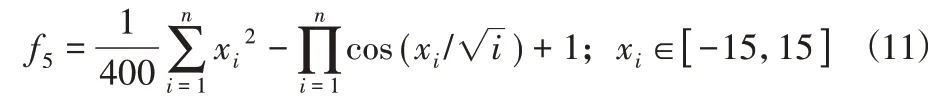
6)Sum of different power函数:

这六个函数均在(0,0,…,0)处有最小值0。
实验是在Matlab R2014a下测试的,同类改进的FPA 的参数设置相同,转换概率p=0.8,λ=1.5。BA 的参数设置为:A=0.25,r=0.5。PSO算法的参数设置为:c1和c2的值均为2,ωmax为0.9,ωmin为0.3。所有算法的种群大小均为30,最大迭代次数为2 000。各算法的仿真寻优迭代曲线如图1所示。
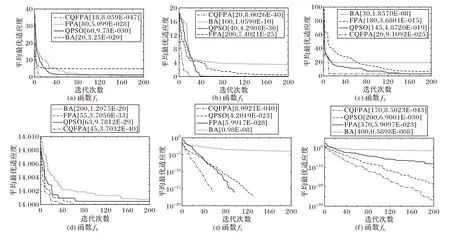
图1 CQFPA、QPSO、FPA和BA在6种标准测试函数f1~f6上的适应度曲线Fig.1 Fitness value curves of CQFPA,QPSO,FPA and BA on six benchmark functions f1-f6
图1中,将CQFPA与传统的FPA、QPSO和BA收敛曲线进行对比,通过比较四种优化算法的收敛速度以及全局搜索能力可知:BA 容易陷入局部最优,达到最大迭代次数也无法跳出局部最优;FPA和QPSO虽然能跳出局部最优,但相比而言,CQFPA 的收敛速度高于FPA 和QPSO,具有较高的精确度且收敛较快。此外,CQFPA 在寻优结果数量级上都比其他三种优化算法高。CQFPA 比FPA 高出10~20 个数量级,且收敛比较快,表明本文在对收缩扩张因子φ上的改进是可取的。CQFPA 相较BA 具有很高的精度,高出20~30 个数量级,不会陷入局部最优。CQFPA 相较QPSO,寻优结果的数量级和收敛速度均有所提高。
2 改进的极限学习机算法
2.1 极限学习机原理
极限学习机(ELM)是由Huang 等[13]提出的一种单隐层前馈神经网络。极限学习机网络比较简单,它相当于一个黑匣子,只需要输入样本,就能很好地产生一系列与输出样本基本接近的数据,有很好的拟合能力。
ELM的数学模型[14]如式(13)所示:
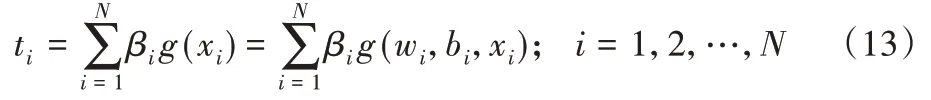
其中:ti表示第i个输出;bi是第i个隐含层偏置。
激活函数的表达式[15]为:

式(13)的N个方程可以写成为:

其中:
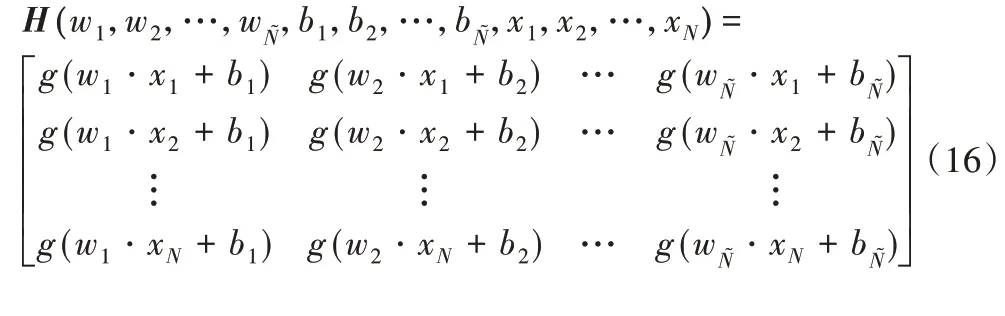
β=,H为隐含层的输出矩阵,只要确定隐含层输出矩阵H后,就可根据式(15)求出最小二乘范数解:

式中,H-1为H的Moore-Penrose 广义逆矩阵。由式(14)可知,已知wi和bi,则求Hβ=T的最小二乘解的过程其实和训练一个单隐层前馈神经网络是一样的,计算式如下:
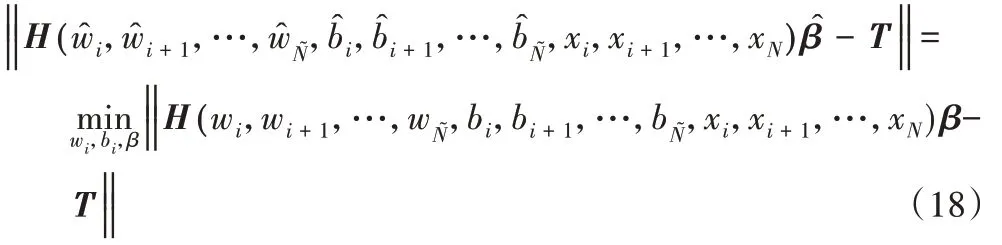
本文的均方误差函数E(mse)如下:

式中:E(mse)越小,表明ELM训练网络性能越好。
2.2 CQFPA-ELM模型
ELM 算法由于输入权值和偏置值随机选取,隐含层节点数目要求量可能很大,使得资源利用率很低;而且在学习过程中ELM 会产生许多非最优的参数,稳定性也很差。在计算输出权重时,误差主要来自于输入权重和偏置的随机选取,也可能存在一些输入为零的参数而导致某些隐含层节点无效。针对这些缺陷,本文提出了一种基于云量子花朵授粉算法优化的极限学习机模型——CQFPA-ELM。
在ELM 算法中,随机初始化后的参数使得ELM 算法的精确度不是很高;而花朵授粉算法在搜索方面具有参数简单、收敛速度快和鲁棒性能好等特点,能有效地找出全局最优解。因此本文将CQFPA 引入到ELM 算法中,对输入权值w和隐含层偏差b(阈值)优化,选出最优的值,代入ELM算法训练网络中,使ELM算法精度提高,泛化能力也提高,同时节省了运算时间。
CQFPA-ELM算法流程如图2所示,其具体步骤如下:
步骤1 初始化ELM 网络模型参数,输入训练样本数据,设置隐含层节点个数L。
步骤2 定义CQFPA 的参数,随机生成CQFPA 的初始种群,种群维度为d维。选取fitness 函数,确定迭代次数的值Nmax以及种群数t。
步骤3 计算最优的fitness 值作为当前种群最优fitness的适应度初始值,利用式(4)计算种群的平均最优位置。
步骤4 若种群个体的转换概率p<rand,进行局部搜索,收缩因子φ=0.4;若rand≤p≤0.8,根据式(6)计算收缩因子φ;若p>0.8,收缩因子为0.9。计算花朵个体的适应度值,更新最优解的位置。
步骤5 判断是否满足适应度值最大值条件或者达到最大迭代次数:若是,停止迭代;否则返回步骤4。
步骤6 将CQFPA 优化得到的输入权值和阈值代入ELM模型中,利用式(16)计算出H。然后,根据式(17)得出输出权重建立ELM训练模型。
步骤7 根据训练好的模型对测试样本进行预测,评估网络模型的性能。
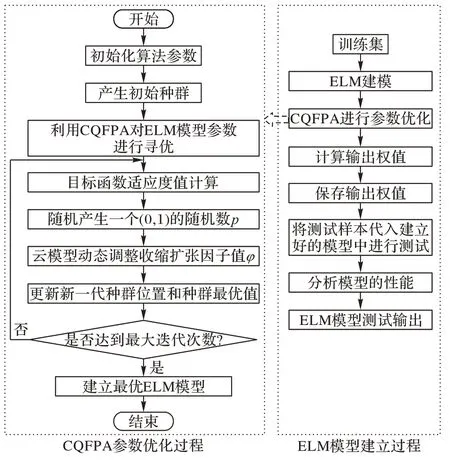
图2 CQFPA-ELM的流程Fig.2 Flowchart of CQFPA-ELM
3 CQFPA-ELM 在油气层识别中的实现
油气层识别技术是一项很复杂的动态研究技术,与它有关的参数有很多,比如:油藏厚度、油压、渗透率、含水率、油藏压力、储存有效厚度等,还有识别的准确性以及时间的影响[17]。本文提出的CQFPA-ELM 在分类上有很高的准确率,并且训练时间短,因此将CQFPA-ELM 应用到石油测井中,通过采用某油田提供的石油数据来验证此算法的有效性。
3.1 数据来源及预处理
本文在预测过程中,假定油井的静态数据是不变的。主要影响石油产量的因素有自然伽马(GR)、声波时差(DT)、自然电位(SP)、铀(U)、钍(TH)、钾(K)、微球聚焦(WQ)、深侧向电阻率(LLD)、浅侧向电阻率(LLS)、补偿密度(DEN)、补偿中子(NPHI)、光电吸收截面指数(PE)、井径(CALI)等13 个属性。本文选取了某石油公司提供的样本数据,由于各属性的量纲不一,数值范围各异,将这些数据先进行归一化处理,使得样本数据范围在[0,1],然后把归一化后的影响因素数据代入网络中进行训练和测试,得出结果。其中,样本归一化的计算式如下:

其中:x∈[xmin,xmax],xmin为数据样本属性的最小值,xmax为数据样本属性的最大值。为遵守保密规范,表1 只列出部分归一化的测井数据。数据归一化不仅能够加快训练速度,而且还能使神经元对输入更敏感。为了对比归一化前后对网络的影响,表2 中列出归一化数据前后的训练时间、识别率以及均方误差。

表1 样本数据(部分数据)Tab.1 Sample data(part of data)

表2 归一化前后对比Tab.2 Comparison before and after normalization
由于油气层影响因素对油气层识别的决定程度不同,本文使用的数据是经过属性约简技术处理过的数据,其中剔除了一些影响程度较小的属性,图3是属性约减后的5个属性归一化后的曲线。
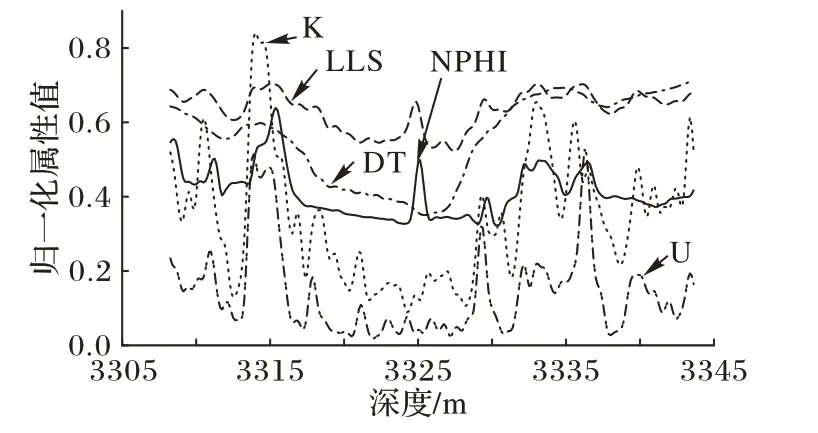
图3 属性归一化曲线Fig.3 Attribute normalization curve
3.2 ELM网络的实验参数选择
本文将样本数据随机分成两部分:训练样本用来构建ELM算法的整个神经网络;测试样本用在测试过程中,测试过程用来测试和检验训练网络的性能。下面给出训练过程中的参数选择及实验分析。
在油气层识别中,CQFPA中适应度函数如下:
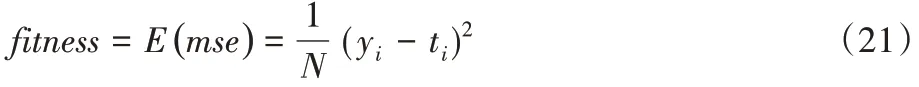
式中,N为输出样本的总个数。
初始化种群,本文迭代次数从0 到120 逐步增加,转换概率p=0.8,λ=1.5。寻找最优的粒子群,即所对应的适应度函数值为种群最小值的一组解。迭代次数逐步增加所对应的适应度函数值的变化曲线如图4所示。由图4可知,适应度值从80 之后开始收敛并趋于平稳,收敛速度较快,因此本文固定CQFPA 的迭代次数值为80。此时取最优的一组解作为ELM算法的输入权值和隐含层偏置。

图4 适应度值变化曲线Fig.4 Curve of fitness value change
将上面得到的最优的输入权值w和隐含层偏差b代入式(4),求出隐含层的输出矩阵代入ELM 网络模型中,得到ELM训练网络。
ELM 模型的激活函数分别选取sigmoid 函数、反正切函数(sin)、Gaussian函数(hardlim)进行实验对比,隐含层节点数从1 逐步增加到90,为了提高ELM 模型的准确性,进行了20 次训练,取20 次训练的正确率平均值,结果如图5 所示,比较3个激活函数对CQFPA-ELM 模型准确率的影响。实验结果表明,当隐含层节点个数相同的情况下,sigmoid 函数对应的CQFPA-ELM 模型的识别率最高,且隐含层节点数取35 时,识别精确度最高。因此本文的激活函数选取sigmoid 函数,隐含层节点数为35。
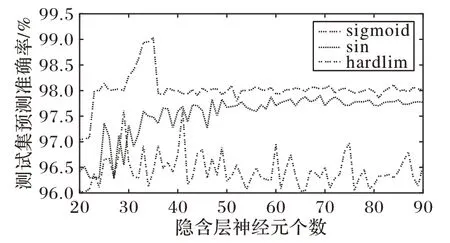
图5 激活函数对精度的影响Fig.5 Effect of activation function on accuracy
3.3 数据仿真验证与结果分析
本文算法的应用环境是Matlab 2014b,PC 的处理器是Intel Core i3-3110,主频2.40 GHz,内存6 GB。为了验证本文提出的CQFPA 优化ELM 参数的有效性,分别与PSO、ACO 和遗传算法(Genetic Algorithm,GA)进行对比。本实验各优化算法的参数设置为:PSO 算法的c1和c2均为2,ωmax=0.9,ωmin=0.2;ACO 算法的最大迭代次数为100,信息素因子α=1.7,启发因子β=2,信息素加强系数为Q=10,信息素蒸发系数ρ=0.2;GA的变异率Pc∈{0.35,0.04}。
本文利用2.2 节训练出来的ELM 网络模型进行预测验证,如图6 是传统的ELM 识别结果,图7 是PSO 优化后的ELM(PSO-ELM)的识别结果,图8 是蚁群算法优化的ELM(ACOELM)的识别结果,图9 是遗传算法优化的ELM(GA-ELM)识别结果,图10 是CQFPA-ELM 识别结果。其中:横轴表示深度;纵轴为油气层识别的标签,“1”表示非油气层,“2”表示油气层。通过对比,由图6~10 可知,相较经典ELM、PSO-ELM、ACO-ELM、GA-ELM 的识别结果,本文提出的CQFPA-ELM 的识别结果更为理想,和实际油井分布情况最接近。
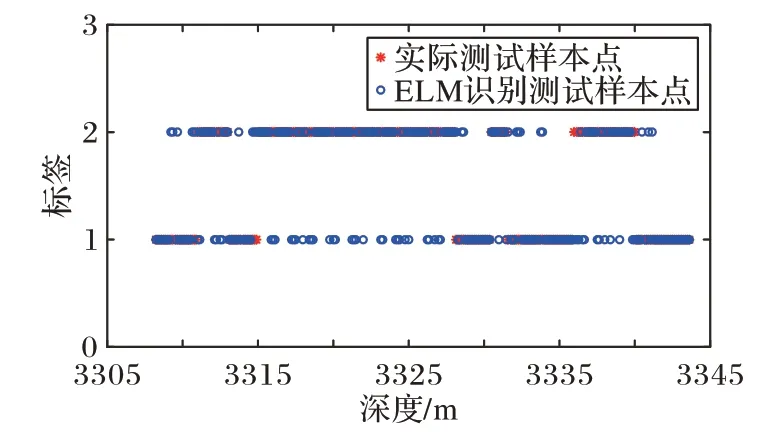
图6 ELM识别结果Fig.6 ELM identification results

图7 PSO-ELM识别结果Fig.7 PSO-ELM identification results
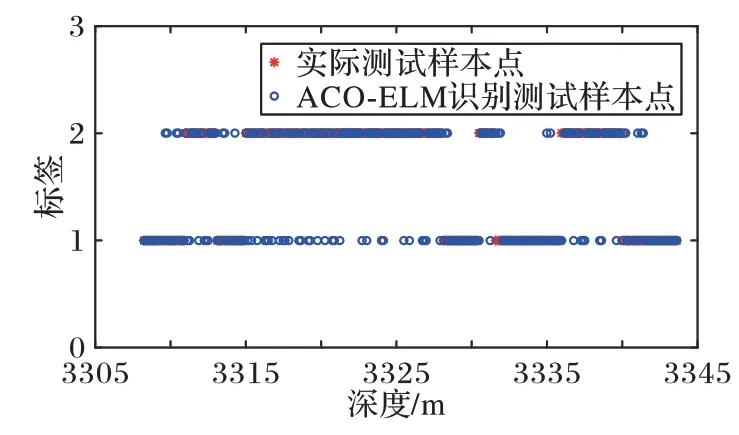
图8 ACO-ELM识别结果Fig.8 ACO-ELM identification results

图9 GA-ELM的识别结果Fig.9 GA-ELM identification results
为了展示传统的ELM、PSO-ELM、ACO-ELM、GA-ELM、CQFPA-ELM 的性能指标,其中包括均方根误差(Root Mean Squared Error,RMSE)、识别准确率以及运行时间,表3是各种算法运行30 次取得结果的平均值。由表3 可以看出,在油气层识别的研究中,CQFPA-ELM相较经典的ELM对油气层的平均识别准确率提高了10.52个百分点,而相较PSO-ELM、ACOELM、GA-ELM 的识别准确率分别提高了6.79个百分点、5.85个百分点、5.37 个百分点。综上,本文提出的CQFPA-ELM 模型有效地提高了分类精度,验证了该模型的分类效果较好。
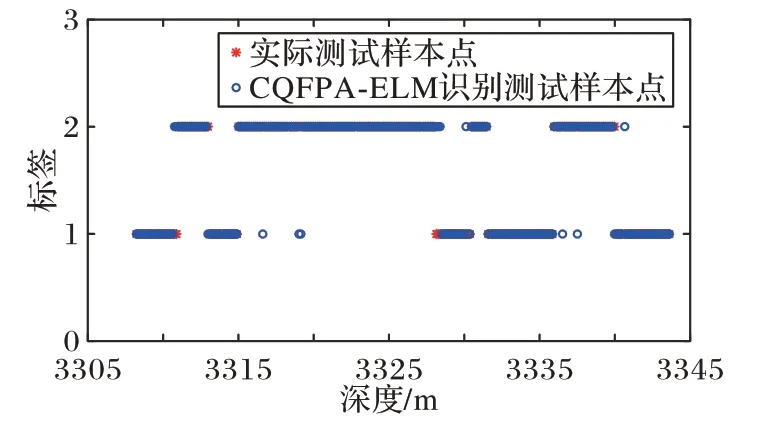
图10 CQFPA-ELM的识别结果Fig.10 CQFPA-ELM identification results
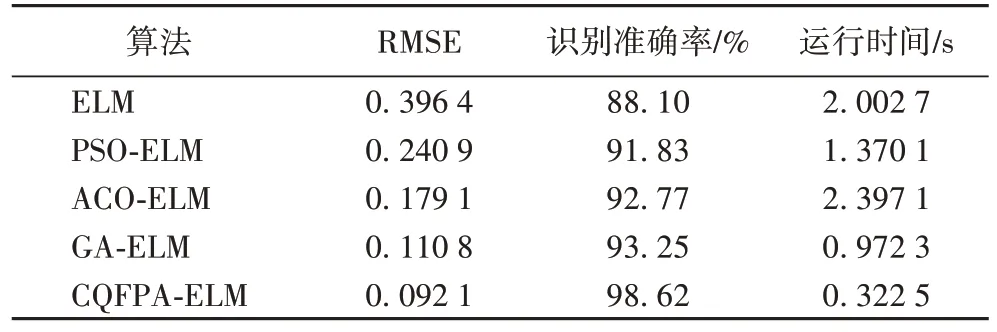
表3 不同ELM算法的性能比较Tab.3 Performance comparison of different ELM algorithms
蚁群算法比较复杂,搜索时间比较长,且容易出现停滞现象,因此在优化ELM 算法(ACO-ELM)上所用时间比另外三种优化算法(PSO-ELM、GA-ELM、CQFPA-ELM)长,达到2.397 1 s,而本文提出的CQFPA 在优化ELM 参数时,运行时间最少,验证了该算法具有较低的复杂度。
4 结语
本文提出的云量子花朵授粉算法避免了FPA易陷入局部最优的问题,且收敛速度加快。将改进的花朵授粉算法用来优化ELM 算法的输入权重和阈值,使ELM 模型的精度提高,并且训练速度加快,同时在网络参数选取上也避免了局部最优,能很好地找到全局最优值,这样得到的ELM 训练网络比较完善。将改进的ELM 算法应用在石油测井中,与ELM 算法以及PSO算法优化的ELM相比,CQFPA优化的ELM预测精确度更高,误差相对减小,表明该改进算法是可行的,可应用于油气层识别。在今后的研究中,可以进一步对ELM 的网络模型进行研究,例如增加ELM 的网络层数,将其达到深度学习的水平,以便应用到大数据集的识别和分类中。
