营养素养评价工具的汉化及在糖尿病患者中的信效度研究——基于CTT和Rasch模型的分析
2020-06-16陈圆圆杨春军王冬梅宋颖
陈圆圆,杨春军,王冬梅,宋颖
近几十年来随着全球经济的发展及生活方式的巨大变化,使得糖尿病患病率在世界范围内不断攀升,成为继心脑血管疾病、肿瘤之后第3大威胁人类健康的慢性非传染性疾病。中国是世界上糖尿病患者人数最多的国家,流行病学数据表明大约11%的人口患有糖尿病,而其中很大一部分尚未确诊,此外,35.7%的人群存在葡萄糖异常状态[1]。国际糖尿病联合会推荐糖尿病需要综合治疗,其中营养与饮食治疗是其他治疗措施的基础,贯穿于糖尿病自然病程的任何阶段[2]。随着对饮食与营养的日益关注,许多学者提出了营养素养的概念,即“个人获取和理解营养信息,做出正确判断,并运用这些信息维护和促进自身及他人营养状况的能力”[3-5]。有研究表明,较高的营养素养与健康饮食行为呈正相关,通过了解患者的营养素养水平,使其明确营养信息的重要性,也为临床医护人员实施针对性的营养教育措施提供依据[6-7]。然而,目前国内尚无成熟的评价工具测量糖尿病患者的营养素养。2018年美国学者GIBBS等[5,8]编制了用于测量营养相关慢性病患者营养素养的评价工具,并在美国、西班牙营养相关慢性病患者中使用,具有良好的信效度。本研究旨在对英文版营养素养评价工具(Nutrition Literacy Assessment Instrument,NLit)进行汉化,并在糖尿病患者中使用,评价其信度与效度。
1 对象与方法
1.1 研究对象 2018年11月—2019年5月采用方便抽样法选择在天津医科大学总医院住院的325例糖尿病患者作为研究对象。纳入标准:(1)符合1999年WHO糖尿病的诊断标准[9];(2)年龄≥18岁;(3)意识清楚,有基本的听说读写能力,能自行阅读理解或在别人帮助下理解问卷内容;(4)知情同意,自愿参与。排除标准:(1)患有严重精神疾病或认知障碍;(2)妊娠期糖尿病患者。本研究经天津医科大学总医院伦理委员会审核批准。
1.2 研究工具
1.2.1 一般资料调查表 使用自行设计的一般资料调查表收集患者一般资料,包括性别、年龄、文化程度、月收入水平等。
1.2.2 NLit NLit是由GIBBS等[5]研制的英文版自评量表,包括营养与健康(7条)、食物中的能量来源(6条)、家庭食品测量(6条)、食品标签计算(6条)、食物分组(8条)、消费者技能(9条)6个分量表,共42个条目,均为标准选择题形式,每个选择题包括了题干以及3~7个备选项,正确选项赋值1分,错误选项赋值0分,总分为42条目得分总和,理论最高分为42分。总分≤28分为极大可能低营养素养;29~38分为中等水平的营养素养;≥39分为极大可能高营养素养。该量表的专家效度及信度较好,整体信度为0.96。
1.2.3 健康素养-最新关键指标量表(Newest Vital Sign,NVS) NVS于2005年由美国学者WEISS等开发,是国际通用的健康素养测量工具,已被美国、英国、日本、中国等许多国家验证和使用[10-13]。可以用来测量人群健康素养以及营养素养中的阅读和计算能力。汉化版的NVS内容包括4项计算题和2项阅读题,简单易行,完成测评仅需3 min。量表采用2级计分方式,回答正确计1分,错误计0分,最高分为6分,得分0~1分为健康素养水平低,2~3分为临界水平,≥4分为较高的健康素养水平。该量表具有良好的信效度,本研究使用该量表作为效标测量中文版营养素养评价工具(CHINLit)的效标关联效度。
1.3 研究过程
1.3.1 量表汉化 取得原量表作者授权,严格按照Brislin翻译原则进行量表翻译和修订[14]:(1)正译:由1名营养学教授和1名护理学专业硕士独立完成量表的正向翻译,两者均精通双语。(2)审核:请1名临床护理专家和1名营养学专家进行独立审核,并由研究者记录修改意见。(3)回译:由1名双语护理专家和1名大学英语教师在未了解量表内容的前提下进行量表回译。(4)比对:有国外留学经历的护理专家对两份英文译稿进行对比分析,当语句一致率不足70%时,由翻译小组进行翻译和回译步骤的循环,直至达到与原量表在概念、语义、思想上等价。(5)修改:邀请1名博士学历的内分泌科主任对量表初稿与原量表进行对比,依据我国居民饮食习惯,对各条目内容提出修改意见。(6)专家咨询:为提高其严谨性和有效性,需对测试问卷进行专家咨询,将测试题编制成专家咨询问卷发放给5名工作时间10年以上,副高级及以上职称的专家(2名护理学教授、2名营养学教授、1名内分泌科主任),对量表的翻译效度、内容效度和跨文化调适做出评价并给予修改意见。考察内容包括:项目与主题的关系程度、项目语言的简明程度、项目语言的清晰度、项目与源语言的等值程度4个方面。研究者本人记录咨询结果,根据结果对量表进行条目筛选、修改或删除,形成CHI-NLit初稿。
1.3.2 预试验和正式调查 采用方便抽样的方法抽取符合纳入排除标准的30例糖尿病患者,发放CHI-Nlit初稿调查问卷。向患者解释调查目的、注意事项,填写完毕后当场收回,调查中询问患者对问卷的理解程度、填表感受、记录填表时间,存在问题和建议,结果显示,患者能够认真填写问卷和理解问卷内容,平均填写时间约15 min。抽取在天津医科大学总医院住院的338例糖尿病患者进行正式调查。
1.4 资料收集 研究者本人发放问卷,确定统一指导语,告知本次调查目的和主要内容,说明调查的保密性和匿名性,获得患者同意并签署知情同意书。问卷填写前告知其填写方式和注意事项,填写完毕当场收回。本研究共发放问卷338份,剔除无效问卷13份(无效问卷为患者无法在24 h内独立完成问卷),回收有效问卷325份,有效问卷回收率为96.2%。符合项目反应理论(Item Response Theory,IRT)中对Rasch模型样本量≥200的要求[15-16]。
1.5 统计学方法 采用SPSS 23.0软件进行经典测量理论(Classica Test Theory,CTT)数据分析,使用Conquest 4.5.2软件进行Rasch模型分析。计数资料采用相对数表示,计量资料以(±s)表示;CTT数据分析的指标包括量表的信度和效度,其中量表的稳定性采用重测信度,内部一致性采用库理信度(KR-21)检验,分量表得分与量表总分的相关性采用Pearson相关分析;效度检验包括内容效度和效标关联效度;采用IRT中的Rasch模型对数据进行信效度分析,主要包括:模型拟合度、难度、信度等。潜在特质的单维性是进行Rasch模型分析的一个重要前提条件,即模型所处理的测验只能包括一个潜在特质维度[17],而量表单维性检验可采用Rasch模型残差主成分分析法(PCA),以首因子标准化残差特值作为衡量量表单维性的指标,其范围为(1.4,2.1)[18]。通常,未加权均方拟合统计量(Outfit Mean Square,Outfit MNSQ)和加权均方拟合统计量(Infit Mean Square,Infit MNSQ)均可作为模型拟合度指标,取值范围为(0.50,1.50)[19],越接近于1表示越拟合。T值是均方(MNSQ)两种适配指标通过Wilson-Hilferty转换法转换成近似正态化的T分数,当|T|<2.0时,代表条目测量的是同一个概念[19]。条目-总分相关系数(PT-measure)表示个体在某一条目上的表现与在整个量表中表现的相关性,范围一般为(0.40,0.80)[20]。Rasch模型分析的项目信度表示项目在施测于其他样本时,项目排序是否相同,样本信度表示相同被试者在完成类似测验时,个体排序是否相同,两者取值范围在(0,1.000),越接近于1.000表示信度越好。怀特图是体现量表整体质量的指标之一,其将被试能力与条目难度放在同一尺度中,能直接显示出项目对于个体的适切度。通过对异常条目的拟合指数(难度值、Outfit MNSQ、T值、Infit MNSQ及PT-measure相关系数、Rasch信度)等方面进行综合评价,以作为条目删减与否的依据。首先对分量表进行逐一分析,其次对量表进行对比分析;间隔7 d后对30例糖尿病患者进行重测,计算其重测信度。采用KR-21对量表进行内部一致性信度分析,其表达式为,其中K为整个量表的总题数,为量表分数的平均数,S2为总分的方差。
2 结果
2.1 一般资料 受试者中男178例(54.8%),女147例(45.2%);年龄18~82岁,平均年龄(54.6±13.5)岁;文化程度:高中及以下173例(53.2%),大专103例(31.7%),本科及以上49例(15.1%);月收入水平:≤3 000元43例(13.2),3 001~5 000元129例(39.7%),5 001~10 000元102例(31.4%),>10 000元51例(15.7%)。
2.2 Rasch分析结果 本研究中的6个分量表是营养素养这一潜在特质的重要组成部分,即6个分量表中包含的条目都要指向营养素养这一特质。因此本研究首先对各分量表进行单维性检验,其次对量表进行Rasch模型分析。
2.2.1 单维性检验 分量表1~6的首成分残差特征值分别是1.7、1.8、1.7、1.7、1.8、1.6,总量表的首成分残差特征值是3.1。
2.2.2 数据-模型拟合 总量表的的项目信度为0.952,样本信度为0.827,分量表的具体情况见表1。
2.2.3 怀特图分析 条目难度分布大约为8个Logits,被试能力分布大约为6个Logits,结果详见图1。
2.2.4 项目分析 删除相关条目后总量表的项目信度为0.919,样本信度为0.838,具体删减情况见表2。
2.3 经典测量理论的信效度
2.3.1 内容效度 为了使量表内容更符合我国文化习俗及居民的饮食习惯,专家对各条目内容进行讨论修改,建议将条目1中的“黄油”修改为“动物油”,条目6中的“黑咖啡”修改为“矿泉水”,条目11中的“蛋黄酱”修改为“沙拉酱”,“人造黄油”修改为“植物油”,条目20~25中的“奶酪通心粉”修改为“蛋糕”,条目30中“猪排”修改为牛肉,为了便于受试者理解,将原量表中所涉及的重量单位“盎司”全部换算为“克”,条目34~42中所附食品彩图全部替换为中文食品彩图。根据内容效度计算方法,本研究结果显示,条目水平的内容效度指数(Item-Level CVI,I-CVI)为0.800~1.000,量表的内容效度指数(Scale-Level CVI,S-CVI)为0.905。
2.3.2 效标关联效度 以NVS作为金标准,Pearsen相关分析结果显示,CHI-Nlit评分与NVS评分呈正相关(P<0.05,见表3)。以NVS≤1分表示营养素养水平不足,绘制CHINLit预测营养素养水平的受试者工作特征(ROC)曲线,ROC曲线下面积(AUC)为0.885〔95%CI(0.846,0.924)〕,当CHI-NLit= 21.5分时,约登指数最大为0.623,此时灵敏度为0.884,特异度为0.757(见图2)。
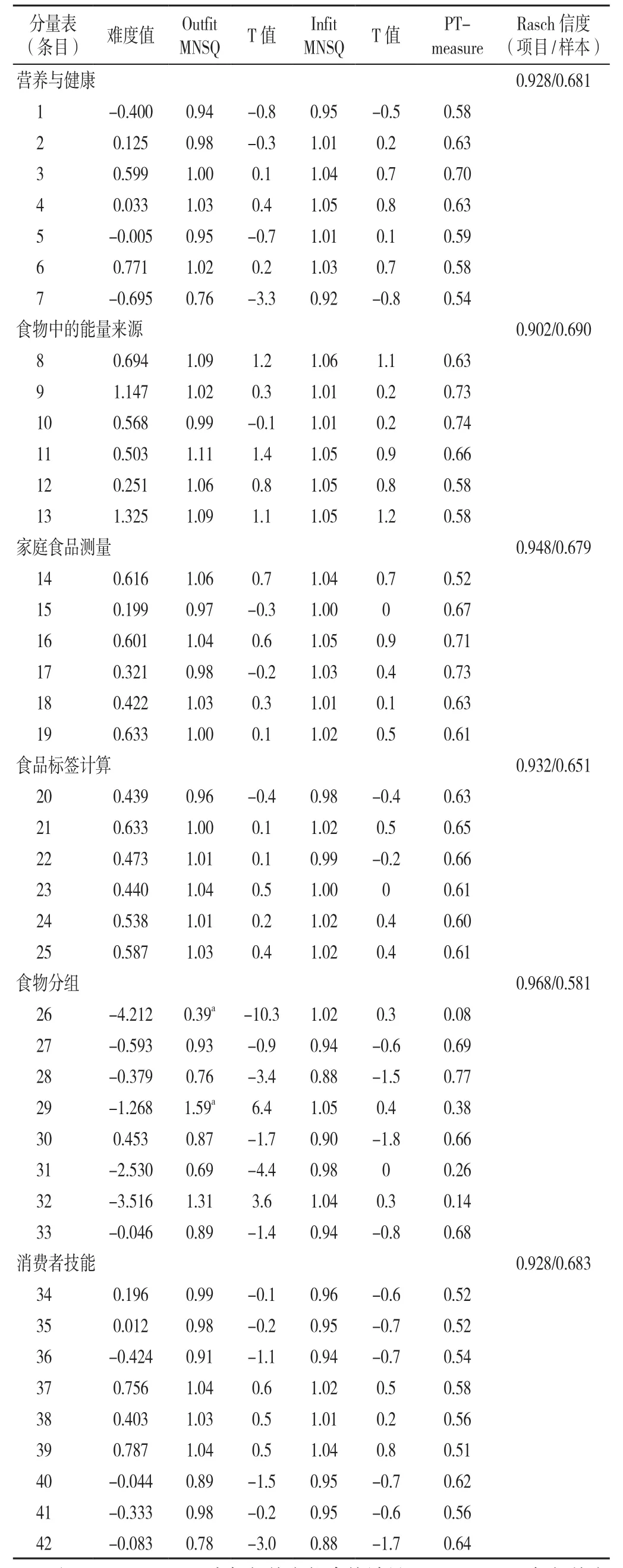
表1 项目拟合指数Table 1 Item fitting index
2.3.3 CHI-NLit的信度分析 分量表的重测信度为(0.895,0.931),KR-21为(0.688,0.721),总量表的重测信度为0.936,KR-21为0.860(见表4)。
3 讨论
本研究结合了CTT和IRT中的Rasch模型分析方法共同评价CHI-NLit的整体质量,探究其在我国人群中的适应性,并提出修订建议。

图1 中文营养素养评价工具怀特图Figure 1 The wright map of CHI-NLit
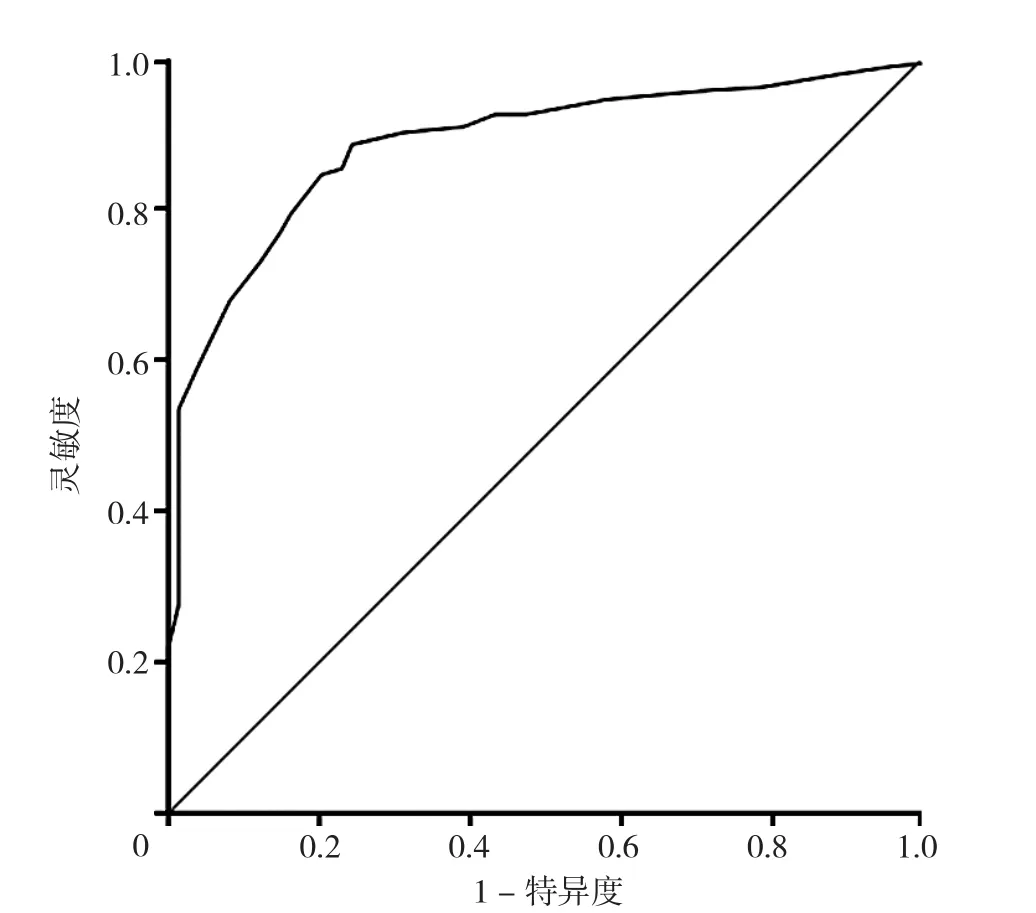
图2 CHI-NLit预测营养素养水平的ROC曲线Figure 2 The ROC curve of the CHI-NLit to predict nutritional literacy level

表2 项目分析结果Tabel 2 The results of item analysis

表3 CHI-NLit各维度评分与NVS评分相关性Table 3 Correlation coefficients of scale and subscale scores of CHI-NLit with NVS scale score

表4 CHI-NLit的信度分析Table 4 Reliability analysis of CHI-NLit
3.1 CHI-NLit具有良好的效度 一般而言,量表I-CVI>0.78,S-CVI>0.90,表明量表内容效度较好[21]。本研究量表的I-CVI为0.8~1.0,S-CVI为0.905,认为该量表具有较好的内容效度。CHI-NLit的结构效度通过Rasch模型分析的残差主成分分析、模型拟合度分析、难度分析等来验证,残差主成分分析结果显示,各分量表的首成分残差特征值均在标准范围内,表明各项目均在所属分量表中,即各分量表分别测量糖尿病患者营养素养的一个方面,不存在特质交叉。总量表的首成分残差特征值不在标准范围内,显示此量表并非单维量表,因此本研究支持原量表中6个维度的划分。依据原量表条目分布进行深层分析,模型拟合分析结果表明除26条目(苹果属于哪一组食物)和29条目(玉米饼属于哪一组食物)不拟合外,其余40个条目的Outfit MNSQ和Infit MNSQ指数为(0.69,1.31),说明数据与Rasch模型拟合良好。绝大部分|T|在参考范围内,说明量表内容能够预测被试者的营养素养水平。除第26、29、31、32条目的PT-measure相关系数不在标准范围内,其他条目的相关系数为(0.51,0.77),显示条目与分量表之间有良好的相关性。继而对量表进行难度分析,从图1可以看出条目难度分布大约为8个Logits,被试能力分布大约为6个Logits,说明难度处于中等水平,部分条目缺乏被试与其对应,过于简单以至于条目很难区分被试能力,如第26、31、32条目。为保证量表质量,需对CHI-NLit量表进行项目分析,有学者认为当某些条目与模型拟合不一致时,表示该条目与其他条目不协调,应将其删除,但并不表示该条目不重要,只是在本次调查中未能有效测出所需要的潜在特质[22]。BOND等[23]则认为不能以拟合指标作为条目删减标准,应根据拟合度指标对异常条目进行分析。本研究通过对相关指标进行综合评价,共删除4个条目,形成38条目的CHI-NLit,具有良好的结构效度。CHI-NLit与NVS相关性结果表明,CHI-NLit具有良好的效标效度,通过ROC曲线确定截断值为21.5,显示CHI-NLit总分<21.5分的糖尿病患者存在营养素养不足的风险,需要加强相关营养宣教。
3.2 CHI-NLit具有良好的信度 传统测量方法中,对于二分计分方式的量表的内部一致性信度采用KR-21信度表示,量表的稳定性通过重测信度表达,KR-21系数在0.6以上,重测信度系数(ICC)在0.7以上,表明问卷的信度较好[24]。本研究中,总量表KR-21和重测信度分别为0.860和0.936,分量表KR-21和重测信度分别为0.688~0.721和0.895~0.931。在Rasch模型分析中,可对项目信度和样本信度进行测量,其数值在0.6以上代表信度尚可。本研究结果显示,总量表项目信度为0.919,样本信度为0.838,分量表的项目信度为0.902~0.968,样本信度为0.601~0.690。总量表信度低于原量表信度(整体信度为0.960),但仍在接受范围内,可能与信度指标不同有关。两种测量方法均表明CHI-NLit具有良好的信度。
3.3 小结 通过传统信效度分析和Rasch模型分析结果表明,CHI-NLit拟合度良好,信效度较好,条目难度与患者能力水平分布合理,整体质量较好。条目内容简单易懂,并确定截断值为21.5,可用于糖尿病患者的营养素养调查,为临床快速筛查低营养素养患者并及时提供营养教育指导提供依据。本研究的局限性在于受条件限制,样本均选自同一地点,量表的普适性有待进一步验证;原量表中被试人群为营养相关慢性病患者(糖尿病、肥胖、高血压等),而本研究中仅选取糖尿病患者进行验证,因此未来研究可纳入多种营养相关慢性病患者,增加其适用性。
作者贡献:陈圆圆、宋颖进行文章的构思与设计;杨春军、王冬梅进行研究的实施与可行性分析;陈圆圆、王冬梅进行数据收集和整理;陈圆圆进行统计学分析,结果的分析与解释,撰写论文;杨春军、宋颖进行论文的修订;宋颖负责文章的质量控制及审校,对文章整体负责,监督管理。
本文无利益冲突。
