基于注意力机制和混合网络的小群体情绪识别
2020-06-12季欣欣钱勇生
季欣欣,邵 洁,钱勇生
(上海电力大学 电子与信息工程学院,上海 200090)
0 引 言
智能情感分析研究已经走过了漫长的道路,但传统上一直关注场景中的单一个体,而不是群体[1]。群体可分为大小群体,大群体如街道的人流,此时人与人之间并没有情感的交流和统一的情绪,本文是对多位个体间有情感交流的小群体进行情绪识别,下文提及的群体均指小群体。由于面部遮挡、光照变化、头部姿势变化,各种室内和室外环境不同以及由于相机距离不同而导致低分辨率的面部图像,因此群体情绪识别问题具有挑战性。
目前,针对群体情绪识别已有许多研究方法。Dhall等[2]介绍了AFEW数据库和群体情绪识别框架,包括使用面部动作单元提取面部特征,在对齐的面上提取低级特征,使用GIST和CENTRIST描述符提取场景特征并使用多核学习融合,但是他们提出的方法依赖于LBQ和PHOG特征和CENTRIST,其捕获面部表示和场景表示是有限的。Y. Qiao[3]提出将基于面部和整张图像上的卷积神经网络(CNN)单独训练,并融合以得到分类结果。然而群体情绪计算为群体成员的幸福水平的平均值,忽略了特殊个体信息(例如脸部的遮挡水平和哭笑的脸),因此对于群体情绪识别仍有待提高。
在本文中提出通过建立混合网络来解决这一问题,该网络在面部、场景和骨架上单独训练3个卷积神经网络(CNN)分支,然后通过决策融合以获得最终的情绪分类。其中一个模型是基于人脸面部特征来训练,并使用注意力机制学习不同人脸的权重,获得整张图片关于人脸的特征表示。通过对比实验,验证了本文方法的有效性,并获得较高的准确率。
1 群体情绪识别架构
本文的系统框架如图1所示。首先对检测到的人脸做对齐相似变换,作为面部CNN的输入,并通过注意力机制学习图像中不同人脸的权重,获得整张图片关于人脸的特征表示。其次使用OpenPose获得图像中人体的骨架,作为骨架CNN的输入。同时考虑了图片的场景信息,将整张图片作为场景CNN的输入。3种类型的CNN都训练了多个模型,然后对选取的模型执行决策融合以学习最佳组合。
1.1 面部CNN
群体图像中人脸所描绘的表情传达了充分的情感信息,在情绪识别中起着至关重要的作用,因此建立面部情感CNN来进行群体情绪识别。本文使用ResNet18[4]模型,模型的输入为对齐的人脸图像。为了减轻过拟合现象并增强模型泛化能力,使用CASIA-Webface数据集对其进行预训练,然后使用L-softmax损失在EmotiW训练数据集[5]中进行微调。下面介绍本文使用L-Softmax损失函数和注意力机制。

图1 群体情绪识别系统框架
1.1.1 L-Softmax损失函数
Softmax Loss函数经常在卷积神经网络被用到,较为简单实用,但是它并不能够明确引导网络学习区分性较高的特征[6]。Large-margin Softmax Loss(L-Softmax)被引入用于判别学习,它能够有效地引导网络学习使得类内距离较小、类间距离较大的特征[7],图2从几何角度直观地表示两种损失的差别,W1=W2即指等量的二分类问题。同时,L-Softmax不但能够调节不同的间隔(margin),而且能够减轻过拟合问题。在微调阶段,对于面部特征xi,损失通过以下公式计算
(1)
其中,yi是xi的标签,wyi是全连接层中j类的权重
(2)
(3)
其中,m是预设角度边界约束,k是整数且k∈[0,m-1]。

图2 L-Softmax损失几何理解
1.1.2 注意力机制
群体图像中存在多个人脸,为了可以独立于图像中存在的不同面部来进行情感识别,需要将所有的面部特征转换为单个表示。
最简单的解决方法是计算平均特征,但图像中某些面部情感与图像的标签无关,可能会混淆最终的分类。例如考虑哭笑的情况,许多方法容易将其混淆为负面情绪,因而无法进行有效识别。如果将置信度值与图像中每个面部相关联,就可以通过对哭泣的面部赋予较低的重要性,从而来推断图像表示正面情绪。
基于上述理解,本文使用注意力机制来找到图像中每个面部的概率权重,根据这些权重计算加权和以产生面部特征的单个表示。该注意力机制的方案如图3所示。将图像中检测到的面部输入到特征提取网络,即ResNet18。再把面部特征向量Pi输入到具有一维输出μi的全连接层,μi获取了面部的重要性,并用其计算得分向量Pm
(4)
然后将Pm和pi连接起来并将其输入另一个全连接层,其中一维输出注意权重δi表示pi和Pm之间的关系。根据注意权重计算特征的加权和,以产生特征向量Pd,其指示基于人脸的图像全局表示
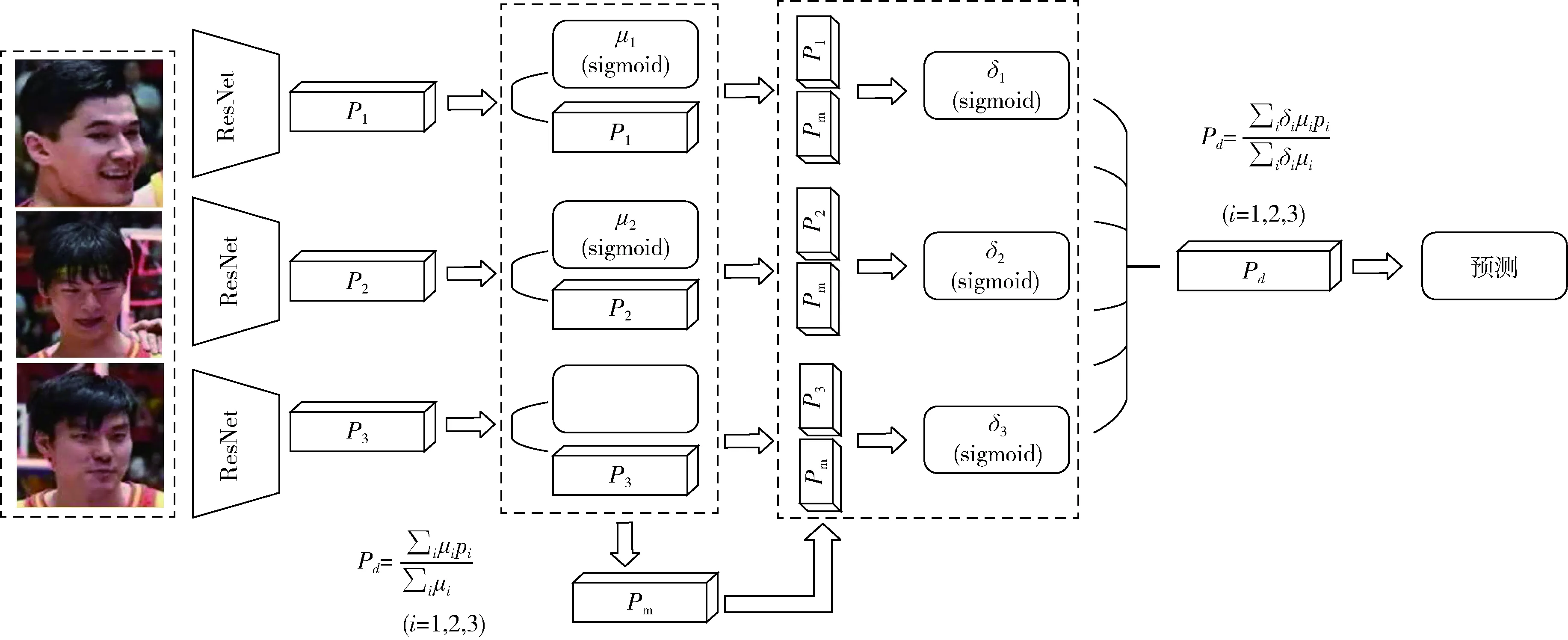
图3 注意力机制
(5)
1.2 场景CNN
图像的全局场景为群体情绪识别提供重要线索。例如在葬礼期间拍摄的照片最有可能描绘出负面情绪;在婚礼中拍摄的照片最有可能表现出积极的情绪;而会议室中出现的照片更可能是中立的情绪。因此,本文使用最先进的分类网络SE-net154[8]从整个图像中学习全局场景特征,训练基于图像全局的场景CNN。SE-net154是一种先进的识别网络,引入了压缩和奖惩网络模块筛选有用特征,压缩和奖惩网络模块如图4所示[8]。
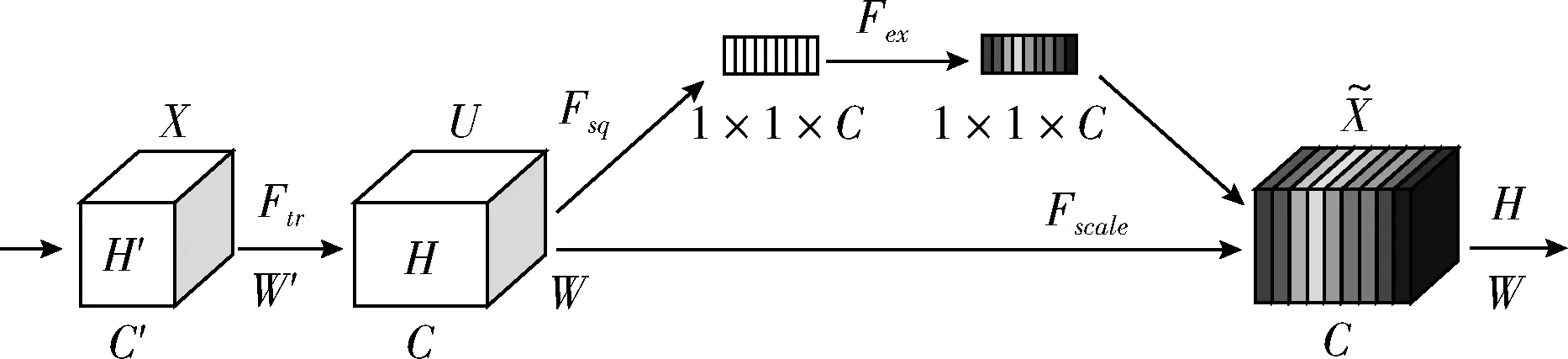
图4 SE网络模块
压缩和奖惩网络模块(squeeze-and-excitation blocks,SE)通过精确的建模卷积特征各个通道之间的作用关系来改善网络模型的表达能力,是一种能够让网络模型对特征进行校准的机制,使网络从全局信息出发来选择性地放大有价值的特征通道并且抑制无用的特征通道。压缩功能如下所示
(6)
其中,zc是压缩通道的第c个元素,Fsq(.)是挤压函数,uc是第c个通道的输入,W和H表示输入的高度和宽度。
奖惩操作包括两个全连接层两个激活层操作,具体公式如下
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(7)

1.3 骨架CNN
以往的情绪识别广泛使用人体面部特征,但根据实验心理学和情感计算的研究结果,身体姿势特征也传达重要的情感信息。为了保留人脸标志和身体特征关键点的相对位置,本文使用骨架特征表示,对应于人脸、身体和手的关键点集合。
本文使用OpenPose[9]来获得人体骨架姿势,它可以联合检测单幅图像中人体、手和面部的关键点(每个人总共135个关键点),并且与图像中检测到的人数相同,效果如图5所示。提取结果显示清晰的嘴形、身体姿势、手势和人物在图像中的布局,骨架特征图像与原始图像尺寸相同,再将图像按人体骨架外部最大矩形裁剪。本文使用ResNet101[4]、SE-net154[8]作为骨架CNN来识别群体情绪,首先通过模型获取图像中每个人骨架的得分,然后将所有骨架的得分和平均作为整个图像的预测。

图5 骨架提取
2 实验与分析
2.1 群体图像数据库
实验使用EmotiW数据库,其图像来自Group Affect Database 2.0[5]。它包括9815个训练图像,4346个验证图像和3011个测试图像,图像标签将群体情绪分类为正面,中性或负面。这些图像是从社交活动中收集的,例如聚会、结婚、派对、会议、葬礼、抗议等。该数据集的一些样本如图6所示。

图6 EmotiW数据库样本
2.2 网络的参数设置与训练
本文在基于Python的深度学习框架PyTorch环境下进行训练和测试实验。电脑系统环境如下:
(1)Ubuntu16.04×64;
(2)AMD Ryzen 5 1600 CPU;
(3)16 GB内存;
(4)NVIDA GeForce GTX 1080。
2.2.1 面部CNN训练
本文使用多任务级联卷积网络模型(MTCNN)来检测图像中人的面部,MTCNN是基于卷积神经网络的人脸检测方法,具有性能高和速度快的优点。它包含3个级联CNN,可以快速准确地检测和对齐面部5个关键点(即两只眼睛、两个嘴角和鼻子)。它根据输入图像构建多尺度图像金字塔,然后将它们提供给以下三级级联框架,候选区域在第一阶段产生并在后两个阶段细化,面部标志位置在第三阶段产生。
从MTCNN模型获得的面部因图像差异而具有不同的方向和比例,为了学习更简单的模型,将每个面部标准化为正面视图并且统一面部图像的分辨率。可使用5个检测到的面部标志点来进行相似变换,使得各脸部的眼睛处于同一水平并将图像尺寸重新缩放到96×112,获得所有基于人脸表情面部CNN所需要的对齐人脸。
对基于人脸表情的面部CNN,本文训练了注意力机制模型,即ResNet18_Attention。模型训练设置批量大小为16,初始学习率为0.001,且应用学习率衰减,每9个时期将其除以10,持续27个时期。
为了比较不同先进网络架构的性能,除了ResNet18模型,本文还使用了SphereFace[10]、VGG-FACE[11]和SE-net154。先在FERPlus表达数据集上预先训练这些CNN,然后在EmotiW训练数据集中使用L-Softmax损失对它们进行微调。
2.2.2 场景CNN训练
对基于图像全局的场景CNN,本文使用了4种网络:VGG19[11],ResNet101[4],SE-net154[8]和DenseNet-161[12]。其中VGG19在Places数据集上预先训练,ResNet101、SE-net154和DenseNet-161在ImageNet数据集上进行预训练,然后使用Softmax损失在训练数据集中进行微调。在这4个模型中,将所有图像保持长宽比例缩放至最小边256,这样可以最大程度保持图片形状,并随机裁剪224×224区域。训练参数设置与基于注意力机制的面部CNN模型相同。
2.2.3 骨架CNN训练
对于骨架CNN,本文采用的ResNet101和SE-net154在ImageNet数据集上进行了预训练,然后在提取的骨架图像上进行微调,且使用与基于图像全局的场景CNN模型相同的训练策略。
2.2.4 模型融合
单个分类器通常不能处理现代模式识别任务的多样性和复杂性,而且决策融合不同分类器的优越性也已经得到了证明。
混合网络是通过融合各个模型的预测而构建的,在所有模型的预测中执行网格搜索以学习每个模型的权重[13]。尽管它只是通过手动指定的超参数空间子集进行穷举搜索,并且不能保证是最优的,但它是决策融合有效且广泛使用的方法。权重范围从0到1,增量为0.05,其总和限制为1。权重为0的模型是冗余的,因此从混合网络中删除。
2.3 实验结果分析
评估人脸表情的面部CNN,表1显示了EmotiW验证集上5种面部CNN模型的结果,所有型号的准确度均达到70%左右。如表可得使用注意机制的网络比Resnet18基线提高了性能约2%,即训练面部CNN时,本文使用注意机制是有效的。
评估基于图像全局的场景CNN,表2列出了EmotiW验证集上4种场景CNN模型的结果。其中VGG19使用L-Softmax损失,ResNet101、SE-net154和DenseNet-161使用Softmax损失。由表可见SE-net154和DenseNet-161获得了较优的性能。
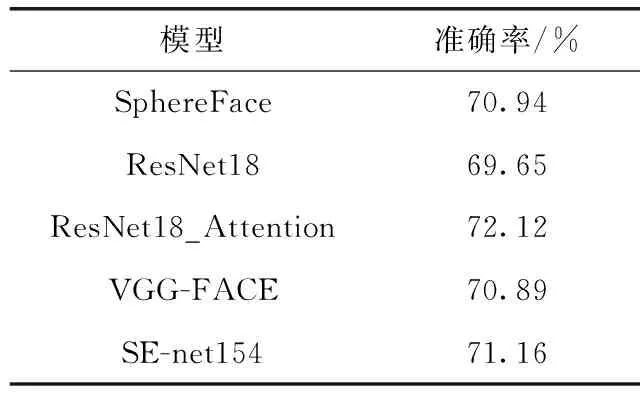
表1 EmotiW验证集上面部CNN模型的结果

表2 EmotiW验证集上场景CNN模型的结果
评估基于人物的骨架CNN,表3显示了EmotiW验证集上两种骨架CNN模型的结果。由表可见SE-net154的性能优于ResNet101。

表3 EmotiW验证集上骨架CNN模型的结果
如图7给出了3个CNN分支上最优模型的混淆矩阵,可知面部CNN和骨架CNN对于正类和负类表现相对更好,但在识别中性类时更差。这背后的原因可能是这两个分支的群体情绪由人体的面部和肢体语言主导,而没有考虑人物所处的环境。场景CNN在识别中性时取得了较好的效果,因此有必要结合多个分支的优点,提高准确率。

图7 各分支最优模型的混淆矩阵
混合网络最终由7个模型组成:SphereFace、ResNet18_Attention、ResNet18、VGG-FACE、SE-net154(场景)、DenseNet-161(场景)和SE-net154(骨架)。表4显示了EmotiW 测试集上具有不同权重的多个模型组合结果,并与文献[14]和文献[15]进行比较,准确率分别提高了3.82%和1.9%,验证了本文方法的有效性。

表4 EmotiW测试集上混合模型的结果
3 结束语
本文研究了对图像中小群体情绪进行识别的问题,提出基于3种视觉特征的卷积神经网络(CNN),即基于人脸表情的面部CNN,基于图像全局的场景CNN和基于人体姿势的骨架CNN。在面部CNN中引入有效的注意机制来融合不同人脸的面部特征,降低了由个别面部表情混淆最终分类的可能,还利用L-Softmax损失进行判别性学习。用OpenPose获得图像中的人体骨架作为骨架CNN的输入,充分利用了图像中人物的情绪线索,并在网络中引入压缩和奖惩网络模块来改善模型的表达能力。最后还探索了多个模型的决策融合,在EmotiW数据库上进行实验以评估所提出方法的识别性能。与现有技术方法相比,实验结果表明本文模型获得了较高的识别率,验证了本文方法的有效性。
