基于全局偏移表进行通用动态链接库函数跟踪的方法
2020-06-11张木梁王国庆张磊
张木梁 王国庆 张磊
(1.武汉深之度科技有限公司技术部 北京市 100080)
(2武汉深之度科技有限公司研发中心 北京市 100080)
1 简介
为了能够向用户提供一个通用的、高性能的方法进行动态链接库函数跟踪。本文引入了“一种基于全局偏移表进行通用动态链接库函数跟踪的方法”技术。
本发明技术受到基于PRELOAD的同名库函数跟踪与基于ptrace的断点式程序调试跟踪的启发,通过新的方法对进程执行过程中GOT表的修改与挂钩,能提供高性能的、通用的动态链接库函数的跟踪分析。
2 动态链接库函数跟踪设计
2.1 简要分析
Linux操作系统下的可执行程序普遍使用ELF格式,为了提高软件的模块化、运行性能与可维护性,减少软件启动时间与整体系统的内存占用,动态链接的技术被广泛使用。动态链接指的是软件运行所依赖的功能被存储在软件以外的动态链接库中,动态链接库暴露出字符串形式的函数接口,在运行期间,软件、动态链接器与动态链接库都被载入到软件的进程空间中。软件在调用某个动态链接库中的某个函数前,动态链接器会根据此函数的字符串名称解析得到动态链接库中函数的具体位置,并跳转到此函数的位置处执行代码,从而开始函数调用。由于此函数名解析定位以及调用的整个过程是在软件运行期间发生的,而不是在软件编译链接生成可执行程序的过程中发生的,因此此项技术被称为动态链接。
更具体的,在ELF文件中存在多个节(section),与动态链接密切相关的节包括全局偏移表(GOT,Global Offset Table)、过程链接表(PLT,Procedure Linkage Table)等。程序调用库函数时实际上会调用PLT中的代码,PLT中的代码会跳转到GOT表中存储的地址处,而GOT表中的地址应该是程序所需要调用的外部动态链接库函数的地址,由于在静态链接时相应的地址是未知的,因此其初始值实际上此地址填写的是指向PLT中的另一段代码,这段代码配合动态链接器负责在程序运行时解析对应的动态链接库函数地址,并最终修改GOT表中相应的地址为此地址,然后再跳转到此地址去执行库函数。这样,当以后程序再次调用此库函数时,即可直接跳转到库函数处执行代码,而不用再进行解析查找了。
一般GOT节的名称为.got.plt,其它动态链接相关的节还包括.dynsym节(动态符号),里面包含了动态链接所需要的符号信息,.dynstr节(动态链接符号所对应的字符串),.rela.plt节(重定位表节,里面包含了每个动态链接项在动态符号表中的下标、链接项的虚拟内存地址等信息)等。
本发明基于ELF文件与进程中GOT表的修改与挂钩的设计与实现,以及动态生成跳转代码表(trampoline)的技术方案的设计与实现。
跟踪库函数主要的技术包括两种,分别是基于PRELOAD的同名库函数跟踪与基于ptrace的断点式程序调试跟踪。
总的来说,本发明设计思路通用,性能高主要是因为:
(1)相比于基于PRELOAD的同名库函数跟踪的方法,针对每个待跟踪的函数,都需要进行手工函数声明,无法以通用的方式对未知的动态链接库函数进行跟踪的问题进行改进。
(2)相比较于基于ptrace的断点式程序调试跟踪的方法,在Linux操作系统下非常复杂的系统调用,牵涉到进程间通信、信号处理、进程状态查看与修改等,因此在国产处理器上的实现往往不完整或者有缺陷,会导致功能缺失或者性能下降的问题提高了性能。
2.2 与本发明相关的现有技术一
2.2.1 现有技术一的技术方案
在现有环境下,跟踪库函数主要的技术包括两种,分别是基于PRELOAD的同名库函数跟踪与基于ptrace的断点式程序调试跟踪。
为了调整程序运行时的行为,动态链接器提供了PRELOAD机制,系统管理员或者用户可以通过修改/etc/ld.so.preload文件或者设置LD_PRELOAD环境变量,以告之动态链接器,在软件启动之后首先载入上述文件或环境变量指定的动态链接库L。如果希望跟踪程序对动态链接库函数(如func1)的调用,开发人员可以在此动态链接库L中声明一个外部可调用的,与func1完全一样的函数签名(function signature)即可。这样,在程序调用func1函数时,实际上将调用L中的func1函数,而不是原来的func1函数。通过此方法,即可对感兴趣的动态链接库函数进行跟踪。
这种技术经常被用在对特定程序的跟踪上,而没有通用工具可以支持。
2.2.2 现有技术一的缺点
使用PRELOAD方法进行动态链接库函数的跟踪无法解决通用性问题。
从上述PRELOAD的技术方案可以看出,如果需要跟踪某个库函数,例如glibc中写入文件数据的函数write,则需要首先开发一个动态链接库,并在其中声明与write完全一样的函数签名(ssize_t write(int fd,const void *buf,size_t count)),然后再在自行开发的write函数内部实现函数的跟踪处理,并最终调用glibc实现的write函数(不然程序的逻辑显然会出现问题)。
因此,针对每个待跟踪的函数,都需要进行手工函数声明,无法以通用的方式对未知的动态链接库函数进行跟踪,而在实际情况中,我们常常需要对一系列的库函数进行分析,这样带来的开发量与维护量就会非常巨大。
这种缺陷是上述技术方案本身所无法避免的。因为此方案实际上是利用了动态链接器在解析库函数的时候,同名函数在更先载入的动态链接库中被首先解析到的原理,因此为了使用PRELOAD技术跟踪库函数,就需要一一实现同样名称的库函数,并编译生成待PRELOAD的动态链接库。
2.3 与本发明相关的现有技术二
2.3.1 现有技术二的技术方案
Linux内核提供了ptrace系统调用,第三方程序P可以通过ptrace调试应用软件S,包括暂停S,查看S的状态(内存与寄存器等数据),修改S的状态,恢复S的运行等。
如果P希望跟踪S的动态链接库函数调用,P可以在调用ptrace的时候使用PTRACE_POKETEXT参数,修改S的PLT中的代码,加入软中断指令(在x86下为int 3),这样在PLT解析动态链接库函数之后会触发这条软中断,从而使得内核开始处理来自于S的中断,并通知S的调试进程P,而P在收到了通知以后就可以查看S的进程状态,得知S将要调用的动态链接库函数,从而能对其进行跟踪了。在跟踪处理完毕后,P还需要再次调用ptrace,传入PTRACE_POKETEXT参数,删除修改后的软中断指令,恢复原有指令,以便程序继续正常运行。
这种技术在通用动态链接库跟踪软件ltrace被使用到了。2.3.2 现有技术二的缺点
基于ptrace的断点式程序调试跟踪有三个问题,第一个问题是它在程序运行过程中需要不断地中断程序的运行,以修改程序的指令(加入软中断指令或者删除软中断指令),并且中间还牵涉到内核态到用户态的状态转换,会带来相当大的性能开销。第二个问题是ptrace系统调用是Linux操作系统下非常复杂的系统调用,牵涉到进程间通信、信号处理、进程状态查看与修改等,因此在国产处理器上的实现往往不完整或者有缺陷,会导致功能缺失或者性能下降。第三个问题同样也是因为ptrace接口特别复杂,而且又牵涉到PLT表的修改,因此应用开发与调试跟踪的人员很难使用此项技术定制自己的动态链接库函数跟踪,最常用的仍然是更为简单,但是无法通用化的基于PRELOAD的同名函数替代跟踪技术方案。
3 本发明技术方案的详细阐述
3.1 本发明所要解决的技术问题
本发明解决了Linux操作系统下动态链接库函数跟踪的下列技术问题:缺乏通用的、高性能的方法进行动态链接库函数跟踪。
3.2 本发明提供的完整技术方案
在本发明中,库函数跟踪的模块形式一般为动态链接库,此动态链接库通过修改/etc/ld.so.preload或者LD_PRELOAD环境变量的方式,在程序主体以及动态链接库被内核载入进程空间后,即被动态链接库载入进程空间。被载入之后,即采取下列措施(下面汇编代码示例均采用x86汇编,实际可以外推到其它处理器的指令集):
(1)声明并实现一个函数trace_fn作为实际的动态链接库函数跟踪函数,可以被用户灵活定制,例如打印出当前时间戳与将要被调用的动态链接库函数的名称。它接受一个整数类型(int)的参数,是库函数的下标,返回长整数类型的值,应该是对应库函数的地址。
(2)声明并实现一个函数fn_hook作为跳板函数。此函数为汇编语言编写,它首先弹出(pop)栈顶数据至rax寄存器中,再依次将rbx、rcx、rdx、rsi、rdi、r8、r9、r10等寄存器的值压栈(push),继而将rax的值复制到rdi寄存器中,接着调用(call)trace_fn,进而依次弹出栈顶数据因此至r10、r9、r8、rdi、rsi、rdx、rcx、rbx等寄存器,最后跳转(jmp)到rax寄存器保存的地址处开始执行。

图1
(3)设置库的初始化函数(constructor),动态链接器会首先载入PRELOAD库,最后(与其它动态链接库比较)运行PRELOAD的初始化函数,因此库初始化时其它库的符号解析已经完成了。
(4)在库初始化时调用memalign函数分配一块32KB大小,页地址对齐页边界的内存,对应全局变量trampoline。
(5)在上述内存空间中,从0开始循环(循环变量为ndx),从前向后反复填充两条汇编指令。第一条汇编指令为push ndx,即将当前的ndx值压栈,第二条汇编指令为jmp fn_hook,即跳转到fn_hook函数去,每次循环ndx加一。
(6)将上述内存空间填满指令后,记录下总循环次数total,并调用mprotect将上述内存空间的属性修改为可读可执行,以使得上述代码可以被执行。
(7)声明结构体struct lib_func {long addr; char* name;},并初始化长度为total的lib_func数组全局变量libfuncs为全零。
(8)读取当前进程(即待跟踪程序)的进程空间虚拟文件/proc/self/maps,获得当前进程各个段(segment)的地址与范围。
(9)由于进程的内存内容由对应程序ELF文件中各个段一一映射而来,而ELF文件中的段又由节组成,下面即可根据ELF的规范解析可以得到.got.plt、.rela.plt、.dynsym、.dynstr节在进程空间中的具体地址。
(10)接着对.rela.plt节中的每个重定位表项进行如下循环,循环变量为i,从0开始:
1.调用ELF64_R_INFO宏通过重定位表项的r_info成员获得动态链接符号表中对应的下标,并根据上述.dynsym节的地址得到相应的动态链接符号;
2.通过动态链接符号的st_name成员,以及上述.dynstr节的地址得到此库函数的名称fn_name;
3.通过重定位表项的r_offset成员获得GOT表中的下标,并根据上述.got.plt节的地址得到GOT表中保存的对应库函数的地址fn_addr;
4.设置libfuncs[i]的addr成员的值为fn_addr,设置name成员的值为fn_name(通过strdup复制一个值);
5.将GOT表中对应库函数的地址从fn_addr修改为trampoline加上i乘以第5步中两条汇编指令的长度(以字节为单位)。
(11)在程序运行时,若调用到了库函数,则由于库函数的地址在GOT表中已经被修改为了trampoline中相应的地址,因此对应的执行流程会被修改为:
1.trampoline中相应的代码会被执行,即首先压栈库函数的下标,其次跳转到fn_hook;
2.fn_hook从栈中获得trampoline中压入的库函数下标,将其保存到rax寄存器中,继而将各个寄存器的值保存到栈中,调用trace_fn,传入的参数为rax的值(即库函数的下标);
3.trace_fn根据传入的库函数下标在libfuncs中得到库函数的名称与真实地址,并进行相应的跟踪分析处理,最后返回库函数的真实地址;
4.fn_hook恢复各个寄存器的值,从rax得到trace_fn的返回值,并跳转到库函数的真实地址处开始执行;
对应对被跟踪进程进行修改的流程如图1所示。
根据上述流程对被跟踪进程进行修改后,被跟踪程序在调用库函数时的流程如图2所示。
其中的虚线表示的是当没有本专利的程序运行时,库函数调用发生的路径。
在上述步骤中,有几个需要注意的技术点:
(1)第1步中的trace_fn函数中调用任何库函数(如printf、malloc、strstr等)都需要要么查找libfuncs中的地址进行调用,要么自行实现。如果直接使用原函数调用,由于trace_fn是在库函数被调用之前被调用的,则可能导致无限循环死锁。
(2)第2步的fn_hook函数中需要将栈上的库函数下标首先弹出到rax寄存器中,这是因为其它的寄存器,即rbx、rcx、…r10等在x86架构下都可能被函数调用用来保存调用参数,因此不能破坏这些寄存器的内容。但是由于调用trace_fn需要传递参数,call指令调用C语言的函数缺省使用rdi寄存器保存第一个参数的值,而且在trace_fn运行的过程中可能会使用到不同的寄存器,因此需要将rdi等寄存器的值保存在栈上,再将rax寄存器的值(保存着库函数的下标)复制给rdi寄存器,再调用trace_fn函数。而缺省情况下,函数的返回值(库函数的真实地址)保存在rax寄存器中,因此需要最后跳转到rax寄存器保存的值对应的地址处开始执行。
(3)第3步中的时机很巧妙,PRELOAD库是第一个被载入的动态链接库,在所有的动态链接库中,它的初始化函数也是最后一个被执行的。在其初始化函数开始执行的时候,主程序所依赖的动态链接库函数应该已经有一部分被解析填充了,因此可以获得真实的库函数地址。如果希望所有的库函数在此阶段都被解析填充,还可以设置环境变量LD_BIND_NOW进行完整的库函数解析。
(4)在第4步中须使用memalign或者valloc函数进行trampoline内存块的内存分配,不能使用常见的malloc或者mmap函数。这是因为malloc无法保证分配的内存在内存页边界上,但是第6步需要将此内存通过mprotect函数设置为可执行内存,而mprotect要求内存地址页边界对齐。而mmap分配的内存距离程序的主体太远,在64位操作系统上一般都会超出4G(即32位)的距离,从而导致jmp指令后面紧跟的32位地址溢出,memalign与valloc分配的内存在堆(heap)中,距离程序主体最近,因此需要选择这些函数。Linux下进程空间的内存地址分布参见图3。
(5)第10步中对库函数的挂钩处理能对所有的库函数进行处理,也能根据要求仅跟踪部分库函数,因此具有通用性,也具有可定制性。
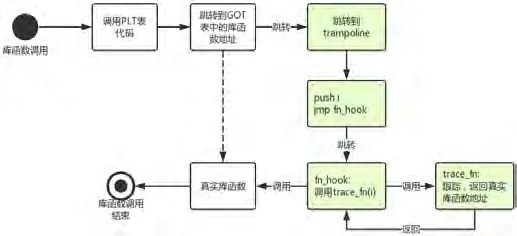
图2

图3
3.3 本发明技术方案带来的有益效果
本发明技术方案通过对进程执行过程中GOT表的修改与挂钩,能提供高性能的、通用的动态链接库函数的跟踪分析。此解决方案依赖性小,通用性强,运行性能高,可广泛用于Linux操作系统下应用程序动态链接库的跟踪与分析中。
