基于信息挖掘的模糊语言查询的研究
2020-06-09黄燕妮湖北师范大学文学院湖北黄石435002
黄燕妮(湖北师范大学 文学院,湖北 黄石 435002)
一、引言
随着现代计算机技术的应用和普及,普通互联网用户在查询所需要信息的时候会使用各种各样的搜索引擎,这种以数据库为基础的查询,可以分为完整查询和模糊查询两种。完整查询建立在使用精确关键字对全文索引的基础上,而模糊查询是用户可以使用词语片段作为查询项目来定位匹配的记录,也就是一种利用部分参数查找到相关数据的方法,后台的程序使用的是SELECT查询中的LIKE语句。如查询某个关键字“张三丰厉害”,可以针对“张三丰”或者“厉害”,或者它们的其它组合比如“厉害张三丰”来查找相关的数据。这种模糊查询要对全文进行索引,不仅耗费时间长,而且查找出来的数据准确率不高,比如“张三厉害”就不符合查询者原本的要求。
这种模糊查询和本文所论述的模糊语言查询是有区别的,区别在于:前者的查询是将关键字拆分,是一种特殊形式的完整查询;而后者是针对模糊语言本身作出的查询,是将模糊词输入计算机,赋予计算机一种“模糊思维”。计算机在运算与存储方面有着人脑不能企及的功能,但是到目前为止却始终未能代替人脑,其根本原因在于人脑与计算机运行的机制具有本质区别,人类语言的模糊性是人类大脑的特有机能,而计算机的运行基理是对各种精确数据做一些数学运算,最终得出非此即彼的运算结果。这种矛盾集中体现在了人机交互接口上,人在输入计算机时使用了模糊语言比如“厉害”,这是一个模糊词,到底什么样的情况算是“厉害”,什么样的情况不算是“厉害”,这个界定就是模糊的,对此计算机不能作出判断,但是又必须要完成已经下达的指令,计算机的处理方式是使用全文搜索的模式,查询到凡是包含“厉害”这个关键字的数据就全部显示出来,其中却包括了查询者认为不“厉害”的情况。如何将模糊语言学的理论运用在数据库查询领域,让计算机的查找结果更加符合查询者的心理预期,同时从测试结果上发掘出对于模糊语言学研究有用处的数据,就是我们本文的立论和试图解决的问题。正如CMU(Carnegie Mellon University卡耐基梅隆大学)在一个综合研究计划(Aura Project光环项目)中提出:“在一个计算机系统中,最宝贵的资源将不再是处理器速度、内存资源、磁盘空间或是网络带宽,而是人的注意力。”[1](GARLAN D,et al. 2002)
这种充分强调人性因素在智能型人机界面系统中的重要作用,和亚伯拉罕·马斯洛(Abraham Harold Maslow,1908-1970)的人本主义中心(Anthropologismus)的主张不谋而合。他将动机的出发点立足于需要上,需要是动机产生的源泉和基础,需要的性质、强度决定动机的性质和强度。在研究方法上,他主张弱化科学的研究方法,提出了“整体动力论”(后来被称为“自我实现论”)的研究方法。Xerox PARC(美国施乐公司)的首席执行官马克·威瑟(Mark Weiser)提出了普适计算(pervasive computing)的理论,他认为:“只有当机器进入人们生活环境而不是强迫人们进入机器世界时,机器的使用才能像林中漫步一样新鲜有趣。”[2](Mark Weiser,1991)科学技术不再以冷冰冰的面目呈现于人前,不是让人去被动地适应、接受它,而是以人为中心,让机器围绕人的需求主动地作出符合使用者个性的判断并提供服务,使人与计算环境自然地融为一体,从而实现真正意义上的以人为本的生活方式。
为了解决上述问题,我们运用模糊语言学理论,其建立的基础是美国数学家、系统理论家扎德(Lotfi A. Zadeh)的模糊集合理论。扎德从数学中的普通集合论中受到启发,提出了“模糊集合(fuzzy set)”这一概念[3](Information and Control,1965)。在普通集合论中,对于论域u中的一个子集A,某个元素u要么属于A,要么不属于A,两者必有其一为真,没有模棱两可的情况。普通集合所表达的概念的内涵和外延都是明确的。但现实生活中大量存在着“亦彼亦此”现象,即元素u在某种程度上属于A,同时在某种程度上又不属于A。这是普通集合论所不能解决的问题,扎德创立的模糊集合论为解释这种“亦彼亦此”的模糊事物和模糊概念提供依据,他通过量化中间过渡的方式对经典集合予以推广,目的是不脱离集合理论的框架来讨论模糊现象。模糊集合的元素不是确定的属于集合,而是某种程度的属于集合。属于集合A的程度可用模糊隶属度值来表示。模糊集合理论从人类认知的一个显著性特点——模糊性出发,认为人脑所形成的概念多数没有明确的外延,承认概念之间存在中间过渡性,由此形成模糊推理、模糊判断和模糊决策等智能系统。扎德认为概念可以分为模糊概念和非模糊概念两大类,模糊集合理论可以用来对自然语言中的模糊性问题进行研究。[4]从模糊概念的分类角度来分析,如果把“非模糊”的名称改为“精确”,把词分为模糊词(用来表示模糊概念)和精确词(用来表示精确概念)两大类,即“非模糊”是不是就等于“精确”,能不能简单地套用逻辑学上的“非真即假”的判断呢,两者之间有没有中间状态,即无法判断是模糊的,还是精确的,或者说,有没有介于模糊和精确之间的情况?我们认为从严谨的角度来说,为了突出语言的模糊性特征,将其分类成为模糊词和非模糊词更好。因为模糊是指不确定性、不精确性、不清晰性,与它相对的是确定性、精确性、清晰性。但是不确定性、不精确性、不清晰性不一定是模糊,可能是非模糊(non-fuzziness)的,它可以表现为歧义(ambiguity)、含混(vagueness)、笼统(generality)。
现代的计算机查询,不管是对单个数据库的查询,还是面对网络的搜索引擎的查询,文本输入的条件都是通过关键词来进行查询,这些关键词中有许多都是模糊词语[5](Princeetal,1980)。而计算机只能进行关键词的完全匹配或是部分匹配来进行处理,得到一些近似的结果,这些结果中有很多都是不准确的,但是人们在计算机上做各种查询之前,总是会对要寻找的对象有个清晰或是模糊的认识,这种认识促使个人去选择一些结果进行浏览。这些被浏览的结果之间必然有某种“共性”。这种“共性”就是这种认识,也就是对关键词的解析。这样在输入的查询关键词和浏览对象的“共性”之间加入了人的认知。如果我们通过某些工具来获取这种认知,那么将能够统计和分析人们对关键词的“解析”情况。同理,如果这些关键词是模糊词语,那么我们能够得到人们对一些模糊词语的范畴内隶属词的理解和应用,为我们今后对模糊语言的研究提供实际的对象和数据。
为此,我们设计了一种基于信息挖掘的模糊语言查询工具,这里的信息就包含了上述输入的查询关键字以及用户经过判断选取的数据。如果查询关键字是模糊语言词,则通过对选取数据提取共同具有的关键词,选取这些关键词中出现次数最多的几个词,作为该模糊词的隶属词,将隶属词与其对应的次数、数据保存下来。这些信息不仅可以作为模糊语言库信息,而且可以作为下一次查询判断的依据,来优化模糊语言的查询过程。
这种方法的优点首先是在获取模糊语言研究数据的同时,不仅不影响人们能够完成模糊语言查询的功能,而且通过历史搜索与浏览信息的挖掘还可以优化整个工具的性能,使模糊语言的方法得到真正的实用。其次,收集的模糊语言的信息可以直接导入到模糊语言库中,为采用模糊集的方法对各个模糊词范畴的边界进行科学的分析提供了真实的数据。如果要作为小范围内的科学实验的工具,只需在工具中设定特定的关键词和被查询的数据,然后让被实验者来进行针对性的查询。
二、一种基于信息挖掘的模糊语言查询工具的原型
为了进行模糊语言的定量研究,我们设计了一种基于信息挖掘的模糊语言查询工具,本节将从系统结构、模块功能、关键索引以及工作流程几个方面来详细介绍。
1.系统结构
如图1所示,整个工具分为两个大的模块:面对用户的客户端(例如网络浏览器)和提供计算和数据的服务器端。
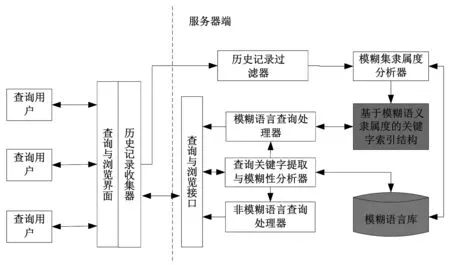
图1 系统模块结构图
这种结构具有一定的灵活性,一方面因为我们只是在传统的查询输入与结果浏览端增加了一个模块。这个模块类似一种窃听装置,它只有记录功能,不影响系统功能,因此这种方法适合各种查询和浏览工具。其次,本设计并不限定服务器是在云端还是在本地的数据中心。只要是能够得到查询与浏览结果之间信息的应用场景,都可以采用本设计的方法。
这种结构具有一定的可扩展性。可扩展性在计算机科学的应用领域是指当用户规模或是数据规模扩大以后,这种方法是否还是适用的。如图1所示,本设计的“瓶颈”在三处地方:历史记录过滤器、查询关键字提取与模糊性分析器以及索引结构。这些地方的瓶颈解决方法我们在后面会一一阐述。
这种结构能够便于模糊语言学家的操作。当系统安装成功后,查询与浏览界面并不会发生变化。当需要导出数据时,只需要将模糊语言库的文件导出,利用数据库查看工具可以进行查看或是输入到普通的文本文件或是excel文件中。这样便于后续模糊语言学家进行简单的处理和分析。
2.模块功能说明
在客户端,只需要在常用的浏览器上增加一个模块“历史记录收集器”。历史记录收集器主要收集三个数据。第一个数据是用户输入的查询条件,这些查询条件可能是句子,也可能是用空格分隔的关键词组。第二个收集的数据是服务器给用户选择的数据。这些数据有可能是一个网页,也有可能是一段文本或数字型的数据。第三个收集的数据是查询用户真正的选择或是浏览的数据。在本设计中实际上只需要对第一和第三个数据分析。为什么我们还收集第二个数据呢?我们主要基于两个考虑。第一个考虑就是不给客户端增加计算量,尽量减少对用户机器的影响,将过滤计算放到服务器端。第二个考虑就是如果我们额外的收集第二个数据,我们可以分析现有计算机对模糊语言的认识与人对模糊语言的认识之间的差异性,可能会导致产生新的研究领域和方法。
在服务器端包括七个模块和一个数据库,历史记录过滤模块主要是过滤上述收集的第二种数据以及第三种数据中与查询关键词完全不相关的浏览记录或数据。例如用户点击了“下一页”按钮出来的第二页显示结果的页面,这个页面是不需要进一步进行分析的数据,需要过滤掉,因此在这个模块中会定义一些特殊的规则来过滤这些不相关的数据。因为所有收集的历史记录都需要经过过滤器来过滤,过滤通常需要进行对比,而这种对比在计算机中具有很大的计算量。这将成为系统的一个瓶颈,为此,我们的处理是在系统实现时采用多个过滤器来进行分析,甚至于可以采用专门的计算机来进行过滤操作。
模糊集隶属度分析器主要完成三个功能:第一个功能是提取查询条件中的关键词。如果用户输入了一段话作为查询条件,分析器首先应该提取一些特殊的词作为关键词,如名词、动词等。第二个功能是分析用户真正浏览或使用数据的共同特性,采用的方法是统计这些数据之中相同的单词或数据项的个数。例如,关键词中包含“鸟”这个词。我们统计张三这个用户在这次查询中浏览的3个网页中,包含“知更鸟”的网页有2个,包含“鸡”的网页有1个。第三个功能是将这些分析出来的数据发送给索引结构和模糊语言库。
基于模糊语言隶属度的关键字索引结构是本文设计的重点。当查询条件中的关键字是模糊语言时,主要通过对被查询集合的数据进行索引来加快查询过程和提供查询准确度。对于每一个模糊单词我们都建立了一个模糊集合来存储对应范畴内的所有隶属词,每一个隶属词都具有对应的浏览次数。如果是某一个用户的统计次数,这个数值反映了这个用户对某一模糊词与其某一项隶属词的隶属度的见解。如果是所有用户的统计次数,这个数值就反映了所有使用过这个模糊词的范畴的认识。这一部分的内容将在稍后作详细论述。
查询关键字提取与模糊性分析器主要是对查询进行一个分类。首先对用户输入的查询条件提取关键字,然后根据关键字的模糊性将查询分为模糊语言查询和非模糊语言查询两种方式。如果所有的关键字都是特指,则将执行非模糊语言查询,否则将执行另一个。“特指”是指特定的具体的事物名称,如知更鸟、杨树、庐山、黄海等。不能特指的词有名词以及形容词等,例如狗、小、大、堆等。非模糊语言查询处理器根据关键词将在被查数据集中进行匹配操作得到精确或是部分匹配的查询结果,然后将结果发送到服务器端的查询与浏览接口。模糊语言查询处理器得到查询关键字后利用索引结构进行查询,然后将结果同样发送到服务器端的查询与浏览接口。
服务器端的查询与浏览接口主要是在服务器中负责与客户端的通讯。模糊语言库主要是存储各个模糊词及其对应的范畴,数据来源于模糊集隶属度分析器,在系统中为查询关键字的模糊性分析提供参考。
3.索引结构
为了让读者明晰地了解基于模糊语言隶属度的关键字索引结构的内部设计,在本节中将详细地利用实例与图来阐述。假设我们在某一个网络搜索引擎的基础上添加了一些表格,可以实现模糊语言的查询功能,如图2所示。主要的索引结构包含两个信息块:
第一个信息块是模糊语言库信息。这部分包含了两个表:表1为模糊词表,包括三列属性:第一列“模糊词”存储了模糊单词。第二列“行号”不仅表示该模糊词在表2中连续占有多少行,而且反映了在这个模糊词的范畴内有多少种隶属词。第三列“行号”存储了该模糊词在表2中的起始行号。表2为范畴表,存储了所有模糊词范畴内的所有隶属词。第一列“隶属词”存储了隶属词的名称;第二列“过滤器”采用了Bloomfilter[6](Rottenstreich,Ori,et al. 2012)过滤的算法得到一个字符串词,通过这个字符串可以判断某一个用户是否采纳过该隶属词的理解和应用;第三列“行数”反映了在表3中连续几行存储了用户对该隶属词的应用信息;最后一列“行号”指明在表3中存储了用户浏览信息的起始行数。这两个表存储了在用户利用该查询工具时对模糊语言的认识,可以用来作为模糊语言研究者的研究对象。
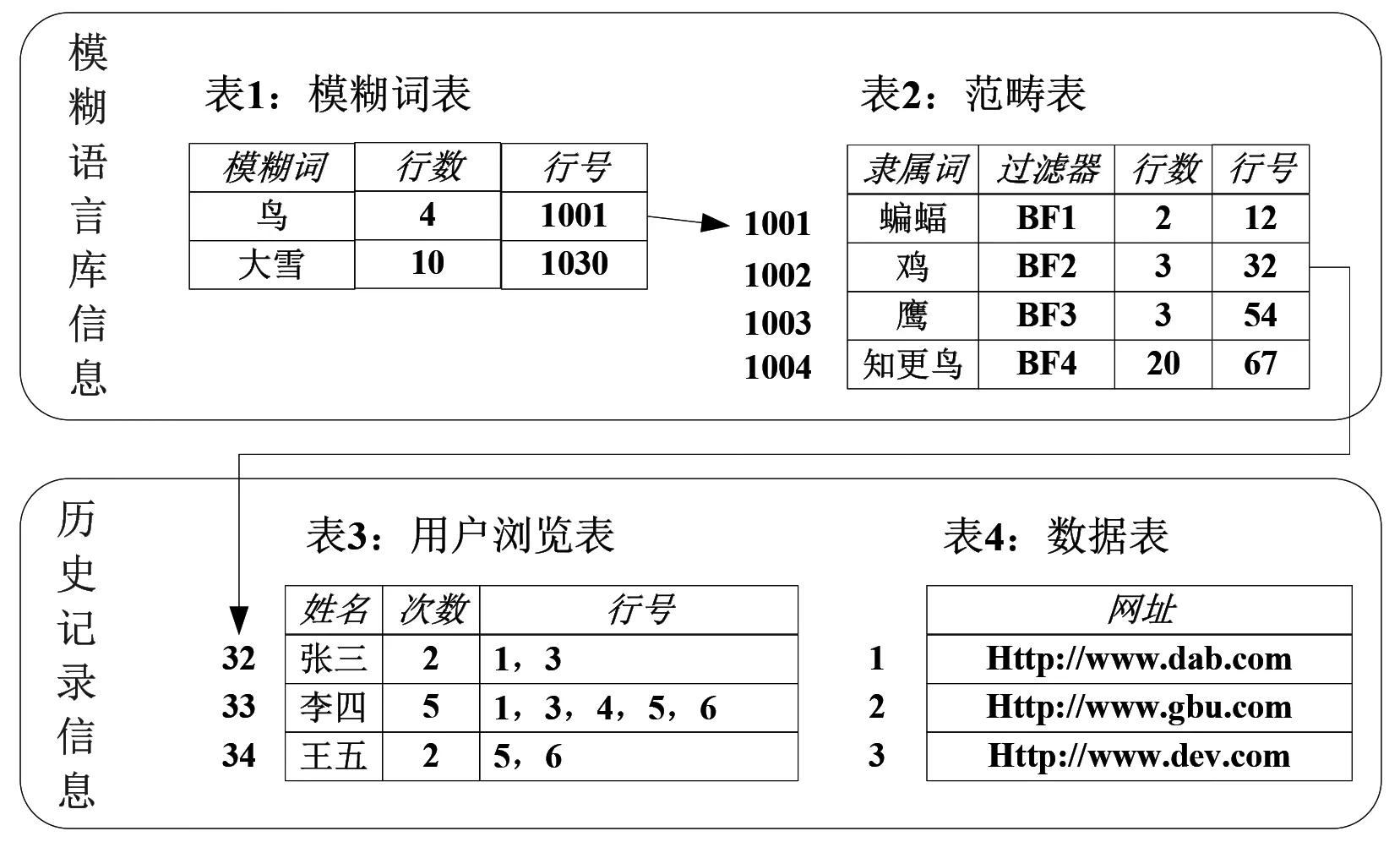
图2 索引结构示例图
第二个信息块存储了用户浏览的历史记录。为了便于模糊语言学研究者的研究,本设计将每个用户的浏览记录做了分开存储。表3是用户浏览表,存储了用户对一模糊词的范畴内的某一个隶属词的浏览情况。第一列为用户的姓名;第二列为用户浏览的次数;第三列为用户浏览了表4中哪些行记录的数据。次数将大于等于行号,因为有可能用户多次访问同一个表4记录的数据。表4为数据表,记录了用户访问过的数据。在本示例中,这些数据为一些网址,表明用户访问过这些网站。在这个信息块中的表4将随着用户浏览次数的增加而增大。如果为了性能,可以将它们存储到新型存储器件SSD中。如果存储在硬盘中,将会影响系统查询性能。
4.工作流程
在本小节中结合图1的结构图和图2示例,简要介绍基于历史数据的挖掘,系统是如何查询数据,并提高查询速度的。
假设用户张三在客户端的查询与浏览界面输入的查询条件中含有“鸟”这个模糊词,并且张三从来没有浏览过除了“鸟”的范畴内隶属词“鸡”以外的信息。首先历史记录收集器会收集到这个查询条件,然后将查询条件发送给服务器端的查询与浏览接口。该接口接收到查询请求后,将查询条件送到查询关键字提取与模糊性分析器中。该分析器会提取查询条件中的所有单词,然后分析这些词中哪些是关键字,发现“鸟”这个词也是一个查询关键字。最后通过模糊性分析发现“鸟”为模糊词,判断该查询为模糊语言查询,将查询条件发送给模糊语言查询处理器。
模糊语言查询处理器得到所有关键字后,将模糊关键字送入基于模糊语义隶属度的关键字索引结构中去做查询,而将非模糊关键字在数据集中做普通查询。索引结构得到模糊词“鸟”后,在表1中查询可知,这个词包含了4个隶属词,并得到表2的起始行号为“1001”。通过该行号我们可以在表2中得到4个隶属词的过滤器,因为用户张三从来没有浏览过除了“鸟”的范畴内隶属词“鸡”以外的信息,所有通过bloomfilter过滤器计算只有“鸡”对应的浏览记录中有用户张三。因此通过“BF2”得到该隶属词对应的用户浏览表的起始地址“32”和行数“3”。然后在表3中从起始地址“32”起3行内找到张三对应的行。然后得知张三浏览过2次含有隶属词“鸡”的信息,并发现是表4中第1行和第3行存储的网址。然后模糊语言查询处理器将这两个网址同其它非模糊词查询到的网站进行合并得到用户张三最有可能访问的网页地址,然后发送给服务器端的查询与浏览接口,再由该接口将查询结果返回给用户张三。
张三的客户端历史记录收集器也将记录这个返回结果,然后将它传给客户端的查询与浏览界面显示出来供张三进行选择查看。如果张三选择了点击某些网页后,完成了该词查询,那么查询过程就此完成,而历史记录收集器将收集该信息,将收集到的所有信息传递到服务器端的历史记录过滤器,由过滤器过滤不太相关的网页,然后将相关的网页发送给模糊集隶属度分析器来分析哪些页面是与模糊词“鸟”相关的,如果这些页面中有了新的共性词,将该词作为“鸟”的新的隶属词加入到表2中,并修改索引结构中需要调整的所有表格,当调整完成后,本次查询带来的所有操作都结束了。
三、未来工作
通过这个工具,研究人员不仅可以获得一个日常使用的模糊语言的隶属度,而且可以结合各个用户的历史记录来分析以人本为中心的各个模糊语言的隶属度。但是,这个系统还是一个比较粗糙的原型,在这个原型的基础上,我们未来还将有一些新的思考和改进。在此详细阐述一下,以期得到大家共同的思索和指正。
首先,在查询条件的各个关键字之间存在一定的潜在关系会影响查询的结果,例如,我们输入的查询条件是“一堆稻谷的图片”和“一堆木箱的图片”。如果我们将“堆”的数目(number)与第二个关键词(“稻谷”或”木箱”)进行分离查询,将会得到过多的中间结果,影响系统的性能。这也说明在各种语用场景中即使是同一个模糊词语也会带来不同的影响。因此,在未来工作中需要将输入的查询条件中的各个关键词,不管是模糊词语还是非模糊词语都结合起来,通过挖掘它们之间的关系来优化系统的设计。
其次,对于系统的性能来说,从计算机科学的现有研究来说,在语言研究方面的定量分析工具绝大部分采用了数据库的存储和索引方式,这对于系统的可扩展性有很大的限制性。例如,当工具涉及的数据库越来越多,执行一个常用的JOIN命令可能需要几十分钟,会严重限制工具的可用性,更何况是想要在提供用户特定功能的同时还要收集可供自己研究的数据,系统性能方面更需要利用计算机科学的最新方法。例如在上文中的表1。实际上我们可以采用LSH(Locality sensitive hashing)的索引方式[7](Pauleve,L. 2010)来索引和查询,每次只用执行一次KEY的计算操作就可以了,而不用在数据库中去进行字符串匹配操作。这样,我们可能会在未来对系统的实现方面进行优化,以期得到更高的性能。
再次,在本设计中并没有强制性地规定什么样的词是模糊词,也没有预先定义一个模糊词的库,而是采用粗浅的“是否是指定”的判断,只有当系统运行一段时间,收集到一定量的模糊词后才能优化系统的查询功能。因此,我们希望能够通过更深入的模糊词义的学习,来找到或是构造一个初步的模糊词的库,然后通过本系统来对这个库进行扩展。最后将这个库能够公布出来,将得到的新的认识和规则来丰富和精炼这个模糊词集,方便我们所有相关研究人员的研究。
