基于稀疏表示变量选择方法的影像遗传学数据分析
2020-06-08谢忠翔武杰项华中
谢忠翔,武杰,项华中
上海理工大学医疗器械与食品学院,上海200093
前言
在信号恢复和重要成分识别等应用中,稀疏表示(包括压缩感知)受到了研究者的关注,该方法最主要的一个特点是:要恢复的信号或要检测的重要成分数量通常等于样本数[1-2]。然而,在基因组数据或生物医学成像数据分析中,样本数量通常远远少于变量数量。由于现有压缩感知方法不能直接应用于这些数据进行变量选择[3-4],因此,本研究在传统稀疏回归模型基础上,改进了它在不同范数条件下进行变量选择能力,形成一种基于稀疏表示变量选择算法(Sparse Representation-based Variable Selection Algorithm,SRVS),且结果表明,SRVS 能更准确地选择精神分裂症影像遗传学特征,筛选有效性更高。
本研究利用基于稀疏回归模型的SRVS,改变Lp(p=0、0.5 和1)范数,对208 名受试者(96 名精神分裂症患者和112 名健康对照者)的41 236 个功能磁共振成像(function Magnetic Resonance Imaging,fMRI)体素和722 177 个单核苷酸多态性(Single Nucleotide Polymorphisms,SNP)进行联合分析,以识别精神分裂症影像遗传学特征。精神分裂症是一种复杂疾病,它是由多种遗传因素(如基因调控的改变、mRNA和SNP 的改变)和环境效应相互作用的结果[5-6]。近年来,许多研究集中于探索与精神分裂症相关的关键基因或SNP[7]。除了遗传学研究,fMRI还为精神分裂症的研究增加了一个维度,因为fMRI能够识别精神分裂症患者大脑区域的结构和功能异常。然而,在大多数研究中,fMRI和SNP 都是分开单独分析[8]。本研究将结合fMRI和SNP,使用SRVS来选择精神分裂症的影像遗传学特征。
1 资料与方法
1.1 一般资料
本研究采用由Mind Clinical Imaging Consortium(MCIC)收集的数据,所选取的数据均符合《美国精神障碍诊断与统计手册》第4 版(DISM-IV)精神分裂症诊断标准[9]。两种类型数据(41 236 个fMRI体素和722 177 个SNP)收集自208 名受试者,包括96名精神分裂症患者和112名健康对照组。
1.2 研究方法
本研究将传统线性回归模型扩展到两类数据集的集成分析:

其中,Y∈Rm×1为观察向量,即受试者的表型,1表示健康人,0表示精神分裂症患者;X1∈Rm×n1和X2∈Rm×n2为两种数据类型的测量矩阵列标准化;X=[α1X1,α2X2] ∈Rm×n;α1和α2为两种数据类型权重,且α1+α2= 1,α1,α2>0;ε∈Rm×1为噪声引起的测量误差。该模型建立目的是基于已知的表型Y和测量的数据矩阵X来恢复未知的稀疏向量δ=其中δ1∈Rn1×1,δ2∈Rn2×1且n1+n2=n。
为了在具有少量非零项的稀疏向量δ(对应于少量的X测量值)的情况下,对表型Y进行最佳逼近[10],使用SRVS 近似求解公式(1)给出的回归问题,并选取稀疏向量δ中非零项所对应测量矩阵X中的列作为所要提取的特征。
SRVS算法流程如下:
(1)初始化δ( 0)= 0;
(2)对于循环l,从fMRI和SNP 测量矩阵中随机选择k列,重组一个m×k子矩阵,用Xl∈Rm×k表示;同时将所选列的索引向量表示为
(3)解决Lp最小化问题[11],找到最优稀疏解δl∈Rk×1:
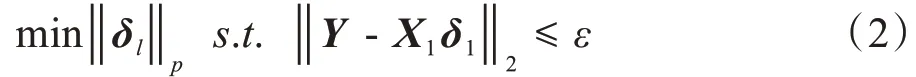
(4)根据上一步得到的δl来更新δ(l)∈Rn×1,δ(l)(Il)=δ(l-1)(Il)+δl;其中,δ(l)(Il)和δ(l-1)(Il)分别对应表示δ(l)和δ(l-1)中第Il项;
(5)如果不满足停止准则,则更新l=l+ 1,并返回步骤2;否则,令并循环终止,稀疏向量δ中非零项对应于数据测量矩阵X中选择的列向量。
在步骤(3)中,目前已经有许多行之有效的方法来解决Lp最小化问题。例如,对于p= 1 时,可以用同伦算法来解决[12];p= 0 时可用正交匹配追踪算法[13];p= 0.5时可用MFCOUSS算法[14]。
在步骤(5)中,设置了以下两个算法迭代停止准则:
(2)X中的每一对列向量被比较的概率应该大于1-pstop。
当两个停止准则都满足时,迭代停止。
2 结果
在本研究中,分别将α1和α2作为fMRI数据和SNP 数据的权重因子,α1+α2= 1。当权重因子α1=1 或者α2= 1 时,相当于只选择了一种类型数据(fMRI数据或SNP 数据)。通过对模型中fMRI数据和SNP 数据各自权重的适当调整,提取具有显著意义的fMRI特征和SNP特征,同时将其与公认的45个精神分裂症基因[15-16]进行对比验证。
2.1 不同权重及范数下SNP特征提取
为选出最佳权重因子α,设置参数VarNum(即最终提取的变量数)为200,令α1= 0.20~0.85,以0.05间隔取14次,在L0范数模型下,选取精神分裂症影像遗传学特征。
不同权重下筛选的fMRI特征和SNP特征数量对比图见图1。由于两类数据的数据量差别巨大(41 236个fMRI数据,722 177个SNP数据),在L0范数模型下,只有当fMRI权重α1≥0.45时,才能提取到fMRI特征,而当SNP权重α2≥0.85时,几乎提取不到fMRI特征。当权重α1≥0.85或者α1≤0.45时,只能提取到一类数据特征(fMRI特征或者SNP特征)。

图1 不同权重下筛选的fMRI特征和SNP特征数量对比图Fig.1 Comparison diagram of the number of fMRI features and SNP features extracted under different weights
根据图1显示的结果,选取SNP 权重范围为0.20~0.65,以0.5 为间隔取10 组,分别在3 组Lp(p=0、0.5、1)范数模型下提取SNP特征,结果见图2。、
由图2a 能够发现,L1范数下筛选出的SNP 特征数量要远远超过L0范数和L0.5范数下筛选出的SNP特征数量,且当SNP 权重为0.55 时,L1范数下筛选出的SNP 特征数量达到一个峰值。在图2b 中,可以发现,在L0范数和L0.5范数下,当SNP 权重分别为0.6、0.5时,筛选出的SNP特征数量达到最大值。

图2 不同权重下Lp(p= 0、0.5、1)范数模型中筛选的SNP特征量折线图Fig.2 Polyline graphs of SNP features extracted in Lp(p= 0,0.5,1)norm model under different weights
设定权重α1:α2= 0.5:0.5,在3 种Lp模型(p=0、0.5、1)中进行处理提取特征,提取到的SNP特征分别为1 100、3 034、28 064个,找出对应的基因数据,并将其与公认的精神分裂症的45个易感基因进行对比[17]。选取出精神分裂症相关的SNP数据,认为在多个模型下重复出现的数据更具有显著意义,因此选取至少被两种模型选中的SNP数据,结果见表1。

表1 3种Lp模型中筛选的SNP特征Tab.1 SNP features extracted in 3 Lp models
在该条件下,找出3 种模型所共同提取出的941个SNP 特征,并将其与之前学术界公认的精神分裂症的45 个易感基因进行对比,发现有DAOA、HTR2A[18]和GABRB2属于这45个易感基因。
2.2 不同权重及范数下fMRI特征提取
通过比较不同权重下筛选的fMRI和SNP 数据的特征量,可以明显发现,对于fMRI数据,可以令其α1=0.5~0.85,以0.05 的间隔取8 次,在范数模型p=0时,选取与精神分裂症相关的影像遗传学特征。
在L0范数模型中,fMRI的权重因子数值越大,所提取到的fMRI特征数量也就越多,尤其是当权重因子超过0.75 时,提取到的fMRI特征数量有一个飞跃性的增长(图3)。
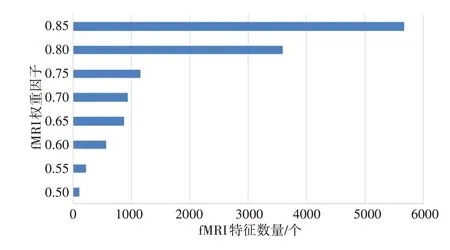
图3 不同权重下提取的fMRI特征数量Fig.3 Number of fMRI features extracted under different weights
通过调整权重来提取fMRI特征,从而寻找合适的权重分配。设定权重因子α1:α2= 0.5:0.5,在3种Lp模型(p= 0、0.5、1)中进行处理提取特征,筛选到的fMRI特征数量分别为118、77、1 973个。
在L1范数下,提取1 973 个fMRI特征,其中有些fMRI特征属于AAL脑模板116个脑区中的同一个脑区,接下来对此进行分区。在L1范数下,权重因子α1:α2= 0.5:0.5 时,所提取到的fMRI特征总量为1 973个,远远超过L0范数下的118 个和L0.5范数下的77 个(图4)。其中,以96 号(Cerebelum_3_R)和92 号(Cerebelum_Crus1_R)脑区提取到的fMRI特征数量最多,而这两个脑区皆为Cerebellum_Superior,属于小脑,这与前人已知的小脑是受精神分裂症影响最为严重的脑区之一相一致。

图4 L1范数下不同脑区中提取到的fMRI特征数Fig.4 Number of fMRI features extracted from different brain regions under L1 norm
由于不同脑区结构大小不同,不能简单地通过某一脑区提取到的体素数量来评价它对于精神分裂症的相关性大小。因此,本研究提出通过对某一脑区提取出的体素数量占该脑区总体素数量的百分比来表示该脑区受精神分裂症的影响程度大小。
表2仅显示了提取出的体素占所属脑区总体素百分比前十的脑区。这里有一点需要注意的是,不能简单地从百分比的大小来判定某一脑区与精神分裂症相关性的大小,只能表示该脑区受精神分裂症的影响程度更大。比如,顶下缘角回(左)13.97%大于中央前回(右)8.72%,不能说中央前回脑区与精神分裂症的相关性就不如顶下缘角回脑区的,只能从一定程度上说明顶下缘角回脑区受精神分裂症的影响程度要大于中央前回脑区的。这其中,中央前回、枕上回、顶下缘角回和角回早已经有研究学者证实与精神分裂症相关[19-20]。内侧和旁扣带脑回、后扣带回则是与记忆、行为与情感有关,这与精神分裂症在临床上显示的情感和行为等方面的障碍相一致。

表2 L1范数下提取的影像学特征Tab.2 Imaging features extracted under L1 norm
3 讨论
本研究的目的是整合分析与精神分裂症相关的fMRI数据和SNP 数据,运用SRVS 将选出的fMRI特征与已知的精神分裂症相关脑区进行对比验证,同时将选出的基因与之前普遍认同的精神分裂症的45个易感基因进行对比,结果证实了本研究提出的方法具有一定的可靠性。
在表1中,可以发现L0.5模型下提取的精神分裂症的易感基因的数目最多,这说明p=0.5 是此方法的最佳约束范数。进行权重分析时,在α1≤0.45 时,选取到的影像遗传学特征几乎均为SNP 特征,这是因为原始数据中fMRI数据量远远少于SNP 数据量,而权重的失衡,又进一步使得这一比例失调。由于在该范围权重下提取到的所有变量全部为SNP 数据,因此所选取的变量也可以看作是单变量分析的结果。
其中基因HTR2A、DAOA 不仅在α2= 0.20~0.65这10种权重下均被找到,还是在Lp范数在p取0、0.5、1 的3 种情况下的重叠基因,说明这两个基因对精神分裂症的研究有着不可忽视的重要意义,此前已经有研究表明这两个基因与精神分裂症有显著关联。
研究结果表明了SRVS 表现优异,不仅找出了包括DAOA、HTR2A、DISC1 在内的精神分裂症的易感基因,也找出了中央前回、枕上回、顶下缘角回、角回、内侧和旁扣带脑回、后扣带回等脑区,而这些脑区已被多名研究学者指出可能与精神分裂症相关。
把SRVS 应用于影像遗传学数据分析是一个有效可行的途径,为今后精神分裂症的影像遗传学研究提供了新的研究思路,推测也可将其用于确定抑郁症等复杂精神类疾病的易感基因。
