基于改进LeNet-5的车牌识别算法
2020-06-06张荣梅
张荣梅,张 琦,陈 彬
(河北经贸大学信息技术学院,石家庄 050061)
随着社会经济的不断发展,建设智能交通系统是城市交通管理的首要任务。车牌识别算法作为智能交通的重要部分,广泛应用于停车场出入口[1]、交通违章管理以及小区进出车辆管理等多个方面。
传统的车牌字符识别方法包括模板匹配[2]、特征统计[3]及机器学习[4]等方法,但是这些方法在进行字符识别时需要对大量车牌特征进行提取,识别效率低。而采用卷积神经网络实现车牌字符识别,能够自动提取车牌图像的特征,提高车牌识别的准确率。卷积神经网络在图像识别处理方面有着明显的优势,其中LeNet-5卷积神经网络算法已经广泛应用于手写数字识别、车牌识别等方面。
目前,已经有很多学者针对车牌字符识别问题提出了LeNet-5网络结构的改进策略。刘华春[5]通过增加LeNet-5网络的特征图数量以及模型输入大小来提高字符识别准确率。但是改进后的算法增加了训练参数数量,计算耗时高。赵志宏等[6]增加了C5层特征图数目,并将输出层神经元个数改为76个,同时识别76个车牌汉字字符与数字/字母字符,准确率为98.68%。但是该算法增加了训练参数数量,识别速度较慢。赵艳芹等[7]增加了卷积层的特征图数量,去掉了一层全连接层,识别准确率为99.96%。但是,改进后的网络结构增加了训练参数数量,运算效率低,同时该算法没有实现对于车牌汉字字符的识别检测。董峻妃等[8]去除了传统LeNet-5网络结构中的C5层,将输出层改为34个神经元,实现了车牌数字和字母的字符识别,准确率为99.96%。但是该算法同样没有实现车牌汉字字符的识别。
针对前人研究中的识别率低、运算效率低的缺点,提出了改进的Lenet-5卷积神经网络结构,以期提高车牌字符识别的准确率和运算效率。
1 LeNet-5卷积神经网络
LeNet-5网络结构是由Lecun等[9]在1998年提出的,但是由于当时计算机处理速度较慢,无法训练大样本,当时该模型并没有被广泛应用。而随着计算机技术的快速发展,该模型已经应用到了很多领域。
LeNet-5网络结构包含输入层、卷积层、池化层、输出层等7层网络结构。其中,C1和C3层为卷积层,通过大小为5×5的卷积核提取图像的局部特征得到特征图像;S2和S4层为池化层,通过将神经元与卷积层连接,对卷积层特征图降维采样;F6层是全连接层,借助双曲正切函数对权重向量与输入向量点积运算,与C5层的全连接;输出层包含10个神经元,分别代表0~9这10个数字,并采用径向基函数(radial basis function,RBF)网络连接,图1为LeNet-5网络的模型结构。

图1 LeNet-5模型结构Fig.1 LeNet-5 model structure
图1中,C1层为卷积层,包含6张28×28大小的特征图;S2层为池化层,包含6张14×14大小的特征图;C3层为卷积层,包含6张10×10大小的特征图;S4层为池化层,包含16张5×5大小的特征图;C5为卷积层,包含120张1×1大小的特征图;F6为全连接层,包含84个神经元;输出层包含10个神经元。
RBF的计算方式为
(1)
式(1)中:xj为全连接层中第j个神经元;yi为输出层第i个神经元;wij为全连接层第j个神经元与输出层第i个神经元之间的权值。
卷积层的作用是提取图像特征数据,通过窗口滑动进行卷积计算,即卷积核在图像中滑动,与图像局部数据卷积生成特征图;同时卷积层通过局部关联的方式进行连接,每一个神经元只对周围局部感知,最后综合局部的特征信息得到全局特征。卷积核遍历输入图像时,计算方式表示为
(2)
池化层的作用是对特征数据进行聚合,降低特征数据维度。由于数据经过卷积层后会产生多个特征平面,如果不进行降维处理会增加训练参数数量,降低运算效率。池化的方法包括最大池化和均值池化,计算可以表示为
(3)

为了使学习到的数据特征更加全局化,数据会经过多个卷积层和池化层,再输入到全连接层。全连接层会将池化层后的多组数据特征组合成一组信号数据输出,进行图片类别识别。
2 改进的LeNet-5网络结构
LeNet-5网络结构最早是针对手写数字识别产生的,其10个输出神经元分别对应着0~9这10类数字。由于中国车牌字符的种类比手写数字识别的种类多,需要对传统的LeNet-5的网络结构进行改进,使之适用于车牌字符种类进行识别。因此,提出了改进的LeNet-5网络结构,在以下几方面提出了改进。
(1)将输入图片归一化为32×16像素大小。由《中华人民共和国机动车牌》(GA 36—2018)[10]得知,中国大部分的车牌字符长度和宽度分别指定为90、45 mm,长宽比例为2:1。相比于LeNet-5网络结构的输入图像为32×32大小,将输入字符图像改进为32×16大小更加符合车牌字符的长宽比,能够避免归一化为32×32大小时而产生的信息丢失的情况。同时,减少输入图像的尺寸大小能够网络模型的训练参数,提高模型的运算速率。
(2)使用修正线性单元(the rectified linear unit,ReLU)激活函数。LeNet-5网络结构中,卷积层中激励函数为tanh函数。但是该函数存在函数饱和,梯度消失的问题。对卷积层中的激活函数进行了改进,选用ReLU函数作为激励函数,使激活函数导数的正数部分等于1,有利于解决梯度消失问题。
(3)取消C5层。由表1可知,LeNet-5网络中C5层的训练参数数量为48 120个,占整体训练数量的80%。将LeNet-5网络模型中的C5层去掉,改为F5全连接层,能够将模型总体的训练参数数量减少40 000个,提高了算法的运算效率。改进后的LeNet-5网络后三层S4、F5以及输出层就形成了单隐层反向传播(back propagation,BP)神经网络,可以用于分类输出。
(4)引用随机失活法(Dropout)。当模型的训练参数过多时,容易出现过拟合的现象。为了解决这一问题,Hinton等[11]在2012年提出Dropout方法,通过在迭代训练时根据概率值随机删除部分隐藏神经元来提高网络性能。通过Dropout去除部分神经元的连接,减少参数更新的个数,增加了算法中每个神经元的独立性,防止过拟合的情况出现。因此,在F5全连接层中加入了Dropout,并将失活概率设置为0.5,使其随机丢弃50%的神经元。
(5)将车牌字符汉字与数字/字母分开识别。针对中国大陆车牌字符的特点,汉字字符包含31类,字母/数字字符包含34类,总共包含65类。由于训练样本将汉字字符与数字/字母字符一起训练容易出现误分类的情况,将车牌字符的汉字和数字/字母分为两个模型识别。因此,汉字识别部分中,输出层的神经元包含31个;数字和字母的识别部分中,输出层的神经元包含34个。
改进后的LeNet-5网络结构包含6层网络,分别为1个输入层、2个卷积层、2个池化层、1个全连接层以及输出层,如图2所示。C1层是由5×5的卷积核与输入层卷积而来,生成6个28×12的特征图像;S2层是通过大小为2×2,步长为2的采样核对C1层中的特征图像进行采样得到;C3层中的特征图尺寸为10×2,与C1层一样,由16个大小为5×5的卷积核卷积得到;S4层中特征图尺寸为5×1,是由C3层与2×2的采样核降采样得到;F5为全连接层,包含160个神经单元且每一个单元与S4层全相连;最后由输出层由RBF函数连接。
同时,改进后的LeNet-5网络结构与传统LeNet-5网络结构的对比(包括每一层网络的尺寸以及训练参数的个数)如表1所示。

表1 网络结构对比Table 1 Model structure comparison

图2 改进后的LeNet-5模型结构Fig.2 Improved LeNet-5 model structure
3 车牌识别技术
对于拍摄得到的车牌图像,需要经过图像预处理、车牌定位、字符分割等一系列流程进行处理,最后将分割好的车牌字符图像输送到神经网络中进行识别。
步骤1图像预处理。由于拍摄的原始车牌图像存在通道数多、像素高、噪声影响等问题,首先对其预处理操作,增强原始车牌图像的对比度,消除图片的噪声。分别包括灰度化处理、高斯滤波、边缘检测、二值化等操作。
步骤2车牌定位。使用基于二值图像的形态学区域填充进行车牌定位[12],扫描车牌位置的区域确定车牌位置。由于车牌图像会呈现为矩形形状,因此选择相似的区域大致确定车牌位置。同时,二值化后的车牌图像字符与车牌背景间会呈现黑白分布的情况,因此车牌字符之间会出现黑白跳变的现象,根据跳变次数精确确定车牌区域。
步骤3字符分割。采用了垂直投影法对车牌字符进行分割[13]。通过对二值化的车牌图像垂直投影后,分析图像像素的分布情况,再根据车牌字符的特点,选择阈值切割车牌字符。
步骤4字符识别。将分割后的车牌字符图像输入到改进后的LeNet-5网络结构中进行识别。考虑到同时对汉字、数字和字母进行识别准确率低,本文将汉字与数字/字母分来识别。
4 实验
4.1 实验数据
由于使用的数据集需要全国各地车辆图片,如果全部进行拍照采集,难度非常大。因此将训练数据分为手机拍摄和互联网收集两部分。第一部分是通过手机拍摄河北部分地区100张高清车牌图像,每张图像的分辨率为4 608×3 456;第二部分是通过百度搜索车牌图片收集600张中国各省份的车牌图像。采集到的所有照片包括受自然光照影响的、倾斜的等不同场景。图3为采集的部分代表性的车牌图片。

图3 部分车牌图片Fig.3 Partial license plate picture
为了增加数据集样本数量,将采集到的车牌图像进行了拉伸、扭曲、旋转处理,然后将处理后的车牌图像进行图像预处理、车牌定位和字符分割,整理得到7 877张车牌字符图像作为改进后网络的训练样本,每个字符图像的像素均为32×16。其中训练集包括7 517张图片,4 285张图片为数字和字母,3 232张图片为汉字;测试集包括360张图片,200张图片为数字和字母,160张图片为汉字。图4为车牌字符分割后的部分训练样本。

图4 部分训练样本Fig.4 Partial training sample
4.2 实验结果
实验在Windows10 64位平台环境上运行,基本配置为Intel Core i5- 4590四核处理器、8 GB DDR3内存、NVIDIA GTX1050 Ti独立显卡。同时使用TensorFlow开源框架验证改进后的LeNet-5网络的识别效果。
为了证明改进后的LeNet-5网络结构在车牌识别中的优越性,以字符识别准确率和时间效率作为模型的评估指标。字符识别的准确率包括汉字识别和数字/字母识别两种类别,时间效率则计算平均每张图片的识别时间,表2为实验结果对比。
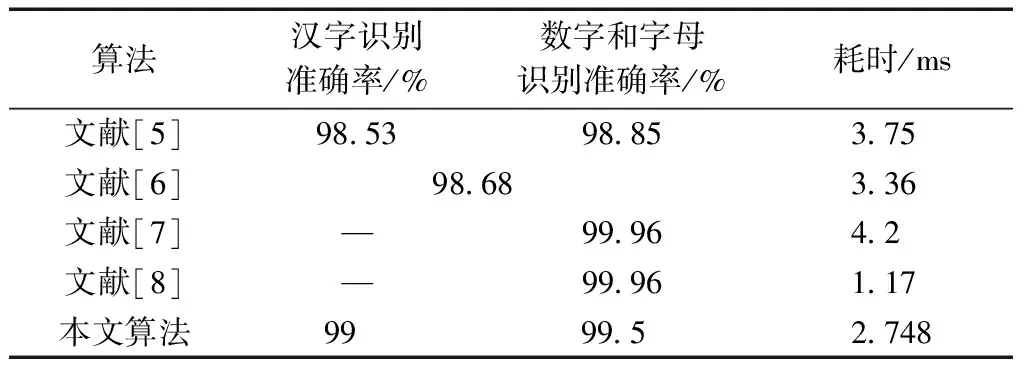
表2 实验结果对比Table 2 Comparison of experimental results
由表2可知,文献[5]是将汉字字符与数字/字母字符分开识别;文献[6]同时识别所有车牌字符;文献[7]和文献[8]只实现了车牌数字与字母的识别,没有实现车牌汉字识别。
通过表2可知,本文算法对于车牌汉字字符的识别率为99%,数字字符和字母字符的识别率为99.5%,同时算法的运行效率达到了单张图片识别时间为2.748 ms。相较于文献[6],本文算法提高了车牌字符识别的准确率;相较于文献[7]、文献[8],本文算法实现了车牌汉字、数字和字母所有字符的识别;相较于文献[5],本文算法提高了车牌字符识别的准确率,同时提高了算法运算效率。
5 结论
由于当前基于LeNet-5网络结构的车牌识别算法存在识别率低、运算时间长的缺点,提出了改进的LeNet-5结构车牌识别算法。对传统的LeNet-5结构进行了改进与简化,修改了网络结构中输入层大小以及输出层神经元数目,同时去掉了C5层,使之适用于车牌字符识别。通过实验表明,改进后的网络模型对于车牌识别的准确率更高,达到了99.5%。同时,改进后的模型提高了运算效率,达到了每字符2.748 ms。
但是在实际应用中,本文算法还存在一些不足:该算法需要将车牌字符分割后,分别对车牌的汉字以及数字/字母进行识别输出,不能直接显示整张车牌的识别结果。在之后的研究中需要进一步优化网络结构,提高车牌字符的识别效率。