低资源场景下印尼语-汉语机器翻译模型对比分析研究
2020-06-03马骏腾肖莉娴王连喜
李 霞 ,马骏腾,肖莉娴,王连喜
(1.广东外语外贸大学 广州市非通用语种智能处理重点实验室,广东 广州 510006;2.广东外语外贸大学 信息科学与技术学院,广东 广州 510006;3.广东外语外贸大学 东方语言文化学院,广东 广州 510006)
1 研究背景
机器翻译(machine translation,MT)是将文本从一种语言自动转换为另一种语言的技术,是自然语言处理的重要研究领域之一。近几十年来,机器翻译技术不断发展,从传统的统计机器翻译方法[1-3]到基于端到端的神经机器翻译方法[4-7],翻译模型和翻译效果都取得了显著提升。
经典的神经机器翻译模型主要基于编码器-解码器结构,是一种基于递归神经网络的变体,常用的编码器和解码器网络单元为LSTM(long short term memory,LSTM)[8]或GRU(gated recurrent unit,GRU)[9],该类模型的优点是能有效捕捉句子单词的序列信息,较好地处理长序列时梯度消失问题,但它存在不能并行对句子进行编码的缺点。为此,J.Gehring等[10]提出一种完全基于卷积神经网络[11]的编码器-解码器结构,使得计算可以并行化,并通过叠加多层来表达较大窗口内的上下文信息,取得了较好的翻译性能。2017年A.Vaswani等[7]提出了使用Transformer结构来构建神经机器翻译模型,Transformer 抛 弃 了 传 统的RNN(recurrent neural network)结构,提出和使用自注意力机制,使得它更关注句子本身,从而能够抽取出更多的信息,进而取得了很好的性能,后续的工作中也陆续出现基于Transformer结构的不同改进工作[12-13]。
近年来,机器翻译工作也聚焦于融合视觉、听觉等信息的多模态机器翻译[14-15],通过结合图片中的语义信息来辅助文本的语义消歧,进而提升机器翻译的准确率。与此同时,面向资源稀缺的低资源语言机器翻译研究近年来也成为研究热点,如面向尼泊尔语与僧伽罗语[16]、希伯来语[17]、印尼语、菲律宾语等资源较少的机器翻译研究。在面向低资源语言的机器翻译场景中,由于训练语料较少,且源端和目标端的语言形态、句子结构差异较大,低资源语言机器翻译也是近年来机器翻译研究的难点之一。
为了解决低资源训练语料少、模型训练难等问题,研究人员提出迁移学习和元学习等技术来实现面向低资源语言的机器翻译模型和方法。如B.Zoph等[18]提出使用迁移学习的思想用于低资源语言机器翻译研究中,其思想是通过在语料丰富的语言对上训练模型后,再使用低资源语言的数据做微调,从而获得在低资源语言上的翻译模型。Gu J.T.等[19]使用元学习的方法来解决低资源语言翻译困难的问题。R.Sennrich等[20]则提出使用易获得的目标语言的大量单语语料,通过现有的翻译工具或者已训练好的机器翻译模型对其进行反向翻译,从而构造伪平行句对。近几年由于计算能力的提升,研究人员在面向低资源语言的机器翻译研究中从迁移技术的使用[21]与如何构造更多更好的平行数据[22-23]角度不断开展低资源语言的机器翻译研究。
虽然神经机器翻译模型相比传统基于统计的翻译模型取得了更好的效果,但是它需要足够规模的训练语料才能更好地调参并获得较好的翻译效果。同时,目标语言与源语言形态的差异、语法结构的差异也会影响模型的性能。例如,属于同一个语系的英语和法语,与属于不同语系的英语和汉语的机器翻译相比,即使在训练数据完全相同的情况下其结果也会有所差异。
本文主要关注主流神经机器翻译模型在低资源语言或在训练数据量少的场景下的表现情况。课题组以印尼语-汉语为语言翻译对象,探究面向资源较为稀缺的低资源语言(印尼语)和在训练数据量较少情况下(低资源场景下),当前主流神经机器翻译模型的翻译表现。课题组尝试从已有的“英语-汉语”数据集构造相同规模的“印尼语-汉语”伪平行数据,使它们具有相同目标端的中文句子,并进行训练和测试,将得到的结果进行对比和分析,探究在相同的低资源场景下,从英语到汉语和从印尼语到汉语的翻译效果。本文工作的主要贡献如下:
1)从已有的“英语-汉语”数据集拓展并构建“印尼语-汉语”伪平行数据集用于模型训练;
2)探索和分析了基于LSTM和基于Transformer两种端到端翻译模型在英语-汉语和印尼语-汉语两个不同语言对上的翻译效果分析;
3)给出了融合注意力机制的基于LSTM和基于Transformer端到端神经机器翻译模型在低资源场景下的适应性分析。
2 神经机器翻译模型NMT
经典神经机器翻译模型(neural machine translation,NMT)采用基于编码和解码的序列到序列翻译模型框架,输入端为源语言单词序列X=(x1,x2,…,xM),输出端为目标语言单词序列Y=(y1,y2,…,yN),NMT模型希望学习得到X翻译为Y的概率P=(Y|X)最大的模型,从而学习得到训练集数据的条件概率分布。本文使用的NMT模型分别为融入注意力机制的基于LSTM 机器翻译模型和基于Transformer的神经机器翻译模型,分别以Att-LSTM-based NMT模型和Transformer-based NMT模型来命名表示该两个模型。
2.1 融入注意力机制的LSTM-based端到端翻译模型
2.1.1 编码端
在LSTM-based端到端神经机器翻译模型中,编码器使用双向LSTM 对源语言句子进行编码,其中前向、反向LSTM的输出序列分别为和其计算方法如式(1)~(2)所示:

式(1)(2)中:Wx为源语言单词xi转换为词向量的词向量查找矩阵;fenc为LSTM 计算过程的函数。
最终编码器在每个时间步上的输出是每个单词前向和后向隐含向量的拼接,即编码端源语言输入序列经过编码得到的输出为h=(h1,h2,…,hN)。
2.1.2 解码端
注意力机制旨在更好地得到目标单词与源语言句子中单词的对齐关系。参考M.T.Luong等[6]的工作,本文在模型的解码端使用LSTM单元,并融合注意力机制,计算方法如下:
首先,计算解码器t时刻的隐含状态st和编码器的每个输出隐含状态hi的对齐信息et,i,如式(3)所示,其中st-1为解码器的上一个隐含状态,Wa为参数矩阵。
然后,通过Softmax 函数计算得到解码器t时刻隐含状态所对应编码器不同隐含状态hi的权重at,i,如式(4)所示。
最后,进行加权求和得到解码端t时刻隐含状态在编码器端的上下文向量ct,如式(5)所示。最后,如式(6)所示,解码器t时刻的隐含状态st的结果由3部分计算得到:解码器的上一个隐含状态st-1;解码器t-1时刻预测输出的目标单词(模型训练时取与xt-1对应的单词yt-1);t时刻解码器隐含状态的上下文向量ct,其中Wy为目标语言单词yt-1转换为目标语言单词的词向量查找矩阵,fdec则表示LSTM 计算过程的函数。
计算式如(3)~(6)所示:

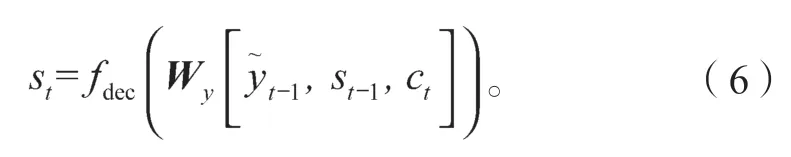
2.2 基于Transformer端到端翻译模型
2.2.1 编码端
Transformer的内部结构包含一个自注意力层(self-attention layer)和前馈神经网络层(feed-forward network layer,FFN),编码器和解码器都可以通过堆叠层数来加深网络的深度,提高模型的效果。每个编码器层只包含自注意力层和FFN层,在自注意力层中,每个输入的向量会被3个不同的权重矩阵WQ,WK,WV转换成3个不同的向量,其中Q为解码器的上一层输出,K和V为编码器的输出,分别为Q(Query)、K(Key)和V(Value)。自注意力机制使用缩放点积(scaled dot-product)作为相似度计算函数,如式(7)所示,
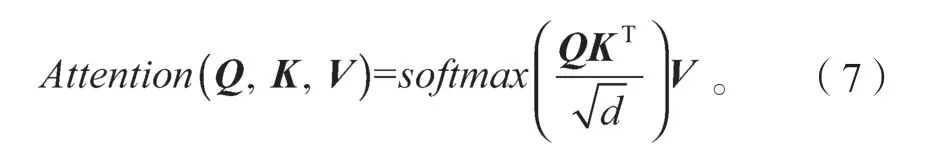
式中d为Q、K、V的维度。
由于Transformer与RNN 不同,它并不能捕捉句子的序列信息,因此在输入的词向量中加入了位置编码给每个单词提供位置信息。为了使自注意力层有更好的表现,A.Vaswani等[7]还将输入的Q、K、V投影到多个子空间中,即多头机制(Multi-Head),它将每个“头”得到的输出拼接后,输入一个全连接层,如式(8)所示,

2.2.2 解码端
解码器层在自注意力层和FFN层之间多了一个编码器-解码器注意力层(encoder-decoder layer),接收来自编码器的最终输入。它采用了和2.2.1 节描述的编码端多头注意力机制一致的计算方法。
编码器和解码器中的每个子层的输出都使用了残差连接,防止网络加深时出现退化的梯度消散问题。并使用了层正则化[23],使得正则化后的数据尽可能地保持原始表达能力,更适应模型的训练。
3 实验
3.1 实验数据
本文所用IWSLT 2015(https://sites.google.com/ site/iwsltevaluation2015/mt-track)机器翻译评测任务所提供的评测数据集,该数据收集的领域是TED(https://www.ted.com)中的演讲内容。为了对比神经机器翻译模型在不同语种上的翻译效果,保证数据的一致性,课题组选取IWSLT 2015 英语-汉语数据集作为基础并进行扩展,得到印尼语-汉语伪平行数据集。扩展的方法是使用Google Translation API(https://translate.google.cn/,翻译时间为2020-01)将训练集中的英语句子自动翻译为相应的印尼语,选择用英语翻译的原因是考虑到印尼语与英语都是使用26个英文字母所构成的单词,语言形态相似,得到的数据可能质量更好。实验所采用的校验集和测试集则由印尼语专业教师进行人工翻译和标注,校验集用于翻译模型的调参,测试集用于模型的结果评测。详细数据集信息如表1所示。

表1 实验数据细节(单位:句对)Table1 Details of experimental data (unit: sentence pair)
3.2 实验设置
3.2.1 数据预处理
在数据预处理阶段,对于英语语言使用Moses[24]统计机器翻译库中的预处理脚本对语言进行预处理操作,其中包括分词、标点规范化、字母大小写处理(truecase)等。对于印尼语课题组则直接将所有字母小写并进行分词,对于中文分词则采用的是Jieba(https://github.com/fxsjy/jieba)分词工具。实验中,课题组控制训练集的句子长度在1~50个词之间,并且将源语言及目标语言的词汇表大小设定为50 000个。在训练过程中使用校验集对模型进行调参和模型选择,整个实验采用BLEU[25]作为评价指标和结果汇总。实验所使用的硬件设备为1 块GeForce RTX 2080GPU显卡。
3.2.2 基于LSTM的端到端模型实验设置
编码器端使用双向LSTM 作为编码单元,隐含状态向量的维度为512维,源语言和目标语言的词向量维度为512维。解码器端使用单向LSTM,隐含状态向量的维度为512维。模型采用Adam 优化器[26],初始学习率为0.001。batch型为句子,batch size 设置为64,dropout 概率设置为0.3。在训练时每2 000个训练迭代在校验集上测试,如果连续4次模型在校验集上的困惑度值(perplexity)没有下降,则执行一次学习率衰减,衰减为原来的二分之一。实验中,如果这种情况出现8次,则使用早期停止策略(early stop)结束训练,beam search的大小设置为5。
3.2.3 基于Transformer的端到端模型实验设置
文中Transformer模型使用OpenNMT-py[27]开源框架进行实验,其中编码器与解码器均使用6层8个头,其中隐含状态向量和词向量维度均为512维。词向量加入了位置编码,FFN 维度设置为2 048 维。优化器选用Adam,初始学习率为0.1。实验使用Noam学习率下降方案[4],其中β1=0.9,β2=0.998,warm up steps为16 000。batch的类型为单词,batch size 设置为4 098,训练200 000个training iteration,选择在校验集上表现最好的模型。dropout 概率设置为0.3,beam search 大小设置为5。
3.3 实验结果与分析
使用所给出的实验设置和评价指标,融入注意力机制LSTM-based的神经机器翻译模型(Att-LSTMbased NMT)和基于Transformer的神经机器翻译模型(Transformer-based NMT)的详细实验结果如表2所示。

表2 不同语言对的实验结果Table2 Experimental results of different models with different language pairs
由表2可知,在英语-汉语和印尼语-汉语两个语言翻译对中,Att-LSTM-based NMT模型均比Transformer-based NMT模型略好,其中Att-LSTMbased NMT模型在英语-汉语语言对上的BLEU值为15.35,在印尼语-汉语语言对上的BLEU值为13.92,相比而言,在印尼语-汉语语言对上的结果要比在英语-汉语语言对上的翻译结果低1.43个BLEU值,这表明模型在低资源语言以及针对印尼语-汉语这种语言形态差异较大的语言对上的翻译结果相对较低。
实验结果还表明,Transformer-based NMT模型在两个相同平行语言对上翻译的结果,均略低于Att-LSTM-based NMT模型。课题组分析,可能的原因是在低资源的情景中(数据集的数量较少),Transformer-based NMT模型在训练数据不够的情况下,翻译效果可能不如RNN结构的机器翻译,因为Transformer的网络深度更深,在这种量级数据上容易过拟合。同时,Transformer-based NMT 在参数相同的情况下,运行出来的结果相对更为稳定,Transformer-based NMT模型在英语-汉语和印尼语-汉语的翻译BLEU值标准方差分别为0.14和0.15,相比于Att-LSTM-based NMT模型的0.37和0.73 更为稳定。
3.4 模型的适应性分析
本研究针对印尼语-汉语低资源语言对,以及翻译训练数据较小的情况下,Att-LSTM-based NMT模型和Transformer-based NMT模型的翻译适应性进行分析。课题组分别分析了两个模型在不同语言对上在不同句子长度时的翻译效果,结果如图1所示。其中图1a为句子长度不同时两个模型在英语-汉语对上的翻译结果对比分析,图1b为句子长度不同时两个模型在印尼语-汉语对上的翻译结果对比分析。

图1 模型在不同长度句子上的BLEU值比较分析Fig.1 A comparative analysis of two models with BLEU metrics with different length of sentences
如图1所示,在大多情况下,Att-LSTM-based NMT模型结果相对更好,且两个模型在长度为30~50时,翻译的结果最好。但在句子长度为30~40时,Transformer-based NMT模型的翻译效果都要稍好于Att-LSTM-based NMT模型。同时课题组发现,当句子长度越长,Transformer-based NMT模型的性能下降最大,这可能是因为Transformer 尽管通过加入位置编码来解决单词位置信息的问题,但是其仍然在建立更长距离依赖方面效果较差,这与位置编码的方式选择有一定的关系。
同时,课题组还对Att-LSTM-based NMT模型和Transformer-based NMT模型的训练时间进行了对比分析,两个模型以3.2.2 节和3.2.3 节参数设置情况下的训练时间对比如表3所示。

表3 模型的训练时间对比Table3 Comparison of training time of the models
由表3可得,Transformer-based NMT模型所需要的平均训练时长要比Att-LSTM-based NMT模型更长。以实验结果来看,在3.2.2和3.2.3 节使用的参数和相同硬件情况下,Transformer-based NMT模型训练所用时间为26.8 h,而Att-LSTM-based NMT模型训练时间为16.5 h,低于Transformer-based NMT模型训练时间。这也验证了Transformer-based NMT模型更为复杂,需要更多的大规模训练数据进行调参才能达到较好的效果。
3.5 案例分析
本研究还对两个模型的翻译结果进行案例分析,比较两种NMT 翻译的效果。课题组选取了两个印尼语-汉语的翻译结果进行对比分析,如表4和表5所示。所选取的两个印尼语句子长度都在30个单词以上,选择了两种模型表现最好的句子长度的情景下结果。

表4 案例分析(1)Table4 Case study (1)
以表4所示的案例为例,Att-LSTM-based NMT模型结果中,在句子的后半部分出现了单词重复的情况,如“你可以用你的电池电池充电”,而Transformer-based NMT模型的翻译结果更加符合源句子真实翻译结果。而如表5所示,在翻译的结果中,同样出现了“这发生在我的工作之前,在我的工作之前”这种重复翻译的情况,并且相比而言,Transformer-based NMT模型的翻译效果更好。这表明,即使在小数据集的训练场景下,Transformerbased NMT模型依然可以取得较好的翻译稳定性。
4 结语
课题组探究了在低资源语言和数据量较小的场景下,基于Transformer的神经机器翻译模型和基于LSTM 神经机器翻译模型的翻译结果和适应性对比分析。实验中课题组发现,在低资源的情景下,融入注意力机制的基于LSTM的神经机器翻译模型无论是翻译效果或者训练时间上,都略好于Transformer,这可能是因为基于Transformer的神经机器翻译模型更深,参数量大,需要在更大规模的数据中才能凸显其优势,并且Transformer 对超参数的设定更加敏感,调参所需代价较大,因此在低资源场景下使用RNN结构模型的性价比会更高。同时在句子长度中等的情况下,基于Transformer的NMT 翻译效果会略胜一筹。另外,总体而言,尽管在小数据量情况下,基于Transformer 神经机器翻译模型的稳定性更好。
