融合深度神经网络与统计学习的印地语词性标注方法研究
2020-06-03王连喜丁曾强邓致妍
王连喜 ,钟 准,丁曾强,邓致妍 ,李 霞
(1.广东外语外贸大学 广州市非通用语种智能处理重点实验室,广东 广州 510006;2.广东外语外贸大学 信息科学与技术学院,广东 广州 510006;3.广东外语外贸大学 日语语言文化学院,广东 广州 510006)
0 引言
词性标注(part-of-speech tagging),又称词类标注,是指以上下文关系为前提,给句子中的每个词标注出合理词性的过程[1]。词性标注是自然语言处理任务的重要预处理工作之一,也是信息抽取、词法分析、语法分析、语义分析等研究的基础。词性标注的准确率将直接影响文本检索、文本分类、机器翻译等研究的效果。词性标注本身是一个难度比较大的问题,因为很多词语通常有多种词性,但是在考虑词语所处上下文语境的情况下,这些词语的词性是唯一的,可以明确附以名词、动词、形容词等具体词性标签。
印地语是印欧语系-印度语族下的一种语言,是南亚次大陆上使用人口最多的语言,也是印度的官方语言之一。以使用人口数量和使用国家数量来计算,印地语是世界排名第8的语言,但由于印度曾被殖民的缘故,印地语的使用地位比英语要低得多,并未成为众多使用人口的第一语言。因此,印地语与其他低资源语言一样,存在标注语料稀缺、标注难度及代价较高、规范性较差等问题,导致大规模的标注资源不易获取。
许多研究表明[1-2],目前对于通用语种的词性标注方法已较为成熟,但由于资源稀缺问题和语言的特殊性,无法直接应用于印地语词性标注上。印地语词性标注目前面临如下挑战:一是印地语中有大量借词(其来源包括梵语、英语、乌尔都语、阿拉伯语、波斯语、土耳其语、葡萄牙语及普什图语),导致语料中有大量外来词;二是印地语承袭了古代梵文多变性特点,词语的格和词性比较复杂,变化灵活。
1 相关研究概述
针对印地语词性标注问题,近年来科研工作者们已提出了多种相关的词性标注方法,如基于规则的方法、基于HMM(hidden markov model)的词性标注方法等[3-7]。如H.Agarwal等[8]利用条件随机场对印地语词性进行标注训练,并对语料库中每个单词的词根和可能的词性进行了标记。A.Dalal等[9]以最大熵马尔可夫模型同时使用多个特征来捕获与序列标记任务相关的词语词性,并提出了一个基于语言标签和组块分析统计的印地语词性标注方法。隐马尔可夫模型、最大熵模型和条件随机场等统计模型的依赖关系学习能力强,但是需要定义大量特征模板,否则容易陷入局部最优解。N.Garg等[10]提出了基于规则的印地语词性标注方法,并对包含了30个印地语标准词性标签的语料进行了实验,结果显示,其精度达了87.55%。S.Asopa等[11]利用规则与组块相结合的方法进行词性标注,在有限语料的情况下提高了标注效果。D.Modi等[12]结合29个词性标签和多个词法特征规则,提出了基于规则的印地语词性标注方法,该方法也取得了一定的效果。基于规则的方法针对特定领域的准确率往往较高,但是规则制定较难且不能穷尽,所以其泛化效果通常会受到限制。
自深度神经网络模型流行以来,一些学者也在尝试利用深度学习来学习长距离信息之间的上下文信息,并以此解决词性标注、命名实体识别等序列标注问题。如J.Yousif等[13]提出了基于多层感知器神经网络的印地语词性标注,并利用反向传播学习算法对标注结果进行纠错。R.Narayan等[14]采用人工神经网络对印地语词性标注进行了研究,实验准确率高达91.30%,效果明显比其他印地语词性标注方法好。此外,N.Mishra等[15]提出了一种混合的印地语词性标注方法,该方法首先借助WordNet 字典标记印地语单词,然后采用基于规则的方法为未标记的单词分配标签标记,最后利用HMM模型来消除歧义。D.Modi等[16]融合基于统计和基于规则的方法,在一个小规模的标注语料上取得了88.15%的平均准确率。
总体上看,印地语自然语言处理技术还不够成熟,国内外开展印地语词性标注方法研究的工作相对较少,并且目前基于统计的词性标注方法对于缺乏大规模人工标注语料的印地语词性标注而言,还不能取得明显的效果。基于此,本课题组考虑将统计学习模型和深度神经网络模型进行结合,通过深度学习模型对待标注序列的上下文信息进行捕获,然后采用条件随机场(conditional random field,CRF)对整个待标注序列的局部特征进行信息线性加权,从而更好地识别序列信息前后的依赖关系。为能更好地捕获上下文信息,并使得输出序列符合一些基本依赖关系的约束,本文研究一种融合深度神经网络和统计学习的印地语词性标注模型。
2 印地语词性标注
词性标注是自然语言处理领域的一种典型序列标注任务,其本质就是对线性序列中每个元素根据上下文内容进行分类的问题。词性标注的过程,就是给定一个一维线性输入序列X={x1,x2,x3, …,xn},通过利用规则、统计模型或深度学习模型,对该序列中的每个元素xi打上给定标签集合中的某个标签yi,从而得到输入序列的相应标签序列Y={y1,y2,y3, …,yn}。例如,给出一个印地语句子:通过词性标注方法进行标注后,可以得到如下的相应标注结果:
在处理序列标注任务时,目前学术界较为流行的做法,是将统计模型与深度学习模型相结合[17-18],这样,一方面可以学习待标注序列中的依赖约束关系,另一方面也可以考虑到长距离的上下文关系,从而很好地结合两种模型的优点。
2.1 LSTM和BiLSTM
虽然循环神经网络(recurrent neural network,RNN)常被用于解决序列标注问题,但是该模型存在“长距离依赖”问题,且容易在网络训练过程中出现梯度消失和梯度爆炸问题。为了解决长序列信息依赖问题,S.Hochreiter等[19]提出了长短期记忆网络(long short-term memory,LSTM)。LSTM 通过输入门、遗忘门和输出门3种类型的门结构来控制不同时刻的状态和输出,通过门控控制单元的状态信息控制之前信息和当前信息的记忆和遗忘程度,所以该模型可以选择性地保存序列信息。但是单向的LSTM模型(如图1)只能获取序列的上文信息,无法获取序列的下文信息,且往往会更偏向于最近的输入表示信息。
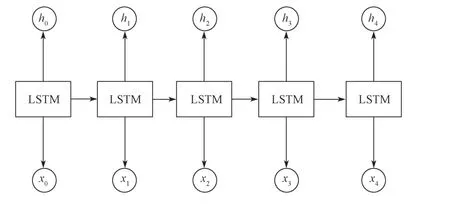
图1 LSTM模型的结构Fig.1 Structure of LSTM model
为解决LSTM 无法同时从正向和反向获取序列信息的问题,C.Dyer等[20]提出了双向长短期记忆模型BiLSTM,其网络结构如图2所示。BiLSTM模型可以从正向和反向两个方向同时对序列进行建模,不仅可以保存上文信息,还可以考虑到下文信息。
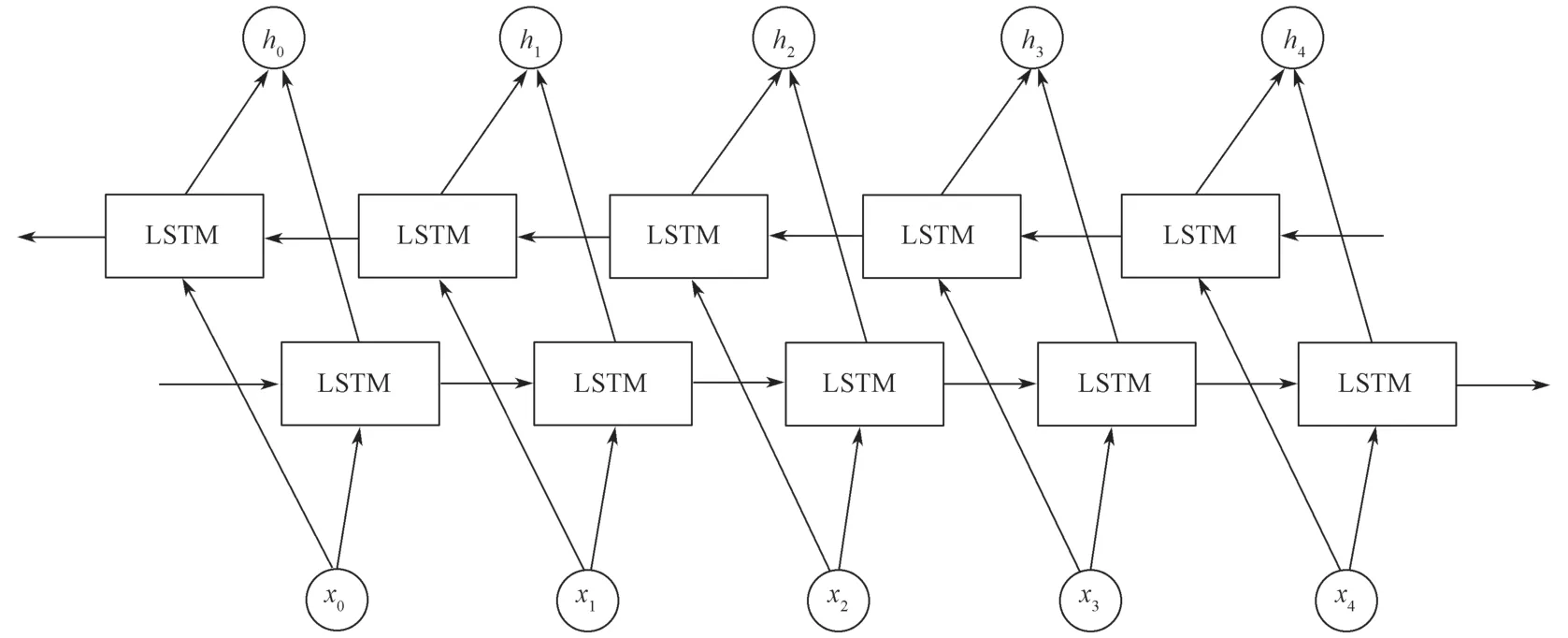
图2 BiLSTM模型的结构Fig.2 Structure of BiLSTM model
2.2 CRF
条件随机场[21](CRF)是一种经典的基于无向图的条件概率模型,也常被用于序列标注问题。CRF模型既具有判别式模型的优点,又具有生成式模型考虑到的上下文标注间的转移概率,以序列化形式进行全局参数优化和解码的特点,其结合了隐马尔可夫模型的优点和最大熵模型的优点,解决了其他判别式模型难以避免的标注偏置问题,是传统统计序列标注的强力模型。
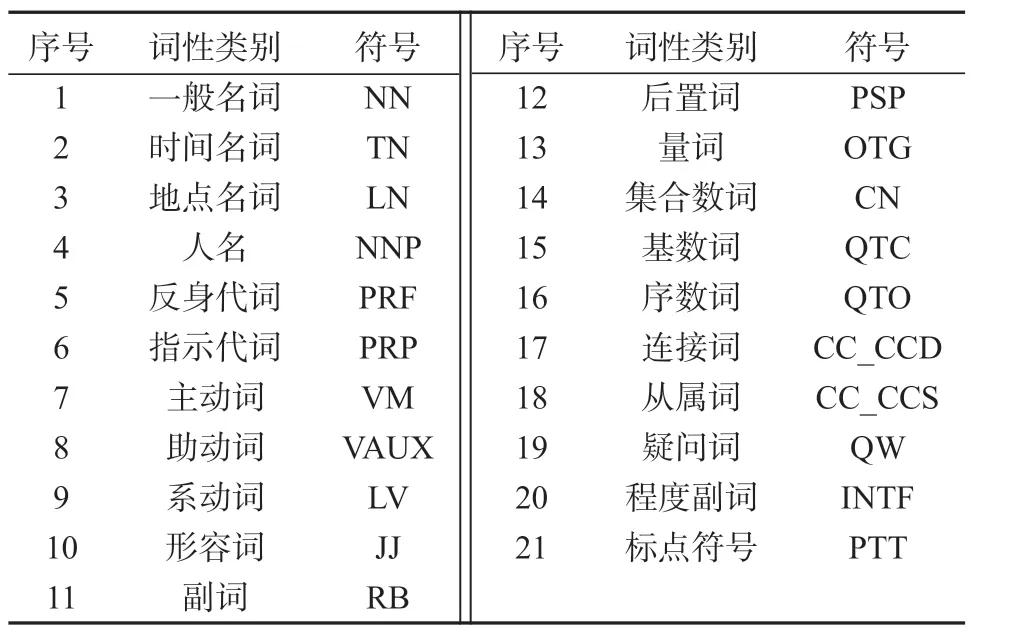
表1 印地语词性标注体系Table1 Part-of-speech tagging system of Hindi
假设随机变量序列X={x1,x2,x3,…,xn}和Y={y1,y2,y3,…,yn}均为线性链表示的随机变量序列,在给定X的情况下,Y的条件概率分布P(Y|X)构成条件随机场,即满足马尔可夫性:
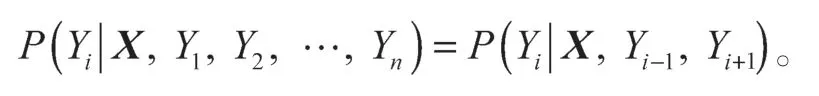
在词性标注问题中,X表示观测序列,Y表示相应的标注序列或状态序列。
对于线性链CRF,给定一个输入序列(观测序列)X,通过一组特征函数集合来对序列X每个元素的可能标签序列组合Y的得分进行计算,计算公式为
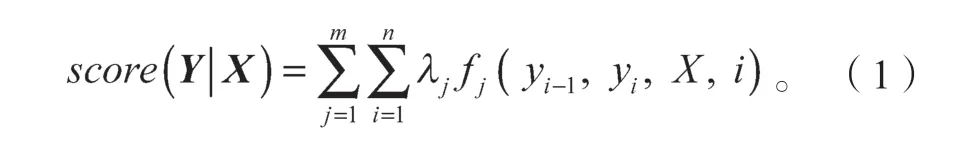
式(1)中:xi为序列X中的第i个元素;
yi为第i个元素的标签;
yi-1为第i-1个元素的标签;
fj为特征函数;
λj为特征权重。
在得到每个可能的标签序列的分数之后,可以通过幂运算和softmax 对序列组合得分进行指数和归一化处理,从而获得标注序列的概率值。归一化方法如式(2)所示。
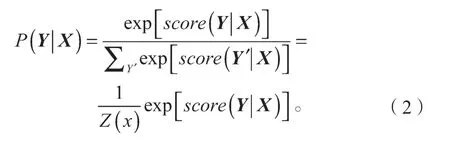
2.3 基于深度学习和CRF的词性标注方法
由前面的描述可知,深度神经网络模型和CRF在序列标注任务中各有优缺点:深度神经网络模型能够捕获待标注序列的上下文信息,但不能有效识别信息之间的依赖关系;CRF 不考虑长远的上下文信息,但更多考虑整个序列局部特征的线性加权信息,对具有依赖关系的信息识别效果较好。
为了能更好地捕获待标注序列的上下文信息和输出序列的依赖关系约束,本文提出基于深度学习和CRF的印地语词性标注方法,首先通过深度神经网络模型(如CNN、LSTM、BiLSTM等)训练得到输入序列的信息特征,然后利用CRF 对上一步的输出信息添加一些约束来保证词性标签预测的合理性。
假设X={x1,x2,x3,…,xn}表示一个印地语句子,其中xi为句子X的第i个词,Y={y1,y2,y3,…,yn}为句子X的词性标注序列。基于深度学习和CRF的印地语词性标注模型主要包括词表示层、序列表示层和CRF 推理层。
1)词表示层。根据输入数据X进行数据预处理,并利用word2vec 方法对大规模语料进行训练生成具有语义信息的低维度稠密实数词向量。
2)序列表示层。将词向量传入到深度神经网络模型中进行训练,得到输入序列的信息特征。
3)CRF 推理层。利用深度神经网络模型的输出状态和当前的转移概率矩阵作为CRF模型的参数,最终获得标签序列Y的概率。
3 实验及分析
3.1 实验数据
词性标注方法的效果通常受如下因素影响:一是受语料规模和语料所属领域范围的影响,语料规模越大,领域范围越集中,词性标注效果越好;二是受词性标记集合大小的影响,词性标记集合的粒度越小,标注效果随之降低;三是受训练语料规模的影响,标注的训练语料规模越大,学习算法的学习效果越好,越能得到好的结果。由于目前印地语缺乏公开的词性标注语料,且相同模型对于不同词性标记集合的标注效果也会出现较大差异,因此结合印地语语法特点及后续印地语自然语言处理任务要求,项目组邀请印地语专家设计了表1所示印地语词性标注体系。
由表1可知,该体系包含21种词性类别构成的词性标记集合,且具有相同词性的细粒度标记类别,如名词包含了一般名词、时间名词、地点名词、人名4种,动词包含了主动词、助动词、系动词3种。
同时,邀请了7名印地语专业人员组成词汇标注小组,对来自印地语的新闻文本进行人工标注。在人工标注时,每个句子均是由多个印地语专业人员达成标注一致性的结果,最终形成5 950条标注句子集,合计114 127个单词。
3.2 实验方案
本实验中,将词性标注集的90%作为训练集(共5 355个句子,108 756个单词),10%作为测试集(共595个句子,5 371个单词)。训练集不仅用于训练词性标注模型,还用于训练词向量矩阵和字符向量矩阵。
为了评估词性标注方法的性能,使用准确率Accuracy作为本实验的效果评估指标,计算公式为

3.3 模型参数设置与评估方法
模型实现使用Python 语言及TensorFlow 框架。词性标注模型经过多次实验调整后,选择最佳结果设置了如表2所示的超参数。在实验的正则化方法中,Dropout 通常会随机删除一些神经元,以防止模型出现过度拟合的情况。

表2 模型超参数Table2 Hyperparameters of the model
3.4 实验结果及分析
为了对比不同方法在印地语词性标注任务中的效果,本文采用相同的标注语料在TnT[22]、HMM[5]、CRF、BiLSTM、BiLSTM+LAN[23]和CNN+LSTM+CRF等模型上进行实验。其中,TnT、HMM、CRF为基于统计学习的方法,BiLSTM和BiLSTM+LAN为基于深度学习的方法,但是BiLSTM+LAN是一种融合标签信息的(label attention network)深度学习方法,主要是将标签进行词嵌入表示,然后将其传入BiLSTM 进行训练,这样就能够捕捉到更长的标签依赖关系。后面几种为深度神经网络与统计学习模型相结合的方法。
由图3所示的多个模型的词性标注结果可以看出,CRF是基于统计学习模型中效果最好的,与HMM 方法相比,其性能约提高了22%。BiLSTM模型的效果较CRF和BiLSTM+LAN 方法的差,而CNN+LSTM+CRF 能够得到更好的效果。
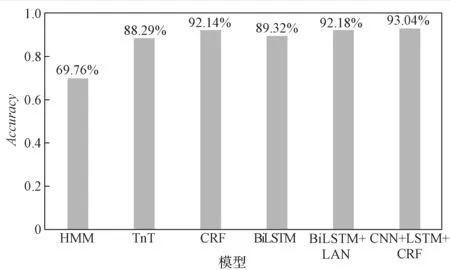
图3 不同模型的词性标注结果Fig.3 Tagging result comparation of different models
整体上看,在深度学习模型基础上加上CRF,其效果并未比深度学习模型有很大的提升,一个可能的原因是神经网络编码器已有很强序列信息编码能力,在此基础上加上CRF 并未引入更多有效信息。
虽然提出的方法能够取得较好的效果,但相较于其他语种的词性标注结果尚有一定的提升空间。其原因在于,当前实验的标注语料规模还不够大,没有充分发挥出深度神经网络在大规模语料中的学习优势。
4 结语
本文提出了一种融合深度神经网络和统计学习的印地语词性标注方法。首先,通过词嵌入方法对印地语单词进行词向量表示;然后,将词向量作为深度神经网络模型的输入进行训练,进而获取单词的上下文信息;最后,通过CRF模型解码深度神经网络模型的输出,获取最优标注序列。实验结果表明,提出的方法较传统统计方法能得到更好的效果。
在未来研究工作中,将尝试端到端的训练模型,并进一步从词法分析角度挖掘印地语本身的语言特征,进而辅助深度学习模型的学习效果,从而提高印地语词性标注的准确性。
