基于特征融合的行人重识别算法
2020-05-30钱华明王帅帅王晨宇
钱华明,王帅帅,王晨宇
哈尔滨工程大学 自动化学院,黑龙江 哈尔滨 150001
行人重识别是指利用计算机视觉技术来判断摄像机拍摄的不同行人图像或视频中同一身份行人的处理过程。当前行人重识别主要包括特征表示和相似度计算2 个阶段。研究发现,当前监控视频中的行人图像在尺度、视角和光照不同时有很大的变化[1],这些变化导致即使是同一个行人的图像仍然有较大的差别。如何更好地描述行人的特征成为行人重识别技术关键的一步。
在特征表达方面,文献[2]采用整体特征进行重识别,并在数据集上得到验证;L.Bazzani 等[3]采用了颜色特征进行识别,并随机选取了视频帧来处理多帧图像,准确率有了很大提高;文献[4]把图像的空间直方图作为整体特征,将HOG 特征作为局部特征,然后将二者进行融合;Liu Chunxiao等[5]将加博变换(Gabor)特征和局部二值模式(local binary patterns,LBP)等综合起来表述行人图像;文献[6]提出的局部对称积累特征提升了视角变化的鲁棒性;随着深度学习的的发展,文献[7]对图像采用深度学习的方法来提取行人特征,极大提高了行人重识别的精度。
针对现有重识别算法存在的不足,本文采用新的特征融合算法来进行重识别。同时为了提高较大数据量下行人检测的效率,提出了先进行预识别的策略。因为使用单个特征不能很好地描述行人,多种特征结合才能提高识别效果。现拟采用多个特征融合的方法,使用新的特征融合策略,将低级特征与中级特征结合在一起,然后进行相似度计算,得到最终识别结果。
1 图像预处理
在实际监控视频中,不同监控摄像头拍摄参数不同、环境条件和光照条件也有很大的改变等,这导致即使是同一个人,在不同的监控设备上拍的照片会有很大的差别,这给重识别精度带来了影响。为了更准确的检测,本文采用的行人图像尺寸都设为128 pix×48 pix(简写为128×48)。然后使用Retina-Cortex(Retinex)算法[8]对检测的行人图片进行处理。本文采取带色彩恢复的多尺度视网膜增强(multi-scale retinex with color restoration,MSRCR)算法来处理图片。此算法可以增强颜色特征,并且使图像颜色不失真。本文使用5 和20这2 种尺度。图1 为算法处理前的图像,图2 为增强后的图像,可以看出:经过图像增强处理后,行人图像的颜色更加鲜明,图像更加清晰,视觉效果得到提升。

图1 处理前行人图像

图2 处理后行人图像
2 行人重识别算法改进
2.1 特征选择
为了精确地识别出目标行人,同时使用中级颜色特征CN 和一些低级特征综合描述行人。其中低级特征包括整体特征和局部特征,整体特征即对整个行人图像进行特征提取,能够得到图像的整体信息。行人图像因拍摄环境、亮度、光照等因素不同,特别是在人流量大的车站、商场等,行人很容易受到遮挡、变形的影响,这种情况下无法提取图像的整体信息,导致特征匹配误差很大。为了解决这个问题,本文选取一些局部特征得到行人图像的局部信息,减小行人因遮挡、形变带来的误差。
整体特征:经过研究,本文选取HSV 颜色特征和HOG 特征来提取行人的整体特征。它们在图像领域有很多的应用,HSV 特征能够较好地表示行人外观的颜色特征,可以弥补光照变化产生的不足[9];HOG 特征保证了即使行人有一些细微的身体动作但不影响检测结果,在与行人有关的识别中得到了很多应用。
局部特征:SILTP 特征是对传统LBP 特征的优化[10],SILTP 特征改进了传统LBP 特征对图像噪声敏感的缺点,使之不仅有尺度不变性,同时减小了图像噪声。
CN 颜色特征属于低纬度的中级特征,对遮挡、光照等有鲁棒性。它生成一个颜色命名空间,使我们可以使用简单的语义属性来判断颜色。
2.2 HSV 空间非线性量化
为了提高行人的检测效率,提出了预识别的方法,分别检测目标图像的上身与下身衣服颜色,再将符合条件的图像进行更深一步的检测。
语义属性属于中级特征,在解决行人重识别问题中有很强的判别性。本设计拟采用简单的语义属性进行行人预识别,用来提高较大数据量下行人重识别的检测效率。
传统的CN 特征是采用概率潜语义分析(probabilistic latent semantic analysis, PLSA)算法在一些图片上进行学习得到的,算法较复杂且不易实现。本文通过计算颜色直方图表述行人特征。首先将行人图像的颜色量化到常用的9 种具有代表性的颜色,然后计算目标的颜色直方图。
本文采用了一种非线性量化方法。针对HSV 色彩空间的特点,将HSV 空间划分为黑、灰、白、红、黄、蓝、绿、青、紫等9 种基本颜色。为了更好地从HSV 空间划分出上述9 种颜色各自所属的颜色区域,采用产生式颜色表构建方法,如表1 为颜色对照表的一部分。根据实际需要,把HSV 空间划分成红、黄、绿、青、蓝、紫、黑、灰、白9 种颜色,并用不同的数值将其标记,一个编码对应一种颜色,结果如表2 所示。
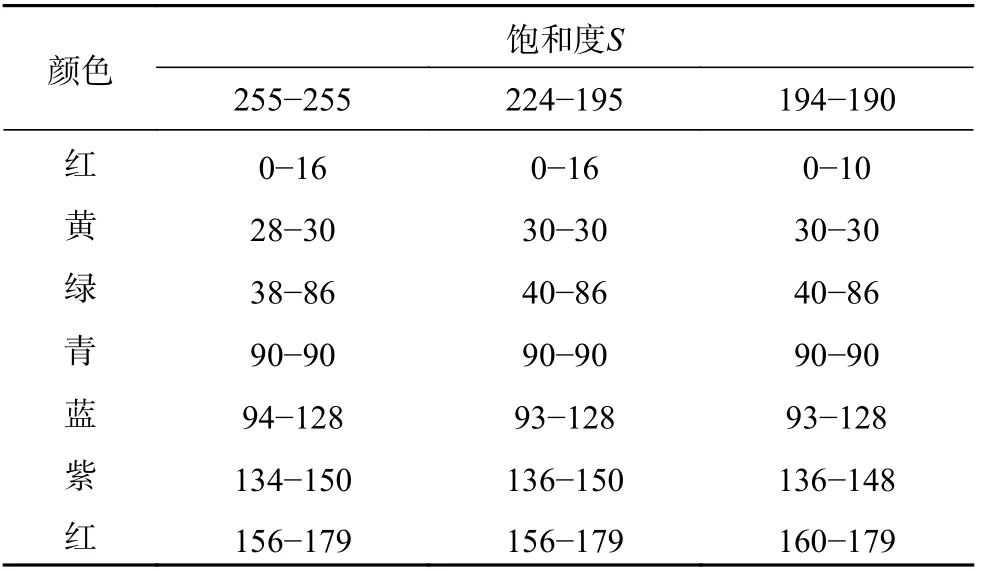
表1 颜色对照表(V=40-45)

表2 颜色标记
然后按照以下步骤操作:
1)使用亮色分离策略分割HSV 颜色空间,按照明度V分量值的大小分成多个色盘Vi(i=1,2,…,m);
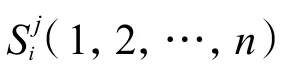
通过上述3 个步骤即可确定出每种颜色各自的H、S、V这3 个分量的取值范围。当V≤40 时,亮度太低,无论色调H和饱和度S的值如何变,该区域都因为亮度太低呈现黑色;40<V≤220 且饱和度满足S<35 时,将该区域设为灰色;当V>220 且饱和度满足S<25 时,该区域视为白色。进行人为标记得到如表1 所示的颜色对照表。通过颜色对照表就可以得到HSV 空间的一个像素点到9 种颜色的映射,即将一个点映射成为一个9 维向量,利用此映射就可以对图像进行编码。
从表1 可知,每个色环的H值并不连续,有些中间区域用人眼也很难确定属于某种颜色。本文采取模糊量化的策略,分别计算与两端相邻颜色的匹配率,就能够估计该区域属于各颜色类的概率,然后进行颜色直方图计算。
通过查表,可以将一个像素点n同C个颜色类别进行关联:u(n)={u1(n),u2(n),…,uC(n)},u(n)是像素点n属于各个颜色类别的隶属度向量,可以看出该向量可以较好地对行人进行描述,同时可以作为一种语义特征进行索引。图3~5分别为行人图像、Plsa 算法处理后图像和本实验算法处理后图像。

图3 行人图像

图4 Plsa 算法处理图像

图5 HSV 非线性量化算法处理图像
2.3 行人预识别
本文根据行人上、下半身的主颜色信息进行行人预识别。首先选取如图6 所示的行人区域,通过遍历A、B 区域内的各个像素点来得到其在HSV 空间的3 个分量值,然后根据表1 采用的量化策略,计算Ci的总体数量,得到主颜色,完成了2 个区域主颜色的识别。

图6 行人预识别分区示例
本文提出的行人预识别步骤如下:
1)计算模板图像A、B 部分的主颜色,分别记为QA、QB。
2)计算待检测行人上身的主颜色,记为TA,当TA=QA时,说明2 张图像的上身区域主颜色一致,继续执行步骤3)来计算下身区域;否则执行步骤4)。
3)计算下身区域B 的主颜色,记为TB。与模板图像的主颜色进行比较,如果TB=QB,说明2 张图像B 区域颜色一致,我们将该图像设为待选择目标。
4)下一帧图像输入,返回步骤2)重新识别新图像。
行人预识别步骤流程如图7 所示。
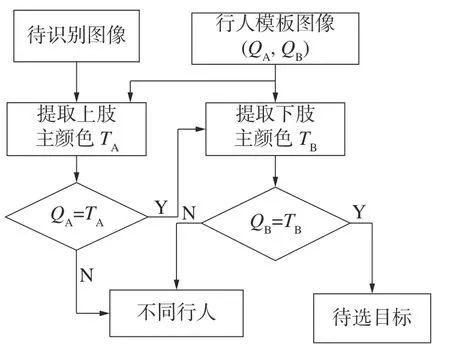
图7 行人预识别步骤流程
2.4 特征提取及融合
由于环境、光照、姿势等因素的影响,单一特征不能很好地表述行人,因此本文将多种特征进行融合[11]来解决行人姿态变化、光照变化等产生的影响。我们采用直接串联的方式对提取的特征进行融合。假设t1、t2、t3、t4分别表示提取到的特征矩阵。则将它们融合后的特征为T=[t1t2t3t4]。
首先采用现有算法提取HOG 整体特征[12]。同时本文选择使用滑动窗口法来提取图像的局部特征和HSV 颜色特征。首先将每一张行人图像按照大小水平分割分为30 个区域,每一块尺寸为8×48,我们采用8 pix×8 pix(简写为8×8)的窗口在行人图像上依次滑动。将步长定为4,得到10 个重叠块。
在文献[6]中我们得知当bin 取10 时,效果最差,是由于bin 为10 时误差很大;当bin 取40 时,会因为bin 太大发生过拟合;当bin 为25 时,效果最好。因此我们选择bin=25 来进行实验。我们对每个块分别提取9 个维度的CN 空间特征,其中每个维度分成25 个bin,最后得到225 维的CN颜色特征直方图。提取HSV 空间特征,HSV 特征有H、S、V3 个通道,将每个通道分为8 个bin,得到一个512 维的颜色直方图。
直方图提取完成后,计算得到每个块的直方图的维度为225 维的CN 特征加上512 维的HSV特征,再加上162 维的纹理特征,得到一个899 维的特征。我们将对应的维度相加,把区域中9 个899 维的直方图合为1 个。同时行人图像经常存在着尺度变化,为了能够更准确地表述图像,本文对行人图像进行2 次缩小采样。分别缩小2 倍和4 倍。同时在HOG 特征中也按照相应的倍数变化。这样总共进行了3 个尺度大小的直方图提取和区域划分,如图8 所示。原图像尺寸为128×48,2 次缩小后分别变成64×24 和32×12 的大小,n×n从8×8 缩小后变为2×2 和4×4。
父亲说,祖父早年离开家乡,远赴南洋经商,但他一直保持着中国的传统,时时告诫子女要做一个堂堂正正的中国人。对于祖父的遗训,父亲似乎一点也不敢怠慢,终其一生,他都奉为圭臬。
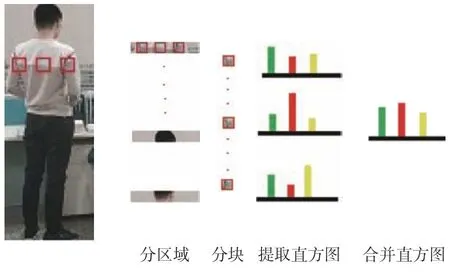
图8 直方图提取
分别提取HSV、CN 等特征后,经过计算,每张行人图像的特征维度共899×(30+9+5)=39 556维,为了提高效率,使用主成分分析法(principal component analysis,PCA)对高维度特征进行降维。最后进行特征融合。
2.5 度量学习算法
在得到了图像的融合特征后,我们要计算每个待检测图像与原图像的相似度,并对结果进行排序来找到目标图像。度量学习可以很好地完成这个任务。
2.5.1 最大间隔近邻算法
最大间隔近邻算法( large margin nearest neighbor,LMNN)主要思想是建立一个k近邻的边界,如果不同类别进入该边界,将对其处罚[13],形式如下
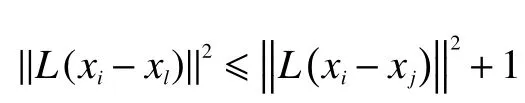
式中xi、xj、xl为不同的类。我们的主要目标是将相同样本的长度减小,将不同样本的长度变大;就是将类内目标拉在一起,推开类间的目标。对于拉近类间的距离,有
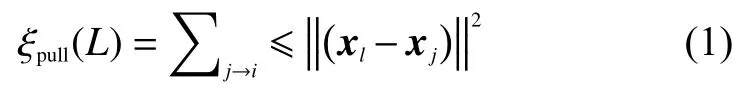
对于拉开类间的的距离,其公式为
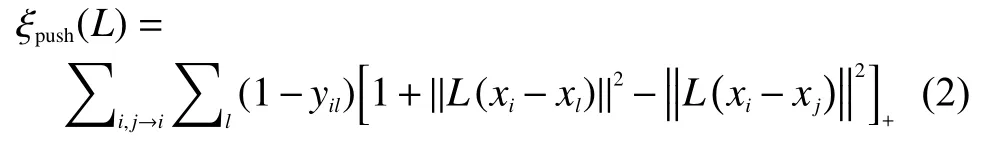
式中:[*]+=max(z,0)函数,yil表示类别标签,当xi与xl类别不同时为0,相同时为1。
因此对于式(1)、(2)处理后,得到最后的度量函数:
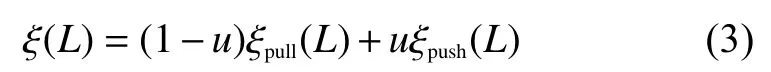
式中u为权值系数,u∈[0, 1]。
交叉二次元判别分析(cross-view quadratic discriminant analysis, XQDA)方法是对KISSME 算法延伸得到的,主要采用高斯模型推导出马氏距离[14]。这个方法不仅降低了特征维度,考虑了距离度量,同时保持了简单原则。
通过使用贝叶斯规则和对数似然比检验,决策函数可以简化为
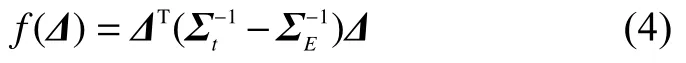
式中:ΣE=WEΣtW,Σt=WtΣtW分别是2 种不同的类别样本的协方差矩阵。
定义其子空间W,同时为了能够更好地把样本分开,采用了以下的优化方案:
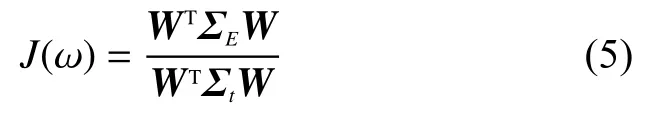
即最后的优化公式,使其获得了最大的子空间W。对于这个度量学习方法,不仅对特征进行了降维,同时还进行了度量学习。
3 实验结果分析
3.1 数据集与评价指标
本文选用了3 个数据集来测试新的特征融合算法,分别是iLIDS、VIPer、3DPeS 数据集,这几个数据集都不同程度地存在光照变化,行人环境变化、相机视角不同的问题,适合用来验证本文提出的特征融合算法。同时为了提高检测的准确性,本文将实际采集的30 对行人数据放入这3 个数据集中进行实验。
由于拍摄环境不同,不同的数据集差别也很大。iLIDS 数据集中的行人图像来自机场,由于行人很多,所以很多行人图像受到不同程度的遮挡;VIPer 数据集中图像的光照变化和行人姿态变化较大;3DPeS 数据集在视角方面有很大的差别。
在行人重识别算法测试中,累计匹配曲线(cumulative match characteristic, CMC)曲线经常被用来描述算法的性能[15]。其中第一匹配率最为重要,它是指在行人图像库中第一次就出现目标行人图像的概率。它的大小直接决定着算法性能的好坏。本文也采用这种曲线来衡量算法性能。
本文的实验测试是在Microsoft Visual Studio 17.0 和OpenCV3.4.1 工具上进行的。
实验时,为了得到更好的效果,选用不同样本数据集进行多次测试,最后计算多次的实验结果取平均值,得到最终的识别率。
3.2 融合特征有效性分析
3.2.1 融合特征有效性分析
在VIPeR 数据集上分别使用单一HSV 特征、CN 和SILTP 特征、HOG 和HSV 特征及本文融合的特征进行行人相似性度量,此处选取最大间隔近邻算法(LMNN)进行测试。测试结果如图9所示。
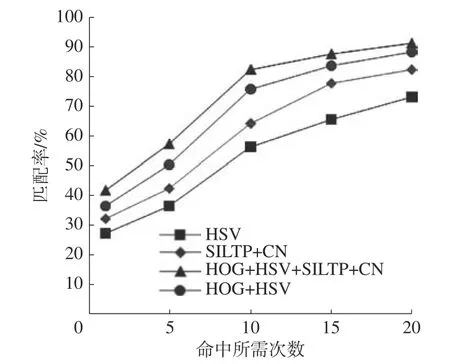
图9 不同特征CMC 曲线
由图9 可知,当只有一种特征时,效果最差;当采用2 种特征时,识别率得到了提升;当使用多种特征结合的时候识别率更好。验证了本算法的有效性。
3.2.2 融合特征适用性分析
为了更好地验证新的融合特征的效果,把新融合特征与LMNN 和XQDA 算法使用的原特征在多个数据集进行比较。其中A代表LMNN 算法原本使用的特征,B代表XQDA 算法原本的特征,M代表本文融合的新的特征。
随机从iLIDS 数据集中选取60 个行人图片用来测试,然后在剩下的每个行人的图片中随机选取一张组成测试集,再随机选取一张组成训练集。同理,在另外2 个行人数据集也进行实验。
由表3 可知,在iLIDS 数据集测试时,当使用LMNN 度量算法时,本文采用新的融合算法得到的特征Rank1 比原特征的识别率高了2.4%,Rank5高了5.5%,Rank10 和Rank20 也有提升。同时,由表中数据可以看出,当使用VIPeR 数据集和3DPes数据集测试时,本文采用的新特征的识别率都要高于原来的特征提取方法。说明了本文提取的特征的有效性。
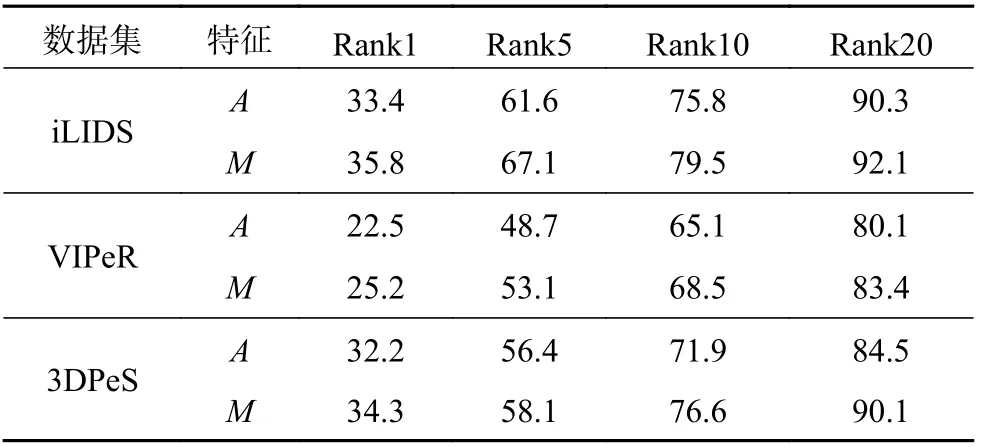
表3 LMNN 在不同数据集上的性能比较
使用XQDA 度量算法时,在iLIDS 数据集上的Rank1 比原特征识别率高了3.6%,Rank5 高了4.4%,Rank10 和Rank20 也有明显的提升。如表4所示。同理,在另外2 个数据集上的测试结果也表明识别率得到了提高。
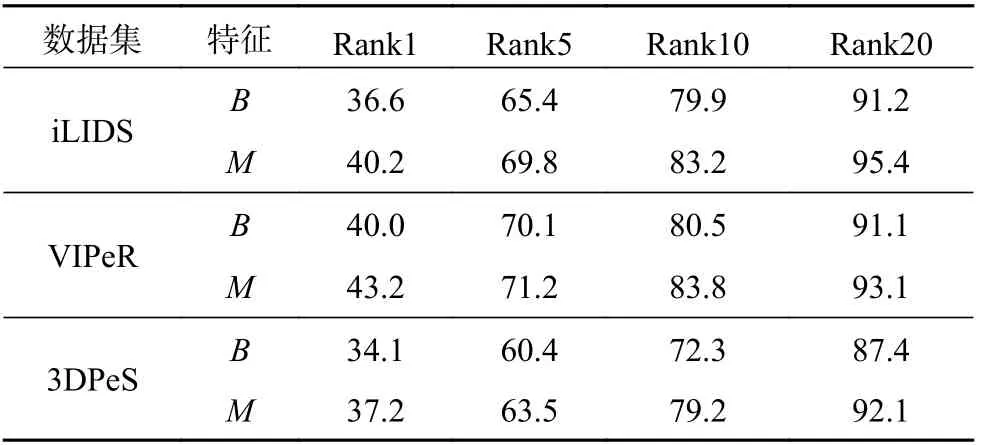
表4 XQDA 算法在不同数据集上的性能比较
如图10 对比了选用的2 个度量学习算法的识别率。可以看出,在3 个数据集上XQDA 算法的识别率都高于LMNN 算法,可知本文提出的新的融合特征结合XQDA 算法,识别率更高。
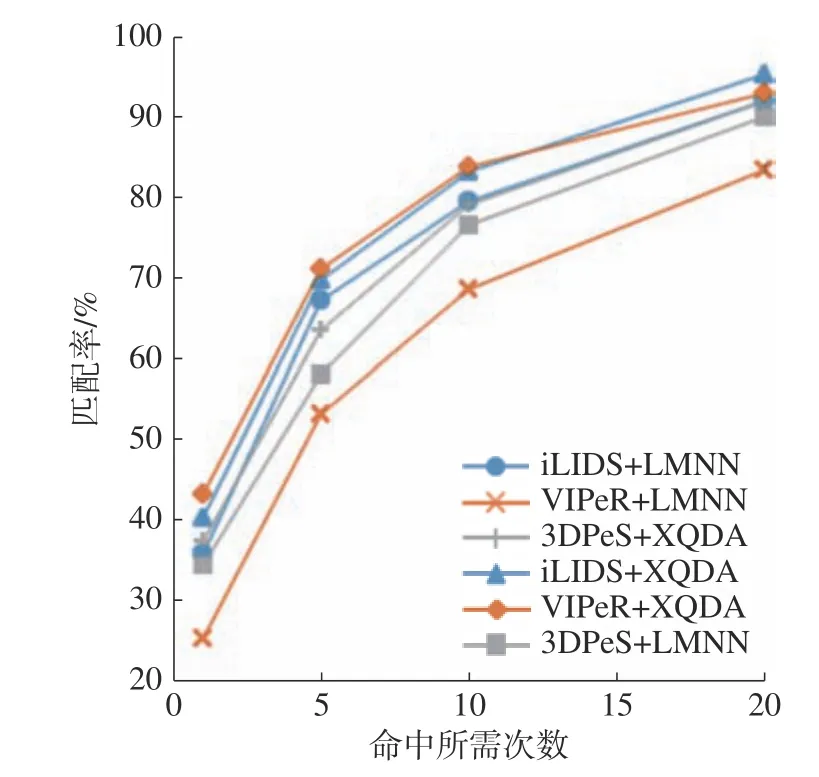
图10 LMNN 与XQDA 在各数据集上的CMC 曲线
上面的实验表明了在本文提出的行人重识别算法在行人图像光照变化、行人姿态变化和遮挡等情况都有良好的效果,体现了本算法的有效性和适用性。
4 结论
1)针对行人衣着颜色特征提出了行人预识别的策略,采用了新的HSV 空间非线性量化策略构建颜色命名空间,能够更快地去除无关行人图像,在待检测图像数据量比较大时能够提高检测效率,有利于进行实际应用。
2)采用中级CN 特征和低级的全局特征、局部特征相结合的方法,融合得到的新特征更好地描述行人图像,解决了行人图像因光照、视角变化等影响识别率的问题。使用2 种度量学习算法在3 个数据集上进行了相似度计算,在使用LMNN算法时,平均Rank1 识别率提高了2.4%;使用XQDA 算法时,平均Rank1 识别率提高了3.3%,从准确率角度讲,XQDA 算法更适合本文融合的新特征。
实验结果表明了该算法能够提高重识别精度,并适用于多种场合。在后续的研究中,将把行人重识别与行人检测、跟踪相结合,构建一个完整的行人重识别系统进行实际应用。
