运用随机森林模型对北京市林分蓄积生长量的预测1)
2020-05-29卢婧冯仲科
卢婧 冯仲科
(精准林业北京市重点实验室(北京林业大学),北京,100083)
蓄积量是森林资源监测的一个重要指标,林分蓄积量的消长变化是指导林业生产的重要指标,也是林业经营决策的重要依据[1-2]。森林经营依赖于当前和预测的森林状况,通过林分生长模型进行蓄积量预测,掌握树木的生长动态,研究森林的生长规律,合理开展各种营林措施,能够为提出优化的经营方法奠定理论基础。近年来,国内外学者对生长模型的研究不断增多,然而目前我国对林分生长模型的研究存在以下问题:对小区域单一树种和单木生长模型研究较多,对大尺度林分蓄积生长模型研究较少;与胸径、树高相关模型研究较多,对环境因子的研究主要集中于树种而非整个林分[3-4];用于分析的样地数据量不足,且缺少固定样地数据[5]。林分生长量能反映一段时间内森林能够产出多少木材,是反映碳储量、森林生产力和环境质量的重要指标,而我国现行的森林资源调查体系不能生成精确可靠的森林蓄积年度生长量,因此,通过林分生长模型来预估蓄积量是十分有必要的。
以往的林分生长模型采用多元线性回归方法,但需假设限制样本必须服从正态分布和无共线性[6]。为此,非参数的机器学习估测方法(如BP神经网络、随机森林法)被引入到回归统计中来估测森林参数[7]。但是BP神经网络存在训练时间长、预测能力与泛化能力的矛盾,易出现过拟合弊端。而随机森林模型不仅能够处理交互作用、非线性等问题,能够避免过度拟合,而且还拥有变量重要性评估功能,具有操作简便、结构清晰、运行效率高等优势[8],因此,在地质、生态等领域应用广泛[9-14]。但目前国内外将随机森林模型多用于遥感估测生物量,而预测林分蓄积生长量的研究不多。
本研究利用北京市森林资源连续清查的固定样地数据和气候数据,通过随机森林方法分别建立针叶林、阔叶林、针阔混交林的林分蓄积生长量预测模型,并根据该模型预测下期北京市森林资源连续清查的蓄积量。该方法能够为后续生物量、碳储量的估测提供数据基础,还能够为北京市森林资源评价和营林决策提供借鉴,对森林精准经营和规划具有重要的现实意义。
1 研究方法
1.1 数据来源
样地数据:用于建模的样地数据来源于2006年、2011年、2016年北京市森林资源连续清查数据。北京市森林资源连续清查(一类清查)是根据北京市地形地势特点及森林分布情况,在全市范围内采用系统抽样方法布设正方形固定样地,样地面积为0.067 hm2[15]。研究所用样地数据包括纬度、经度、海拔、坡向、坡位、坡度、土层厚度等因子,以及各样地的树种结构(针叶林、阔叶林、混交林)。利用MYSQL软件,以样地号、样木号为标准,将森林资源连续清查数据的样木库和样地库匹配得到蓄积量数据。由于测量时可能出现漏测、漏记、错记等现象,导致样地蓄积量减小,而本研究假定林分生长量均为正,因此,在建模过程中将生长量为负的数据剔除。用于建模的样地点分布如图1所示,样地覆盖度高且分布均匀,能够反映北京市林分生长状况。
气候数据:本研究所用气候数据包括平均气温、平均降水量、平均温差,由加拿大学者开发的CLimateAP免费开放软件包获取,该软件提供的气候数据覆盖整个亚太地区,涵盖了由东安格利亚大学气候研究中心生成的历史气候数据和基于IPCC第5次评估报告(AR5)预测的未来气候数据[16-17]。针对一类连清数据,根据3期连续清查观测样地的点位坐标逐年提取了2007—2021年的气候数据,分为3个时间段(2007—2011、2012—2016、2017—2021年)对气温、温差、降水量取平均值,作为气候因子参与建模,分别对各期数据进行预测分析。
1.2 随机森林模型
随机森林模型主要思想来源于Boosting、AdaBoost和Bagging等算法,随机森林模型建立的是多个决策树,即通过多个弱学习器的结合,达到强学习器的效果[18-19]。随机森林是由很多的决策树{f(x,θk),k=1、2、…、k}组成,其中x是输入的向量,θk是独立同分布的随机向量,决策树与决策树之间是相互独立的[20]。在森林训练完成后,当有新的数据输入时,随机森林中的所有决策树独立进行计算。当预测变量为数值型变量时,生成的随机森林模型为多元非线性回归模型,模型预测结果为多棵决策树预测结果的平均值。
在随机森林模型中,需要设置树的棵数(n)和树节点抽选的变量个数(m)。树的棵数为重抽样次数,一般当树的棵数大于500以后整体误差率趋于稳定[21],但为保障预估结果的可靠性且不会影响计算效率,树的棵数需要依据具体数据而定。变量个数指每次寻找最佳分割效果时从全部自变量中随机选取的变量数,一般对于回归问题,变量个数默认值设置为全部自变量数目的三分之一[22]。
1.3 模型精度评价
本文利用全部数据的80%进行建模,20%进行验证。在综合考虑多种因素的考虑下,选择以下5项指标作为长期动态预测模型的基本评价指标[23-26]:决定系数(R2),偏差(B),均方根误差(RMSE),相对偏差(rB),相对均方根误差(rR)。具体计算公式如下:
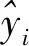
1.4 变量重要性评价
在模型建立后需进行变量重要性评估,可以看出各个因子分别对针叶林、阔叶林、针阔混交林生长的影响大小。其基本思想是[27-28]:对于随机森林中的每一颗决策树,使用相应的袋外数据来计算它的袋外数据误差,记为B1;然后随机地对袋外数据所有样本的特征X加入噪声干扰,再次计算它的袋外数据误差,记为B2;假设随机森林中有n棵树,那么,特征X的重要性得分为V(X)=∑(B2-B1)/n。
1.5 模型实现
为实现森林资源的经营管理和可持续发展,需要及时准确地掌握森林资源状况,尤其是森林资源的动态变化情况。从匹配好的样地中,根据树种组成将样地分为针叶林、阔叶林、针阔混交林,样地数量分别为736、268、729个。
在建模过程中,因变量为蓄积生长量,自变量为经度、纬度、海拔、平均气温、平均降水量、平均温差、土壤厚度、坡度、坡向、坡位等因子,在R.3.4.3环境下调用随机森林数据包,分别建立针叶林、阔叶林、针阔混交林的林分蓄积生长量动态预测模型,其中n取值为1 000,m取值为3。
2 结果与分析
2.1 模型检验
由表1可,模型的各项评价指标较好,能够满足森林样地蓄积量预测的精度要求。针对针叶林、阔叶林、混交林,其决定系数(R2)分别为0.93、0.94、0.89,说明模型的拟合优度较好;其偏差(B)分别为0.006 6、-0.015 3、0.077 9 m3/hm2,均方根误差(RMSE)分别15.499 1、9.555 7、14.293 7 m3/hm2,相对均方根误差(rR)分别为26.12%、18.99%、35.25%,相对偏差(rB)分别为0.01%、-0.03%、0.19%,表明预测的蓄积量准确度较高,模型可靠性良好。

表1 林分蓄积生长量预测模型效果评价
为了更加直观的表达模型预测结果的偏差,绘制调查值与预测值关系散点图。从图2中可以看出,模型预测出的蓄积量与蓄积量标准值的一致性较好,进而说明模型的拟合效果良好。
2.2 因子重要性评估
由表2可知,影响针叶林生长因子重要性从大到小的顺序为:坡度、平均气温、经度、海拔、平均温差、纬度、坡向、坡位、平均降水量、土层厚度;影响阔叶林生长因子重要性从大到小的顺序为:平均降水量、平均温差、经度、纬度、平均气温、海拔、坡向、土层厚度、坡度、坡位;影响针阔混交林生长因子重要性从大到小的顺序为:纬度、经度、平均温差、平均降水量、平均气温、坡度、海拔、坡位、土层厚度、坡向。综合来看,环境因子对3种林分生长的影响程度各不相同,其中经度、纬度、平均温差对林分蓄积量的生长影响较大。
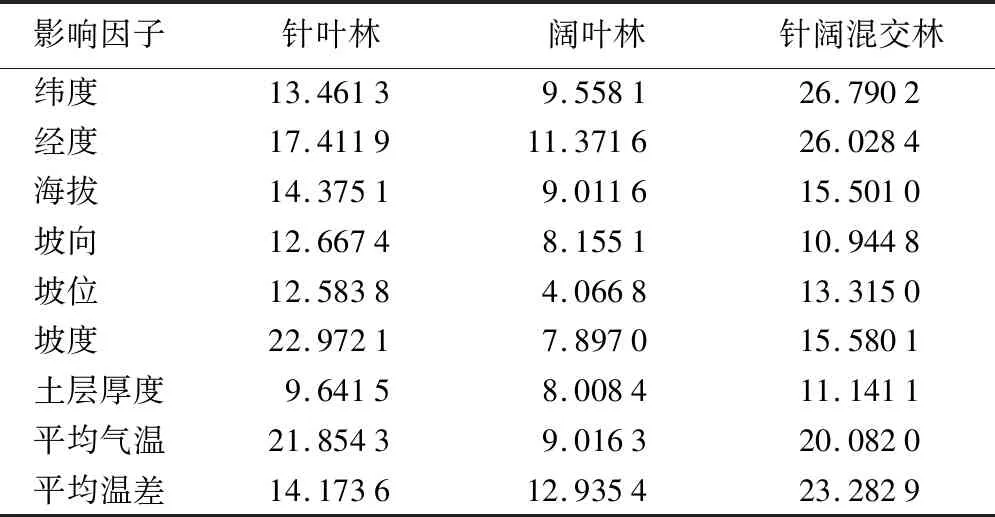
表2 林分生长影响因子相对重要性 %
2.3 北京市林分蓄积生长量预测结果
样地数据选择2016年全部4 074个森林资源连清样地数据,其中,针叶林921个、阔叶林539个、针阔混交林2 614个,气候数据利用ClimateAP软件提取得到2017—2021年的平均气温、平均降水量、平均温差,根据随机森林模型预测出蓄积生长量,并得到2021年的北京市林分蓄积量。由表2可知,北京市林分蓄积量预测的平均值为58.107 3 m3/hm2,变化范围为7.284 6~388.775 6 m3/hm2,蓄积量平均值由大到小分别是针叶林、针阔混交林、阔叶林。
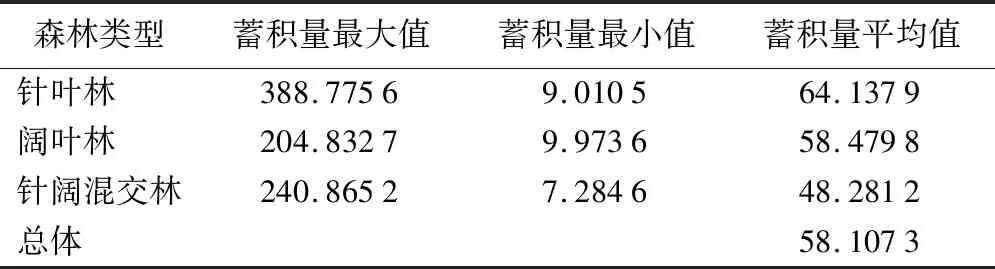
表3 北京市三种森林类型2021年蓄积量统计指标
2.4 北京市林分蓄积量时空变化
2.4.1 北京市林分蓄积量时间变化
由表3可知,北京市林分年平均蓄积量2006为36.358 5 m3/hm2,2011年为51.939 2 m3/hm2,2016年为53.210 9 m3/hm2,预测的2021年为58.107 3 m3/hm2,总体呈增加趋势,在15年内,林分蓄积量共增加21.748 8 m3/hm2,其中2006—2011年增加幅度最大,年平均蓄积量增加了15.580 7 m3/hm2。由于政府制定政策保护首都园林绿化建设成果并引导全市严格保护林地,北京市林地面积不断增加,而2006—2011年林地面积增加幅度较大,因此,北京市林分蓄积量呈增长趋势[29]。
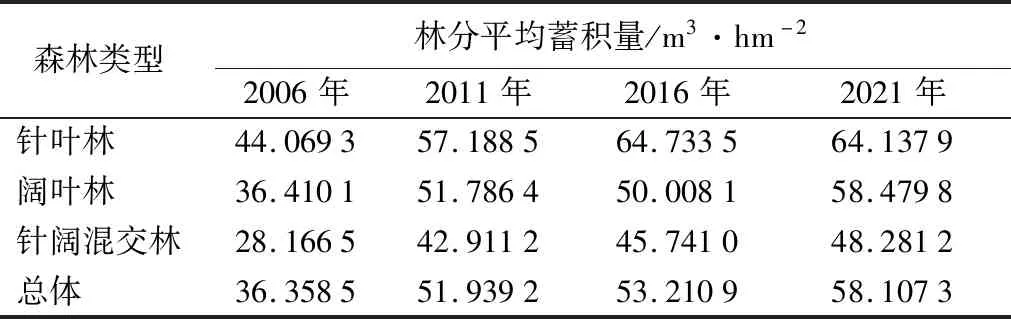
表4 北京市2006—2021年林分蓄积量变化
从3种森林类型的蓄积量变化情况,针叶林蓄积量在2006—2016年不断增加,预测2021年小幅下降;阔叶林的蓄积量在2006—2016年先增加后减小,预测2021年大幅上升;针阔混交林在2006—2016年不断增加,预测2021年继续保持上升趋势。因此,需进一步落实政府制定的发展战略,做好生态退耕造林工作,促进首都经济社会可持续发展[30]。
2.4.2 北京市林分蓄积量空间变化
由图4可知,北京市年平均蓄积量分布在15年间较为一致且逐渐均匀,并未因为平均蓄积量的增加出现某区域蓄积量激增现象。按北京市的14个城区来看,位于北京市边缘区的门头沟区、顺义区、通州区等蓄积量较大,位于城市中心的西城区、东城区、朝阳区、石景山区等蓄积量较小。这是由于北京市城市森林资源分布不均匀,山区森林面积占北京市森林总面积的75%,而人口相对集中的城区、平原区的森林资源明显不足[31]。北京市蓄积量的空间分布及变化为城乡统筹发展提供基础,为林业各方面的分析提供科学依据,从而为各级部门的管理、决策工作提供服务。
3 结论与讨论
森林蓄积量是政府掌握国家森林资源状况和制定计划采伐、森林经营管理措施的重要依据,其生长量能够反映环境因子对森林生长的综合影响,因此,测定林分蓄积生长量具有重要意义[32]。本文结合已知固定样地数据和对应环境因子数据,利用随机森林方法建立与经纬度、海拔、平均气温、平均降水量、平均温差、坡度、坡向、坡位、土壤厚度相关的林分蓄积生长量预测模型。利用北京市第六~八期的一类连清数据进行建模,预测出第九期蓄积量。
(1)林分蓄积生长模型预测精度R2为0.92,其中针叶林、阔叶林、混交林的预测精度分别为0.93、0.94、0.89,说明模型拟合优度较好;其偏差、均方根误差、相对均方根误差、相对偏差均满足要求,表模型准确度较高,可靠性好。
(2)通过随机森林方法得到的模型中每个变量的重要性评分表明,环境因子对3种林分生长的影响大小各不相同。对于针叶林生长影响较大的因子为坡度、平均气温、经度、海拔;对于阔叶林生长影响较大的因子为平均降水量、平均温差、经度、纬度;对于针阔混交生长影响较大的因子为纬度、经度、平均温差、平均降水量。
(3)预测的2021年北京市林分蓄积量平均值为58.107 3 m3/hm2,变化范围为7.284 6~388.775 6 m3/hm2;蓄积量平均值由大到小分别是针叶林、针阔混交林、阔叶林。将预测的林分蓄积量与前几期蓄积量进行对比,在时间尺度上蓄积量呈增加趋势,在空间分布上蓄积量与前些年较为一致,中心城区的蓄积量逐渐增加。
