基于SVM的融合多特征TextRank关键词提取算法
2020-05-25朱衍丞蔡满春芦天亮石兴华丁祎姗
朱衍丞 蔡满春 芦天亮 石兴华 丁祎姗
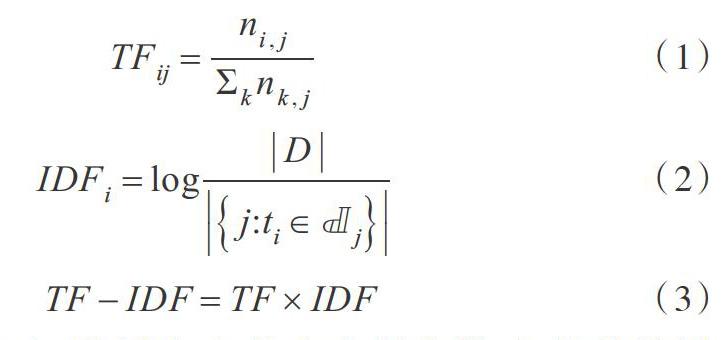

摘 要:网络用户通常使用关键词筛选所需信息,但随着网络文本信息爆发式增长,且大多数文本信息不提供关键词,用户提取有效信息的难度不断增大。利用关键词提取算法可从文本数据中筛选出具有代表含义的关键词,因此提出一种新型基于TextRank的关键词提取算法。该算法利用每个词的TF-IDF、词向量、位置、词性等特征,利用SVM训练得到的词语初始权重,使用TextRank提取文本关键词。实验表明,該算法准确率达到78.09%,相较于传统TextRank算法提高了32.18%,证明该算法具有一定的实用及参考价值。
关键词:关键词提取;支持向量机;TextRank
DOI:10. 11907/rjdk. 192152 开放科学(资源服务)标识码(OSID):
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2020)002-0088-04
英标:Research on SVM-based Fusion Multi-Feature Textrank Keyword Extraction Algorithm
英作:ZHU Yan-cheng,CAI Man-chun,SHI Xing-hua,LU Tian-liang,DING Yi-shan
英单:(Institute of Police Information and Cyber Security,Peoples Public Security University of China,Beijing 102628,China)
Abstract:Network users usually use keywords to filter the required information, but as the network text information grows explosively, and most text information does not provide keywords, it is more difficult for users to extract valid information. The keyword extraction algorithm can be used to filter out the keywords with representative meanings from the text data. Therefore, a new TextRank keyword extraction algorithm is proposed. This algorithm uses the TF-IDF, word2vec, position, part of speech and other attributes of each word as well as the initial weights of the words obtained by SVM training. On this basis, TextRank algorithm is used to extract the keyword. The experimental result shows that the accuracy of the algorithm reaches 78.09%, which is 32.18% higher than the traditional TextRank algorithm. The results prove that the algorithm designed in this paper has certain practical and reference value.
Key Words: keyword extraction; support vector machines; TextRank
0 引言
关键词提取是自然语言处理中的一个重要子任务。关键词是可反映文本主题或主要内容的词语。准确提取文本关键词在信息检索、对话系统及文本分类方面具有重要意义。
在不支持全文搜索的文献检索初期,关键词作为搜索论文的必要条件,是论文设计过程中不可或缺的部分,该项设置保留至今[1-2]。但近年来,随着网络自媒体的快速发展,每个用户都可成为网络消息生产者、传播者及消费者,没有提供关键词的网络信息每时每刻在大量产生。在实际应用中,用户通常更倾向于利用关键词对网络信息进行识别、区分对自己有价值的信息,再对网络信息进行检索、分类、聚类等操作。因此,一个有效的关键词提取技术可帮助用户实现快速搜索,获取目标信息。
传统关键词提取算法主要有TF-IDF、TextRank、LDA等基于无监督的关键词提取算法,这些算法通常建立在统计学分析基础之上,基于候选词词频、文档频率等统计信息筛选出关键词,该类算法效率较高,在大量数据统计分析方面具有一定优势,但同时往往忽略了候选词所在文章的内在结构与关联信息,导致关键词提取效果不佳[3]。目前这些方法在英文文本上具有较好的效果,在中文中的应用却不尽如人意[4]。首先,汉语复杂性决定了任务难度,且大量长句和复杂句法也给算法带来了巨大挑战[5]。此外,语料资源稀缺也是限制自然语言处理发展的重要原因之一[6]。
基于有监督的关键词提取方法,如SVM、Bayes等,利用提取算法分析大量文本,从而得到一种关键词提取规则,该规则相较于基于无监督的关键词提取算法,获取规则更加科学、有效,抽取的关键词质量大幅提高,但是基于有监督的自动关键词提取算法不能提取文本关键词,且操作过程较为复杂,使用不便[7-8]。
为提高关键词提取准确度,充分发挥有监督与无监督关键词提取算法的优点、克服其缺点,本文提出一种基于TextRank的关键词提取模型,该模型使用Word2Vec算法提取词的语意属性,结合位置权值、TF-IDF值,词性等属性,利用SVM算法,对文本不同词进行学习,预测其为关键词的可能性(用百分比表示),并作为TextRank初始权值,进行关键词提取[9-10]。
为降低语料规模与领域性方面的影响,本文使用共计65万多条所有栏目的新闻文本及新闻编辑筛选的关键词作为训练及测试样本[11]。
1 相关研究
1.1 数据分析
本文数据均来自于网上爬取的新闻数据及其关键词(关键词数量大于或等于1),利用Python的jieba包对文本数据进行分词并标注词性。在实际测试中,经过人工筛选的关键词往往屬于人名、地名及短语,故将所有关键词取出生成词表,加入到jieba词典库中,提高分词效果,减小因分词算法缺陷造成的误差。
本文新闻样本中的关键词是编者基于真实用户需求提取的,这些关键词涵盖了新闻关键信息,可使读者更快速地了解相关新闻主旨并选择是否详细阅读。从现状来看,常规基于统计的关键词提取算法在该类新闻样本上测试效果不好。同时对于传统算法,生成的结果形式是一个词对应一个权值,按照权值从大到小排序后,选取一定数量靠前的词作为文本关键词。考虑到现实情况,根据阈值对关键词进行筛选,该阈值为根据预测关键词总数与实际关键词总数比值约为2时对应的阈值。
1.2 传统算法测评
词频-逆文本频率((Term Frequency-Inverse Document Frequency,TF-IDF)由两部分组成。词频指某个给定的词语在单个文本中出现的频率;逆文本频率由包含文本总数目除以包含该给定单词的文本数目。计算公式为:
其中词频(TF)=某词在文章中出现次数/文章的总词数,逆文档频率(IDF)=log(文本的总数/包含该词的文本数+1)。
经过统计分析,设定TF-IDF阈值为0.156,统计结果见表1。
TextRank算法基于PageRank,是一种基于图的模型,通过构建拓扑结构图,对词句进行排序,一般用于为文本生成关键词和摘要。在关键词自动抽取领域,TextRank作为当前主流方法,在各领域已有较成熟的应用。本文在对算法进行简单介绍后,基于当前数据集进行测评。
根据TextRank的定义,可将PageRank的公式改写为:
由式(4)、式(5)可知,如果某词后来出现频率高,则该词将比较重要,即TextRank值很大;在TextRank值很大的词后面出现的词,TextRank值也会有一定增幅。
其中,[w(vj,vi)]表示节点[vj]到节点[vi]的边的转移概率,[out(vj)]表示节点[vj]指向的所有点集合,[In(vi)]表示节点指向[vi]的所有点集合,[w(vi)]表示节点[vi]权值,每个节点初始权值相同。
经过统计分析,设定TextRank阈值为2.20,统计结果见表2。
改进的TextRank算法基于TextRank原理,利用不同规则生成初始权值提高TextRank效果,需复现两种算法:TFIDF-TextRank算法与融合多特征的TextRank算法[12]。
基于TextRank的计算公式,将[w(vi)]分别定义为:
式中[α]是一个常数,对于式(6),每个单词的权重由TF-IDF值决定,对于式(7),[WFreq]、[WPos]、[WLoc]分别表示单词平均信息熵、词性权重、位置权重,其中[α]、[β]、[γ]是系数。
经过统计分析,设定TFIDF-TextRank的阈值为3.30,融合多特征TextRank的阈值为2.30,统计结果见表3。
对比TF-IDF与TextRank及其相关改进算法的结果可知,基于统计分析的传统关键词提取算法在当前数据集上的效果较差,提取的关键词往往只能作为参考[13-14]。相比之下,改进后的TextRank算法效率较高,由此可知,关键词不仅与其词频有关,还与词的其它属性有关[15]。所以,为获得效率较高的关键词提取算法,必须改进TextRank算法,充分利用该关键词在文章中的其它信息,生成更好的初始权重,以提高关键词提取准确率。
2 算法创新
2.1 词属性选择
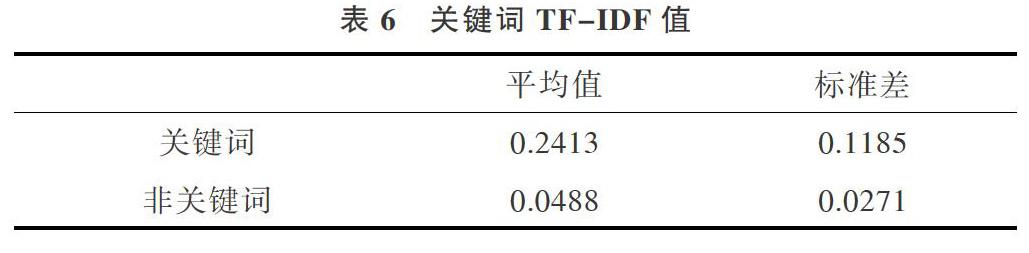
基于关键词的特点,从统计学角度分析发现,关键词与非关键词在其词性、首次出现的位置(位置权重标准见表7)、TF-IDF值均存在明显差异。对当前数据集进行统计,结果如表4—表6所示。
鉴于通过以上几种属性无法对词进行语义层面的划分,所以在模型中引入词向量(Word2Vec)属性。词向量模型是一种简化的神经网络,利用one-hot对句子进行编码,以相似度计算的方式,用指定长度的向量表示每一个在句子中出现的词[16],这一特定长度的向量便称为词向量。
2.2 初始权重生成
以上属性较为复杂,维度较大,往往很难通过人工设置权重的方式进行计算。采用支持向量机(SVM)对词的属性进行训练,以生成TextRank的初始权重。SVM以统计学的VC维理论与结构风险最小原理为基础,在解决一系列实际问题中表现出优良的学习能力[17]。SVM不同于决策树(DT)、朴素贝叶斯(NB)等分类算法,不仅在高维模式识别中表现出较好的效果,同时具有较强的泛化能力[18]。可以推测,通过给TextRank设置更优的初始权值可提高准确度。因此,本文利用SVM对文本中的词进行训练以生成初始权值[19]。
在数据准备阶段,首先计算并生成相关词的属性信息(见表7)。其中关键词标签为pos,非关键词标签为neg。
训练中使用Python 的sclera包中的SVM类,对以上数据进行训练。其中,参数C=0.8,kernel=linear,gamma=1,同时,为了可以得到概率,将probability设为true。实验证明,用以上参数对模型进行训练可得到较好的训练结果。
考虑到计算时间,本文采用其中1万篇文章,共计6万余词,其中关键词和非关键词的比例为1∶1,对模型进行训练。最终利用SVM模型对文章中每一个词进行判断,以模型判断为pos的概率,并作为TextRank初始权值。
3 结果分析
在实际应用过程中,因为模型较为复杂,每一次搜索及运算时耗较大,所以本文在测试集中随机取3万条文本进行3次统计分析,取其平均值作为最终结果。设定该算法阈值为4.20,统计结果如表8所示。
相较于其它几种算法,结合SVM提取特征的TextRank关键词提取算法效果较好,且在大规模数据量上也能达到较平均的水平。
从该结果可以推断出,关键词与其它词在位置权重、词性、TF-IDF值及词向量等特征上具有明显区别。在使用多种特征对词进行筛选时,SVM可以对多种特征进行有效整合,生成一个特征值,该特征值可作为权重使用,结合TextRank,得到的结果可超过其中单独某个算法可达到的最佳值。
4 结语
与传统TextRank及其它利用位置、TF-IDF等表征属性的改进型TextRank关键词提取算法相比,本文结合SVM的TextRank关键词提取算法在已有研究基础之上,加入了词性和词向量等特征,并独创性地使用SVM将这些特征有机结合起来,显著提高了TextRank算法效果。但该算法生成的模型较为简单,与基于理解的自然语言处理方法相比还存在较大差距[20],并且算法存在一定的局限性,还需进一步优化。
参考文献:
[1] 赵京胜,朱巧明,周国栋,等. 自动关键词抽取研究综述[J]. 软件学报,2017,28(9):2431-2449.
[2] 刘啸剑. 基于主题模型的关键词抽取算法研究[D]. 合肥:合肥工业大学, 2016.
[3] 方龙, 李信, 黄永,等. 學术文本的结构功能识别——在关键词自动抽取中的应用[J]. 情报学报, 2017(6):67-73.
[4] NAN J,XIAO B,LIN Z, et al. Keywords extraction from chinese document based on complex network theory[C]. Hangzhou: 2014 Seventh International Symposium on Computational Intelligence and Design,2014.
[5] 张谦,高章敏,刘嘉勇,等. 基于Word2vec的微博短文本分类研究[J]. 信息网络安全, 2017(1):57-62.
[6] 盛晨,孔芳,周国栋. 中文篇章零元素语料库构建[J]. 北京大学学报:自然科学版, 2019, 55(1):18-24.
[7] GU Y,XIA T. Study on keyword extraction with LDA and TextRank combination[J]. New Technology of Library and Information Service, 2014,30:41-47.
[8] ZHANG K,XU H,TANG J,et al. Keyword extraction using support vector machine[M]. Berlin:Springer, 2006.
[9] 徐晓霖. 融合Log-Likelihood与TextRank的关键词抽取研究[J]. 软件导刊,2018,17(3):87-89.
[10] 宁建飞,刘降珍. 融合Word2vec与TextRank的关键词抽取研究[J]. 现代图书情报技术,2016(6):20-25.
[11] 徐冠华,赵景秀,杨红亚,等. 文本特征提取方法研究综述[J]. 软件导刊,2018,17(5):17-22.
[12] 李航,唐超兰, 杨贤,等. 融合多特征的TextRank关键词抽取方法[J]. 情报杂志, 2017(8):187-191.
[13] CHEN C H. Improved TFIDF in big news retrieval: an empirical study[J]. Pattern Recognition Letters, 2017,93:112-122.
[14] LI W,ZHAO J. TextRank algorithm by exploiting Wikipedia for short text keywords extraction[C]. IEEE International Conference on Information Science & Control Engineering,2016.
[15] TU S S, HUANG M L. Mining Microblog user interests based on TextRank with TF-IDF factor[J]. The Journal of China Universities of Posts and Telecommunications, 2016(5):44-50.
[16] ZUO X,ZHANG S,XIA J. The enhancement of TextRank algorithm by using word2vec and its application on topic extraction[J]. Journal of Physics: Conference Series, 2017, 887:012028.
[17] GOLDBERG Y,ELHADAD M. splitSVM: fast, space-efficient, non-heuristic, polynomial kernel computation for NLP applications[C]. Meeting of the Association for Computational Linguistics on Human Language Technologies: Short Papers,2008:237-240.
[18] 丁世飞,齐丙娟,谭红艳. 支持向量机理论与算法研究综述[J]. 电子科技大学学报,2011,40(1):2-10.
[19] 曹雪峰. SVM在决策树归纳中的应用[D]. 保定:河北大学,2009.
[20] XU S, KONG F. Toward better keywords extraction[C]. Suzhou:International Conference on Asian Language Processing, 2015.
(责任编辑:江 艳)
