一种主动半监督大规模网络结构发现算法
2020-05-23柴变芳曹欣雨魏春丽王建岭
柴变芳,曹欣雨,魏春丽,王建岭
1)河北地质大学信息工程学院,河北石家庄 050031;2)河北中医学院教务处,河北石家庄 050200
当前社会正处于信息化浪潮的新阶段,大量数据时刻生成并可建模为大规模网络.快速、准确地识别这些网络数据潜在的聚类结构,是商家定位用户群体,制定精准营销策略的依据.网络中可能存在社区结构[1-2]、星型结构或层次结构,甚至同时存在多种结构.关于这些网络的先验信息很少,成为人们发现网络潜在结构的难点.FORTUNATO[2]采用社区发现算法识别网络中类内链接紧密和类间链接稀疏的结构,但当网络中可能不存在这种结构时,该算法不能发现真实的网络聚类模式.一些网络结构发现方法可识别网络的多类型潜在聚类模式,如基于随机块模型的算法[3],但此类方法复杂度高,不能处理大规模网络.基于混合模型的网络结构发现算法——在线变分期望最大(online variational expectation maximization, onlineVEM)算法[1],可发现大规模网络的多类型聚类结构,但其结果受初始参数影响,准确性和稳定性还有待提升.
近年来出现的半监督社区发现方法,利用先验信息提高了网络社区发现的准确率[4-13].根据半监督社区发现算法使用先验的形式,将现有方法分为基于节点先验的方法[4-6]和基于约束对先验的方法[7-13].后者因先验信息容易获得而较为流行.根据约束对先验信息的获得方式,将现有算法大致分为2类:① 随机选择约束对标记[7-11],如YANG等[9]提出基于非负矩阵分解(nonnegative matrix factorization, NMF)的超网络半监督社区发现算法(SuperNMF),随机选择约束对先验标记,利用约束先验改变网络的邻接矩阵,采用传统的社区发现方法获取网络节点聚类.② 基于主动学习策略选择约束对进行人工标记,以较少的先验实现算法性能较大程度提升[12-13].如YANG等[13]提出迭代主动半监督社区发现算法ALISE(active link selection),主动选择最不确定的节点对进行人工标记,利用已标记链接重构网络拓扑结构.这些半监督社区发现算法主要发现网络中的社区结构,如果网络中不存在这种社区结构,或者存在其他类型结构,此类算法无效,且这些方法主要针对中小规模网络.
综合大规模在线网络结构发现方法、半监督社区发现方法和主动半监督聚类方法研究成果可知,通过主动选择信息量大的节点,利用约束对先验,对其进行类别标记,可用较少的代价获得高质量的先验,使算法不仅能更准确地识别网络的各种聚类模式,还能高效处理大规模网络.为此,本研究基于onlineVEM算法,提出一种用于大规模网络结构发现的基于迭代框架的主动半监督在线变分期望最大(active semi-supervised onlineVEM, ASonlineVEM)算法.算法包含初始化阶段和在线算法迭代阶段.初始化阶段主动选择代表节点,并基于代表节点初始化模型参数.在线算法迭代阶段每次迭代执行3个任务:① 运行onlineVEM算法;② 不确定节点选择;③ 模型参数更新.在不同网络数据上与同类算法进行比对,结果表明,ASonlineVEM算法可利用少量先验信息较大程度提高网络结构发现的准确率.
1 大规模网络的主动半监督结构发现策略
onlineVEM算法是针对大规模网络结构发现设计的在线算法.算法先随机选择网络中部分节点构成子网络,利用期望最大(expectation maximization, EM)算法估计节点的类隶属度及混合模型参数,再迭代估计网络的剩余节点隶属度及模型参数.估计方法为:
迭代过程中选择1个节点i, 它属于类k的概率γik即为该节点的隶属度
(1)
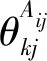
利用当前节点的隶属度更新模型参数,则第t+1 次迭代时所有节点属于类k的概率为
(2)

第t+1次迭代时, 类k节点链接到节点j的概率为
(3)

onlineVEM算法每次迭代随机选择1个节点,利用式(1)计算其隶属度,再利用式(2)和式(3)更新模型参数,迭代此过程直到算法准确率或迭代次数达到阈值(准确率阈值通常为算法两次迭代优化目标函数差值<1×10-6,迭代次数阈值设为网络节点数的2倍).若初始估计的模型参数不准确,会导致后期更新的模型参数是一个较差的局部最优解;每次随机选择1个节点则会使算法不能快速收敛.因此,可利用主动策略选择信息量大或难以识别的节点进行标记的特点,将这些信息作为监督信息,以提高算法的准确率.本研究采用3种策略对onlineVEM算法的准确性及效率进行改进.
策略1 主动选择代表节点进行标记.考虑到在线算法上次迭代参数对下次迭代的参数更新有较大影响,初始参数应保证有较高准确性,因此,需在初始化参数时尽量确定影响力大的节点的类隶属度.为使代表节点对其同类节点具有较大影响,可通过主动策略选择代表节点标定初始化参数,并利用代表节点的精确标定最大程度影响剩余节点.基于k-rank-D[14-15]选择最可能成为代表节点的候选集合,并用标定的约束对先验从候选集合中选择各类的代表节点,利用代表节点初始化模型参数.
策略2 主动选择不确定节点进行标记.当代表节点确定后,网络中仍存在一些难以确定类别的边界节点.通过节点类隶属度信息主动选择不确定性高的节点,利用约束对先验确定其与哪个代表节点具有必联(must-link)关系,从而实现不确定节点类别的标记.
策略3 基于迭代框架的在线算法.迭代运行onlineVEM算法,每次基于上次算法迭代的结果,选择最不确定的节点进行标记,进而得到一个更优解,下次算法从该解开始寻找更优的解.该迭代框架能找到比运行1次onlineVEM算法更优的解.为提高算法运行效率,在迭代过程中,对于已标记类别信息的节点在后续算法中将不再估计其类隶属度.
2 ASonlineVEM算法
2.1 变量定义
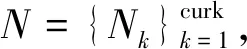
2.2 ASonlineVEM算法描述
算法包括模型初始化和提纯两个阶段.
2.2.1 模型初始化阶段
首先,基于k-rank-D获得网络候选代表节点集合;然后,依次主动选择各类的代表节点;最后,基于Newman混合模型[16]初始化模型参数.
1)选择候选代表节点.k-rank-D算法假设:代表节点的中心度较大,周围节点的中心度较小且距离其他代表节点较远.节点i的中心度为vi(i=1, 2, …,n), 初始中心度v0=1/n, 第t+1次迭代时,所有节点的中心度为
(4)

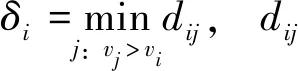
(5)


3)初始化模型参数.基于Newman混合模型利用EM算法估计N集合中代表节点隶属各类的概率;随机初始化N集合外所有剩余节点的类隶属度;最后,计算初始模型参数.
2.2.2 模型提纯阶段
通常基于模型初始化阶段得到的参数计算网络聚类的结果并不准确,需多次运行在线参数估计算法,选择不易识别类隶属度的节点进行标记,逐步提升模型性能,迭代该过程,直到达到阈值.每次迭代需进行3个操作:运行在线算法onlineVEM、主动选择节点及模型参数更新.首先,运行onlineVEM算法更新未标记节点的隶属度及模型参数.然后,采用式(6)估计节点i的熵,选择熵最大的前几个不确定节点(本研究选择3)作为待标记节点集合.最后,查询每个待标记节点i与N中代表节点是否存在必联关系,若存在,则其与代表节点属于同类,将节点i加入代表节点所在的Nk并更新节点隶属度和模型参数.迭代运行上述过程直至达到准确率和先验限制的阈值.
(6)
ASonlineVEM算法伪代码和源代码请扫描论文末页右下角二维码见图S1和图S2.第1步的中心度和节点间距离可通过离线并行算法计算,不是影响算法运行时间的主要因素.第1步的运行时间主要为计算节点离散度和代表性所用的时间,时间复杂度为O(n). 第2步的运行时间是对少量节点的计算,但这与对大规模网络节点和边相比占用时间很少.第3步初始化模型参数的复杂度为O(n). 第4步迭代的主要运行时间是在计算节点的熵和运行onlineVEM算法上,其复杂度分布为O(nc)和O(mc),m为网络边数.虽然第4步需多次迭代,但onlineVEM算法总是以上次迭代得到的参数作为初始参数,因此,算法每次迭代都会很快收敛.第4步的时间复杂度为O(tmc),t为迭代次数,网络节点越少则t越小.对于大规模网络, 即m较大时,可通过每次迭代对邻接边进行采样来提高效率.因此,ASonlineVEM算法可用来处理大规模网络,总的时间复杂度为O(tmc).
2.3 ASonlineVEM算法收敛性证明
ASonlineVEM算法是基于onlineVEM的迭代算法,每次迭代首先基于当前隶属度和模型参数运行onlineVEM算法,再选择3个节点,利用先验更新其隶属度值.CHAI等[1]证明了onlineVEM算法收敛,并设第t次迭代算法收敛到一个局部最优值Q′, 此时, 模型参数为Θ′, 节点隶属度为γ′. 然后,利用先验而非式(1)修正选择节点的隶属度,使节点更快地收敛到正确的隶属度,隶属度更新为γt, 基于式(2)和式(3)将模型参数更新为Θt.第t+1次迭代将以第t次的参数作为初始值,其对应似然收敛到更优,即Qt+1≥Qt. 因此,经过一定迭代次数可使算法收敛,后续实验中通过算法运行结果也可验证其收敛性.
3 实验及结果分析
选取不同结构的人工网络和真实网络数据集对ASonlineVEM算法进行测试,并与半监督社区发现SuperNMF和ALISE算法比较.其中,主动节点标记使用的约束对先验比例RP为网络节点对的百分比;网络节点对为n(n-1)/2,n为网络节点数.
使用如式(7)的标准化互信息[17](normalized mutual information, NMI)来衡量算法准确性.它可较好地评估基准标签与计算得到的标签之间的相互关系和吻合程度,常用来评价网络结构发现的质量.NMI值越接近1,表示算法聚类准确度越高.
(7)

算法使用Matlab 2014软件在Intel®CoreTMi5-6200U CPU,8 Gbyte内存的Windows 7(64 bit)计算机上运行.考虑到算法每次运行都存在差异性,取5次结果的均值作为实验结果.
基准网络 Girvan-Newman(GN)网络中,顶点与社团外顶点连边数的均值Zout决定社区结构的清晰程度,Zout越大,网络结构越复杂.图1分别为Zout=8和Zout=9时3种算法的NMI结果对比.可见,ASonlineVEM算法准确率明显高于其他网络,尤其当Zout=9时,RP=1.6%, ASonlineVEM算法准确率为0.92,ALISE算法仅0.33.随着Zout增加,对比算法准确率明显下降,ASonlineVEM准确率较高,说明后者能准确发现更复杂的网络结构.

图1 三种算法在GN网络上的NMI对比结果Fig.1 NMI comparison results of three algorithms on GN networks
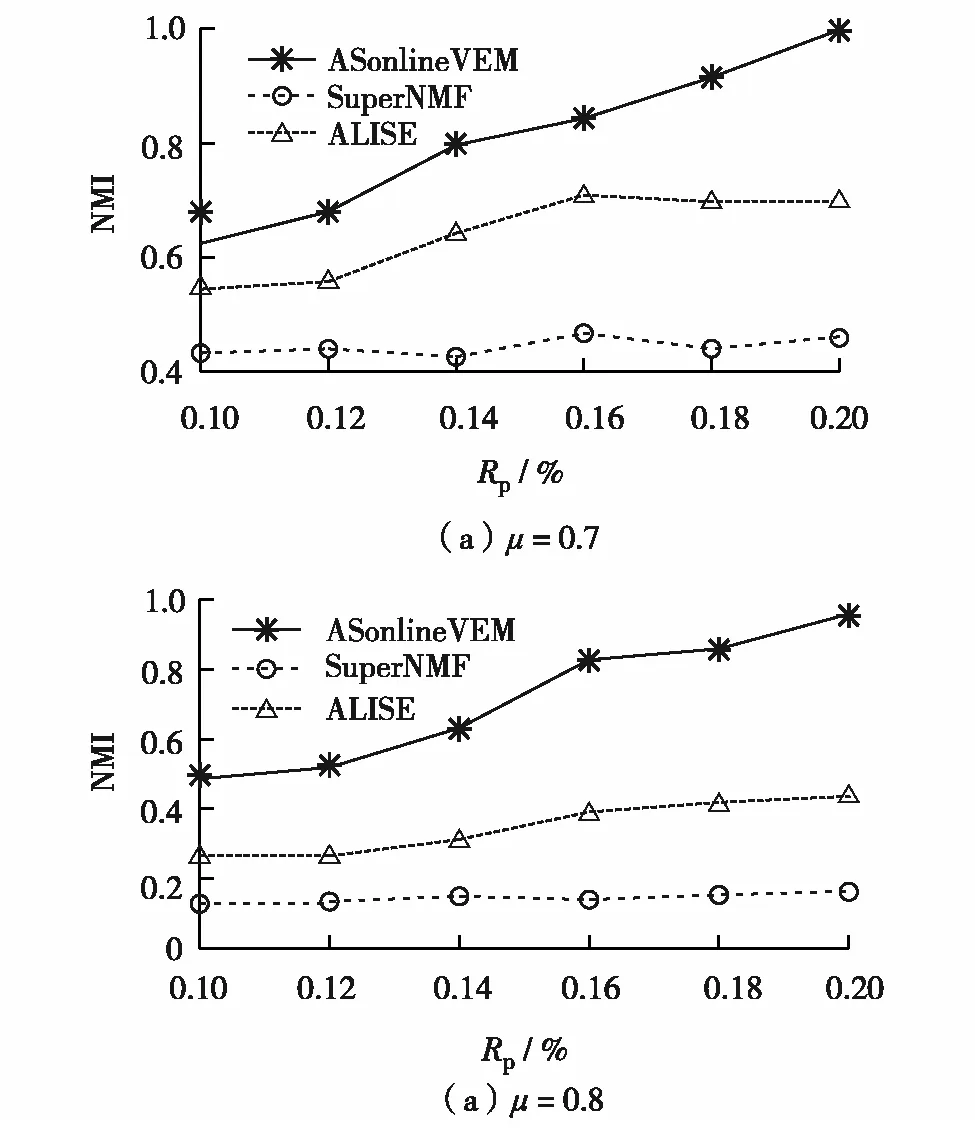
图2 三种算法在LFR网络的NMI对比结果Fig.2 NMI comparison results of three algorithms on LFR networks
Lancichinetti-Fortunato-Radicchi(LFR)基准网络结构比GN网络的更复杂.设网络节点数分别为1 000,最小和最大社区节点数分别为20和100,节点度分布参数为2,社区大小分布参数为1,混合参数μ决定了发现网络结构的难易程度,设μ为0.7和0.8.图2为在LFR基准网络上3种算法的NMI结果.由图2可见,ASonlineVEM算法的的准确率明显高于对比的半监督社区发现算法.综上可见,在具有社区结构的基准网络上,ASonlineVEM算法的社区发现准确率要高于对比算法,尤其在网络结构不清晰时更能体现算法的优势.
人工网络 采用ASonlineVEM、SuperNMF和ALISE算法对人工生成具有社区结构(network1)和二分结构(network2和network3)的网络进行实验,参数设置如表1.图3为3种算法在3个网络上的性能实验结果.由图3可见,在社区结构网络中,3种算法效果相当;而在二分结构网络中,相同先验比例下ASonlineVEM算法准确率高于对比算法.如在network2中,RP=0.12%时,ASonlineVEM算法的准确率约是对比算法的2倍.在人工网络上,ASonlineVEM的准确率高于对比算法.
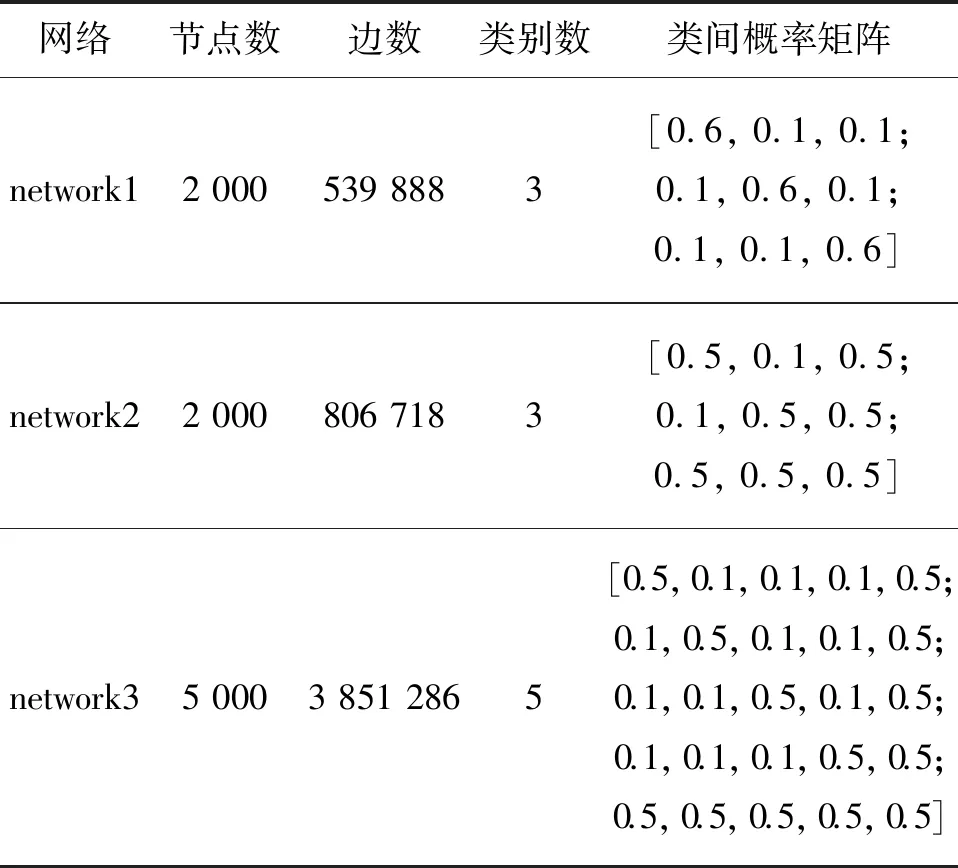
表1 人工网络数据集Table 1 Synthetic network dataset
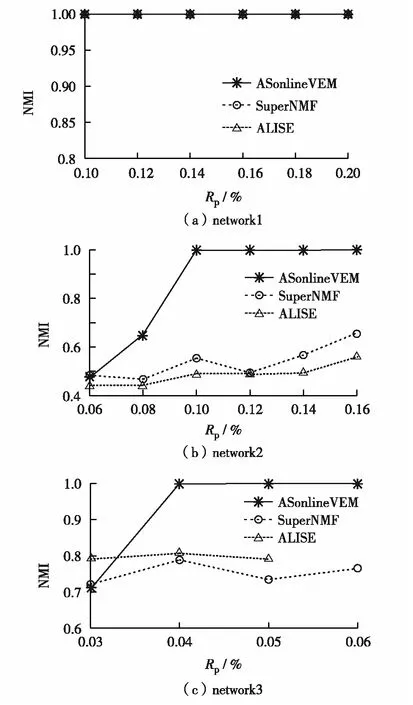
图3 三种算法在人工网络上的NMI对比结果Fig.3 NMI comparison results of three algorithms on synthetic networks
真实网络 本研究使用的真实网络数据集包括经典网络Dolphins、Football、Adjnoun和Friendship[18],以及Facebook网络Baylor、USC、Maryland和NYU[19].真实网络数据集合的具体参数请扫描论文末页右下角二维码见表S1.图4为分别采用ASonlineVEM、SuperNMF和ALISE算法在小规模经典网络数据集上测得的NMI结果.由图4可见,不同先验比例下ASonlineVEM算法性能均优于其他算法.

图4 三种算法在经典真实网络的NMI对比结果Fig.4 NMI comparison results of three algorithms on classic real networks
ASonlineVEM和ALISE算法都是基于迭代框架的主动半监督社区发现算法,图5为2种算法在真实大规模复杂网络Baylor和USC数据集上的NMI性能对比.由图5可见,在大规模复杂结构网络上,ASonlineVEM算法的准确性都优于ALISE算法.

图5 ASonlineVEM和ALISE算法在 Facebook网络上的NMI对比结果Fig.5 NMI comparison results of ASonlineVEM and ALISE algorithms on Facebook networks
对于具有社区结构的网络,ASonlineVEM算法初始通过主动策略选择代表节点进行标定,保证初始参数有较高的准确性,再利用代表节点的精确标定最大程度影响剩余节点.迭代过程主动选择不确定性且信息量大的节点进行标记,提高了算法发现网络结构的准确率.SuperNMF算法随机选择先验导致无法充分利用高质量先验信息.ALISE算法可发现社区网络的聚类结构,但非社区网络network2和network3的聚类结构属于二分结构,SuperNMF和ALISE算法主要处理的是社区结构发现问题,无法发现多类型网络聚类结构.
分析不同网络的准确率结果发现,随着先验比例的增加,ASonlineVEM算法较其他同类算法准确率更高、收敛速度更快、稳定性更佳,表明该算法效果均优于其他算法.
ASonlineVEM算法不仅能准确识别网络的聚类模式,还能高效处理不同规模网络.对于规模较小的基准网络,如Zout=9的GN网络,当Rp=2%时,ASonlineVEM、SuperNMF和ALISE算法运行时间t分别为0.258 7 、0.611 6和0.552 0 s.在网络节点较少的真实网络Football上,当Rp=14%时,ASonlineVEM、SuperNMF和ALISE算法的运行时间分别为0.185 4、0.364 0和4.296 4 s.可见,ASonlineVEM算法运行效率最高,其他小规模网络上也有相同运行结果.
针对节点较多或边数较多的大规模复杂网络,为简单起见,给出部分大规模网络上ASonlineVEM和ALISE算法的运行时间对比结果.network2和network3人工网络的时间对比结果如图6.图7为两种算法在Facebook数据集上数据传输一次所需要的时间对比结果.总的来说,在不同规模网络上,ASonlineVEM算法明显比ALISE算法高效.
ASonlineVEM算法在迭代过程中,对已标记类别信息的节点将不在后续算法中估计其类隶属度,只计算剩余节点的类隶属度,大幅节省了算法耗时. ALISE算法每次迭代选择网络中最不确定的链接进行人工标记,而大规模网络的边数往往远大于节点数,这使ALISE算法每次迭代计算边不确定性的复杂度较大,导致算法运行时间长.

图6 ASonlineVEM和ALISE算法在 人工网络上的运行时间对比Fig.6 Time comparison of ASonlineVEM and ALISE algorithms on synthetic networks

图7 ASonlineVEM和ALISE算法在 Facebook网络上运行时间对比Fig.7 Time comparison of ASonlineVEM and ALISE algorithms on Facebook networks
结 语
提出了主动半监督大规模网络结构发现算法ASonlineVEM,基于网络数据可快速且准确地识别潜在的多类型聚类结构,利用主动学习方法选择构造高质量先验提高了算法准确率,利用在线技术提高了算法运行效率,有利于在推荐系统和舆情分析中用户群体划分等领域的实际应用.但是,该算法目前主要针对的是静态大规模网络,如何实现动态大规模网络的结构发现算法以及在大数据平台下的大规模网络结构发现算法仍需深入研究.
