一种基于机器学习的车牌识别系统的设计
2020-05-22张明军俞文静李伟滨朱晓丹
张明军,俞文静,李伟滨,朱晓丹
(广州大学华软软件学院 网络技术系,广东 广州 510990)
0 引 言
智能交通系统(intelligent traffic system,ITS)是解决交通问题的一个重要手段,而车辆牌照识别(license plate recognition,LPR)技术在ITS中起着关键作用[1-2]。车辆牌照识别(简称车牌识别)系统能够对获得的车辆图像信息进行分析,自动定位出车辆牌照的位置,并识别出车牌号码。
车牌识别系统主要由两部分构成:车牌检测和车牌识别。车牌检测的任务是从采集的车辆图像中检测并提取车牌区域,主要包括车牌定位和车牌判断。车牌定位是从车辆图像中定位出候选车牌区域,其常见方法有如下几种:(1)基于边缘检测的车牌检测法,通过检测车牌的矩形区域定位候选车牌,但在垂直边缘交错的情况下往往定位不准[3];(2)基于颜色信息的车牌检测法,通过车牌颜色定位候选车牌,但在低照度、低对比度等情况下无法定位[4];(3)基于文字的车牌检测法,使用MSER(maximally stable extremal regions)算法[5]提取文字区域,然后使用种子生长法将这些图块连接起来,最终组合成候选车牌区域[6]。车牌判断是从定位的候选车牌区域中提取真实的车牌区域,常采用SVM(support vector machine)方法[7-9]。车牌识别的任务是从检测到的车牌区域中识别出车牌字符,主要包括字符分割和字符识别。字符分割是将字符从车牌区域图像中逐一分割提取出来,并按顺序排列,最常见的算法包括垂直投影法[10]和连通域搜索法[11-12]。字符识别是对已分割提取出的字符进行内容解析的过程,常见采用神经网络方法[9,13-14]。
随着计算机技术以及机器视觉技术的不断发展,车牌识别技术日趋成熟,大量运用于城市道路交通管理中。但由于特殊天气、光线和视角等各种不可控因素,车牌识别问题依然面临挑战[15-16]。文中以车牌识别的实用性为目的,设计了一种车牌识别系统。其中,首先设计了一种车牌定位方法选择候选车牌区域,然后采用SVM算法对候选车牌区域进行车牌判断;最后对车牌区域进行字符分割,采用改进的LeNet-5深度网络模型进行车牌字符识别。实验证明该系统具有较好的鲁棒性和识别准确率。
1 车牌检测
1.1 车牌检测思路
车牌定位综合边缘检测法和颜色定位法的优势,提出了Sobel-Color定位算法,以Sobel边缘和颜色两种特征进行车牌定位,提高了定位的准确率。同时,为了保证车牌定位的可靠性,在Sobel-Color定位的基础上,增加了MSER定位法,即经过Sobel-Color算法无法定位车牌则由MSER算法定位车牌。设计的车牌检测流程如图1所示。
1.2 Sobel-Color定位算法
Sobel-Color定位算法将Sobel边缘和颜色两个特征同时作为车牌的特征进行检测,具体算法步骤如下:
Step1:输入车辆图像I=(x1,x2,…,xn,…,xN)。
Step2:将I转化为灰度图像IGray和HSV图像IHSV。
Step3:对IGray进行Sobel运算,得到二值图像Gx=(g1,g2,…,gn,…,gN)。
Step4:读取IHSV的三个通道值,分别记作hi,si,vi,i=1,2,…,N。
Step5:若hi∈B或者hi∈Y,且s∈SX,v∈VX,则令xi=255,否则为0,得到二值图像KBY=(k1,k2,…,kn,…,kN)。

图1 车牌检测流程
Step6:将Gx与KBY合并成图像LB=(l1,l2,…,ln,…,lN)。合并规则如下:如果gi=255,且ki的八连通区域不为0的像素个数≥1,则li=255,否则li=0,i=1,2,…,N。
Step7:对LB进行形态学操作,轮廓检测,明显非车牌区域剔除。
Step8:依据LB中的候选区域坐标和大小,从I中截图候选车牌区域。
Sobel-Color算法中B为蓝色车牌色调值范围,Y为黄色车牌色调值范围,SX为车牌颜色的饱和度范围,VX为车牌颜色的亮度值范围,取经验值。
1.3 MSER定位算法
MSER算法是由Matas[5]提出,能够对一幅图像选择适当的阈值而得到连通分量,并对这些连通分量的平稳性进行检测获得最终的平稳区域。MSER获取区域如式(1)所示。
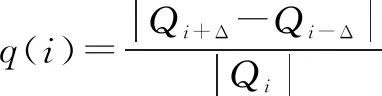
(1)
其中,Qi表示二值化阈值i对应的二值图像中某一连通区域,当二值化阈值由i变成i+Δ和i-Δ时,Δ为变化值,连通域Qi相应变成了Qi+Δ和Qi-Δ。当Qi面积随二值化阈值i变化而发生较小变化即q(i)为局部极小值时,Qi为最大稳定极值区域。
使用MSER算法进行车牌定位的步骤如下:
Step1:输入车辆图像I=(x1,x2,…,xn,…,xN)。
Step2:将I转化为灰度图像IGray+和反向灰度图像IGray-=255-IGray+。
Step3:分别对IGray+和IGray-执行MSER检测,记作MSER+和MSER-操作。
Step4:根据检测区域点生成MSER+图像IMSER+和MSER-图像IMSER-。
Step5:将IMSER+和IMSER-进行位与操作,生成图像IMSER。
Step6:对IMSER进行形态学操作,轮廓检测,明显非车牌区域剔除。
Step7:依据IMSER中的候选区域坐标和大小,从I中截图候选车牌区域。
1.4 基于SVM的车牌区域判断
支持向量机(support vector machine,SVM)[7]是一种基于统计学习理论的机器学习算法,具有较强的泛化能力。SVM的训练过程实际上等价于求解一个线性约束的二次规划问题,其目标是在训练样本集中寻找一个最优的超平面,将样本数据最大限度地分开,使两类数据之间的边界最大且分类误差最小,且能保证得到的解为全局最优解。
直方图特征的特征量丰富,适用于SVM分类,因此文中使用图像的直方图特征作为SVM的输入特征,分别在图像水平和垂直方向统计直方图。其中水平方向的特征维度为36,垂直方向的特征维度为136,输入的特征维度是172。使用SVM进行车牌区域判断的具体步骤如下:
Step1:输入候选车牌区域图像,并对其进行二值化处理。
Step2:统计图像中一行元素中为1的数目,输入图像共36行,得到36个数据。
Step3:统计图像中一列元素中为1的数目,输入图像有136列,得到136个数据。
Step4:将Step2与Step3得到的这些数据作为SVM的输入特征,输入特征维度为172。
SVM训练的数据集中正样本数量为1 400个,负样本数量为2 174个;测试集中正样本和负样本分别为1 400个。SVM使用OpenCV中的函数库,设置为径向基核函数,通过实验可知,该模型对于车牌区域的判别正确率达到0.999 7,满足本系统的需求。
2 车牌识别
2.1 车牌识别思路
车牌识别是从获取的车牌区域中识别出字符,首先需要进行字符分割,然后进行字符识别,其中字符识别采用卷积神经网络(CNN),流程如图2所示。
2.2 字符分割算法
车牌字符分割的步骤如下:
Step1:输入车牌区域图像P。
Step2:将图像P灰度化PGray。
Step3:使用OSTU算法[17]对PGray二值化。
Step4:取轮廓,选取每个字符轮廓,同时剔除虚假字符和去除铆钉。
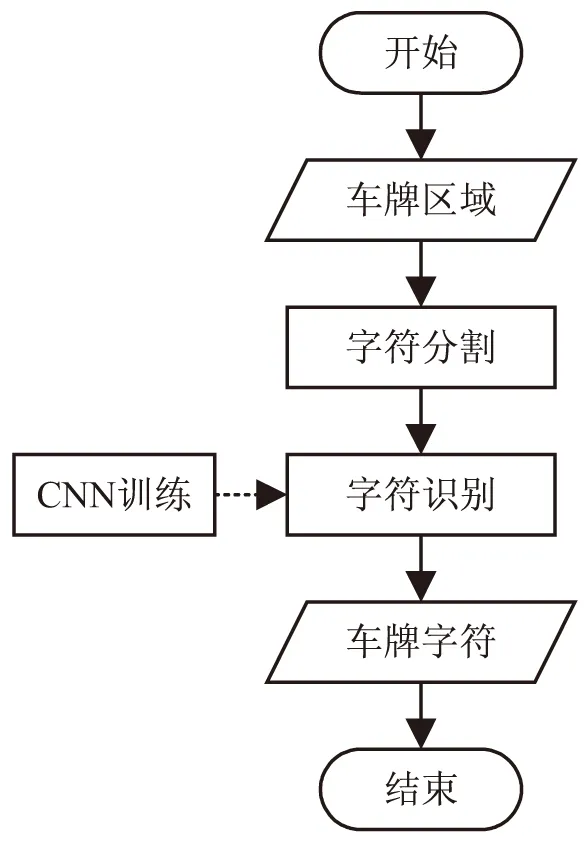
图2 车牌识别流程
Step5:截取每个字符图块,并归一化处理。
其中Step4和Step5的操作往往存在两个问题:(1)车牌的边缘部分往往存在虚假字符,难以剔除;(2)部分中文字符选取的轮廓并非一个整体,提取字符区域则不完整。解决思路主要是首先定位一个特殊字符,以第二个字符作为特殊字符,然后根据这个特殊字符来定位其他字符,具体方法如下:
(1)在Step4中统计每个字符轮廓外接矩形的高H和宽W,并进行比较,获取最大的H和W,记作(Hmax,Wmax)。
(2)对所有字符矩形进行判断,如果满足其高度和宽度分别大于0.8Hmax和0.8Wmax,且其距离车牌左边缘为1/7至2/7倍车牌宽度之间,将此字符作为特殊字符,即车牌里的城市代码字符,其坐标和尺寸分别记作(xs,ys),(Hs,Ws)。
(3)以特殊字符作为基准,则可定位前面的中文字符,即车牌里的省份简称。定位方法为:中文字符矩形的坐标为(xp,yp)=(xs-1.32Ws,ys),中文字符矩形的尺寸为(Hp,Wp)=(Hs,1.15Ws)。
(4)同步骤(3),定位特殊字符的后续字符,并可删除这几个字符之外的其他虚假字符。至此,完成字符分割。
2.3 基于CNN的车牌字符识别
对车牌字符识别采用LeNet-5网络。LeNet-5网络[18]是一种简单但经典的卷积神经网络(CNN)模型,主要用于手写数字识别,网络结构由7层组成,每层包含训练参数,7层主要包含卷积层、池化层、全连接层3种连接方式。
由于LeNet-5网络输出类别数目为10,而中国车牌包括10个数字之外,还包括24个英文大写字母(字母I和O除外),31个省市简称的汉字(不包括港澳台)。因此需要对LeNet-5进行改进,具体如下:
(1)改进输出层。车牌的字符数一共65个,但考虑汉字与数字或字母有较大出入,因此设计两个分类器,一个用于汉字分类,则改进输出层的单元数为31个;另一个用于数字和字母分类,则改进输出层的单元数为34个。
(2)调整特征平面数。由于模型的识别数量修改为31和34,比原来模型的输出类别大,而且有较为复杂的汉字识别,为了更全面地提取图像特征,需要调整一些层的特征平面的数量。因此,将C1层和S2层的特征平面的数量由6个增加到24个,将C3和S4层的特征平面的数量由16个增加到52个,将C5层的特征平面的数量由120个增加到480个。调整各层参数,将对输出的结果产生影响。
3 系统测试与分析
设计的车牌识别系统的实现平台为Windows 10,Visual C++和OpenCV3,界面采用QT设计,字符训练和识别部分采用Tensorflow+Python3.6。为了验证系统的有效性,首先从网络上收集了大量车牌,制作了车牌字符数据集,数量约为16 000个,并归一化为32×32大小。同时,收集了大量真实车牌用于测试。设计实验如下:
(1)正常条件下的单幅车牌图像识别实验,目的在于测试系统对车牌字符识别的准确性。部分测试结果如图3(a)~3(d)所示。测试了多个城市的车牌图像共172个,正确率100%,其主要原因有:一是采集的车牌图像分辨率较高,且角度、距离以及图像光线等都比较理想;二是测试图像并未全部覆盖全国各个省份,测试样本量不够大。

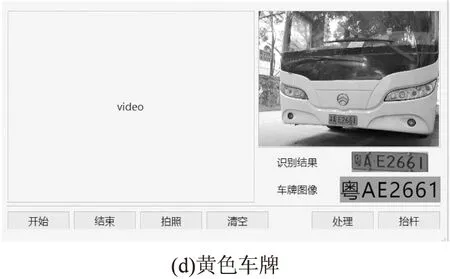
图3 正常条件下的单幅车牌图像识别实验结果
(2)恶劣条件下的单幅车牌图像识别实验,目的在于测试系统在恶劣条件下的性能。文中测试的恶劣条件主要包括:大角度成像、雨天成像、夜晚成像、雾天成像等,测试结果如图4(a)~4(d)所示。一共测试了21个恶劣条件下的图像,识别错误为2个,正确率为90.5%。由此表明,该系统在恶劣条件下依然能够准确定位车牌,并具有较好的识别率。
(3)单幅车牌图像识别速率实验,目的在于测试系统的识别效率。选取单幅车牌图像共100个,分为三组多批次进行测试,统计识别速率的结果如表1所示。

表1 单幅车牌图像识别速率实验结果
由表1可知,车牌识别速率较快,系统具有较好的效率,能满足系统实用性的目的。选取的车牌图像分辨率较高,数据量则较大,因此系统的初始化处理以及识别过程中的相关处理所花时间较多。如果还需要提高系统的识别效率,可以适当降低车牌图像的分辨率。
4 结束语
以车牌识别的实用性为目的,设计了一种鲁棒的车牌识别系统,在各种环境干扰的情况下也具有较好效果,识别率高于90%。提出了一种有效的车牌定位方法,并采用SVM进行车牌检测,提高了车牌检测的准确率;提出了一种车牌字符分割策略,并针对车牌字符识别的需求改进了LeNet-5深度网络模型,提高了字符识别的准确率。但该系统在新能源车牌、双行分布的车牌、军警车牌等特殊车牌识别上仍需进一步完善。
