基于子图相交的社交账号与知识图谱实体对齐
2020-05-22刘家祝吴碧伟曾明勇
刘家祝,郭 强,吴碧伟,曾明勇
(江南计算技术研究所,江苏 无锡 214085)
0 引 言
随着互联网基础设施的完善和移动互联网设备的普及,社交媒体越来越深入社会生活的方方面面。特别是对于公众人物和组织,社交媒体是他们与外界保持信息流通的重要媒介。社交媒体的数据具有实时性高,非结构化等特点。知识图谱的概念是由Google公司在2012年提出[1],是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化描述。知识图谱的数据具有实时性较差[2]、准确度高[3]等特点。
社交媒体和知识图谱互相利用对方数据的特点,将对知识图谱扩充与社交网络分析等领域产生积极的促进作用,而社交账号与知识图谱实体对齐是联通二者的桥梁。文中研究的目的在于将社交账号当作一种实体,利用社交账号相关信息和知识图谱实体相关知识,研究社交账号与知识图谱实体的链接技术,将社交账号与知识图谱中正确的实体链接起来。
为了对齐账号与实体,提出的方法分为两个步骤:候选实体集生成与目标实体选择。图1给出了一个对齐过程的示例。

图1 Twitter账号与Wikidata对齐
在候选实体生成步骤中,利用知识库提供的搜索服务,在不同的搜索策略下构建候选实体集。在目标实体选择步骤中,提出了一种子图相交算法,旨在利用从社交媒体账户中提取的社交关系,通过搜索服务映射到知识图谱中,形成知识图谱的子图,利用子图存在的相关特性来选择目标实体。
1 相关工作
社交账号与知识图谱实体的对齐问题是近年来在知识图谱研究领域的热点问题。2017年Trendo大学的Nechaev Y等人[4]首次提出该问题,他们研究了Twitter账号与DBpedia之间的链接问题,基于监督学习给出了初步解决方案并提出了SocialLink问题,指出跨社交网站的账号链接是其中的难点和重点。文献[5]提出了对SocialLink问题的改进,引入了Social Embedding的概念,与知识图谱中的RDF graph embedding方法配合使用,以提高对齐问题的评估指标。
实体链接是指将文本中的实体提及(entity mention)链向知识图谱实体的过程[6]。文献[7]研究了不同策略在候选实体集构建过程中的作用。文中研究的问题是将社交账号链向知识图谱实体,故实体链接问题在实体链接研究框架、实体链接步骤及各阶段所采用的技术方法等方面[8]对本课题具有较强的参考意义。
Usbeck R等人[9]发布的AGDISTIS系统试图利用构建知识图谱中的子图的方式,完成批量的实体链接工作。在目标实体选择阶段,他们采用HITS(hyperlink-induced topic search)[10]或PageRank[11]算法,选取重要程度最高的实体为目标实体。AGDISTIS系统在本课题的数据集上取得了0.537左右的准确率。链接效果不理想的原因在于HITS算法依赖于子图中候选实体节点的入度,但这一特征在Wikidata实体中不明显。该系统的子图构建方法对本课题具有一定的参考价值。
由于社交媒体通常严密防范网络爬虫,同时提供的API也有严格的限制[12],获取社交账号的社交关系并不容易。文献[13]收集了一个小规模的社交图数据集,并证明它可以有效地改善社交账号对齐的结果。知识图谱中的实体通常包含指向其他实体的链接,这些实体可以被看作一种社交关系图。
2 问题定义与方法
文中研究的目的是针对给定的Twitter账号t,在知识图谱KG中找出对应的实体et,这里的知识图谱特指Wikidata[14]。令集合C为账号t在KG中生成的候选实体集,C={c1,c2,…,cn},函数φ为根据账号t在知识图谱KG中生成的候选实体集,函数ψ为计算候选实体ci为正确实体的可能性,链接过程可以形式化地描述为如下两个部分:
(1)候选实体集生成:C=φ(t,KG,Tr),其中Tr为搜索策略集。
2.1 候选实体集生成
为了能够正确地将Twitter账号与知识图谱实体对齐,首先需要根据账号信息生成包含正确命名实体的候选实体集C。这里利用Wikidata提供的搜索服务生成候选实体集。
Wikidata搜索页面提供关键词搜索服务,能够对实体条目的标题和内容进行搜索。使用搜索页面生成候选实体集的关键在于提供合理的搜索关键词:既能生成包含目标实体的候选实体集,又能减少候选实体集实体数量。根据这一目的,测试了三种搜索策略:
用户名策略(Suser):使用Twitter账号的用户名。用户名为社交网络用户自行设置的字符串,可以更改或重复,国内社交媒体一般称为“昵称”。这个策略中使用原始的用户名作为搜索关键词。
用户名去符号策略(Sremove):由于用户名为用户自行设置的字符串,用户名中可能包含标点符号或者图像符号。这个策略将除空格与文字字符以外的所有符号去掉。
用户名分割策略(Ssplit):这个策略以策略Sremove中产生的字符串为基础,以空格为分割符,将用户名分割为多个不同的搜索关键词,将多个关键词的搜索结果合并以产生候选实体集。
表1给出了一个搜索策略的示例。对于这些策略,可以将多个策略联合使用,即对于某个目标账号,将多条策略生成的多个候选实体集取并集,生成最终候选实体集。这里没有使用Twitter账号中更多的信息构造搜索策略,如描述、推文等,因为Wikidata的搜索服务对于长字符串的处理并不理想。最后对每一次搜索服务的返回结果取前k个,构成最终候选实体集。

表1 搜索策略示例
2.2 目标实体选择
在产生候选实体集以后,需要采用一定的方法计算候选实体为目标实体的可能性,选择最有可能的候选实体作为目标实体。这里对三种算法进行实验,分别为标题匹配算法、AGDISTIS算法、子图相交算法。
2.2.1 标题匹配算法
标题匹配法以Twitter账号用户名与候选实体标题字符串的相似度为选择标准,选择第一个与Twitter账号用户名完全相同的候选实体为目标实体。
2.2.2 AGDISTIS算法
AGDISTIS算法[9]是一种基于图的实体链接方法。该方法利用目标实体提及(entity mention)与上下文中的实体提及,在知识图谱中生成有向子图,以HITS(hyperlink-induced topic search)[10]或PageRank[11]算法计算图中顶点的重要程度,选择重要程度最高的顶点作为预测的目标实体。
在该实验中,将目标账号中存在的社交关系视为上下文实体提及用于生成子图。AGDISTIS方法生成子图的过程,是提出子图相交算法的基础。
2.2.3 子图相交算法
文中在AGDISTIS算法[9]的基础上提出了子图相交算法。AGDISTIS算法在目标实体选择阶段使用的HITS[10]或PageRank[11]算法,其权值的计算依赖于候选实体节点的入度。但是在知识图谱的结构中,发现大量的候选实体入度为0,进而导致权值计算结果为0。基于这样的观察,引入了基于子图相交来衡量节点重要程度的算法。
首先从给定社交账号t的社交关系中涉及的相关账号生成扩展实体集CE,CE中的元素为知识图谱中的实体条目。这里提取了Twitter页面中出现的转发(retweet)、提及(mention)、引用(quote)以及关注(following)中的用户作为账号t的相关账号集RA={ra0,ra1,…,ran},取RA的前m个账户生成CE:
(1)
针对候选实体集C中的每个实体ci,生成一个搜索深度为d的扩展图Gci。在这里将知识图谱KG认为是一个有向图GKG=(VKG,EKG),其中,顶点V是KG中的实体,边E为KG中的关系,那么x,y∈V,(x,y)∈E↔∃p:(x,p,y)为KG中的一个RDF三元组。
扩展图Gci的建立从初始化G0=(V0,E0)开始,其中V0为{ci},E0为空,然后采用广度优先搜索扩展G0。定义扩展操作为ρ,第i步扩展结果为Gi=(Vi,Ei),i=1,2,…,d,扩展过程为:
Gi+1=ρ(Gi)=(Vi+1,Ei+1)
(2)
Vi+1=Vi∪{y:∃x∈Vi∧(x,y)∈EKG}
(3)
Ei+1={(x,y)∈EKG:x,y∈Vi+1}
(4)
对G0执行d次ρ操作即得到扩展图Gci。取每个扩展图Gci的顶点集Vci,令交集元素个数:
ici=|Vci∩CE|
(5)
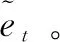
算法过程描述如下:
算法:子图相交算法。
输入:目标账号t;候选实体集C;搜索结果保留数k;相关账号保留数m;图搜索深度d;知识图谱KG;搜索策略集Tr;
步骤:
1.CE←∅
2.RA←getRelateAccount(t,m)
3.FORrai∈RA
4.CE←CE∪KGSearchService(rai,Tr,k,KG)
5.END FOR
7.ic←0
8.FORci∈C
9.G←breadthFirstSearch(ci,d,KG)
10.V←getVertexesFromGraph(G)
11.tc←|V∩CE|
12.IF tc≥ic THEN
14.ic←tc
15.END IF
16.END FOR
3 实验与分析
无论是社交网络分析还是基于知识图谱的实体链接工作,先前的研究者们已经发布了大量的数据集用于研究和测试。文中研究内容为Twitter账号与Wikidata[14]知识图谱实体的对齐工作,无法直接使用这些先前发布的数据集。因此将使用自行构造的数据集对文中方法进行测试和评估。
实体对齐旨在从候选实体集中选择最有可能的实体作为目标实体,故最终的结果只有“成功”或“失败”两种结果。因此,文中衡量算法性能的指标为准确率(Accuracy)。在2.2.1中提到的标题匹配算法将作为本次实验的基准算法。这个算法实际上是利用Wikidata自身搜索服务来实现Twitter账号实体的对齐。
评估将分为三个部分进行。首先对候选实体集生成部分与目标实体选择部分分开评估,然后对总体方法进行评估。
3.1 实验数据
针对文中提出的研究工作,需要一批特殊的Twitter账号,这些账号在Wikidata中存在相应的实体。同时需要这些Twitter账号的基本信息,如账号名、昵称等。由于文中方法主要从Twitter用户的社交关系入手,所以Twitter账号发表的推文以及关注的账号也是需要的信息。
文中研究所涉及的知识图谱Wikidata由维基媒体德国分会首先提出[14]。为了完成数据集的构造,首先通过Wikidata Query Service,利用SPARQL[15]语言获取了3 024条具有Twitter账号的Wikidata实体,其中包含1 379个人物账号,1 645个组织账号。
获取的结果格式如表2所示,其中Item为Wikidata中的实体链接,ItemLable为Wikidata中的实体标签,Twitter为实体所对应的Twitter账号名。根据Twitter账号名,利用网络爬虫技术[16-17],爬取相关账号的基本信息、推文及关注账号列表。

表2 Wikidata Query Service结果示例
为了保证能够获取较为可靠的社交关系,去除了推文总数在300条以下且关注总数在100以下的账号,最终保留账号2 281个,其中人物账号1 086个,组织账号1 195个。表3列出了推文和关注相关的统计信息,平均推文数6 129.63条,关注账号数2 937.66个。

表3 Twitter账号数据统计
3.2 候选实体集生成
在实验数据集上对搜索策略逐条进行评估。评估针对Twitter账号类型按照人员、组织和综合(人员+组织)分为三大类。评估的指标为:
(1)候选实体集大小均值(average number of candidate entities,ACE):候选实体集元素个数的平均数量。
(2)非空率(non-empty rate,NER):候选实体集不为空的比率。
(3)覆盖率(coverage rate,CR):在候选实体集中包含目标实体的比率。
在评估候选实体集生成性能之前,需要确定搜索结果保留数k。图2描述了三种搜索策略在测试数据集上的性能表现。为了保证目标实体覆盖率与候选实体集大小之间的平衡,最终选择k=5。

图2 k取值与覆盖率的关系
表4显示了针对不同搜索策略的实验结果。可以看出Sremove相对于Suser虽然去除了非文字符号,但是性能并没有提升。Ssplit对于单个Twitter账号来说增加了搜索次数,提高了候选实体集非空率(NER),但是字符分割带来的语义破坏,影响了目标实体覆盖率(CR)。最终选择使用Suser策略。

表4 搜索策略实验结果
3.3 目标实体选择
目标实体选择部分的评估将在包含正确目标实体的候选实体集中进行,候选实体集的生成策略采用Suser。将对三种方法在实验数据集上的准确率进行计算,三种方法分别为:标题匹配算法(Atitle)、AGDISTIS算法[9](AHITS)和子图相交算法(Asubg)。
AGDISTIS算法在构建子图时使用的宽度优先搜索深度(d)为2[9]。子图相交算法在构建子图时,基于子图规模与算法运行时间的平衡,选择宽度优先搜索深度(d)为3;保留了爬取数据中所有的相关账号,平均个数为311.788。
表5显示了不同方法针对实验数据集中不同类型数据的准确率。可以看出,子图相交算法在针对人员类型账号数据时,相对于其他两种方法性能较好,但是对于组织类型账号数据性能弱于AGDISTIS算法。这样的差别在于,在知识图谱中,组织类型的实体往往有多条相关的实体[18]。特别是对于Wikidata这类由社区众筹维护的知识图谱来说,针对某个组织往往存在多个实体。
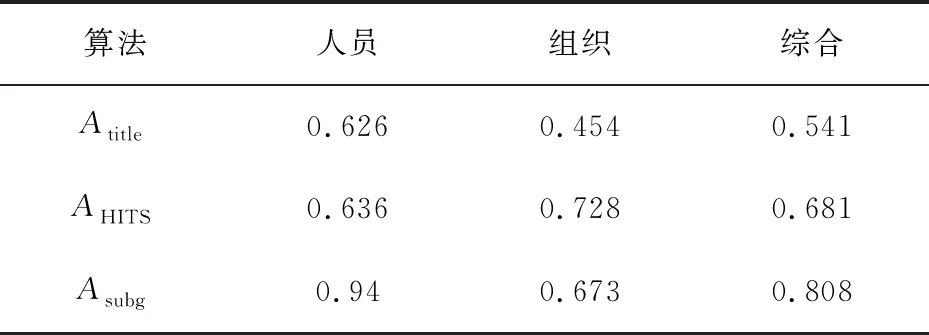
表5 目标实体选择实验结果
子图相交算法使用相交子图的顶点个数—ic值作为目标实体的选择依据。这一简单的指标在实验中取得了最高0.94的准确率。表6显示了目标实体与非目标实体之间平均相交子图顶点数值(ic)上的对比。
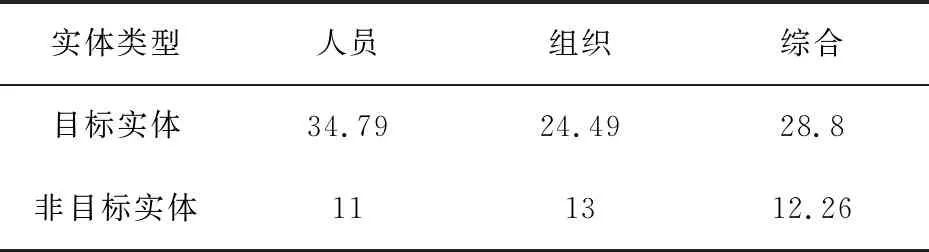
表6 目标实体与非目标实体的平均ic值对比
从表6可以看出,目标实体与非目标实体在平均ic值上具有较大的差异。这充分显示了社交账号中的社交关系映射到知识图谱中形成的子图,在结构上呈现出了聚集的特性,在正确的候选实体附近较为“稠密”,ic值为描述这一结构特性较为直观的指标。
3.4 总体方法
总体评估针对整个数据集,对于候选实体集为空的数据将标记为对齐失败。表7显示了三种方法的总体评估结果。
从表中可以看出,总体性能相对目标实体选择部分有很大下降,这主要是由候选实体集生成部分目标实体覆盖率(HTVC)引起的。对于未包含正确实体的候选实体集,目标实体选择算法是无法找到正确对齐实体的。总体性能特点与目标实体选择部分类似,组织类型数据对齐正确率较低,子图相交算法取得了最好的综合性能。
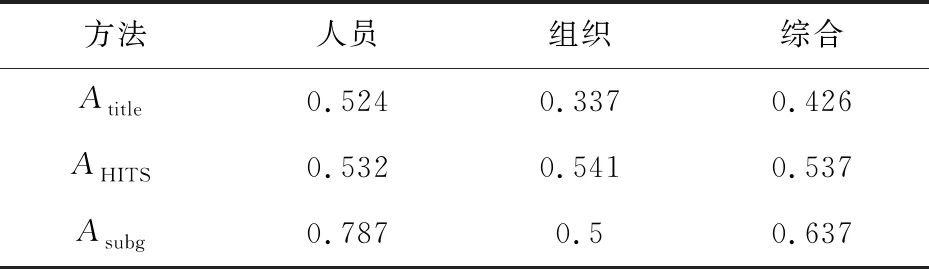
表7 总体方法实验结果
4 结束语
提出了一种将社交账号与知识图谱实体进行对齐的算法—子图相交算法。算法通过将目标账号的社交关系图映射到知识图谱中形成子图,以衡量候选实体所在子图位置的实体聚集程度,来选择目标实体。该研究揭示了基于社交关系映射的知识图谱子图,在目标实体“附近”存在聚集特性,利用这一特性预测目标实体取得了较高的准确率。
通过Wikidata提供的搜索服务构建了用于测试和评估的对齐数据集,文中方法在该数据集上实现了0.637的准确率。
子图相交算法所利用的社交媒体的社交关系图以及知识图谱的图结构等信息,是普遍存在于社交媒体和知识图谱中的。所以该对齐方法可以应用于其他的社交媒体和知识图谱。
下一步的工作可以从三个方面开展。首先是增加方法对不存在目标实体的空链接(NIL)项的处理功能,可以考虑引入更多的特征,采用机器学习方法,设计一个基于监督方法的实体对齐系统。
其次是将映射子图的聚集特性应用于更多的领域,例如其他社交媒体的实体链接、社群分析、话题识别等方面。最后是扩充数据集,添加更多职业和类别的账号,同时加入NIL类账号用于机器学习算法的训练和测试。
