科研论文爬取与多维度分析系统的设计与实现
2020-05-22王树梅尚衍亮
王树梅,尚衍亮
(江苏师范大学 计算机科学与技术学院,江苏 徐州 222111)
0 引 言
随着信息时代的到来,知网成为国内最大的论文数据库,如何高效地获取论文信息,挖掘论文价值,成为了一个亟待解决的问题。为了解决该问题,人们开始尝试应用网络爬虫来获取信息。网络爬虫(web spiders)是模拟用户在浏览器上的操作,从特定网站,自动提取对自己有价值的信息的脚本程序。目前,主要使用Python进行网络爬虫[1]编写。网络爬虫大致可分为以下几种类型:普通网络爬虫、聚焦网络爬虫、增量网络爬虫和深网络爬虫[2-4]。当爬虫爬取网页时,解析出链接资源的超链接,并将这些超链接放入“待爬取队列”,然后按照一定的顺序进行数据爬取,如果在爬取的过程中遇到错误,爬虫会跳过该超链接,进行下一个超链接的爬取。如果信息需要存储的话,可以选择将信息保存到文档中,也可以保存到数据库中[5]。
科研能力不仅体现了一个科研人员的学术修养,更是体现高校办学实力的核心指标。近几年,高校的科研能力不断加强,但是因为发展的原因,各高校的科研能力也参差不齐。同样,对于个人来说,也存在着较大的差距。知网作为一个最大的数字图书馆,为全社会的专家学者提供论文资源和最专业的学习平台。目前知网存储着大量的学术论文和学者信息,因此,该系统使用爬虫技术对知网进行爬取,爬取与个人和学校科研能力相关的评价指标,如论文数、论文被引用量等,然后清洗整理,多维度分析论文数据,直观地展示个人及学校的科研能力。整个系统最终以Web网站呈现,用户只需输入相应的关键字,即可看到分析结果。
目前,越来越多的学者开始认识到知网数据的价值,如胡冬妮等[6]分析了知网的841篇论文,总结国内情感识别的发展脉络,指出国内情感识别的研究重点及趋势。游涛等[7]借助中国知网的数据, 对本校的论文发表总量、年论文发表趋势、论文总被引次数、论文总下载次数等数据进行分析,并与其他高校进行对比分析,最后对高校的科研能力进行评价。潘惠梅等[8]通过手工方式获取2017年以来知网收录于地理教学相关的论文数据,利用Bicomb 2.0和SPSS 20.0软件对高频关键词进行聚类与可视化分析,对2017的地理教学知识进行回顾,通过对知网的数据分析来指导教学。李智超等[9]以中国知网的论文数据为基础,检索鸡传染性支气管病毒混合感染案例,对混感临床案例的地区分布、发病鸡品种和鸡传染性支气管炎病毒混合感染疾病类型进行分析。
根据上面的分析可以得出,知网论文的价值受到了越来越多人的关注。但是由于缺乏技术上的支持,大部分针对知网数据的分析仍然停留在手工阶段[10-13],手工获取知网论文数据,格式化数据,最后使用相关的分析工具进行分析。这种方式虽然可以操作,但是耗时耗力且分析的效果较差。因此,该课题拟设计出一套集网络爬虫和多维度分析为一体的系统。该系统可以代替手工方式获取论文信息,专家学者只需要输入相关的关键词,即可得到分析结果,从而节省了人力和时间。
1 系统的功能需求分析
1.1 系统的功能需求
(1)在线论文爬取模块。
该模块模拟浏览器操作,根据用户所需的关键词,爬取论文列表页,获取论文标题、论文链接、论文发表时间、论文来源和论文作者等信息,最后将数据存入数据库。根据获取到的论文链接来爬取论文详细页面,得到论文的详细信息,并实时存入MySQL数据库[14]。爬取模块同时提供爬虫状态展示,向用户展示实时爬取的论文列表。
(2)多维度分析模块。
该模块清洗整理论文信息后进行多维度分析,包括年论文发表数量走势、高产作者展示、高产机构展示、基金占比等,同时给出单篇论文的作者关系图和单篇论文的详细信息。
1.2 系统的用例图
该系统的用例图如图1所示。
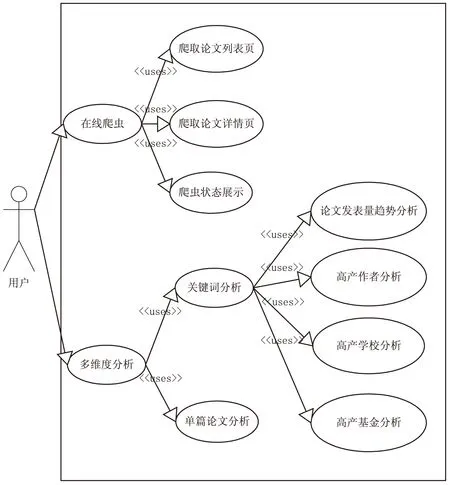
图1 系统用例图
系统共两大部分:在线论文爬取系统和多维度分析系统。
(1)在线论文爬取系统分为论文列表页爬取和详情页爬取。论文列表页用来爬取论文的列表页,获取论文标题,论文链接,论文发表时间,论文数据库,论文作者等信息。列表页主要用来获取论文的详细信息。同时提供实时爬取状态展示。本系统将爬虫内置到网页当中,实现可视化操作,一键爬取。
(2)多维度分析系统,使用HightCharts和Echarts进行数据的多维度分析。其中HighCharts用来制作年论文发表数量走势折线图、高产作者柱状图、高产机构展示柱状图、基金占比柱状图和单篇论文作者关系图。
2 系统实现过程
(1)在线论文爬取模块。
如图2所示,论文爬取主要分为两部分,第一步使用Selenium获取Cookies[15],然后使用Requests和BeautifulSoup4进行列表页的快速爬取,爬取完成后将列表页的论文信息存入数据库。第二步从数据库中获取论文的链接,使用之前获取的Cookies进行快速的爬取,并将数据存入数据库。

图2 爬取模块结构
(2)多维度分析模块。
如图3所示,系统主要由首页、热门分析页面、在线爬虫页面、数据图表展示页、单篇论文详情页面、爬虫状态页面这六个页面构成。

图3 多维度分析模块
·首页用来介绍本网站,包括系统所提供的功能,并提供在线联系。
·热门分析页面用来展示用户关键词查询次数汇总排行。
·在线爬虫页面启动爬虫,并给出使用步骤。
·数据图表展示页面主要提供了对该关键词的数据分析展示。
·单篇论文详情页面主要展示了单篇论文的作者关联信息以及论文的详细信息。
·爬虫状态页面主要展示了当前爬虫抓取的论文,并提供论文链接跳转到单篇论文详情页。
(3)数据库设计。
通过对系统的需求分析得出系统中包含了作者、论文、基金、年份、关键词和学校等实体。
系统的所有数据表主外键关联关系具体如图4所示。

图4 主外键关联关系
3 论文爬取结果
(1)论文爬取步骤。
①输入关键词:在输入框内输入你要抓取的相关的关键字,例如大数据,然后回车或者点击开启爬虫按钮。
②点击数据分析:等待数据爬取结束之后可以点击进入实时数据分析界面,当然也可以跳过前面的两步,直接进入实时分析界面,选择系统提供的数据。
③等待数据爬取:提示爬虫已经启动,然后等待10秒钟,等待系统连接到知网,此时可以实现查看爬取的进度和爬取的相关论文。
④数据下载:本系统支持原始数据的下载,可以将图表以图片的形式下载,当然也可以选择导出原始数据并进行下载。
图5为输入关键字“大数据”后爬取的论文结果列表。
(2)多维度分析结果。
对爬取的数据进行多维度分析,包括论文年发表数量、高产作者、高产量机构、基金占比。

图5 爬取结果
图6(a)是对2005年至2019年CNKI网站上发表的以“大数据”为关键字的论文的统计数据,从数据折线图上来看,发表论文数量呈递增趋势。图6(b)是通过关键字“大数据”爬取的作者发表论文数量排名,本校杨现民教授排名第五。图6(c)通过关键字“大数据”爬取的科研机构发表论文数量排名,可以看出武汉大学在大数据研究方面取得的成果较多。图6(d)为通过关键字“大数据”爬取的基金论文发表数量,可以看出基于国家自然科学基金发表论文最多高达3 486篇。图7展示了作者关系,通过合作关系,可以找出作者之间的关联状态。图8是爬取的论文详细信息,包括论文来源、作者、发表期刊以及摘要。

(a)论文年发表数量统计 (b)作者论文发表数量统计
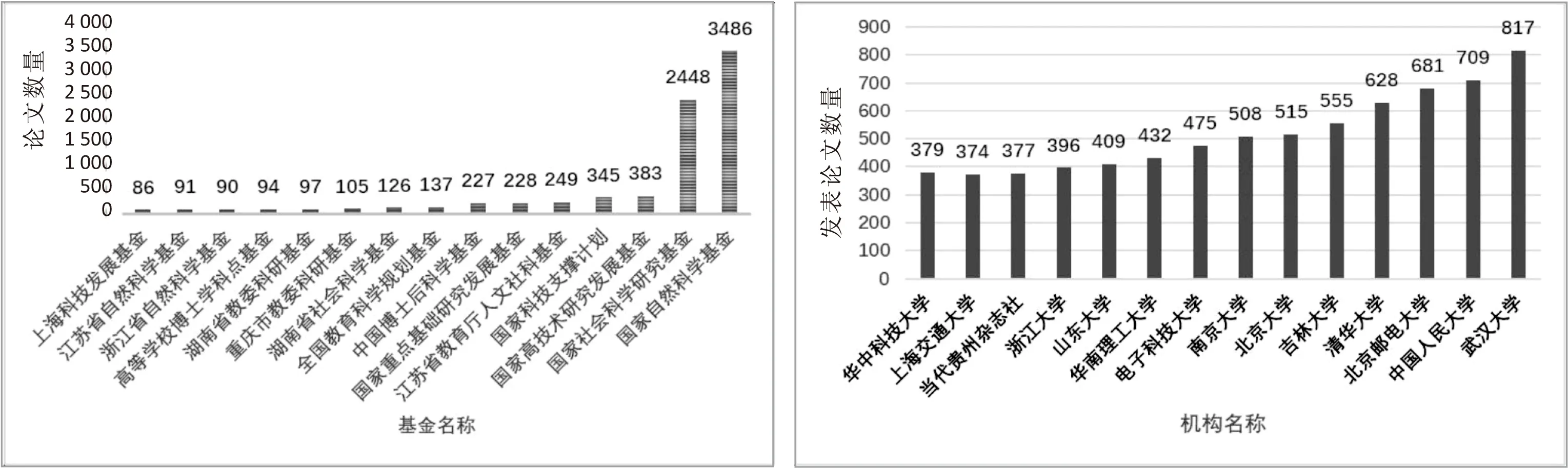
(c)机构论文年发表数量统计 (d)基金发表论文数量

图7 作者关系

图8 论文详细信息
4 结束语
系统的设计与实现过程中,利用了Python和Django技术、MySQL技术,为系统的开发提供了技术支持。该系统开发过程主要包括:需求分析,概要设计,详细设计,概要等步骤。系统将爬虫内置在网页中,使得爬虫简单易用。
科研论文爬取与多维度分析系统在实际开发中涉及到许多方法和技术,该系统在以后的实际应用中还需要不断的更新完善。比如监督策略、反爬虫策略,加强爬虫的健壮性。网络爬虫将采用分布式爬取,提高爬虫的速度,增加目标网站的数量。多维度分析模块要实现用户定制化分析,分析范围扩大到论文的内容,结合NLP技术对论文内容进行分析,挖掘论文内容的价值。
