关于常用字覆盖率统计算法的研究
2020-05-22阿不都克里木玉素甫王亮亮
阿不都克里木·玉素甫,杨 琴,王亮亮
(1.新疆教育学院 现代教育技术中心,新疆 乌鲁木齐 830043;2.新疆教育云技术与资源实验室,新疆 乌鲁木齐 830043;3.新疆教育学院 信息科学与技术学院,新疆 乌鲁木齐 830043)
0 引 言
常用字是现代汉语中经常用到的字,即字频和使用度最高的字。随着社会的发展,常用字的使用频率也在不断的变化。而常用字最基本的选字原则就是根据字的使用频度,选取使用频度高的字。除此之外还有其他的选字原则,如:根据字的使用分布选取分布均匀的字,选取构字能力和构词能力强的字,根据汉字的实际使用情况斟酌取舍等。目前计算机选字主要采用统计字频的方法,并以字频高低逐一排序。字频指的是汉字的使用频率,即某个汉字在抽样统计资料里出现的次数在统计总字数中所占的比例。字频统计对识字教学、字书编纂以及汉字的机械处理和信息处理等都十分重要。1988年1月,国家语委和国家教委联合发布《现代汉语常用字表》[1],共收录常用字3 500个,其中常用字2 500个,次常用字1 000个。1988年3月发布《现代汉语通用字表》[1]共收录通用字7 000个(包括《现代汉语常用字表》的3 500字),这两种表都是以字频的高低来排序的。为了了解常用字在文本中的使用情况,以计算机信息处理的方式来获取统计信息,并且本研究作为新疆高校教育资源安全审查信息化系统研究项目的基础研究部分,主要研究了常用字在电子文本中的覆盖率统计,使用率统计和字频统计的数学算法以及计算机程序算法,并根据得出的研究方法研发常用字覆盖率统计分析系统,最后做一个统计实验,即分别通过《现代汉语常用字表》中的频度最高的581个常用字[2],1 000个常用字和2 500个常用字对电子文本进行统计分析,并获取覆盖率、使用率、字频统计信息,以此了解文本中常用字的使用情况。
1 覆盖率统计算法的优化
覆盖率统计的主要任务就是统计出给定文本中常用字的覆盖情况,根据统计信息结果就可以知道常用字在文本中的覆盖率或者说是比率。为此在前期研究中[3]首先将电子文本中非汉字元素取出后,再对所剩下的汉字元素进行统计分析。但是在计算机处理中该方法还不是很实用。因为为了先抽取文本中除了汉字以外的元素,对于计算机来说需要先定义大量字符元素,以便计算机可以识别并分类。如:数字、各种符号以及其他未知符号等。这对实现计算机程序算法带来了一些困难,也有可能由于程序无法识别文字字符产生统计误差等问题。因此对前期所使用的数学公式进行优化处理,以便适用于计算机程序算法[4-6]的实现。
1.1 覆盖率统计数学算法
覆盖率是阅读教材里被包含的在字表里的汉字与阅读教材里的全部汉字的比率[7]。在优化后的算法中不再对文本中的非汉字字符进行统计和抽取操作,而是直接对文本中的汉字字符[8]进行统计,这也更符合计算机的处理。具体数学表达式如式(1)所示。
(1)
其中,F为常用字在电子文本中的出现次数,L为文本的长度;C为常用字,Ci为常用字表中下标为i的汉字,N为常用字字数;T为电子文本,Tj为电子文本中下标为j的汉字。出现次数F主要是通过常用字和电子文本中的汉字逐一对比后获取的统计结果,即当Ci=Tj时,X(Ci,Tj)=1,当Ci≠Tj时,X(Ci,Tj)=0,X函数的值将会累计计算,运算结束后作为F的值。
1.2 覆盖率统计程序算法的实现
(1)程序处理流程。
根据式(1)可以通过计算机程序来实现覆盖率统计。首先将程序处理流程定义如下:
第一步:统计出文本中汉字的个数L。
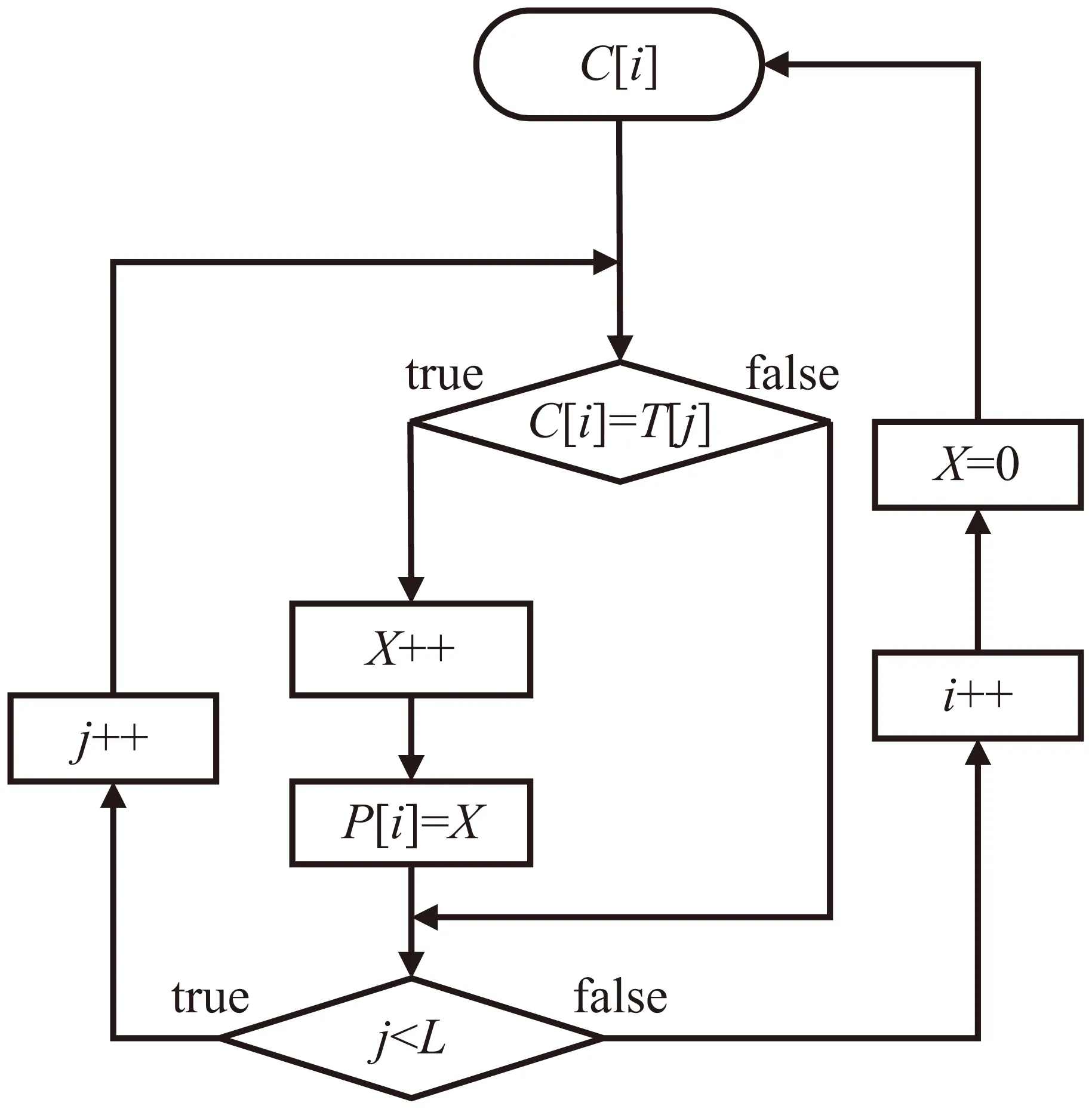
第二步:统计常用字在文本中的出现次数F,具体流程如图1所示。
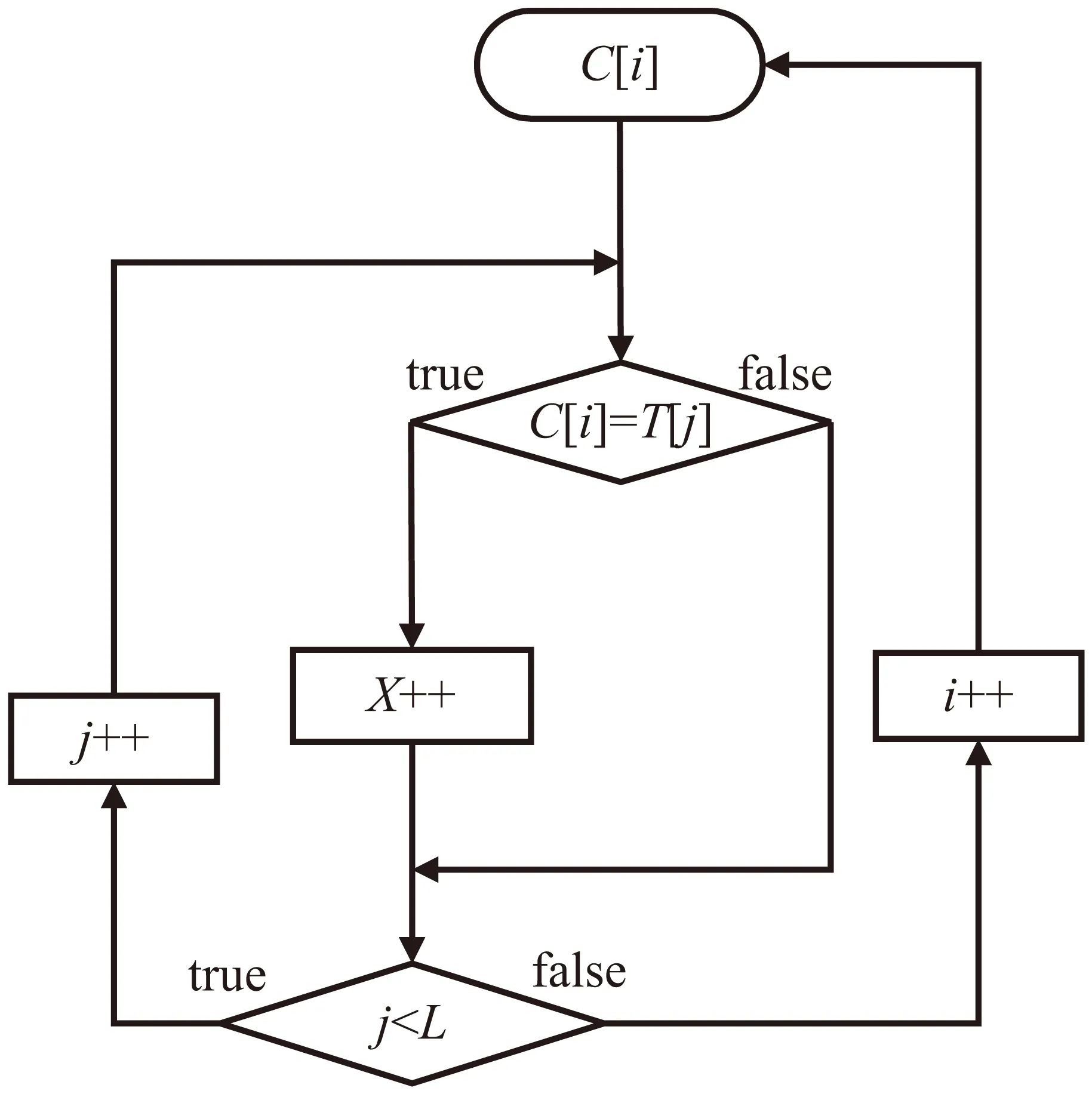
图1 常用字出现次数统计流程
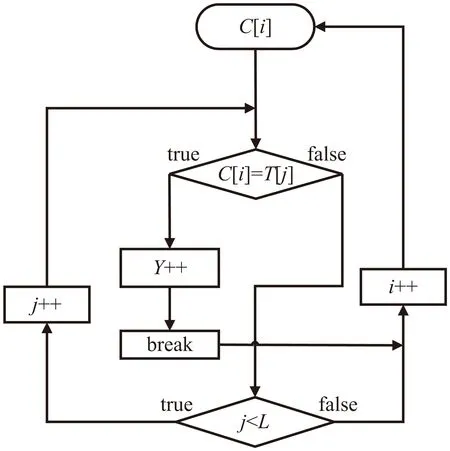
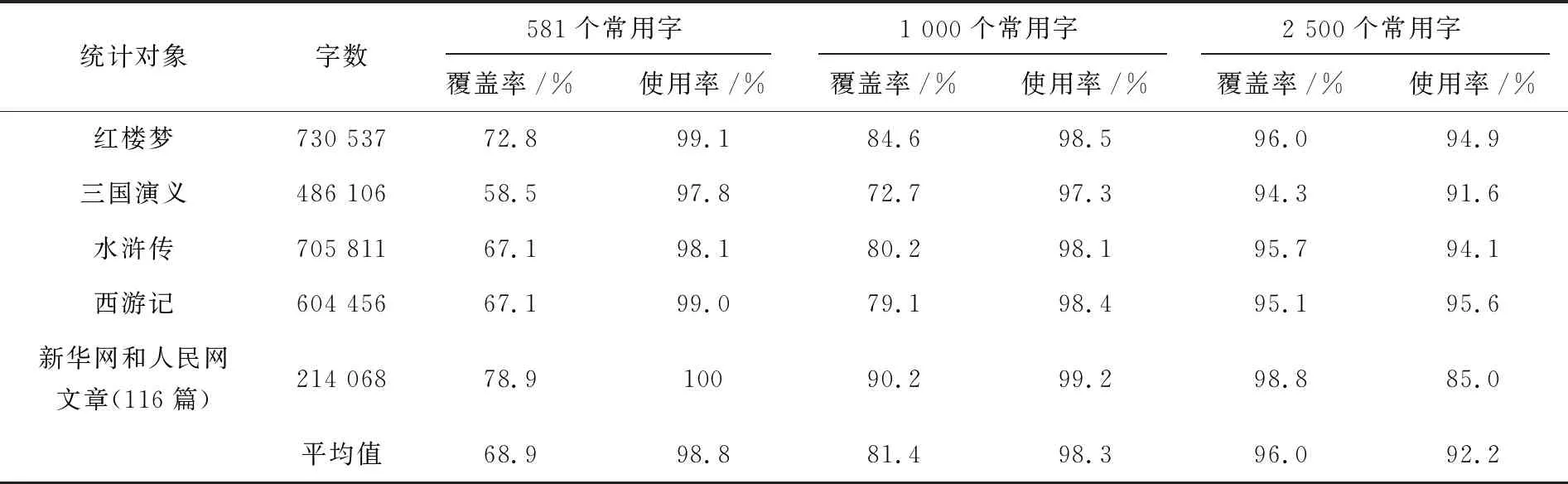
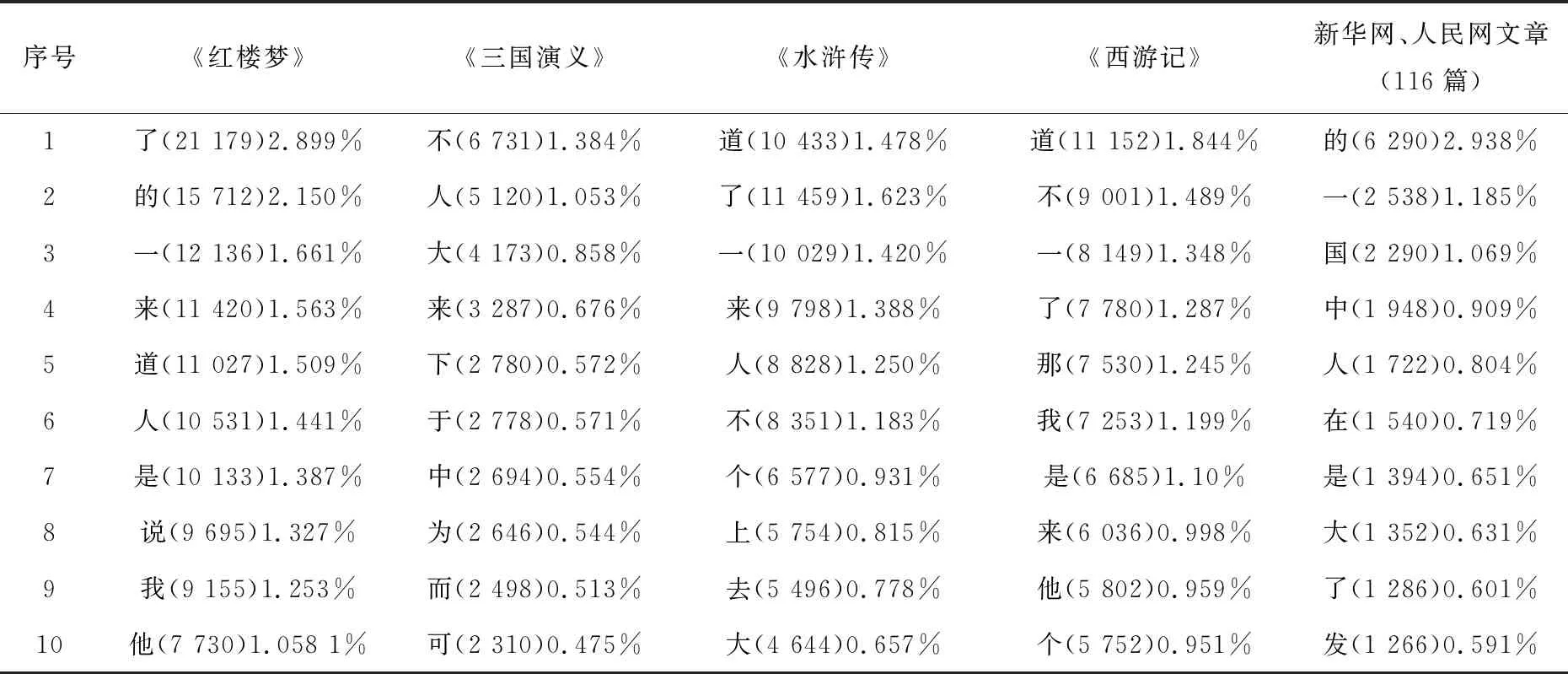
该流程图中进行循环操作将对常用字和电子文本中的汉字逐一进行对比,符合条件C[i]=T[j]时X的值加1,不符合时先判断j 第三步:根据式(1)计算覆盖率。 (2)程序算法的实现。 根据式(1)和程序处理流程,覆盖率统计核心Java[9-11]程序算法如下: intX; //统计常用字在文本中的出现次数 public int getCiShu_tongji(String text) {//获取出现次数的函数 X=0; //出现次数赋值为0 for (inti=0;i for (intj=0;j if (C[i].equals(T.charAt(j)+"")) {X++;} }} return X; //返回出现次数的值 } (3)程序统计流程示例。 下面将通过一个简单示例来说明程序覆盖率统计的过程,首先需要一个常用字表和文本。为了简化,只抽取了频度最高的14个常用字。具体覆盖率统计示例如下: 常用字:的,一,是,不,了,在,有,人,这,上,大,来,和,我 文本:这些是不是你的? 可以算出文本长度L的值为7,常用字N的值为14。那么首先计算常用字在文本中的出现次数F,具体流程如表1所示。 表1 覆盖率统计流程示例 上述表1所示,常用字与文本中的汉字逐一对比后的常用字出现次数F的值为5,那么根据覆盖率统计公式计算结果如下: 常用字使用率是指电子文本中所出现的常用字在常用字中的比率。 通过统计电子文本中的常用字使用率,可以了解到文本中所使用的常用字使用比率,具体数学表达式如式(2)所示。 (2) 其中,G为文本中常用字使用次数(该值不计算重复出现的常用字),N为常用字数,Ci为常用字表中下标为i的汉字,Tj为电子文本中下标为j的汉字。电子文本中使用次数G是通过常用字与电子文本逐一对比后获得的结果,但与式(1)的出现次数F还有一定区别。G在统计过程中不计算重复出现的常用字,因为常用字与电子文本汉字对比时,只要有一个符合条件,它就代表该常用字已经使用,因此无需与下一个文本汉字对比。即当Ci=Tj时,Y(Ci,Tj)=1且j=L,当Ci≠Tj时,Y(Ci,Tj)=0。j=L表示一旦符合条件将文本T的下标j赋值为文本长度L,此时就会重新开始从下一个常用字进行对比,避免了重复计算,保证了统计结果的准确性。 (1)程序处理流程。 根据式(2)使用率程序处理流程定义如下: 第一步:获取常用字字数N。 第二步:计算文本中的常用字使用次数G,流程如图2所示。 图2 常用字使用次数统计流程 图2中单个常用字C[i]在循环对比过程中如果满足条件C[i]=T[j],首先将Y的值加1,再用break命令结束内循环,这样就可以保证每个常用字统计结果不重复。然后i的值加1,再从下一个常用字C[i]开始统计。 第三步:根据式(2)计算使用率。 (2)程序算法的实现。 以下为使用率统计核心算法。 intX; //统计常用字在文本中的个数 public int getShiYong_tongji(String text) {//获取使用次数的函数 Y=0; //使用次数赋值为0 for (inti=0;i for (intj=0;j if (C[i].equals(T.charAt(j)+ "")) {Y++; break; } }} returnY;//返回出现次数的值 } 字频是指每个常用字在文本中的出现频度[12-14]。 为了计算字频,首先需要统计每一个常用字在文本中的出现次数,然后再将每个汉字的出现次数除以文本长度,具体字频统计数学表达式如式(3)所示: (3) 其中,Pi为每个常用字在文本中的出现次数,Ci为常用字表中下标为i的汉字,Tj为电子文本中下标为j的汉字。每次对比后X(Ci,Tj)累计值作为Pi的值,再计算下一个常用字Pi的值,即当Ci=Tj时,X(Ci,Tj)=1,当Ci≠Tj时,X(Ci,Tj)=0,直到j (1)程序处理流程。 字频统计程序流程如图3所示。 图3 常用字字频统计流程 在此流程中首先还是要对单个常用字C[i]进行逐一对比,如果满足条件C[i]=T[j],X的值加1并将该值赋给负责存储每个常用字频度的数组P[i],然后判断下一个条件j (2)程序算法的实现。 字频统计核心程序算法如下: intX; //统计每个常用字在文本中的个数 int[]P=new int[N];//该数组用于获取下标为i的常用字在文本中的使用次数。 public int[] getPinDu_tongji(String text) { X=0; //使用次数赋值为0。 for (inti=0;i for (intj=0;j if (C[i].equals(T.charAt(j) + "")) {X++;} } P[i]=X; //将使用次数X的值赋给数组P X=0;} returnX; //返回出现次数的值 } 服务器操作系统:CentOS 7; 使用编程语言:Java,JavaScript,XML[15-16]; 使用开发工具:Eclipse; 系统框架:主要采用B/S架构。 系统可以根据输入的文本进行统计分析,可以统计文本中常用字的覆盖率、使用率、字频等。可根据需要选择目标常用字,即可以选常用581、1 000、2 500个常用字表对文本进行统计分析。图4为常用字覆盖率统计分析系统的字频统计功能界面。 图4 常用字在文本中的字频统计 为了测试系统,以四大名著和新华网、人民网共116篇文章作为统计对象,分别统计分析了字频最高的581个常用字、1 000个常用字和2 500个常用字在这些统计对象中的覆盖率、使用率以及字频,具体统计结果如表2所示。 表2 常用字统计分析 那么再来看一下统计对象中常用字字频的情况。在统计结果中只抽取了使用频度最高的前10个汉字,具体统计结果如表3所示。 表3 字频统计 从表3中可以看出,根据不同的统计对象常用字的使用频度也会有所不同。 对常用字在教育资源电子文本中的覆盖率统计,使用率统计,频度统计相关的统计算法进行了研究,并结合相关程序算法,以计算机程序的方式来实现一个常用字覆盖率统计分析系统,并通过统计分析系统对四大名著和新华网、人民网116篇文章中所使用的常用字进行了统计分析。结果表明常用字在文本中的覆盖率和使用率相当高,即581个常用字在文本中的覆盖率平均在68.9%以上,1 000个常用字在文本中的覆盖率平均在81.4%以上,2 500个常用字在文本中的覆盖率平均在96%以上,并且常用字在不同统计对象文本中的使用频度也会有所不同。因此常用字不管是在生活中还是在工作中都无处不在,对人们的学习、生活、工作起着至关重要的作用。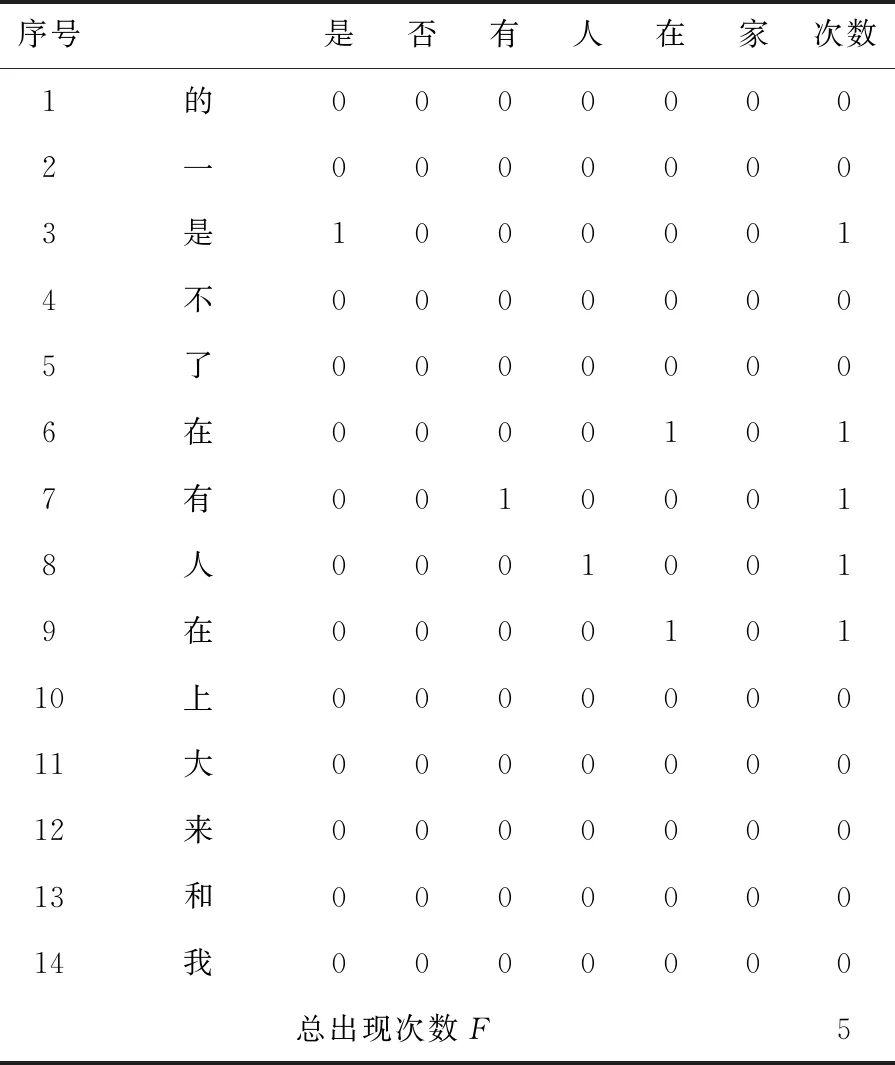
2 使用率统计算法
2.1 使用率统计数学算法
2.2 使用率统计程序算法的实现
3 字频统计算法
3.1 字频统计数学算法

3.2 字频统计程序算法的实现
4 常用字覆盖率统计分析系统
4.1 系统框架
4.2 系统功能
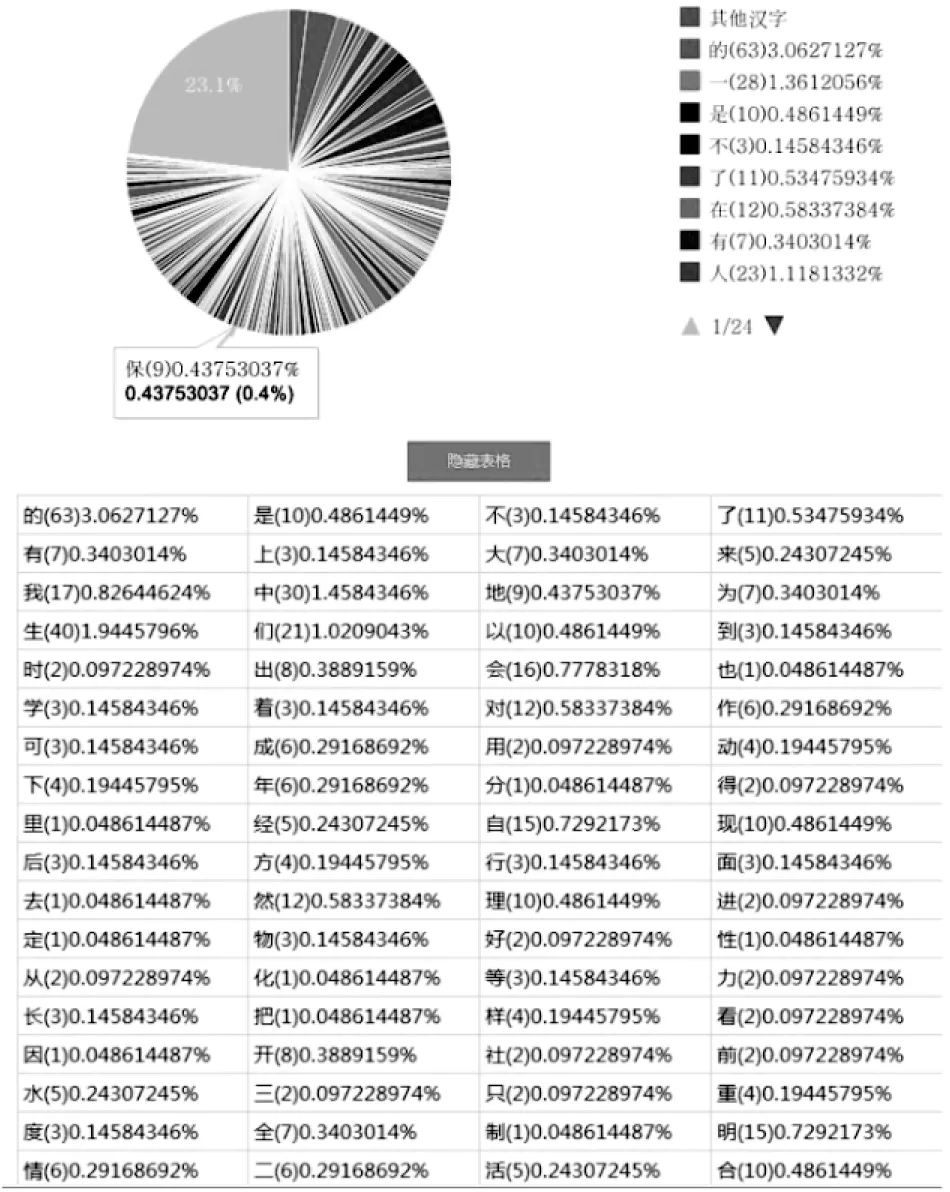
5 常用字统计实验
6 结束语
