自适应Gabor卷积核编码网络的表情识别方法
2020-05-20梁华刚张志伟王亚茹
梁华刚,张志伟,王亚茹
长安大学 电子与控制工程学院,西安 710000
1 引言
在现实生活中,表情是人类最重要的生物特征之一,包含着非常丰富的情感信息,在人与人相互情感表达中起着重要作用。随着近年来计算机视觉的发展,表情识别作为人工智能的一个方向也引起越来越多国内外学者的关注。
郑昌金等[1]的基于LBP(Local Binary Pattern)特征和熵正则化Wasserstein距离的表情特征提取和识别方法,对传统LBP进行了改进,并取得了良好的识别率。黄丽雯等[2]的非对称方向性局部二值模式人脸表情识别方法,通过对分割的表情区域计算相关贡献度和二值模式直方图信息,采用级联网络进行多尺度多方向特征融合,最后对融合特征进行分类识别。Deng 等[3]的基于Gabor特征结合主成分分析和独立成分分析的方法,对滤波器数量进行了限制,减少了数据冗余,提高了模型计算速度。于明等[4]基于LGBP(Local Gabor Binary Pattern)的识别方法和张娟等[5]基于Gabor小波变换的表情识别方法相比较,前者采用对提取的多尺度、多方向的Gabor特征进行局部二进制编码,然后建立过完备字典实现图像分类,后者对预处理的图像经过单模式Gabor特征提取,进而应用模板匹配算法进行识别。两者模型简单,在不同数据库上有很好的识别率,完全体现了Gabor小波在表情识别方面的优势。早在1989年,LeCun等[6]提出了卷积神经网络(Convolutional Neural Network,CNN)模型,为现代图像、计算机视觉和NLP 技术等领域的发展奠定了深度网络的基础。比如Xu 等[7]的基于卷积神经网络的识别方法,通过参数迭代更新,提取图像深度信息,实验结果表明卷积网络模型相比于传统方法在识别率、泛化性方面有很大优势。钱勇生等[8]的多视角表情识别方法,通过改进卷积网络提取不同视角的特征,引入压缩和惩罚网络进行学习,加入空间金字塔和优化算法增强网络鲁棒性和快速性。Lopesa等[9]的深度卷积网络的识别方法,应用特定的预处理技术,仅使用少量数据训练深度网络提取特征,解决了公有数据集数据量不足的问题,并且在保证识别率的情况下实时性也有不错的表现。Zeng等[10]的基于深度编码器的识别方法,对编码器结合深度学习特点进行累加来提取图像深度特征,在网络结构方面有很大的创新,并且有非常好的识别效果。以上传统方法存在泛化性不强、提取特征单一、特征融合后高维特征冗余、多级网络计算量大、对光照问题不敏感等问题。而深度卷积模型的网络参数更新方式和结构都比较复杂,训练过程过于繁琐,对硬件要求较高,难以保证在实际应用中模型实时性问题。根据现有传统方法、深度学习等方法的研究基础,设计能体现二者优势的网络模型。
综上,本文提出一种基于Gabor卷积核改进的网络模型,利用深度学习模型参数优化的特点,设计自适应Gabor卷积核,采用不同的卷积通道,分别提取适应度较高的Gabor 特征。进一步对提取高维特征进行通道内降维和通道外编码降维。然后应用GA(Genetic Algorithm)优化算法对支持向量机分类器具有鲁棒性的安全因子等相关参数进行优化,使得低位映射的超平面决定的决策边界存在最大间隔。产生更加高效的数据分类模型,在保证准确率和泛化性的情况下,调节各级参数,尽可能降低网络训练时间、模型复杂度、错误率。
2 相关理论
本章主要对表情识别过程中用到的预处理操作、Gabor滤波器组、支持向量机理论进行概述,分析不同过程中应用的理论方法,为整体网络框架提供基础。
2.1 图像预处理
图像预处理过程在表情识别方面至关重要,它主要包括人脸面部检测、分割、归一化等操作,目的是得到包含细节的归一化、噪声较少的表情图像。(1)人脸粗剪检测:首先对图像进行分块,其次应用HOG特征对不同数据库的图像进行人脸检测,然后根据提取的特征训练一个检测模型,用于图像预处理操作。(2)粗剪裁剪:将检测出来的人脸表情用规定大小的实线框进行标记,并且截取框内人脸图像。(3)数据归一化模块:因为输入到后期识别网络的图像大小是相同的,所以要对截取的表情图像进行精剪,进一步进行归一化处理,最后得到归一化后的表情图像的大小为48×48。图1为人脸表情预处理的结果示意图,从图中效果来看,分割效果比较可观。

图1 JAFFE表情库人脸表情预处理结果
2.2 Gabor滤波器组
Gabor 变换[11-12]是一种短时傅里叶变换方法,当选取的函数为高斯函数时,这种短时傅里叶变换称为Gabor 变换。在图像表示的空域中,一个二维的Gabor滤波器是一个正弦平面波和高斯核函数的乘积,具备在空间域和频域[13]同时取得最优局部化的特性,相应的定义如式(1)所示:
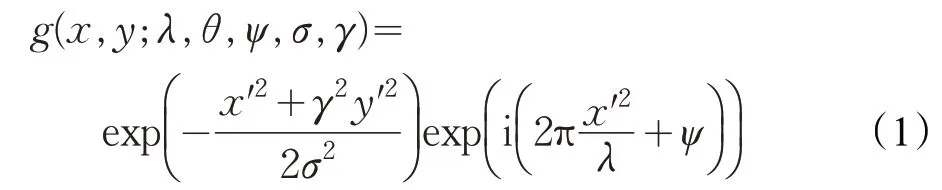
式(1)为复数形式,且x′=xcosθ+ysinθ,y′=-xsinθ+ycosθ,λ为正弦波长,θ为 Gabor 核函数的方向,ψ为相位偏移量,σ为高斯函数的标准差,γ表示空间宽高比。一般的,Gabor 滤波器是自相似的,也就是所有的Gabor 滤波器都可以通过一个母小波经过膨胀和旋转产生。
本文设计了40 个实部滤波器,包括8 个不同方向(横向)μ∈{0,1,2,3,4,5,6,7} ,5 个不同的尺度(纵向)。生成的滤波器组为图2 所示,其中最大中心频率为ωmax=π/2,以上Gabor 滤波器组的参数σ主要和设计滤波器的带宽有关系(σ=0.5 为最佳滤波效果)。

图2 不同频率和方向的Gabor滤波器组
2.3 支持向量机
支持向量机(Support Vector Machine,SVM)[14]就是利用内积核函数代替高维空间的非线性映射,通过此核函数对特征向量进行变换,将低维不可分问题转化为高维可分,这个映射表示为:

其中,X为输入数据,每个样本用(xi,yi)表示,φ为映射核函数,Z为高维输出向量。一般,定义的分类超平面根据式(3)计算样本点到超平面的距离:

式中,w为变换矩阵,b为偏差。应用拉格朗日和KKT(Karush-Kuhn-Tucher)条件对支持向量最大间隔和与分类面的最小距离进行优化,问题转化为使得||w||最小,表示为:

其中,xi为样本的特征向量,yi为类别标签,取值为±1,分别对应的是正样本和负样本,K表示核函数,n为样本数,ε为惩罚因子(人工经验参数)。
SVM在逻辑回归基础上存在的决策边界不但要求支持向量间有最大间隔,也要使得与分类面存在最大距离。如图3 为支持向量机二分类效果图,图(a)为支持向量和分类面最小距离的最大间隔面效果图,图(b)为局部支持向量和分类面最小距离的最大间隔面效果图。其中前者是全局最优解,分类效果显然比后者更加好。
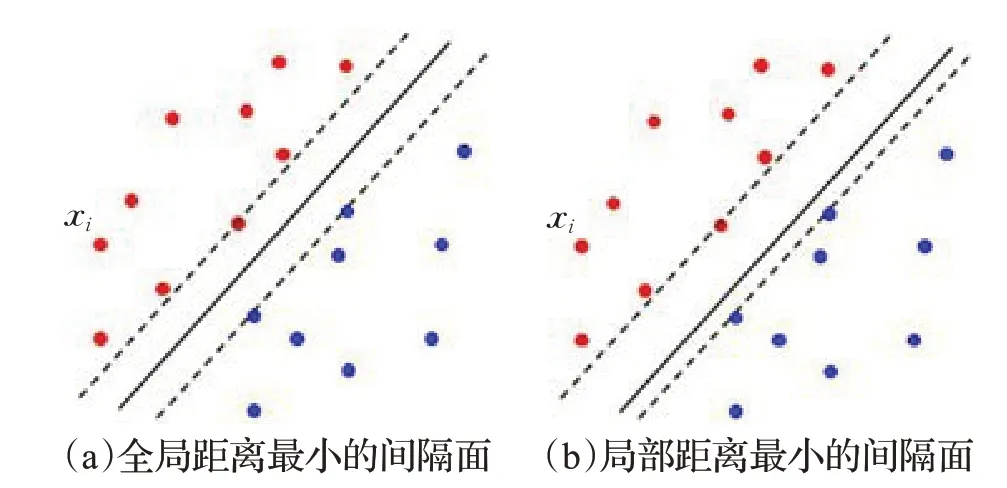
图3 SVM二分类线效果图
3 模型建立
3.1 Gabor卷积核优化
改进的Gabor卷积核主要通过计算优化出Gabor小波的中心频率和方向等参数,实现卷积核的自适应特性,并且提取待卷积核图像在整个频率域的边缘、亮度和位置等多方面的特征。根据图4 所示的网络模型,Gabor卷积特征就是将输入的图像与Gabor卷积核组进行卷积得到。输入图像表示为I,得到图像卷积特征的子区域图像IC和Gabor卷积核的定义为:


式中,(μ,ν)为优化完的自适应Gabor 核参数值,IC为输入的待卷积子区域图像,Ψ函数为参数优化函数,k∈{1,2,3}。
3.2 GaAeS-net网络模型结构
本节主要对设计的GaAeS-net(Gabor Autoencoder Support Vector Machine Convolution Network)网络模型结构进行概述,自适应Gabor卷积核网络方法区别于传统手动提取特征方法和自提取卷积神经网络方法,能够体现Gabor 参数动态性,实现两次特征降维操作,并且根据优化的分类器模型实现表情识别。网络模型如图4 所示。网络结构共分为四部分:输入数据层、卷积层、池化层、分类层(本文“层”意不同于神经网络“层”)。
3.2.1 输入数据层
为了保证得到面部图像不同区域的器官特征,文中建立用于描述不同器官特征关系的图像通道,根据在每个通道中定义的不同区域卷积核遍历整张图像提取Gabor特征,其中划分区域的种类、大小根据人脸表情图像所确定。当然,对于一张人脸来说各器官的大致位置是确定的,但是对于表情变化主要基于各个器官位置关系,因此在输入图像时定义不同的网络结构,对输入的数据进行变换和重复多利用。如图4所示,I是长宽为m×n的归一化图像矩阵,由预处理知道m=n=48。
3.2.2 卷积层
对于整个模型来讲,卷积层可看成是整个网络的核心,卷积层的复杂度、卷积核数目等都影响网络提取特征的快速性以及最后用于识别的分类器的准确性。如图4 所示,文中卷积层只有一层,通过输入的归一化图像I定义5 种通道,并且根据每种通道划分不同区域。所用卷积核大小为lC×lC,lC∈{12,24,32,36,48},C={1,2,…,5}∈RC,C为输入图像的通道数。首先,在卷积层对决定Gabor 核的方向、尺度、大小参数进行初始化。然后,根据式(6)进行优化操作,表示提取的Gabor特征图。为了能在不同方向和尺度上充分体现表情特征,对卷积参数进行扩充,主要根据3.1 节计算出Gabor自适应值(μ,ν),通过计算二范数筛选出3对邻近的Gabor核参数,如式(8)、(9)所示:
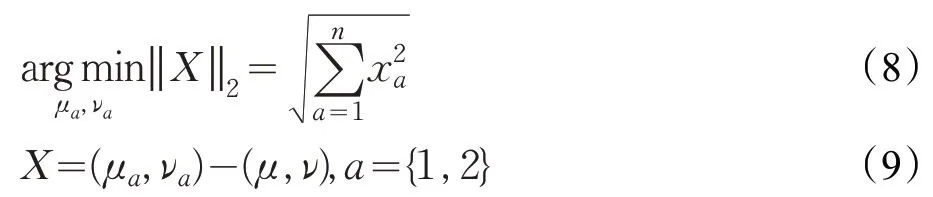
其中,n为所用到的Gabor 核方向和尺度模板总数,本文设计模板总数为40,(μa,νa)为邻近参数值,a为扩展参数对数,与自适应值(μ,ν)共同组成用于卷积的参数对,含义为l×l大小的Gabor核在进行i步卷积时得到的第k个Gabor 卷积核方向和尺度参数值。根据此操作可知,在每种卷积核下进行一次卷积操作得到3张特征图。又因为提取的单个局部区域特征不足以表达原始图像的特征,所以采用步长S∈{12,8,12,8,0}对每个通道的图像进行遍历来提取各个局部信息。
3.2.3 池化层
在实现上述的卷积操作之后,得到的特征图数据是巨大的,因此对高维特征数量进行降维显得尤为重要。如图4 所示,本文网络模型的降维操作分为两步,首先进行通道内降维[15],其次进行二次编码降维。如式(10)所示通道内降维:

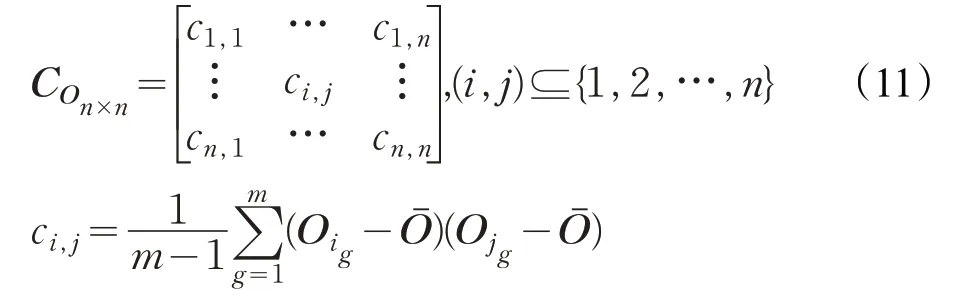

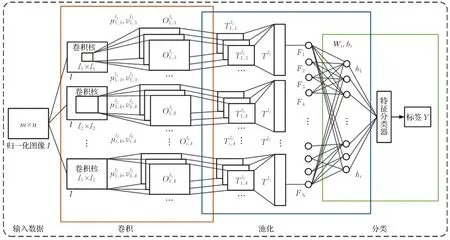
图4 GaAeS-net网络模型图
其中,base为需要进行降维的基础变换矩阵,此矩阵通过对协方差矩阵的特征值排序得到,排序前j列的特征向量组成base矩阵,表示特征向量矩阵。
通道内降维对冗余信息进行剔除,为了保证后期分类的准确性和迭代优化的计算量,对于通道外的不同特征融合和降维应用编码网络。经过实验分析,无论从网络泛化性、鲁棒性、计算量都进一步证明了编码降维的必要性。对编码降维基于Liu 等[16]的深度编码网络,其中输入为基于每个通道下卷积特征图像连接而成的降维向量。编码降维的目标函数表示为:
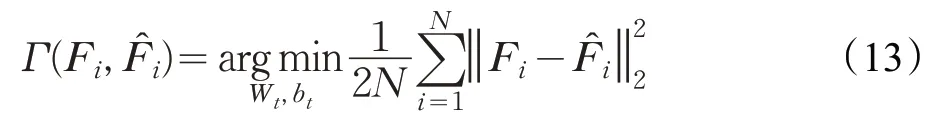
式中,Wt、bt为编码网络权重和偏差矩阵,N为所分表情高维特征数,Fi为输入的特征,为它的估计,为输入和估计的距离函数。
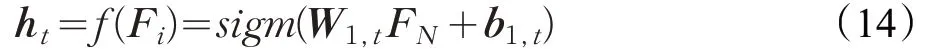
其中,ht为编码层的隐含层神经元输出,t为隐含神经元的个数,激活函数sigm(x)=(1+exp(-x))-1。因为在编码过程中,编码操作是不定向的,所以要对输入特征进行估计,通过迭代更新权重减少编码误差,得到便于分类器分类的特征集合。式(15)是对输入特征向量的估计:
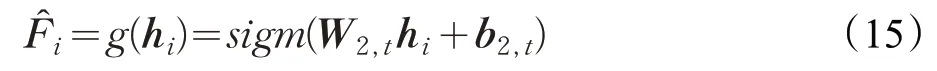
式中,hi为隐含神经元的输出,W2,t、b2,t为估计出的高维向量的解码权重矩阵,为编码向量的估计。
GaAeS-net[17]的池化降维操作在网络中起着决定性的作用,为了保证在实际中提取特征的有效性,对两次降维的参数进行实验分析,在最大程度上保证信息完整性(第一次损失10%,第二次损失15%),使得特征识别的网络模型计算量最小,参数适应度最好。
3.2.4 分类层
不管是Li[18]、Sun[19]等的复杂卷积神经网络,还是Ding[20]、Pan[21]等的各种神经网络的变体模型,大多数使用的是KNN(K-Nearest Neighbor)以及Softmax 分类器,由于在自学习网络中的优势,各种变体网络更是偏爱基于统计学的分类器。
根据数据库、模型特征分析,本文所用数据库的图像都比较少,一方面难以满足Softmax损失函数分类器,有效避开了归纳到演绎的传统过程;另一方面分类损失误差不能传输到网络输入进行调节,进而选用SVM 为特征分类器。又因为基于两次降维后得到的自适应Gabor 特征,应用传统SVM 分类器时,在原始训练集上不能很好地识别。针对以上问题,GaAeS-net 模型应用GA算法对定义的分类器参数进行优化[22]。但是需要优化的参数迭代次数完全取决于提取降维特征高效性,为了尽可能减少模型计算量,文中实验部分主要对涉及的参数应用控制变量等方法进行调节。得到不同参数不变的剩余参数最优值,绘制相关曲线图进行分析,确定不同参数在限定范围内的最优值,进一步提高分类器的识别率,强化模型泛化性,减少计算量,保证实时性要求。最后,设置GA所需的最大迭代数、种群数、交叉验证等参数,在限定的参数范围内优化核函数的参数集合,从而得到数据集上最优分类超平面。
3.3 面部表情识别网络
本文人脸表情识别流程框架如图5所示,主要应用Gabor 特征的性能优势,定义不同大小的Gabor 卷积核提取图像不同区域特征,进而对学习到的不同面部表情特征进行分类,得到高效、快速、准确的网络模型。此模型主要分为三个阶段,分别为图像预处理阶段、模型训练阶段、数据测试阶段。
图像预处理阶段:大多数的图像由于拍摄环境多样性使得表情图像的背景较复杂,为后期特征提取带来更多不属于表情的特征,进而给训练、识别的数据带来更大误差。因此这个阶段的目的主要是得到包含细节的归一化人脸表情图像。
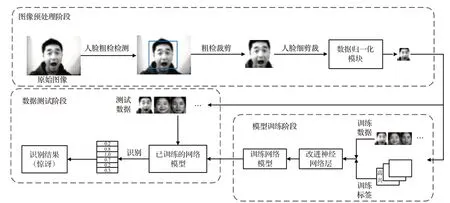
图5 基于Gabor核卷积网络框架
模型训练阶段:此阶段主要目的是训练高精度、快速、鲁棒性较强的网络模型。其中应用设计的GaAeS-net网络对预处理过的表情图像进行训练,通过调节自适应Gabor、不同通道降维、分类器优化等相关参数,得到最优的识别模型。
数据测试阶段:此阶段主要目的是检测训练模型的识别率、泛化性、快速性等相关性能。首先对原始数据集进行分类,使得部分用于训练,部分用于测试。文中针对训练模型的数据预处理也是测试数据的处理过程,只是基于不同数据库的图像存在差异,因此也需要对处理过程中的参数进行调节,以适应不同的数据集。
4 实验与分析
本文实验部分主要在不同数据库、不同类型卷积核、不同模型、不同训练时间等多方面进行实验。主要使用Matlab 2014a 环境进行实验分析,其次还在VS 2013+opencv、ubuntu 16.04+python+pytorch-GPU 中进行图像采集、预处理和部分模型的训练及验证工作。通过对比不同卷积核方法和各种先进方法的实验结果,本文方法得到了充分的验证,在不同的数据库上都表现出非常好的性能。
4.1 数据库介绍
本文主要应用了四种不同数据库,这些数据库分别是:CK+数据库,此数据库是在 2010 年 Cohn-Kanade 数据库基础上扩展来的,其中包括了123个对象,593个视频序列,而且每个视频序列都有一个标签,共分为7类;JAFFE(The Japanses Female Facial Expression Database)数据库,日本女性数据库,共有213张表情图像,由10 个女性的7 种表情组成;FER2013 数据库,此数据库源自于一次人脸表情大赛,其中数据主要存放于fer2013.csv 文件中,共分为标签和像素值两列,并且分为7 类;CHD2018(长大电控2018)数据库,该数据库是为了验证GaAeS-net 模型准确率、泛化性、鲁棒性等而自己创建的数据库,其中采集了30 个人的8 种不同表情,其中每种表情在不同光线(正常、强光、弱光)下进行采集,共计图像2 160张。
因为每个数据库中的人物来自不同的国家和地区,表情表达也深受地域限制,所以对各个数据库的表情不做统一整合。而同一数据库中的图像存在冗余,进而要进行筛选,建立表1。并且对每个挑选的图像进行标签定义,最后的数据库由8 个类别文件夹和1 个文本标签组成,其中每个数据库都有8 种表情(JAFFE、FER2013除外)。图6是经过整理后的不同标准数据库人脸表情图像示例,其中包含不同年龄、不同性别、不同光强的表情样本。本文实验主要在CK+、JAFFE、CHD2018 数据库上进行,其余数据库用于测试或者验证其他方法。
4.2 GaAeS-net模型性能分析
为了测试本文GaAeS-net 模型的性能,在自建的CHD2018数据库上进行实验,分别对模型准确率、泛化性、光照强度等三方面进行测试分析。为了便于实验,其中将CHD2018 数据库中每类表情平均分为10 份,8份用于网络训练,2份用于模型测试。
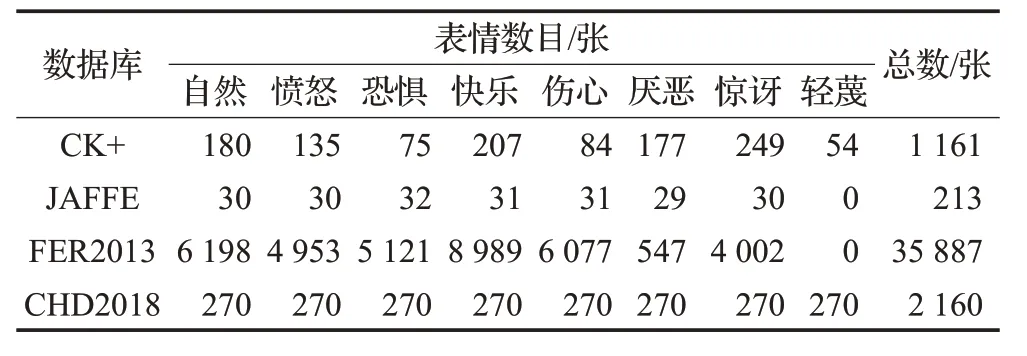
表1 不同数据库表情样本种类数目

图6 标准数据库表情示例
首先,对相关图像进行预处理,得到归一化后的图像集合。其次,初始化所有网络模块参数。具体的,随机生成Gabor核参数;编码参数赋值为1;编码迭代和分类器优化的最大迭代次数设置为150;学习率为0.01;种群数为40 等。最后,开始训练和测试,分析实验结果。如图7 为提取到的基于不同Gabor 卷积核的自适应Gabor特征图,共有5个通道,每个通道中有若干特征图(图中显示前3张)。其中每种通道下存在特征冗余,但是经过数据融合和降维操作后消除特征冗余,很大程度上减少了数据量,最后得到整合的特征向量。

图7 各通道自适应Gabor特征图
根据提取到的特征图像,经过不同的通道内降维和通道外编码操作,对于二次编码降维在一定程度上对分类器优化、准确率有很好的效果,但是也使得网络训练时间变长。通过参数调节证明,编码迭代次数为25时,编码损失误差从开始的3.425降到0.161,同时用于分类器优化的迭代时间和识别率都是最优的。因此,进一步将降维特征输入到待优化的SVM 分类器,得到分类器参数适应度曲线,如图8 所示。看图可知,在训练集合上对分类器参数进行优化分类,在迭代次数将近30 次时分类器识别率基本稳定在95%左右,并且平均适应度也达到70%以上。最终迭代完150次时,分类器准确率达到99.138 7%,得到适应度最佳的核参数c=13.363 6,g=0.000 190 74。为了表现网络的性能,分别对每类表情的准确识别率、错误识别率进行统计,得到表2。

图8 分类器参数适应度曲线
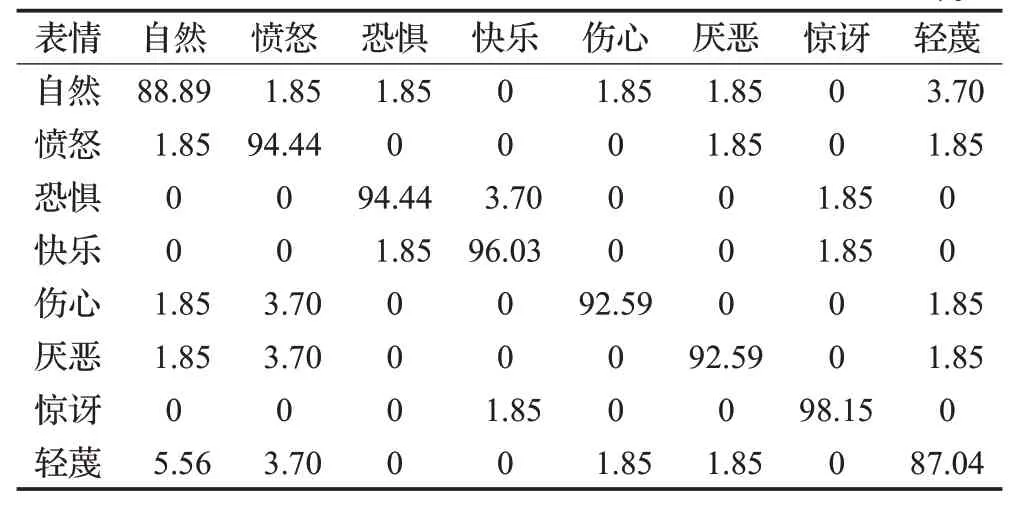
表2 基于CHD2018数据库的GaAeS-net模型表情识别率 %
根据表2的实验结果分析,本文模型的最大识率达到98.15%,平均识别率为93.021 2%,平均错误率为6.98%。其中自然、厌恶、轻蔑等表情容易被错误识别,识别率分别为88.89%、92.59%、87.04%,最容易被错误识别的是愤怒表情,错误率最大的表情为轻蔑,错误率达到9.26%。快乐、恐惧、惊讶等表情不容易被误检,准确识别率分别为96.03%、94.44%、98.15%。对于所有表情最大识别率和最小识别率相差11.11个百分点。相比于在训练集合上的识别率,本文方法在不同测试集上也有良好的识别率和泛化性。因为本身数据库在建立的时候对光照强度做了分类,根据识别的结果分析可知,Gabor 卷积核得到的特征对光照不敏感,并且自适应Gabor卷积核对表情图像具有比较好的适应度。
4.3 基于不同类型卷积核的网络实验
本节实验主要在两个数据库CK+、JAFFE上进行了训练和测试,比较Gabor-SV 核和其他类型卷积核的识别率。具体的,选择PCA核[23]、LBP核、权重核、Gabor等5 种不同的卷积核和KNN、Softmax、SVM 等 3 种分类器进行实验,结果如图9所示。

图9 不同类型卷积核网络准确率
由图9 可知:PCA 核在两个数据库上的准确率为89.12%和72.14%;LBP核的准确率为90.24%和88.59%;Gabor-So 核和Gabor-SV 核应用的卷积核是一样的,唯一不同在于分类类型,二者的实验结果为92.85%、90.32%和99.34%、94.86%;普通权重核的实验数据为91.57%和89.42%。相比于应用相同Softmax 分类器的LBP 核和普通权重核,Gabor 核在准确率上增长2.61 个百分点和1.28 个百分点,从而说明了Gabor 核提取特征的优越性和Gabor 核优化参数的有效性。在使用优化SVM 对Gbaor 核提取的特征进行分类的最大准确率能达到99.34%,相比于Softmax 分类器,增长6.49 个百分点和4.54个百分点,进一步体现了分类器核参数优化的有效性。PCA 核应用KNN 分类器不能很好地进行分类,在两个数据库上其准确率最低为72.14%。而不同卷积核在JAFFE 数据库上的准确率远不及在CK+数据库,主要是因为数据量相差较大,网络模型存在数据欠拟合,样本特征不明显等。
4.4 不同网络模型的对比分析
针对GaAeS-net 模型在不同数据库上基于不同光照、不同类型卷积核的实验对比分析,在一定程度上验证了模型的性能,在同类方法中完全体现出了卷积核和模型的优势。但是本身模型的可推广度、计算量和客观度缺乏验证,因此根据自身条件通过在FER2013数据库上进行实验,对比分析本文方法相比于现有的先进方法的优势。根据不同模型的实验结果建立表3。
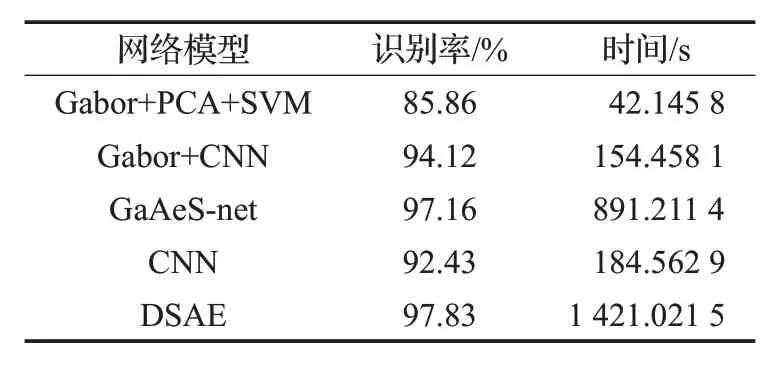
表3 本文改进方法与现有方法性能对比
从表3可以看出,应用了5种不同的方法,其中Gabor+CNN、CNN、DSAE等深度网络的识别率分别为94.12%、92.43%、97.83%。DSAE 网络的准确识别率为97.83%,为同类型中最高,但是相应的计算时间为1 421.021 5 s,在所有算法中计算量最大。而本文改进的GaAeS-net方法识别率为97.16%,计算时间为891.211 4。在识别率方面,与现有方法DSAE 相差0.67 个百分点,相比传统方法和普通卷积神经网络提高了11.3个百分点、4.73个百分点,与之先进的深度网络识别率比较接近。同理,在计算量方面与最优方法相差529.810 1 s,与传统方法相差较大,进一步说明了改进网络的有效性和不同方面的性能优势。
5 结束语
综上,本文结合传统学习方法和深度学习方法的不同优势,对已有的传统机器学习方法进行改进,提出一种GaAeS-net模型的方法。GaAeS-net模型可以提取面部表情的自适应Gabor 外观特征和不同器官之间的面部几何关系特征,通过定义不同的卷积通道进行特征提取,然后针对数据冗余和分类复杂度,对高维特征进行降维和编码,进而得到更加具有分辨力的特征向量。最后,在4种不同表情数据库上对8类面部表情通过3类实验说明了本文改进方法的性能。相比于传统方法,本文方法在识别率、泛化性方面有很大的优势。未来的研究也会围绕表情识别开发更复杂、更高性能的网络系统。
