面向多形式维文的敏感信息过滤算法研究
2020-05-20依不拉音吾斯曼郭文强
依不拉音·吾斯曼,郭文强,于 凯
新疆财经大学 计算机科学与工程学院,乌鲁木齐 830012
1 引言
在历史上维吾尔人使用过很多文字,如察哈台文、古突厥文、阿拉伯维文、拉丁维文等。最后一次文字改革是1985年,1985年前使用拉丁维文,1985年开始使用现在的传统维文,因此拉丁维文在维吾尔社会上有一定的影响力。随着互联网技术在新疆地区的发展和普及,维吾尔族网民的数量急剧增长,近十几年来新疆地区双语教育的加深,汉语拼音字母和英文字母的影响,加上传统维文由32 个字母组成,有120 多个字形,具有复杂的键盘布置,必须预装维文输入法,书写方向为自右向左和现代中英文混合使用非常不便等原因,互联网和移动网络上的维文使用呈现传统维文和拉丁维文共存的“一语双文”特点。现在互联网上使用拉丁维文人数不少于传统维文人数。多种维文文字共存的网络环境下,保证网络安全对新疆的社会稳定至关重要。暴力恐怖活动是当前国际社会普遍面临的国家安全威胁。2018年4 月20 日习近平总书记在全国网络安全和信息化工作会议中指出“系统部署和全面推进网络安全和信息化工作”。新疆是反暴力恐怖活动的主战场,网络中信息内容安全监控十分必要。对海量网络文本信息进行多形式维文(传统维文和拉丁维文)敏感信息检测,从而集中处理高关注的文本内容,为快速情报获取提供相应技术支撑,从而提高政府对网络信息的事控能力以及处置突发事件能力,提升维稳决策和响应能力是区域重大需求。
目前维文敏感信息检测与过滤研究仅限于传统维文,缺乏拉丁维文敏感信息语料库和决策树的研究,分别使用传统维文和拉丁维文的敏感信息进行检测,工作量大,效率很低,主要原因是互联网上有些人习惯使用拉丁文,有些人习惯使用传统维文,一部分人还混合使用。分别两次进行敏感信息检测,不但效率低,而且时间很长。因此本文构建传统维文和拉丁维文敏感信息语料库,在此基础上提出拉丁维文和传统维文一体化的多形式维文敏感信息决策树,实现传统维文和拉丁维文的敏感信息检测与过滤,不但提高了效率,而且缩短了时间,对新疆的社会安全和长治久安总目标的实现有重大意义。本文主要完成的工作有:
(1)研究传统维文和拉丁维文的语法特征、编码特征和映射关系,提出拉丁维文和传统维文间的编码转换算法 ULTC(Uyghur Latin Traditional Conversion),实现传统维文与拉丁维文之间的编码转换。
(2)使用ULTC 转换算法,在现有的传统维文敏感信息语料库中增加对应的拉丁维文敏感语料信息,实现多形式维文敏感语料库ULSC(Uyghur Latin Sensitive Corpus)的构建,在此基础上提出多形式维文文档敏感值的计算方法。
(3)针对现有的维文敏感信息决策树只包含传统维文敏感信息不包含拉丁维文敏感信息问题,在ULSC的基础上构建传统维文与拉丁维文敏感信息一体化的多形式维文敏感信息决策树LUDT(Latin Uyghur Decision Tree),在LUDT 基础上提出多形式维文敏感信息过滤算法USF(Uyghur Sensitive Information Filter)。
(4)通过翔实的实验来验证ULTC、USF算法的实际效率。
2 相关工作
2.1 相关知识
传统维文的语法特征:传统维文是新疆的维吾尔人从1985 年开始使用的以阿拉伯字母为基础的文字,传统维文属于阿勒泰语系中的阿拉伯文系统,其文字书写自右向左,和现代中英文的自左向右书写有很大区别。维吾尔语有32个字母,其中8个元音字母,24个辅音字母,每个字母在词中出现位置会不同,有2~4 种不同字形(如:词首,词中,词尾,独立式),共有120多种字形,这使得传统维文的输入法系统拥有复杂的键盘布置设定。维吾尔语词和词之间有空格隔开,不分大小写。有些词首字母由两个字符构成(如:字母由和两个字符组成)。
传统维文的编码特征:传统维文编码在Unicode 编码表的阿拉伯编码区内是分散分布的,词首字母和大部分独立式字母在0627-06AD 范围内,词中、词尾和部分独立式字母在FA8C-FEEE 范围内,如图1 所示,图中黑色部分是传统维文编码所在区域。维文字母编码的这种分配对维文字母的排序、自动选型、决策树的构建等带来很大的不便。
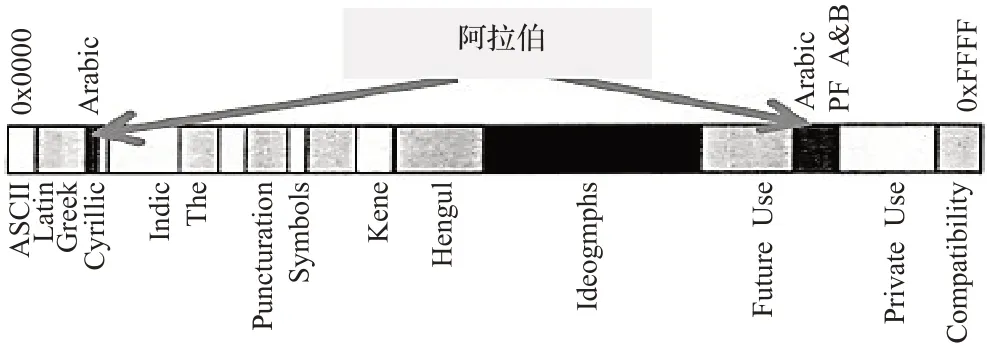
图1 Unicode编码分布图
拉丁维文:拉丁维文是用拉丁字母来拼写维吾尔语的文字。2000 年新疆大学和新疆维吾尔自治区语言文字工作委员会一起公布了维文与拉丁维文的对应标准,把拉丁维文叫作维吾尔族的计算机网络文字UCY(Uyghur Computer Yeziki)。维吾尔语有32个字母,而键盘上只有26 个拉丁字母,维吾尔文与拉丁维文对应标准上,只使用了24 个拉丁字母(不包括读音重复的v和c),剩下的8 个维文字母中的3 个原音字母与拉丁文扩展区的 ü、ě、ǒ 字母对应,剩下的 5 个辅音字母用ch、ng、zh、sh、gh等双字母对应[1],如表1所示。
2.2 相关研究
近几年来维文网页信息提取、维文词法分析、词干提取、信息检索技术研究也有了长足的进步。文献[2-5]中吾守尔院士、亚森等人介绍了传统维文、拉丁维文与斯拉夫维文的书写规则和对应关系,提出了它们之间的相互映射关系和转换规则。文献[6]中蔡李等人提出了一种有关句子特征的信息提取方法,该方法结合句子的特征对网页内容进行提取,使用该文献中的网页正文提取方法可以实现维吾尔文网页信息获取。文献[7-9]中吐尔根·依不拉音等人对维吾尔文的特点进行了细致的剖析,破解了维吾尔语词法分析、维吾尔语词汇切分、维吾尔语词干提取的难点,提出了有关维吾尔语词法分析的有向图模型和词干提取方法,提高了维吾尔文词干提取的准确率。词干提取有效简化维吾尔文敏感信息检测的过程,是实现网络维吾尔文敏感信息过滤的基础。文献[10-11]中邓一贵、周毅敏等人提出了有关敏感词决策树过滤相关算法,通过结合决策树记录敏感词词频等信息,最终计算出文本信息的整体敏感度,实现了文章敏感度的检测。文献[12-14]中唐华等人分别介绍了中文自适应多重过滤模型和基于K近邻分类算法的涉恐信息过滤模型。文献[15]中薛朋强和吾守尔院士等人提出了一种基于确定有穷自动机的改进算法ST-DFA,实现了针对传统维文敏感词决策树的实时更新和维文反过滤技术。
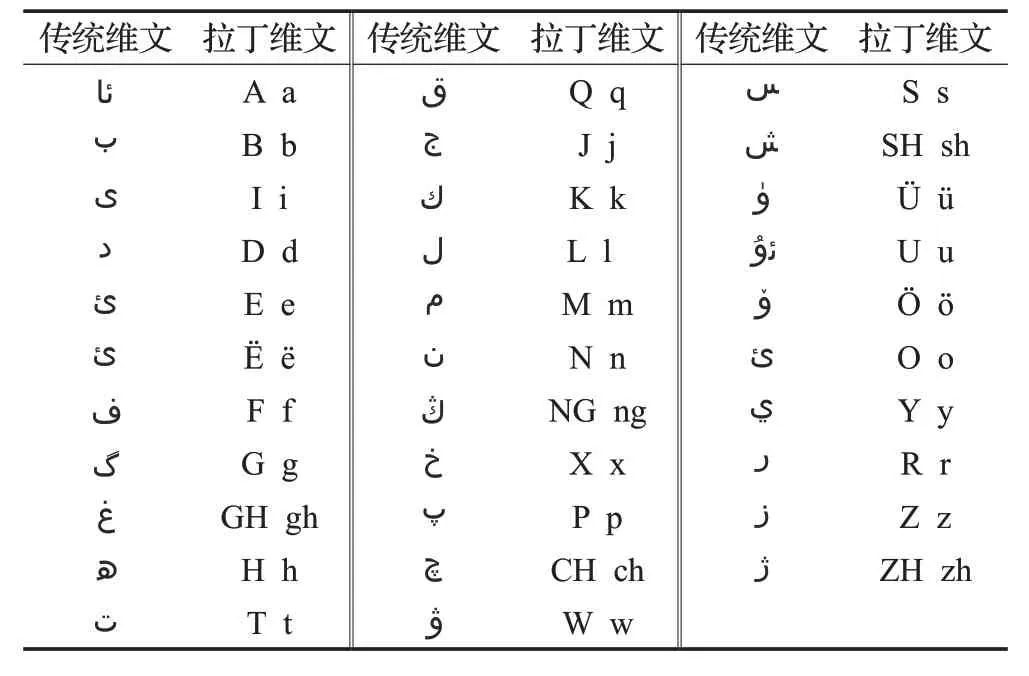
表1 传统维文与拉丁维文对应标准
现有的研究仅限于传统维文决策树构建、敏感信息检测与过滤算法上,对拉丁维文信息检测研究还是空白,反而互联网上使用拉丁维文的用户日益增多。因此本文研究拉丁维文和传统维文的编码特征,提出它们间的编码转换算法ULTC,通过ULTC 算法在传统维文敏感信息库中形成对应拉丁维文敏感信息语料,构建传统维文和拉丁维文的多形式维文敏感信息语料库ULSC。在此基础上提出拉丁维文和传统维文一体化的多形式维文决策树LUDT,在决策树的基础上提出多形式维文敏感信息过滤算法USF,弥补目前维文敏感信息检测与过滤系统的空白。
3 多形式维文敏感信息过滤算法与敏感值计算
针对现有维文敏感信息检测与过滤系统的缺点,本文首先设计传统维文与拉丁维文间的编码转换算法ULTC,使用ULTC 算法现有的维文敏感语料库中的传统维文剖象文件转换成拉丁维文剖象文件,添加到语料库中,实现多形式维文敏感信息语料库ULSC 的构建。考虑拉丁维文的字形和编码优势,决策树按照拉丁文的编码顺序排列,新建节点并添加节点内容时,在语料库中添加拉丁维文敏感信息后还要添加对应的传统维文敏感信息,实现拉丁维文与传统维文一体化的多形式维文决策树的构建。经过预处理准备好的拉丁维文和传统维文文档流经决策树的方法,实现多形式维文敏感信息的过滤,如图2所示。

图2 多形式维文敏感信息过滤算法流程图
3.1 ULTC编码转换算法设计
ULTC 算法的主要功能是,根据传统维文和拉丁维文的Unicode 编码特征和表1 中的对应关系,把传统维文词语转换成对应的拉丁维文词语(如:传统维文词语(新疆),转换成拉丁维文词SHinjang)。
拉丁文编码是按顺序排列的,而传统维文编码在Unicode 编码表的阿拉伯区内是分散分布的,如图1 所示,所以拉丁维文与传统维文编码间有不连续现象。因此,创建一个二维数组LU[Li,Ui],(i=1,2,…,32),其中Ui是32 个传统维文词首字母,Li对应32 个拉丁字母,再建一个维文字库表UCB(Uyghur Character Base),保存32 个传统维文字母的125 种字形,可以网上下载。ULTC 算法如式(1)所示,其中UWi是用户输入的传统维文词语,n是该词的长度,i=1 时读取UWi中的第一个字母,LU数组中找到对应的拉丁维文字母,保存到拉丁维文目标词LWi中,依此类推,做到i=n为止。
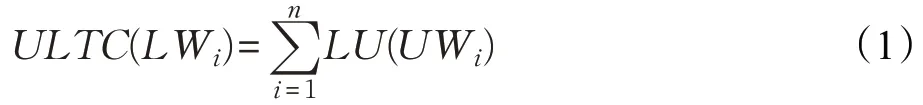
具体ULTC编码转换算法过程如下所示:
1. Public LU[2,36],UCB[3,36],UW,LW as string /*定义拉丁文与传统维文对照数组和维文字库*/
2. 根据数组LU 中输入内容,创建字母对照表。
3. 由传统维文的125种字形创建传统维文字库UCB。
4. 读取UW中的第一个传统维文字母编码。
5. 使用二分法在LU中查找对应行数。
6. 读取第二字段中对应的拉丁文字母,保存到拉丁维文目标词LW中。
7. 检查循环是否结束(循环变量是否大于UW的长度),如果是跳转下一步,否则返回第4步继续寻找。
8. 形成UW对应的拉丁维文敏感词。
3.2 ULSC多形式维文敏感信息语料库构建
多形式维文敏感信息语料库ULSC 是为决策树的构建提供语料信息。敏感关键词的语义与其字形无关,因此在现有的传统维文语料库的基础上,增加一些新的传统维文敏感词,用ULTC算法把它们转换成对应的拉丁维文敏感词录入语料库ULSC 即可。根据敏感信息在互联网的分布情况,主要在贴吧、微薄、Ulinix的论坛和新闻评论中采集传统维文的敏感信息,由于敏感信息随着时间和事件的发展而不断更新,每隔一段时间要对敏感信息语料库进行更新并记录更新的始末位置,语料库的起始位置前和结束位置后添加特殊符号标记起始位置和结束位置,这样下次更新语料库时只需要从起始点标记处开始录入,完成后将标记的位置移动到录入截止的位置。这样就保证了敏感信息决策树随着敏感信息语料库的扩大而实时更新。ULSC由两个区域组成,传统维文语料区和拉丁维文语料区,首先采集传统维文的敏感信息语料,ULTC编码转换算法把它转换成拉丁维文语料,并存入ULSC的拉丁文区,如图3所示。
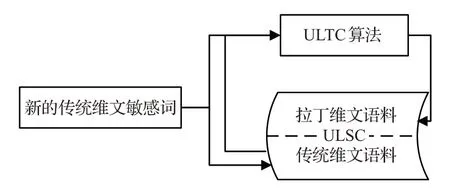
图3 ULSC构建流程图
3.3 LUDT多形式维文敏感信息决策树构建
传统维文虽然由32 个字母组成,但有125 种字形,这对决策树的构建和查询带来很大的不便。因此,鉴于拉丁维文的字形优势,首先构建拉丁维文决策树。决策树中的节点包括:叶子节点,该节点没有孩子的节点,包含维吾尔敏感信息语料库拉丁区中的最后一个拉丁维文单词;非叶子节点,决策树中有孩子的节点,包含的信息不是维吾尔敏感信息语料库拉丁区的最后一个拉丁维文敏感词;伪叶子节点,该节点在决策树中有孩子节点,包含的信息是语料库中最后一个拉丁维文敏感词[16]。
首先在ULSC的拉丁区中读取敏感词,然后添加到决策树中。为了提高决策树的查询速度和效率,在构建决策树时将根目录的子树按照拉丁字母顺序排列,在下面的每一棵子树按照敏感词的第二个字母排列,如果第二个字母相同则按照第三个字母排列。首字母A 的为第一棵子树,首字母Z的是最后一棵子树。相同前缀词的关键词只需存储在相同的前驱节点,这样敏感词相似时,大量减少冗余和节点数,如对Namayix(游行)、Namayix wahti(游行时间)、Namayix orni(游行地点)等敏感词,Namayix wahti 和 Namayix orni 在 Namayix的下一层。这样可以进一步缩小维吾尔文敏感信息决策树所需要检索子树的范围,并且需要检索信息的最大长度不会高于决策树的高度。每当决策树需要更新时,只需更新维吾尔文敏感信息词汇中不同的后缀部分,降低了更新决策树算法的时间和空间复杂度。另外,针对每一个节点,通过多形式敏感信息库ULSC的传统维文区中找到对应的传统维文敏感词,并添加到该节点中,实现拉丁维文和传统维文敏感词的同步查询。ULSC的信息量越大时,决策树的冗余也会很高,这时在决策树中调用ULTC 算法来实时形成对应的传统维文敏感词,有效控制决策树冗余。
在决策树中某一个节点是否叶子节点,使用Leaf作为敏感词是否结束的标志,如Leaf=1是叶子节点,Leaf=0是非叶子节点,Leaf=9是伪叶子节点。下面以Anangni(妈的)、Ah tamaka(海洛因等各类毒品的总称)、Namayix(游行)、Namayix wahti(游行时间)、Namayix orni(游行地点)等敏感词为样例构建敏感信息决策树,如图4所示。
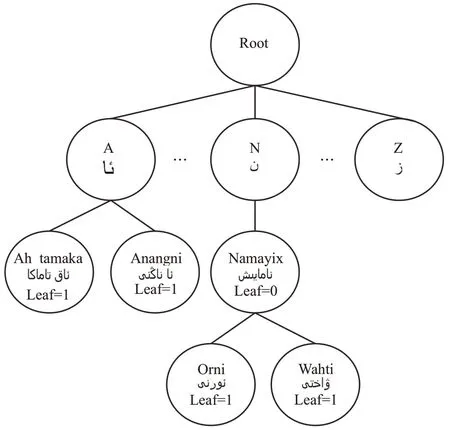
图4 多形式维文敏感信息决策树
定义1 多形式维文敏感信息语料库ULSC(U,L),其中U={u1,u2,…,ui,…,un}是传统维文敏感信息集合,L={l1,l2,…,li,…,ln} 是拉丁维文敏感信息集合,1 ≤i≤n,n是敏感词个数,U和L的敏感词按顺序一一对应,ui和li分别是传统维文和拉丁维文第i个敏感词,其中ui={p1,p2,…,pj},li={q1,q2,…,qj}(1 ≤j≤m),pj,qj分别是拉丁维文和传统维文敏感关键词,m表示关键词数,s0表示拉丁文关键词qi的首字母编码。
有关多形式维文敏感信息决策树的构建,首先创建一个根节点R(Root),根节点下再创建A~Z 的32 个子树节点,接下来ULSC中的拉丁维文和传统维文敏感信息按拉丁字母顺序添加到决策树上。具体LUDT 决策树的构建算法如下所示。
创建决策树T:创建一个根节点R,再创建包含信息A~Z的32个子树节点。
输入:多形式维文敏感信息语料库ULSC 中输入拉丁维文敏感信息集合L和传统维文敏感信息集合U。
输出:新的敏感信息决策树T*。
1. 初始化参数i=1,j=1;C设为当前处理节点,C=R。
2. 若i≤n,则获取li和长度m以及li中的第一关键词qj的第一个字母s0并执行第3步;否则跳转第8步。
3. 如果j >m说明T已经包含pj,跳转第6步;否则获取li中的关键词pj并校验C是否为R,如果是pj的节点赋值给C,执行下一步。
4. 查找C的子节点是否包含pj关键词的节点;如不包含将按照字母顺序创建新节点,将pj和它对应的传统维文敏感词qj添加到新节点,并令节点信息中的Leaf=0;否则该子节点赋值给C,令j++,并跳转第3步。
5. 将新节点赋值给C,j++;若j≤m跳转至第4 步;否则令节点C信息中的Leaf=1,且R赋给C,i++并转第2步。
6. 检测C是否有孩子节点,如有且Leaf=0则令Leaf=9。
7. 将根节点Root赋给C,i++并执行第2步。
8. 返回更新完成的决策树T*。
鉴于拉丁文的字形优势,算法中首先建立拉丁维文的决策树,节点按照拉丁文的字母顺序排列,添加节点内容时,拉丁维文和对应的传统维文敏感关键词都添加到节点中,便于检测敏感词是否结束,节点中还存放Leaf 的值。决策树的高度完全依赖于敏感词的长度。具有相同维吾尔文前缀词的敏感信息,决策树上只需存储相同的前驱节点,后缀词存储到前驱节点的孩子节点上,这样不但降低了空间复杂度,还提高了查询速度和算法效率。
3.4 USF多形式维文敏感信息过滤算法
多形式维文敏感信息过滤算法USF的功能是,将网上获取的传统维文和拉丁维文文本经过预处理后存储起来,然后以数据流的形式流经多形式维文敏感信息决策树,实现多形式维文网页文本信息的检测与过滤。为了提高决策树的检测效率,如果语料库中有相互包含的敏感词(如“Namayix”“Namayix orni wahti”)时,按照最大匹配的原则进行过滤。
本文收集的多形式网络文本信息包含传统维文网络文本信息和拉丁维文网络文本信息。多形式敏感信息决策树的每个节点也包含拉丁维文敏感信息和传统维文敏感信息,因此两种文字的信息过滤过程是完全一样的。下面以拉丁维文敏感信息的过滤来介绍算法具体流程。
定义2 拉丁维文网络文本信息集为W={w1,w2,…,wj,…,wn},1 ≤i≤j,n为文本长度,wi是信息集中的一个关键词;k0表示wi的首字母;设定wm是检测敏感词的起始点;wij表示wi和wj之间的文本信息。
拉丁维文文本信息检测算法要做的就是判断wij是否包含敏感词,若包含则该关键词为wmi。具体USF多形式维文敏感信息过滤算法如下所示。
输入:拉丁维文网络文本信息集W,多形式维文敏感信息决策树T。
输出:过滤后的拉丁维文文本信息集W*。
1. 初始化参数:i=1。
2.R赋值给C,获取wm;若i+(h-2) 3. 如果i >j跳转第6步,否则获取wij,wi,wj,k0,令i++,如果C=Root,则C的子节点中值为k0的节点设为C,执行下一步。 4. 查找C的子节点是否包含wi节点内容;如果包含,则该节点设为C,执行下一步,否则跳转第2步。 5. 如果C中 Leaf=0 跳转第 3 步,若 Leaf=1 则是敏感信息,使用*代替wij的值,跳转第3步。 6. 返回不包含敏感信息的拉丁维文数据集W*。 在进行多形式维文文档敏感信息过滤时,网上获取的维文文档通过预处理后,构成由若干个敏感词组成的集合W,W={US,LS},其中US={us1,us2,…,usn}是传统维文关键词集合,LS={ls1,ls2,…,lsn}是拉丁维文关键词集合。多形式维文敏感信息语料库ULSC 是由一系列拉丁维文和传统维文敏感词组成的集合,ULSC={U,L}={q1,q2,…,qn,p1,p2,…,pn},其中传统维文敏感词L和拉丁维文敏感词U是一一对应的,对语料库ULSC,如果或,则US或LS是多形式维文决策树上的基本节点。下面针对拉丁维文,提出敏感值的计算公式。 维文文档敏感值UDS(Uygur Document Sensitivity),拉丁维文关键词集合LS,关键词的个数为N,和LS匹配的语料库L中的敏感词个数为M,L的敏感值为: 敏感值可以表示该文档的敏感程度,网上获取的文档敏感值过高,表示该文档对社会安全不利,及时向相关部门反馈,避免一些不好的社会事件发生。 表2 ULTC算法实验结果 本文对传统维文与拉丁维文Unicode 编码转换算法ULTC和多形式维文敏感信息过滤算法USF,进行了实验研究与测试,并对测试结果进行了分析。实验由两个步骤进行:第一步是ULTC 编码转换算法的测试;第二步是多形式维文敏感信息过滤算法USF的性能测试。 (1)实验环境 本文所有实验在一台Intel®Pentium®CPU B940@2.4 GHz,内存为4 GB的笔记本PC上完成;在Windows7 32 位系统下进行;实验采用Java 语言开发,开发工具Myeclipse2015,运行环境为Tomcat7.0。 (2)前期准备 建立多形式维文敏感信息语料库。首先收集传统维文敏感信息语料,部分敏感信息在网络上下载,下载的主要网站包括维吾尔语论坛、Ulinix、贴吧、新闻下的评论、个人微博下的评论等,因为这些地方话语比较自由,可以获取敏感信息。另一部分敏感信息从书籍、杂志和一些文章中获取。除此之外还使用一些常见的中文敏感词汇进行翻译以对其进行补充。最终收集了传统维文的1 000 个敏感词。通过ULTC 转换算法,把传统维文敏感词转换成对应拉丁维文敏感词,实现2 000 个敏感词组成的多形式维文敏感语料库。为了方便多形式维文决策树的构建,敏感语料库进行简单预处理,语料库由传统维文区和拉丁维文区组成,使每个敏感词独占一行,并且拉丁维文敏感词和传统维文敏感词顺序一一对应。为了更好地观察决策树更新后的查全率,将1 000个敏感词分成两部分,第一部分包含700 个敏感词,在对网络维吾尔文文本信息过滤前添加到语料库中,剩下的300个敏感词在第二次文档过滤时添加到语料库中,这样可以观察决策树更新前与更新后的效率。提前在敏感信息较多的Ulinix、贴吧、维语论坛等网站上下载包含传统维文和拉丁维文的300篇网页,进行预处理后整理出每篇5 000 字左右的4 篇文本文档,其中两篇是传统维文,两篇是拉丁维文的TXT文档。 本文的实验数据是语料库中收集的1 000个传统维文敏感信息关键词,这些敏感词通过ULTC编码转换算法转换成对应的拉丁维文敏感词,并添加到语料库中。采用人工方式和维软(Uyghur Soft)公司开发的AlKatip软件的多形式维文词汇库来测试ULTC 编码转换算法的正确率,测试结果表明正确率已达到了100%,如表2所示。 多形式维文敏感信息决策树包含拉丁维文和传统维文的敏感信息,USF算法使用同一个决策树来实现不同形式的维文文档的敏感信息过滤,并脱离了多形式维文敏感语料库的依赖。决策树按照拉丁文的编码顺序排列,简化了传统维文字形复杂度给决策树带来的查询复杂度,提高了检测效率。 实验由两个步骤组成:第一步是拉丁维文文档的敏感信息过滤,分别对决策树更新前和更新后的状态进行敏感信息过滤;第二步是传统维文文档的敏感信息过滤,也是分别对决策树更新前和更新后的状态进行过滤。根据实验结果计算出了USF 过滤算法的查全率和文档的敏感值,实验结果如表3所示。 表3 USF算法实验结果 ULTC编码转换算法的准确率达到了100%,表明多形式维文语料库中的拉丁维文敏感词和传统维文敏感词完全一一对应。根据表3可以发现,不管是传统维文还是拉丁维文,USF敏感信息过滤算法的查全率在决策树的更新有所下降,传统维文的下降幅度更高,除此之外传统维文的查全率比拉丁维文低。主要原因是决策树按照拉丁文的字母顺序排列的,传统维文敏感词直接添加到对应的拉丁维文敏感词的节点上,因此决策树上传统维文敏感词的顺序是比较混乱的,使得部分敏感词在决策树更新过程中未能完成节点的添加或错点添加,这样算法就无法找到该节点,造成查全率的降低。本实验结果与文献[17]中的中文敏感信息过滤相比,查全率明显低于文献[17],主要原因是汉字的字形和语义优势,加上汉字拼音配合决策树的使用,简化了匹配的查询复杂度,提高了检索效率。根据表3还可以看出文档的敏感值过低,主要原因是多形式维文敏感语料库和下载整理的文档综合性比较强,没有彼此之间的针对性。除此之外,实验中使用的文档大部分内容是网上下载的,近几年新疆维稳和网络监控工作力度的加大,网络敏感信息数量大幅下降也有关系。 多形式维文敏感信息过滤算法的研制对目前新疆社会稳定和长治久安总目标的实现具有非常重要的意义。本文提出的多形式维文敏感信息过滤算法实现了网络媒体上的传统维文和拉丁维文敏感信息的过滤,弥补了现有的维文敏感信息检测与过滤系统不支持拉丁维文的空白。由此,本文的研究成果对新疆的网络安全和社会稳定工作具有重要的实际意义。未来工作包括:进一步优化多形式维文敏感信息决策树的结构,引入领域本体的概念来提高决策树和文档的针对性,从而提高过滤算法对传统维文和拉丁维文敏感信息的过滤效率。3.5 敏感值计算方法


4 实验与分析
4.1 实验环境与前期准备
4.2 ULTC文字编码转换算法实验
4.3 USF算法性能分析

4.4 实验结果分析
5 结束语
