雾计算中基于DQL算法的伪装攻击检测方案
2020-05-20涂山山于金亮
孟 远,涂山山 ,于金亮
1.北京工业大学 信息学部,北京 100124
2.可信计算北京市重点实验室,北京 100124
1 引言
在过去的十年中,由于移动互联网流量呈指数级增长,移动设备引导着无线通信和网络的显著发展[1]。其中,蜂窝异构网络、毫米波通信及多输入多输出(Multiple-Input Multiple-Output,MIMO)技术为下一代用户提供了千兆无线网络接入服务,使得处理效率低下的移动设备也能够借助远程云数据中心的高处理能力和大内存存储能力运行各自的计算服务[2]。然而在云计算中,不同的用户、应用程序会在不同的时间、位置生成和利用数据,如语音服务、视频服务和游戏等产生的数据都与用户的时刻位置有关,这将导致不同的应用程序需要更高的处理和存储要求,并且不同的应用程序数据在执行时往往没有考虑用户的移动性[3]。当前,云服务器与终端用户的距离较远,而大量物联网设备的加入使得终端迫切需要低延迟、位置感知等能力。因此,传统云计算不再适用于新一代移动物联网网络,雾计算的出现弥补了新的应用场景的缺失。在雾计算网络中,处理数据的应用程序运行于依据地理位置分布的雾节点中,大多数雾节点与终端通过无线网络连接,雾节点之间也存在高频率互动。然而,由于雾节点与终端用户间的行为在无线网络中往往容易暴露,雾计算网络容易受到恶意用户的伪装攻击。同时,现有的方法大多通过使用应用层的安全技术保护雾计算网络,而没有考虑物理层安全技术在雾计算网络中的应用,缺少对无线信道移动随机性的研究,而对物理层安全技术的研究可以增强密钥的安全性,使密钥基于无线信道由双方直接生成,不需要密钥管理中心及密钥分发过程,并且物理层安全技术独立于计算复杂度,能够简单高效地解决安全问题。因此,本文基于物理层安全(Physical Layer Security,PLS),提出一种基于DQL(Double Q-learning)算法的雾计算伪装攻击检测方案,贡献如下:
(1)设计了在静态环境中非法节点(雾节点和终端用户)与接收端之间的零和博弈,通过在接收端建立基于信道状态信息(Channel Status Information,CSI)的假设检验,解决了用于检测伪装攻击的阈值问题。
(2)提出了基于强化学习中的DQL 算法在动态环境下检测伪装攻击的方案,实现了对检测阈值的优化。
(3)通过与常用Q-learning 算法比较误报率(Fault Alarm Rate,FAR)、漏检率(Miss Detection Rate,MDR)、平均错误率(Average Error Rate,AER),证明了该方案能够解决Q-learning 算法中的Q 值过度估计问题,降低FAR、MDR 和AER,提高伪装检测的准确率,增强雾节点与终端用户间的安全性。
2 相关研究
雾计算中恶意用户的伪装攻击指的是雾节点或者终端用户使用虚假的媒体访问控制地址(Media Access Control Address,MAC-A)冒充合法节点向其他节点发送数据,以此实现中间人攻击和拒绝服务攻击,从而获取非法收益。为了识别伪装攻击,可以利用物理层技术实现雾节点与终端用户间的无线网络安全通信。物理层安全技术利用无线信道中标志着无线链路物理层特征的信道参数识别伪装攻击,这些信道参数包括信道频率响应(Channel Frequency Response,CFR)、接收信号强度指示器(Receiving Signal Strength Indicator,RSSI)、信道状态信息(Channel Status Information,CSI)、接收信号强度(Receiving Signal Strength,RSS)。当前,终端用户与雾节点间的环境是动态的,移动终端不断运动,信道也随之改变,使得接收端难以识别非法数据包。为了应对动态环境中的伪装攻击问题,最新的研究利用强化学习中的算法,在动态环境中寻找用于检测伪装攻击的最优阈值的方案[4]。
雾计算可以为终端用户提供计算、存储等服务,但是也存在很多安全问题,如数据信息、密钥信息易泄露,易受到窃听、干扰攻击等。面对这些问题,研究人员提出了不同的解决方法。文献[5]提出了一种安全可验证的矩阵外包方案,该方案将矩阵求逆任务从客户端交由雾服务器执行,使用混沌系统为矩阵加密,保证了矩阵在服务器端的安全。然而,此方法对身份验证和攻击模型的考虑较少。文献[6]研究了一种基于5G的网络服务链模型,并且针对雾层的cloudlet服务实现了处理DDoS(Distributed Denial of Service)攻击的终端用户身份验证方法,但此方法使用了多个验证票据,步骤较为繁琐。文献[7]提出了基于属性加密的密钥交换协议,结合数字签名技术,实现了保密性、身份验证和访问控制。文献[8]介绍了一种基于雾的重复数据删除空间众包框架,解决了终端与雾节点间任务与感知数据安全传输问题,但是计算复杂度较高。
综合上述研究,由于雾计算网络中存在伪装攻击,并且现有研究大多使用应用层安全技术,缺少对物理层安全的研究,因此本文提出了基于物理层安全和DQL算法检测伪装攻击的方案。
3 模型构建与假设检验
本文构建了一个雾节点层与用户层间的伪装攻击网络模型,并且在接收端建立用于检测攻击的假设检验。
3.1 安全模型构建
本文的网络模型面向雾节点与终端用户,考虑雾节点与终端用户间的无线网络,如图1所示。假设有a个发送端,r个接收端,h个合法节点和i个非法节点,其中:
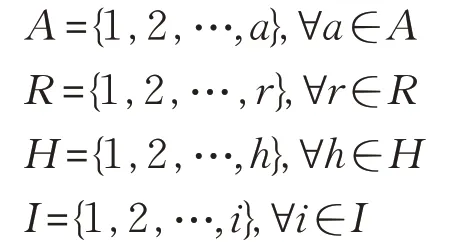
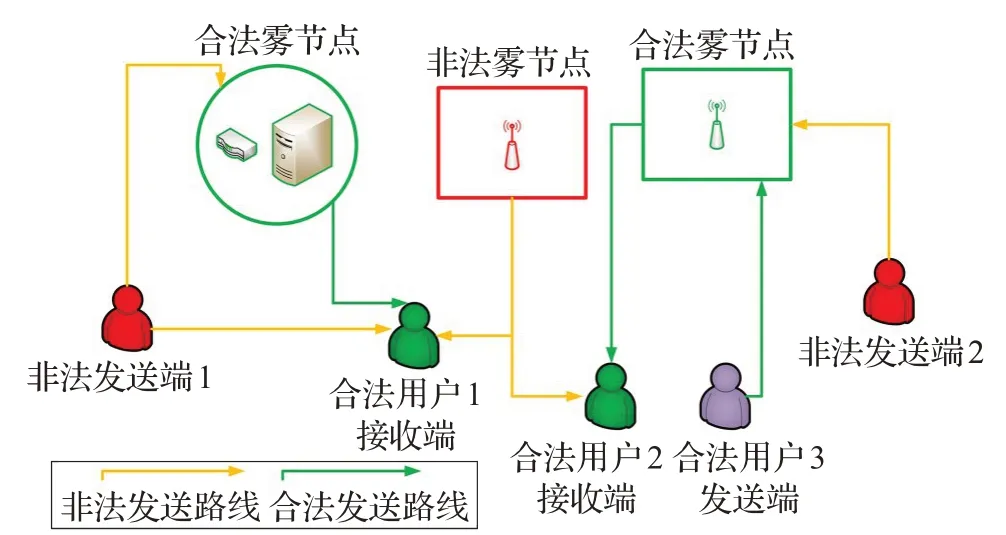
图1 伪装攻击网络模型
非法节点表示带有虚假MAC-A 地址的节点,它可以是雾节点,也可以是终端用户节点。同时该节点可以假冒终端用户向雾节点或终端用户发送数据包,也可以假冒雾节点向合法用户发送数据包。非法用户在一个时隙内发送一个虚假MAC-A 地址的概率为pj∈[0,1]。第a个发送端的MAC-A地址为αa∈θ,∀a∈A,其中θ是表示所有MAC-A地址的集合。每个接收端收到每个数据包后均估计其相关的CSI,并提取数据包的信道向量,接收端接收的数据包的信道向量被称为信道记录。例如,数据包的导频可以用于发送端的信道响应估计。因此,第a个发送端发送的第t个数据包的信道向量为,第a个发送者发送的第t个数据包的信道记录为,x表示第t个数据包的第x个信息[9]。
3.2 假设检验
假设检验用来验证数据包的身份,合法节点发送的数据包的信道向量为,合法节点的MAC-A 地址为,假设Η0表示MAC-A 的数据包是由合法节点发送的,假设Η1表示MAC-A的数据包是由非法节点发送的,如下所示:

物理层安全中,CSI表明了信道特征,它是唯一的,接收端提取CSI 可以验证数据包。如果信道向量与信道记录相同,那么发送端发送的数据包被认为是合法数据包,接收端接收;否则,数据包被认为是从非法节点发送而来,接收端拒绝接收。假设检验的统计量为:


因为欧式距离的值S大于等于0,所以阈值也大于等于0。定义误报率PA与漏检率PB:

其中,PR为条件概率,误报率表示合法节点发送的合法数据包被检测为非法数据包的概率。漏检率表示非法的数据包被检测为合法数据包的概率。接收端接收(6)中合法节点发送的合法数据包的概率和接收端拒绝(7)中非法数据包的概率分别为[4]:

根据假设检验,假设测试阈值的大小影响伪装攻击检测的精确率,当阈值增大时,漏检率随之增加,另一方面,当阈值减小时,误报率也会增加。除了物理层安全检测,接收方也应该设定高层数据包检测(Higher Layer Authentication,HLA),检测经过物理层验证的数据包,最终接受所有通过检测的数据包,每个数据包被接受时,,若不被接受,。
综上所述,通过在接收端建立假设检验,可以为伪装检测设置一个检测统计量,以便于将其与测试阈值进行比较,判断每一个接收到的数据包是否是合法数据包。
4 静态和动态伪装检测
本章主要介绍静态检测中基于博弈论的效用计算和动态场景中使用DQL算法检测伪装攻击的方法。
4.1 静态伪装检测的效用计算
在静态伪装检测中,在接收端建立假设检验并选择阈值检测伪装攻击,使用零和博弈计算接收端的效用,其中有F个非法节点和N个接收者[10]。非法节点发送非法数据包的概率为pj∈[0,1],1 ≤j≤F,发送非法数据包的集合为Y=[pj]1≤j≤F,非法节点之间可以互相协作,假设在一个时隙中只有一个非法节点进行伪装攻击,接收端接收到一个非法数据包的概率为。另外,接收端接收合法数据包的收益为g1,拒绝非法数据包的收益为g0,接收端拒绝合法数据包的成本为C1,接受非法数据包的成本为C0。因此,伪装攻击先验分布下伪装检测的贝叶斯风险[11]为:

上式中第一项为合法数据包的收益,第二项为伪装攻击产生的收益。因此,在零和博弈中,接收端的收益为:

在式(11)中,λ为接收端选择的测试阈值,λ∈[0,∞)。在实际的场景中,节点具有移动性,是动态变化的,对接收端来说,它不知道完整的信道状态,因此,在下一节中将采用DQL算法寻找动态环境中的最优测试阈值。
4.2 动态伪装检测
DQL算法是强化学习算法,它改进了Q-learning算法。DQL 与Q-learning 都可以在动态环境中得到不充分信息的最优策略[12-13]。相对于Q-learning 算法,DQL解决了Q值过度估计的问题[13]。
在动态伪装检测中,接收端构建假设检验,评估每个时隙中发送来的T个数据包,利用测试阈值检测它们的发送者是合法节点还是非法节点。将测试阈值分为L+1 级,λ∈{l/L},0 ≤l≤L ,接收端在时刻τ的状态表示为sτ,它指的是在时刻τ-1 处的 FAR 与 MDR,表示为,其中D为接收端所有状态的集合。因此,误差率同样被量化为L+1 级,它们的值与测试阈值相关。根据DQL 算法,接收端在每个状态下选择动作,其获得的立即收益如下式所示:

DQL 算法使用了两个Q 值表Q1和Q2,它们互相选择最大Q值和动作,弥补错误。接收端使用ε-greedy策略在每个状态选择动作,以ε的概率选择次优动作,以1-ε的概率选择使当前状态下最大的动作[14],概率值为:
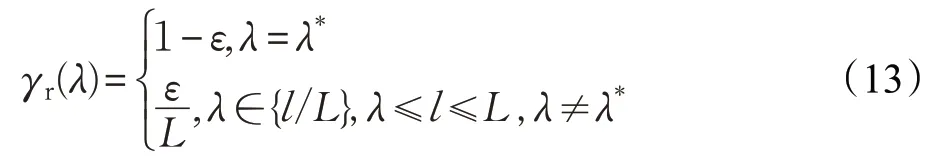
在DQL算法中,μ表示奖励性衰变系数,μ∈(0,1),学习效率δ表示下一状态可能带来的收益,δ∈(0,1),更新公式如下:
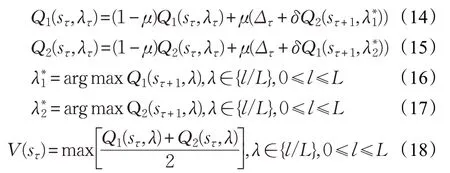
式(18)表示当前状态中对应于各个动作下Q1+Q2的均值最大值。因此,最佳测试阈值为:

式(19)计算的是在每个状态下使两个Q 表收益和最大的动作。
根据上述公式,获取最佳阈值和最大化效用的DQL算法步骤总结如下:
步骤1 初始化,给ε、μ、δ、Q1(sτ,λ)、Q2(sτ,λ) 赋初值,其中 ∀λ∈{l/L},0 ≤l≤L。
步骤2τ=1,2,…,在当前状态sτ下,选择测试阈值λτ,用于判断当前状态与前一状态间的时隙内所有数据包的合法性。
步骤3 接收端a接收到一个数据包,观察MAC-A地址,αa∈θ,∀a∈A,提取信道向量和信道记录,即和。
步骤4 使用式(3)计算欧式距离。如果,那么将这个数据包发给HLA处理,并且,接收这个数据包;否则拒绝这个数据包。此步骤用于判断接收到的数据包是否是合法数据包,接收合法数据包,丢弃非法数据包。
步骤5 重复步骤3 和步骤4,直到接收端处理完一个时隙中接收到的T个数据包。
步骤6 进入下一个状态sτ+1,根据式(12)计算Δτ,以0.5的概率使用式(14)更新Q1(sτ,λτ),以0.5的概率使用式(15)更新Q2(sτ,λτ),并且使用式(18)更新V(sτ),获取当前Q值平均值的最大值。
步骤7 返回步骤2 继续执行,重复步骤2~步骤6,直到达到目标状态,完成优化公式(18)、(19)所表示的最大Q值和最优测试阈值的过程。
5 仿真实验
假设检验中,FAR与MDR基于DQL算法的计算公式如下[15]:

其中,Fx22M是2M自由度的累积分布函数,接收端以σ2获得发送端的平均功率增益,ρ为合法数据包的信号与干扰加噪声比(Signal to Interference plus Noise Ratio,SINR)。b为信道增益的相对变化,k为伪装者的信道增益与发送端的信道增益比。
仿真实验针对本文提出的基于DQL算法检测伪装攻击的方法与基于Q-learning算法检测伪装攻击的方法进行对比,并将两种算法在FAR、MDR、AER 和最大Q值这四个方面进行比较。本文的实验环境模拟为20 m×20 m 的房间,房间内的节点随机分散,所有的信道增益服从常规分布ξ(0,1)[4]。假设同一时隙内接收端处理T=20 个数据包,设定信号的中心频率为f0=2.4 GHz,其中相关的初始值设置为g1=6,g0=9,C0=4,C1=2。根据4.2 节描述的DQL 算法中参数的取值范围,本实验假设ε=0.5,μ=0.4,δ=0.8。同时,为了计算FAR、MDR和AER的值,本文根据实验环境选择了合适的初值ρ=10 dB,k=0.2,b=3 dB[4],实验用到的初始化参数及意义见表1。

表1 仿真实验用到的参数值及意义
在初始化参数下,1~100 次连续实验中,基于DQL算法进行伪装检测和基于Q-learning算法进行伪装检测的FAR值对比如图2所示。

图2 两种算法的FAR值对比图
随着实验次数的增加,算法中的阈值也在不断变化,在DQL算法中,根据式(20),FAR值先降低,但随后大体保持在23.3%~23.7%之间。这是因为进行多次实验后,随着接收端收到的比特数增加,每当选择最优阈值检测伪装攻击时,算法都会利用之前多次检测攻击的经验选择最优检测阈值,一定实验次数后,最优测试阈值差别减小。另外,根据雾计算无线网络动态变化的特点,信道衰落的不同导致信道向量有所差别,因此FAR值小幅波动,但大体保持在恒定范围内。与Q-learning算法相比,在大部分实验次数下,DQL算法的FAR值较低,这是由于接收端使用两个Q 表互相弥补估计误差,增加了收益估计的准确率,使其选择了更合理的阈值。因此,在使用基于DQL算法检测伪装攻击时,接收端接收到合法数据包但将它视为非法数据包并丢弃的可能性更低,从而增加了合法数据包的接收率,提高了雾节点与终端用户间通信的安全性。
相似地,在初始化参数下1~100 次连续实验中,两种算法的MDR值比较如图3所示。
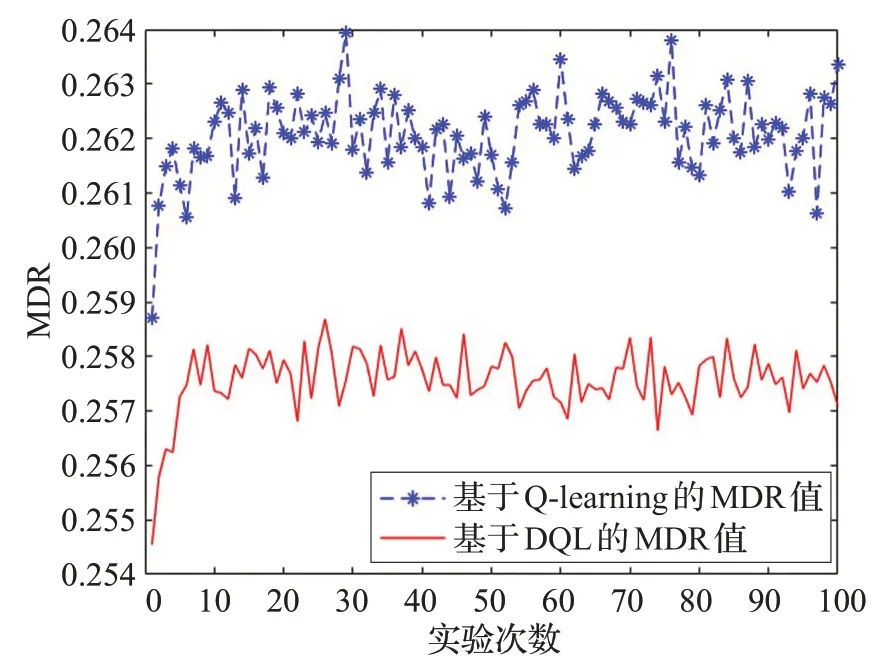
图3 两种算法的MDR值对比图
很明显,由于接收端的Q表初始值全为0,前期实验中所选择的最优阈值较小,随着实验次数的增加,当最优阈值增大时,根据式(21),与FAR 值相反,MDR 值有较小幅度的增加。一定实验次数后,因为每次实验的信道向量和选择的最优阈值有微小差异,导致MDR 值在小范围内上下波动,但其值已经稳定下来,大体保持在恒定范围内。另外,DQL 算法的MDR 值比Q-learning算法更小,因此,在DQL 算法下,接收端接收到非法数据包但将它视为合法数据包并接受的可能性更低,增加了非法数据包的丢弃率,提高了雾层与用户层间通信的安全性。
基于FAR和MDR值,本实验再次比较了在ρ=10,b=0.2,k=3 时,1~100次优化测试阈值的实验过程中两种算法的平均错误率,其结果如图4所示。
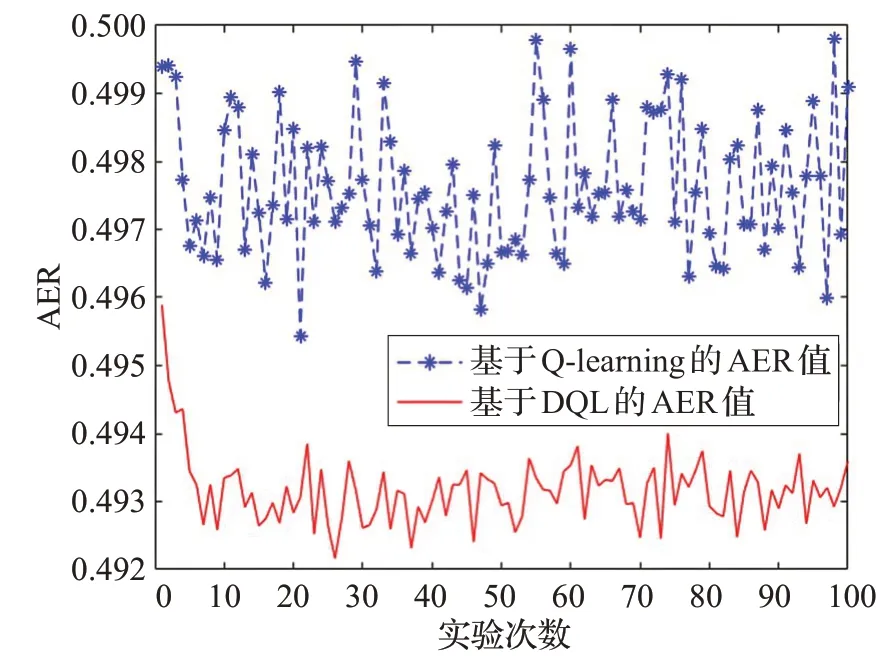
图4 两种算法的AER值对比图
AER表示在固定网络模型中,给定的初始化参数条件下伪装检测的平均错误率,计算公式如下:

与FAR、MDR一样,随着接收端判断并接收了更多比特的数据包,它学习到了许多选择最优阈值的经验,平均错误率保持在恒定范围内。可以看到,使用DQL算法检测伪装攻击的AER 值比使用Q-learning 算法检测伪装攻击的AER 值小,因为AER 值是综合FAR 值、MDR值计算得到的。因此,在接收端使用DQL算法检测合法节点和非法节点发送的数据包的性能优于使用Q-learning算法,它可以提高伪装攻击检测的精确度,减少在雾计算网络下接收端受到伪装攻击的概率。
最后,本实验比较了两种算法在初始化参数设定下1~100 次连续实验过程中共5 000 个状态下的最大Q值。结合前文所述的错误率分析,由图5 可以看出,在每个状态下DQL 算法的最大Q 值比Q-learning 算法的最大Q 值小,这是由于接收端使用的DQL 算法借助两个Q 表相互弥补收益的估计误差,处理了Q-learning 算法存在的Q值过度估计问题,使得每个状态下收益的估计值更加精确,从而对每个状态下的阈值选择产生影响。即优化了最优阈值的判断,选择更合适的阈值检测数据包的合法性,进而降低了FAR、MDR 和AER 的值,减少了接收端受到伪装攻击的数量。综合上述实验,基于DQL 算法的伪装攻击检测优于基于Q-learning 算法的伪装攻击检测。
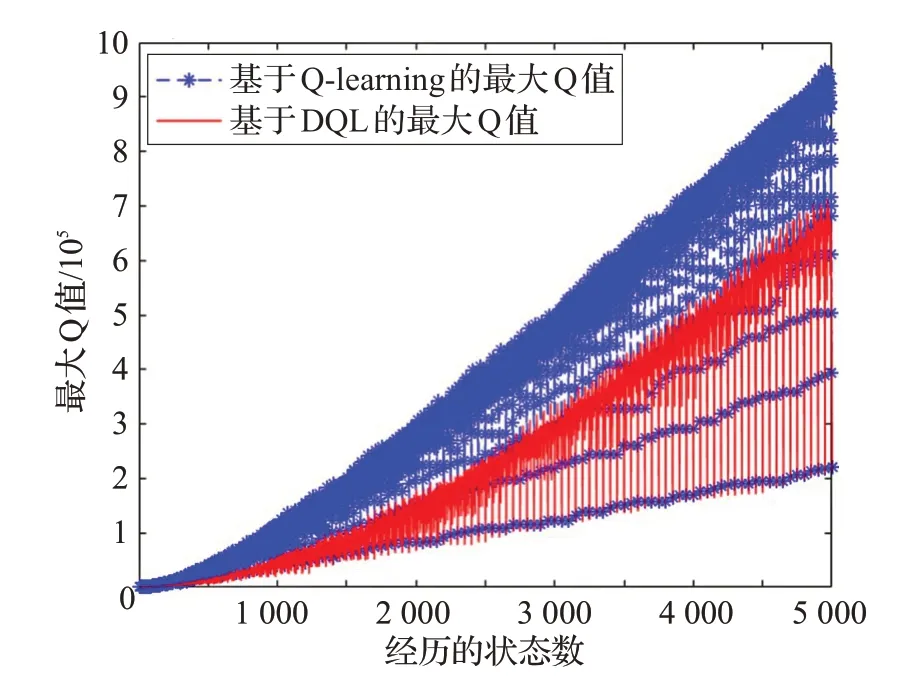
图5 两种算法的最大Q值对比图
6 结束语
本文分析了雾计算网络中雾节点与终端用户易受到伪装攻击的缺陷,提出一种利用雾节点与终端用户之间的无线信道特性检测伪装攻击的方案。该方案首先在接收端建立假设检验,利用静态伪装检测,基于零和博弈计算接收端和伪装者的收益;其次,将假设检验和博弈论的方法用于动态伪装检测中,设计了一个基于强化学习DQL算法获取伪装检测最优阈值的方案。仿真实验结果表明,基于DQL 算法检测伪装攻击能够降低误报率、漏检率和平均错误率,其检测性能优于使用Q-learning 算法的伪装攻击检测。在未来的工作中,将继续使用强化学习的方法解决各种安全威胁,比如窃听攻击、身份验证、干扰攻击、拒绝服务攻击等。
