机器学习技术在保单失复效管理工作中的应用
2020-05-18林鹏程唐辉鞠芳
林鹏程 唐辉 鞠芳
摘 要:为了保障保险公司长期稳健发展,保单管理工作须采取现代科技手段加以完善。文章通过对保险公司历史上大量不同时期失效保单特征进行分析,研究构建了基于Stacking多模型融合技术保单失复效模型。该模型能预测失效保单客户在短期内复效概率,并制定相关复效督导管理策略和差异化服务策略。通过基于帕累托法则的实证分析,采用Stacking多模型融合技术构建的失复效模型较其他集成算法构建优势明显,特别是将模型融入PDCA管理实践中,能够为保单精细化管理提供有效的数据支撑,具备良好业务价值。
关键词:Stacking;随机森林;XGBoost;LightGBM;保單复效;帕累托法则;PDCA
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2020)20-0088-06
Application of Machine Learning Technology in the Management
of Lapse and Reinstatement of Policy
LIN Pengcheng,TANG Hui,JU Fang
(Research and Development Center of China Life Insurance (Group) Company,Beijing 100033,China)
Abstract:In order to ensure the long-term and stable development of insurance companies,the management of policies must be improved by modern technology. The article analyzes the characteristics of a large number of lapsed policies in different periods in the history of insurance companies,and researches and builds a policy lapse and reinstatement model based on Stacking multi-model fusion technology. The model can predict the recovery probability of lapsed policy customers in the short term,and formulate related recovery supervision and management strategy and differentiated service strategy. Through empirical analysis based on the Pareto principle,the lapse and reinstatement model constructed by using Stacking multi-model fusion technology has obvious advantages over other integrated algorithm construction. In particular,the model is integrated into PDCA management practice,which can provide effective data support for the refined management of insurance policies and has good business value.
Keywords:Stacking;random forest;XGBoost;LightGBM;policy reinstatement;Pareto principle;PDCA
0 引 言
失效保单是指投保人与保险公司的保险合同以约定分期支付保险费;在投保支付首期保险费后(除合同另有规定外),投保人超过规定的期限六十日未支付当期保险费,从而进入合同效力中止状态。失效保单在保险合同效力中止期间发生的保险事故,保险公司不承担保险责任[1]。因此,如果保险公司(特别是寿险公司)中存在大量失效保单,潜在构成损害保险消费者利益的风险,极易引发投诉纠纷,影响公司及行业形象,同时可能滋生营销员个人违法犯罪行为[2]。
银保监会早在2015年明确做了关于《中国保监会关于人身保险失效保单专项清理工作情况的通报》,要求各大保险公司应建立失效保单定期清理工作机制,对人身保险失效保单进行实时监控和管理各保险公司采取失效保单管理的措施。在具体执行层面,往往采取两大方式:首先,防范失效保单产生,主要是通过加强保单续期率的管理,并且通过公司基本法来考核个人续收服务情况;其次,重点要严格控制失效保单数量管理,主要是定期对失效保单进行清查,进行复效督导管理(复效即指依照前条规定合同效力中止的,经保险人与投保人协商并达成协议,在投保人补交保险费后,合同效力恢复[3])。
然而,开展持续的失效保单复效督导管理工作难度较大,这里有三方面的原因:第一,有的寿险公司特别是在成立之初,由于急于扩大业务规模,容易形成了重售前、轻售后的管理氛围;第二,由于长期寿险保单,营销员一般只拿到客户投保前几期佣金,后期佣金过低或无佣金,造成营销员无动力去管理失效保单;第三,失效保单客户是否因遗忘或者资金周转不灵等非主动因素导致失效,复效需要营销员与客户逐一拜访联系,这对于从业多年的老业务员来说,由于客户数量较多,容易产生因新单压力怠慢老客户的情况。
综上所述,复效督导管理问题核心是平衡投入和产出效益的关系,即在不影响团队新单展业的同时,如何划分合理有限的团队资源,实现复效管控利益最大化。从管理学角度来看,存在对帕累托法则[4]的迫切需求:团队只需花20%的精力就能实现80%的复效管理目标。
因此,基于上述潜在需求,中国人寿保险股份有限公司研发中心AI小组在技术上希望根据历史经验结合大数据分析,及时寻找最佳的复效意愿客户群体;建立一套相关保单失复效预测模型,对客户复效意愿能够精准预测,在满足帕累托管理法则基础上,同时实现对失效保单客户的差异化服务管理。
保单复效业务属于个人协议支付场景;在金融領域智能化模型中应用,该类场景主要集中在银行信用卡还款、信贷催收等领域。例如:文献[5]通过SPSS软件对某银行原始用户数据进行处理,通过PCA对数据集中变量进行筛选,将用户分为违约和非违约两类,并通过实例说明逻辑回归方法在信用卡风险评估模型构建中的应用,并验证其可行性和有效性。文献[6]针对单一BP神经网络算法的不足,利用遗传算法对BP神经网络进行优化,并通过信用卡消费行为数据集验证,可以有效提高信用卡消费行为风险评估中的检测率和准确率。文献[7]利用贝叶斯网络模型,采用交叉验证法,对美国最大的P2P公司进行借款人信用体系预测。
在保险领域中,研究个人协议支付预测行为,特别是复效预测研究的相关文献较少,目前主要有保单续期缴费预测研究,比如文献[8]利用Logistic回归算法、KMO因子分析构建保单续期预测模型,验证模型的可行性。文献[9-11]分别从寿险公司基层管理视角,分析失效保单的成因、防范策略和应对建议。
上述方法在一定程度上为保单失复效预测模型提供了技术参考,但是考虑到大型保险公司的客户数据存储主要是以结构化为主,客户特征还存在稀疏性强的特点,往往更适合采用树形算法进行分类预测[12],为了提升单个决策树算法的稳定性,往往采用诸如Bagging、Boosting和Stacking等集成学习进行模型构建。
本文分别利用目前主流的RandomForest、XGBoost、LightGBM以及Stacking融合集成学习算法进行失效保单复效预测模型研究,进一步探讨模型在满足保单失复效帕累托管理法则的可行性,经对比分析,选择了Stacking多融合算法进行本文的机器学习算法;由于失效保单复效督导工作具有持续性要求,将保单失复效模型纳入PDCA管理模式[13],效果显著,可供后续类似场景参考使用。
1 相关集成学习技术简介
当前运用人工智能机器学习技术解决实际问题,大多数采取集成技术。机器学习中的集成技术,是指将多个单一功能的分类器,采取一定的策略进行组装结合,用以增强整体预测性能。单一功能的分类器也称基础分类器,例如决策树、逻辑回归等这种算法。通常来说,集成方式又分同质集成和异质集成。同种类型基础分类器组合在一起的叫同质集成,目前比较典型的有Bagging和Boosting这两种方式;不同类型基础分类器组合在一起的叫异质集成,目前比较典型的方式有Stacking方法[14]。
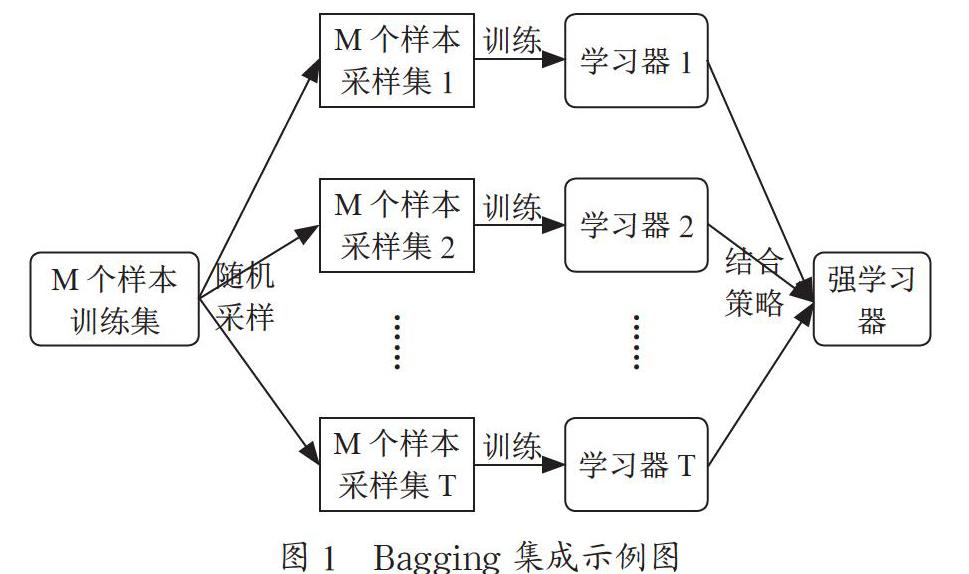
1.1 Bagging方式
如图1所示,主要是将同一集合的训练样本通过T次随机采样的方式形成T组大小与初始样本相同的采样集,分别对应T个弱学习器进行训练,采取一定的结合策略(分类场景使用投票策略,回归场景使用均值策略),最后形成一个强学习器。
如果学习器采用决策树作为基础分类器,该集成环境下比较典型的算法是随机森林(Random Forest),除了具有上述功能外,随机森林还有其他优点:自有的袋外估计(out of bagging,OOB)方法能够准确估计泛化误差,且更不易出现过拟合问题;算法抗噪声能力强,便于并行处理机制。
1.2 Boosting方式
如图2所示,主要是通过每个弱学习器预测结果相加,根据给定的损失函数计算集成模型中下一个弱学习器的预测内容和自身弱学习器的权重,通过反复迭代,最终形成一套强大的学习器的过程。
XGBoost[15]是Gradient Boosting的实现,每个学习器采用CART决策树的方式进行训练,同时在计算损失函数的时候引入二阶泰勒公式展开进行拟合,把新一轮对样本权重大小的要求转换为对新CART树结构的要求,通过采用近似精确贪心策略,遍历样本所有特征求解,计算最佳分裂点,从而形成强大分类器。
其优化过程如下:
(1)
其中,gi和hi为泰勒公式的一阶导数和二阶导数,L为总损失函数,l为每个样本的损失函数,yi为样本真实标注值,xi为样本特征,r为叶子参数,T为叶子结点个数,wj为样本正则。通过定义Ij={i|q(xi)=j}将上述公式中对所有样本进行最小损失计算,转换为对CART树的叶子节点要求。
(2)
当 时,具有最小的损失函数。
LightGBM[16],在原理上和XGBoost类似,但是在功能实现上主要采用基于直方图的方法将连续特征离散化,在选取特征分裂点的时候,只需遍历直方图;相对于XGBoost的预排序方法计算分裂增益,存储上降低了内存的消耗;另外在决策树的生长策略方面LightGBM采用的是leaf-wise的策略,即只选择最大增益的叶节点来生长;XGBoost是采取level-wise的策略,即对同级节点统一进行生长,最后留下增益最大的节点,策略上LightGBM的效率要高很多。
1.3 Stacking方式
如图3所示,该方式可对大型数据集(通常百万级别以上)使用的一种强化组合学习方式,该方式下的分类器分为两类。一类是初级学习器,通常可采用异质分类器,比如Bagging、Boosting方式下各种强分类器。经各自分类器训练后,采用交叉验证的方式获得每个样本的预测结果数据。另外一类是元学习器,通常采用非线性分类器(例如逻辑回归或者决策树等),将异质分类器的训练结果进一步训练,最终获得强大的分类效果。
根据研究表明,训练异质分类器需采用K折交叉验证的方式,避免让元分类器出现过拟合现象,同时将原始特征结合异质分类器获得的分类效果,可进一步丰富和完善原始样本的表征能力,这样结合元分类器效果更加显著,例如周志华教授的Deep Forest级联结构采用了此类方法[17]。
无论采用哪种集成方式,在性能方面较之前非集成的传统机器学习,都具有显著的提升。三种集成方式具有各自特点,本文将针对保单失复效训练数据逐一进行效果验证,通过对比挑选合适的集成算法。
2 实证分析-构建保单失复效模型
随着我司近些年来业务量不断攀升,在业务数据方面,特别是在保单续期管理过程中积累大量的历史数据。这些数据主要来源于两大业务领域,一方面来自客户续期缴费服务跟踪管理,这里包含客户缴费行为等特征数据;另外一方面来源于失效保单的复效跟踪管理,包含激励复效措施等分布特征数据。本文模型即基于这些数据进行实证构建。
2.1 样本情况
为了获取合理的样本分布,本文对我司过去20年内不同时点的处于两年内失效状态的保单进行抽样,将短期内(例如1个月)发生复效的保单定义为正样本,其余定义为负样本,其中剔除抽样重复的失效保单,数据情况如表1所示。
2.2 特征预处理
为了提升模型运算效率和降低特征的冗余度,需对特征做一系列处理。首先须通过统计缺失率、IV值以及相关系数等方法进行初步筛选;其次,针对将收入、保费等连续值特征进行对数化处理,用来消除因时间变化,相关统计量发生明显偏移的情况;同时,针对类型特征進行编码化处理,将整体数据集变成数值型变量;最后,采取LR模型、GBDT训练对特征进行二次筛选,筛选可能关联度较高的重要特征。
同时,根据现有客户保单缴费行为,基于RFM方式,进一步衍生计算客户交费习惯等特征。
最后,保单失复效建模特征将聚焦于保单属性、客户画像以及客户交费习惯三大类主题。
2.3 模型构建过程
如图4所示,整个模型构建过程,将失效保单训练样本总量进行合理拆分,分别为模型样本和验证样本。模型样本用于构建模型使用,训练模型的参数;其中取模型样本的一小部分(约10%左右)作为测试样本,用于调整模型参数,增强模型可用性。验证样本主要集中测试模型的泛化能力,评估模型的相关泛化水平是否达到预期的业务水平。
其中预测模型将分别使用RandomForest、XGBoost、LightGBM和Stacking融合算法进行构建。
为了使评估模型能力更加针对业务实际情况,在评估时不仅采用AUC、KS等技术指标进行评价,同时还须考虑模型的运行时效以及满足帕累托法则情况。
2.4 效果对比分析
为了得到充分合理的对比效果,需要对每一种算法进行参数调优,方法是采用网格搜索和贝叶斯调参优化结合,经过1 000次系统自动迭代,最优参数如表2所示。
其中RandomForest、XGBoost和LightGBM采用的是Sklearn库,Stacking融合算法采用的是mlxtend库。
经过模型多轮学习构建,得到相关性能指标如表3所示。
根据对比分析可以看出,Stacking融合算法效果最优;从算法执行效率来看LightGBM执行最快;但是同时可以看出XGBoost从预测效果角度略低于Stacking融合算法,但是从执行效率角度远快于Stacking融合算法,几乎与LightGBM相当。
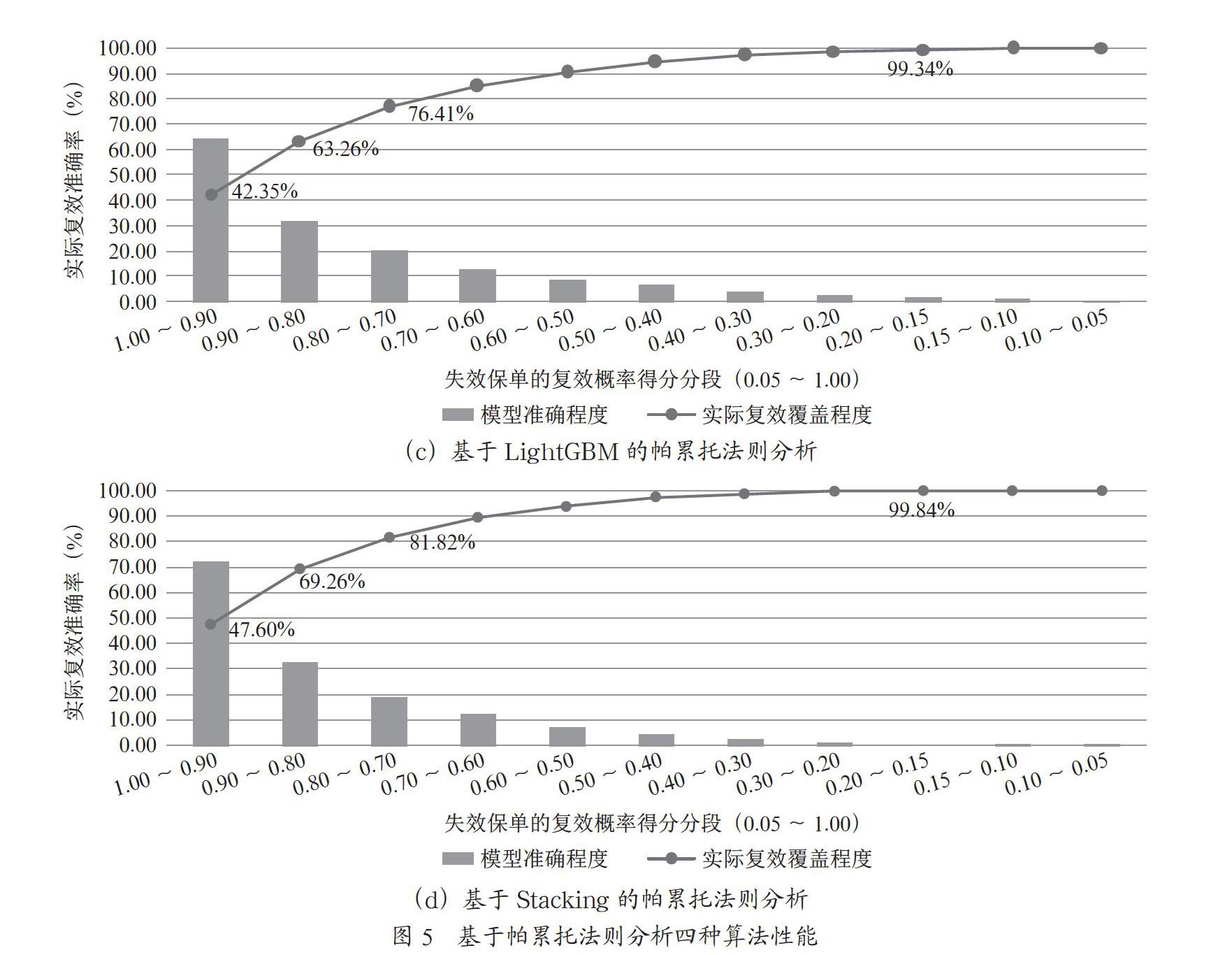
进一步地,结合我们保单失复效预测使用场景,使用帕累托法则进行分析,方框内容是为了便于四种算法对比效果分析,可以看出通过四种算法同样抽取模型得分在0.7以上的保单进行效果统计对应的数值来看,基于Stacking算法的效果最好,结果如图5所示。
从图5可以看出,Stacking融合算法相对具备较强的帕累托特性,即只需集中精力管理30.00%的全量失效保单,即可实现覆盖81.82%当月复效保单,而XGBoost算法,也基本上达到了80.00%的水平,从原理上来说,这两种算法都满足当初所设定的使用精简人力成本高效管理复效工作的目标。
由于保单失复效管理属于定期清查工作,本身对模型实时性响应要求并不那么严格,为了获得更好的泛化能力,本文的模型最终选取基于Stacking融合计算作为我们的建模算法。
3 实际应用效果
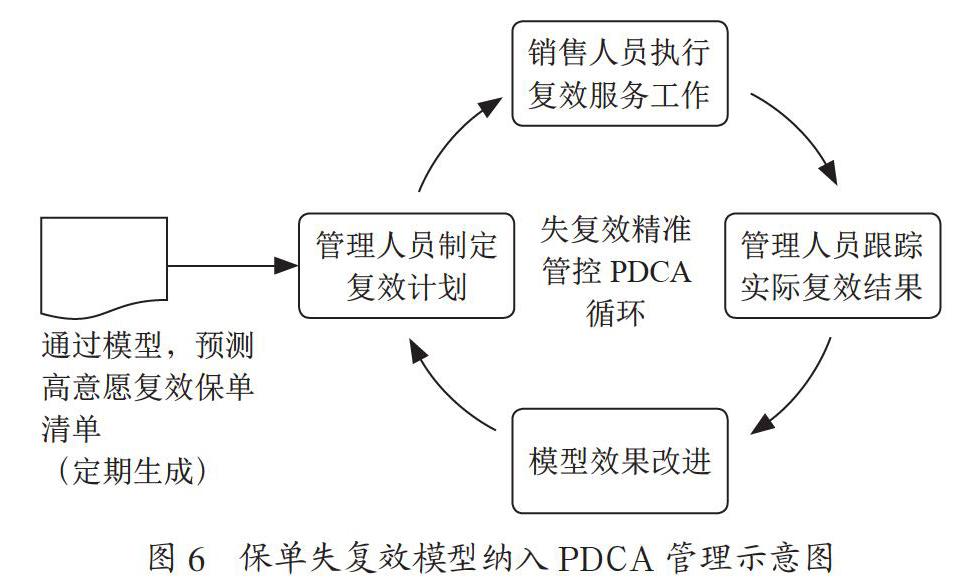
为了持续加强保单失复效模型所起的作用,在场景设计上,我们借鉴PDCA循环理论。如图6所示,通过模型计算复效概率得分,科学制定高复效意愿跟踪管理计划,以目标为导向具体指导销售人员进行差异化复效督导措施,通过分析实际复效效果与模型预期的偏离程度,找出当前复效以及模型存在的问题,制定相关的整改措施,并进一步优化模型效果,持续改进和加强保单失复效模型在管理工作中的作用。
模型使用除了便于使管理人员进行帕累托法则督导外,销售人员在执行复效服务工作时,可根据保单失复效模型得分采取差异化沟通计划,提高复效服务的工作效率;针对不同的复效意愿,采用不同的复效沟通方式。
如图7所示,以下为模型在分公司试点的效果,与业务自然情况的对比分析,以及根据模型预测结果建议采取沟通措施计划。
如表4所示,在差异化复效沟通方面,针对高复效意愿的客户,可借助微信/短信提醒方式,节省沟通时间成本;对于复效意愿较为普通的客户,采取合适的激励措施引导客户复效;而针对复效概率低的客户,可采取直接推荐优选其他更加合适的保险产品进行沟通。
值得一提的是,在分公司试点期间,由于对复效考核要求要进一步细化为期初(失效日期在本年度前的保单)和期内(失效日期在本年度的保单)两项指标。根据生产运营经验来看,失效时间越长的保单,其本身复效难度也是越大,如图8所示,这个正好同保单失复效模型的SHAP特征可解释性完全一致。
4 结 论
本文在对比多种集成算法模型的基础上,建立起了基于机器学习算法的保单失复效模型,并且基于公司历史积累的海量数据,对比评估RandomForest、XGBoost和LightGBM和Stacking融合算法在满足帕累托法则的对比分析研究。实证结论表明,采用Stacking多融合算法,在非及时响应的批处理环境下,具备较强的泛化能力。
保单失复效管理影响着保险公司长期健康稳定的发展,通过将模型引入PDCA持续优化场景设计,能够为保险机构提供科学可靠的管理决策支持,同时将营销员从繁重的催收工作解放出来,提升自身工作效率,改善客户服务水平,具备较强的实践参考价值。
参考文献:
[1] 邢秀芹.保险学 [M].北京:北京邮电大学出版社,2008.
[2] 朱小平,吴婷.期交失效保单风险点探析及应对 [N].中国邮政报,2016-06-30(4).
[3] 全国人民代表大会常务委员会.中华人民共和国保险法 [R/OL].[2020-09-20].http://www.npc.gov.cn/wxzl/gongbao/ 2015-07/06/content_1942828.htm.
[4] 百度百科.二八效应 [EB/OL].[2020-09-20].https://baike.baidu.com/item/%E4%BA%8C%E5%85%AB%E6%95%88%E5%BA%94/5155000?fromtitle=%E5%B8%95%E7%B4%AF%E6%89%98%E6%B3%95%E5%88%99&fromid=7224763#2.
[5] 阿明翰,張达敏,李伟.逻辑回归在信用卡风险评估模型构建中的应用 [J].内江科技,2016,37(9):41-42.
[6] 刘岚,王霞,林红旭,等.基于混合BP神经网络算法的信用卡消费行为风险预测 [J].科技管理研究,2011,31(17):206-210.
[7] 黎月.基于贝叶斯网分类器的互联网借贷风险评估 [J].北方经贸,2018(6):106-107.
[8] 卢文祥.基于logistic回归模型的保险单续款预测研究 [D].哈尔滨:哈尔滨工程大学,2017.
[9] 罗忠敏.失效保单的负面效应与应对策略 [J].华南金融研究,2002(6):53-55.
[10] 韩焱.失效保单的成因及防范对策 [J].保险研究,2002(4):41-42.
[11] 贾佳丽.河北寿险业“失效保单”存在问题及改善建议 [N].中国保险报,2018-04-03(12).
[12] MURTHY S K. Automatic Construction of Decision Trees from Data:A Multi-Disciplinary Survey [J]. Data Mining and Knowledge Discovery,1998,2(4):345-389.
[13] 万融.商品学概论:第5版 [M].北京:中国人民大学出版社,2013.
[14] 周志华.机器学习 [M].北京:清华大学出版社,2016:171-185.
[15] CHEN T Q,GUESTRIN C.XGBoost:A Scalable Tree Boosting System [C]//KDD16:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data MiningAugust,2016:785-794.
[16] KE G L,MENG Q,FINLEY T,et al. LightGBM:a highly efficient gradient boosting decision tree [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems. Curran Associates Inc.,57 Morehouse Lane,Red Hook,NY,United States,2017:3149-3157.
[17] ZHOU Z H,FENG J. Deep Forest:Towards An Alternative to Deep Neural Networks [J].National Science Review,2019,6(1):74-86.
作者简介:林鹏程(1980—),男,汉族,福建龙岩人,中级工程师(一级),硕士研究生,研究方向:AI算法在金融企业的应用;唐辉(1981—),男,汉族,湖北天门人,高级工程师(一级),硕士研究生,研究方向:企业信息管理。
