机器翻译视角下规范彝文文本分词歧义类型探究*
2020-05-18⊙蔡夏
⊙ 蔡 夏
(西南民族大学,四川 成都 610041)
一、研究背景及现状
彝语是属于汉藏语系藏缅语族彝语支的一种语言,同属彝语支的语言还有纳西、拉祜、傈僳、哈尼、基诺、怒苏、白、土家等。学术界一般将彝语分为六大方言区,即北部方言、东部方言、南部方言、东南部方言、西部方言、中部方言,其中又包括了五个次方言和二十五个土语。[1]本文所关注的是最大的彝语方言区——北部方言区在日常交际中出现的歧义现象,文中以书面语的使用为例。彝语是表意的音节文字,规范后的彝文虽然只有819个字(加上次高调上的彝文,共计1165个),但是几乎每个字都有其本义与引申义,而且大多核心词汇的词性也会随着使用性的增强而发生变化,从而逐渐扩展其本身的词性和词义。因此,彝语中的同音异义、同形异义现象在长期的使用中是相当普遍的,这使得彝汉机器翻译在文法上分词时遭遇诸多歧义现象和易混淆词句,增加了在算法上的实现难度系数。[2]
目前,学术界对彝语言的研究多集中在语法、语音等层面,聚焦语料库或计算机语言的角度来研究彝语及其翻译的成果则很少。[3]本文尝试运用机器翻译的分析和加工方法,对文中选取的彝语例句进行切分和结构剖析,简单探讨机器翻译模式下“彝译汉”所面临的切分歧义现象,同时为彝汉翻译语料库的建立提供具体案例。
二、研究视角——机器翻译
机器翻译(machine translation,MT)是计算机把一种语言(源语言,source languaage)翻译成另一种语言(目标语言,target language)的一门学科。它既是一门学科也是一门技术,作为语言学的一个分支,涉及计算机、认知科学、语言学、信息论等学科,是人工智能的终极目标之一。机器翻译是自然语言处理在计算机科学、语言学、心理学、认知科学和数学等多学科交叉中衍生出的,一般通过建立形式化的模型来分析、理解和处理自然语言。[4]

机器翻译中与语言智能有关的有三个方面,即语音识别/合成、自然语言处理和计算机编程。这三个领域涉及的问题各不相同。以自然语言处理领域为例,机器翻译侧重于解决该领域中的词性标注、句法标注、语义标注、词义消歧、指代消解、信息抽取等问题,以达到提升信息处理效率和效度的目标。[5]
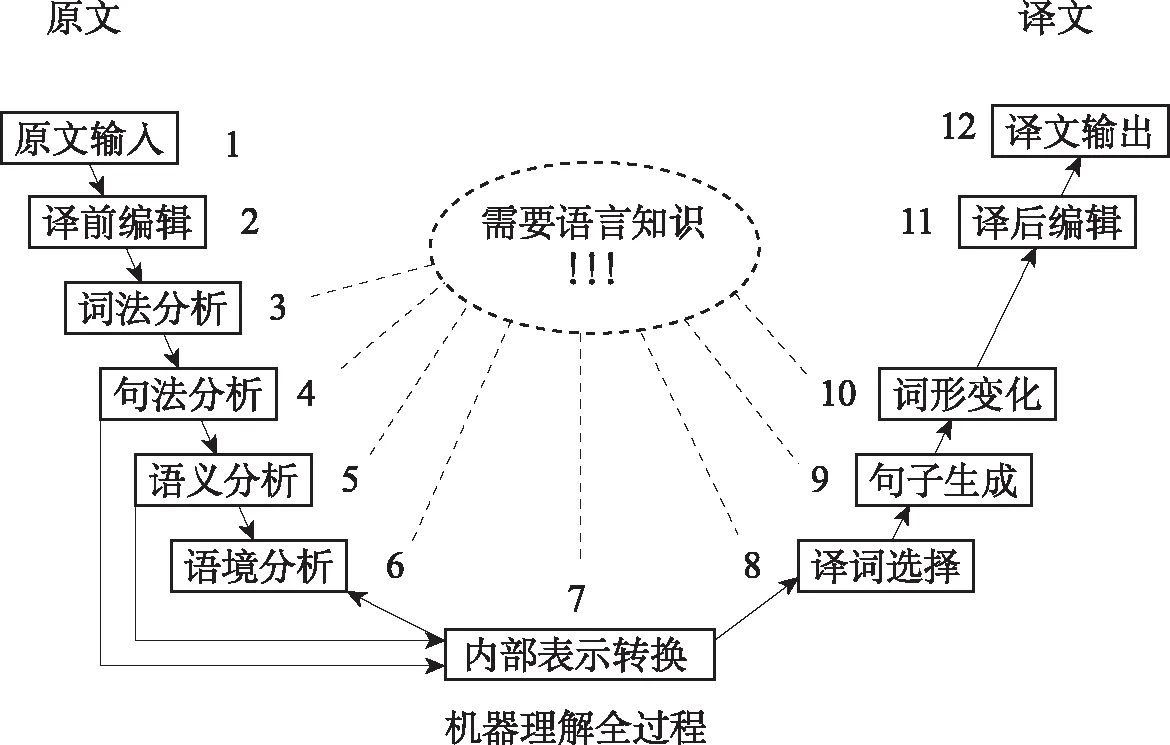
一般而言,机器翻译主要运用以下三种运算方法,即基于规则的方法、基于统计的方法和基于实例的方法,这三种方法各有优缺点。基于规则的方法在翻译中完全依赖规则,而当规则出现摩擦时,则需要更多的人力物力资源配合;基于统计和实例的翻译则依赖于语料库和实例的规模,也存在一定的局限。[6]
机器翻译通过对句子成分进行切分与标注的方式以达到分析和输出语句的目的。[7]切分歧义是影响分词系统切分正确率的重要因素,包括交集型歧义、组合型歧义以及混合型歧义3种类型:1.交集型歧义:如字符串abc既可以切分为ab/c,又可以切分为a/bc。其中,a、ab、c和bc都是具有独立意思的词或词语;2.组合型歧义:若ab为词,而a和b在句子中又可以分别单独成词;3.混合型歧义:由交集型歧义和组合型歧义自身嵌套或者两者交叉组合而产生的歧义。采集歧义字符串的两种具体方法:正向最大匹配和逆向最大匹配两种方法扫描发现交集型歧义;正向最大匹配和逆向最小匹配,并且最小匹配从单字词开始的方法发现组合型歧义。[8]
三、理论基础及相关概念简述
(一)转换生成语法
按照转换生成语法“管约论”的观点,人类大脑的语言器官中有一个词库和一个推导程序或称演算系统。推导程序从词库中选择词项,推导出句子的结构描写式,然后交由大脑中的其他应用系统进行语音和语义解释[9],如图所示:
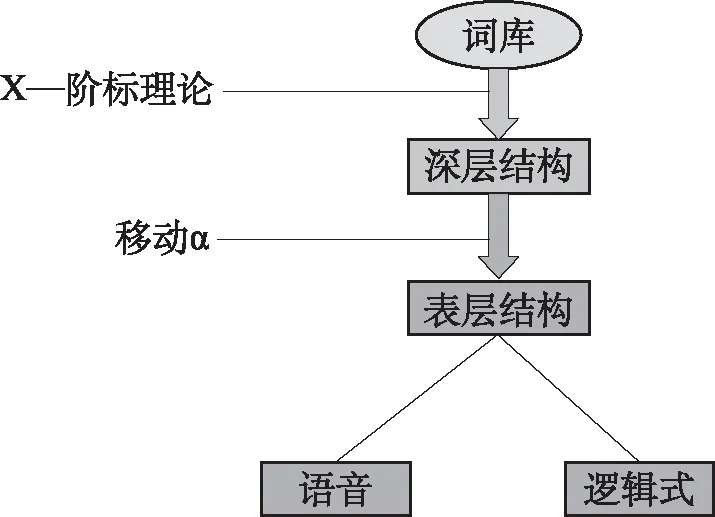
转换生成语法“管约论”[10]
“X-阶标理论规则”是“管约论”模型句法最基本的句法结构规则。它可以描述任何语言中的任何句子类型。
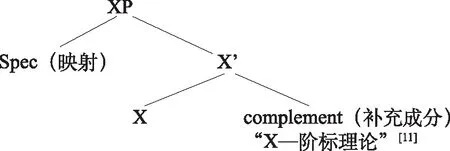
“X-阶标理论”[11]
转换生成语法理论也制定了一套符号[12],其常用符号列举如下表:
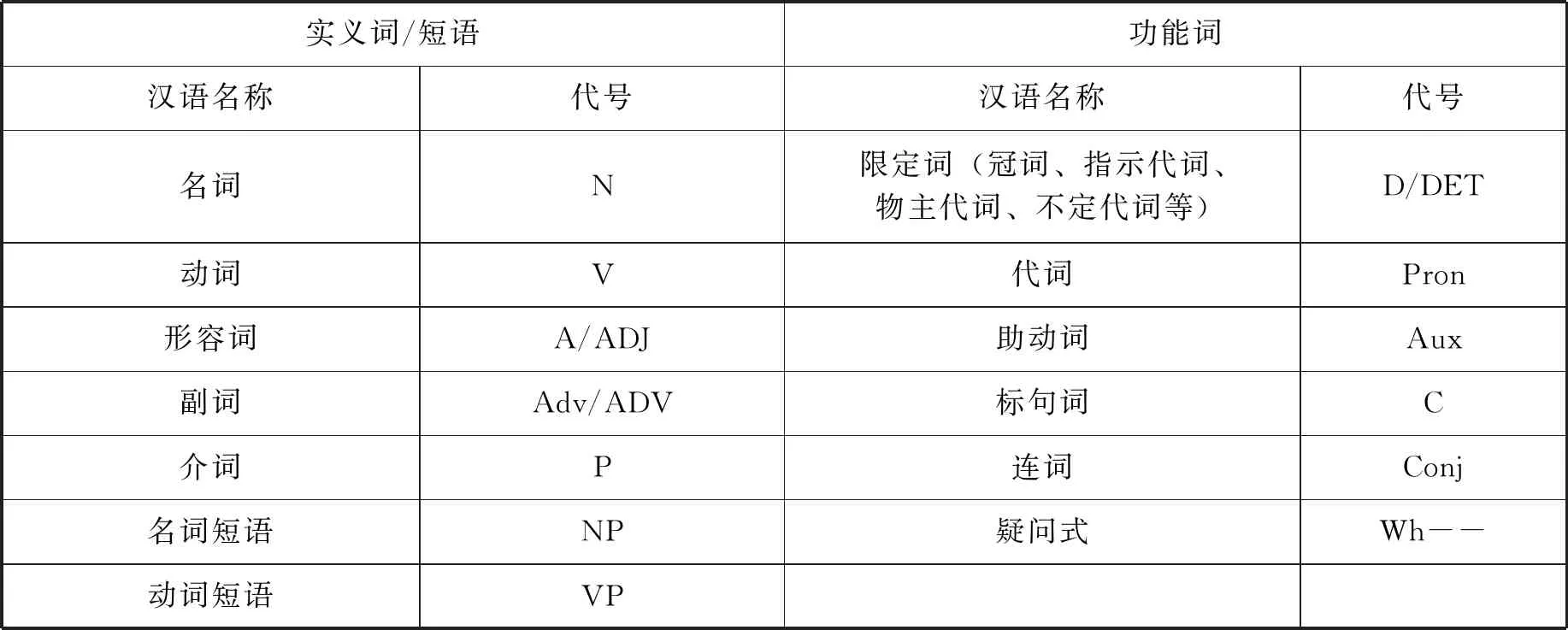
实义词/短语功能词汉语名称代号汉语名称代号名词N限定词(冠词、指示代词、物主代词、不定代词等)D/DET动词V代词Pron形容词A/ADJ助动词Aux副词Adv/ADV标句词C介词P连词Conj名词短语NP疑问式Wh--动词短语VP
最常见的句法结构有以下几种[13]:
(1)S=NP+VP;(2)VP=V+S;(3)NP=NP+S;(4)VP=NP+S;
(5)VP=V+NP;
(二)文法中的歧义现象
任何一种自然语言中都存在着歧义现象。所谓歧义是指人们在言语交际的过程中,听话人对一个句子的语言意义有着两种或两种以上理解的言语现象。也就是说,当一种语言形式能够传递出两种或两种以上的意义,进而传达出两种或两种以上的解释时就会产生歧义。[14]一般来讲,词汇歧义包括了同形异义词和同音异义词。结构歧义是指由于句子结构切分不同或结构关系不同或潜在关系不同而形成的语句歧义。[15]彝语歧义现象是指词与词、词与短语、短语与短语组合后,呈现出不同的语义结构关系、不同的语法结构关系、不同的层次结构关系,可作几种形式的切分,从而形成句法上的歧义。[16]本文主要探讨和关注的是彝语言实际运用中的词汇歧义和结构歧义现象。
四、彝语切分歧义的举例与分析
(一)组合型歧义举例
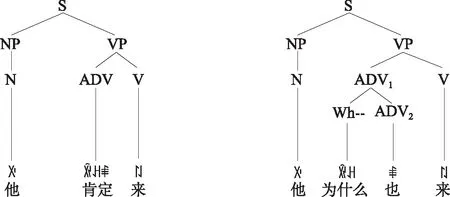
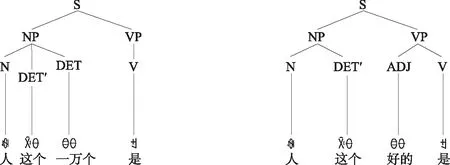
(二)交集型歧义
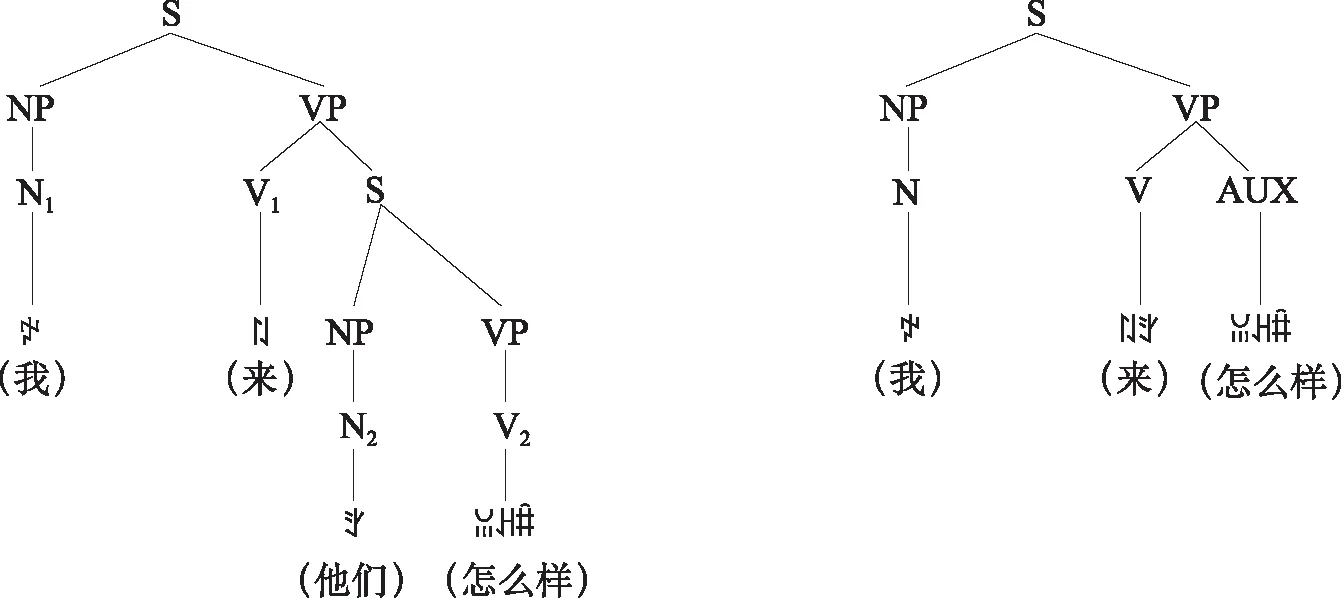
(三)混合型歧义句
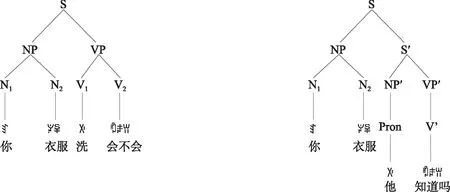
五、结论
机器翻译通过将彝语自然语言结构在使用中产生的各种歧义即语用歧义进行系统归纳和比较研究,找出彝语文本中容易产生歧义的共性特征。其涉及话语、言语行为和指示意义等,进而积极地利用歧义产生的多重语用效果,去验证与丰富语言规则,最终推动有关彝语言文本的深入研究。从以上探讨机器翻译对彝语句法结构的切分、标注和解释、分析中,我们可以看到,目前机器翻译尚且面临诸多挑战,但同时我们也有理由相信,通过大量实例的分析与累积,对彝语句法和词汇等进行切分、标注与转换、输出等处理,使得基于规则和基于统计的机器翻译语料库不断充实,机器翻译的效果也一定会逐步优化,使我们在语言交流中的障碍和压力得到有效缓解。
*本文系“四川省高校重点实验室——民族语言文字信息处理实验室建设项目”研究成果之一。
