粗糙集在多属性评价中的应用:理论分析与文献述评
2020-05-18邬阳阳孙岩松
邬阳阳,任 艳,韩 硕,孙岩松
(新疆财经大学 计算机科学与工程学院,新疆 乌鲁木齐,830012)
1 引言
多属性综合评价与多属性决策在学术上并没有进行严格区分[1]。综合评价是相对于单指标评价而言的,利用多个指标从多个维度对事物进行评价,在工程管理、经济管理以及决策等领域有着广泛地应用。传统的综合评价方法主要包括基于数理理论和统计分析的评价方法,但随着管理问题的日益复杂,这些方法已经不再适用于复杂系统的评价,而智能化方法具有较好的鲁棒性和自适应性,并且隐含并行处理数据的能力[2]。于是,一些学者将人工神经网络、支持向量机、云模型、粗糙集等智能学习方法引入到多属性决策问题的研究,设计了基于智能方法的综合评价方法。作为一种有效的评价理论,粗糙集理论也受到了学者们的关注。
粗糙集理论由波兰学者Pawlak 于1982 年提出[3,4],是继概率论、模糊集、证据理论等理论之后处理不确定性信息的有效工具。伴随着数据科学的兴起,粗糙集理论得到了迅速发展。一些学者也将粗糙集应用到经济学、管理学、金融等诸多领域[5]。粗糙集理论在计算过程中完全由数据驱动,计算结果具有客观性,并且算法易于运行,其理论本身的属性重要度计算方法、约简原理可以应用到指标权重的计算和评价指标的筛选两个方面。另外,作为一种软计算方法,粗糙集可以和其他多种软计算方法(神经网络、模糊集、证据理论)进行结合,优势互补,建立新的评价模型,也可以结合传统的评价方法(灰色系统评价法、模糊综合评价法、因子分析法)提高综合评价结果的精确度[6]。
就目前的文献资料而言,有些学者对粗糙集在综合评价中的一些基本原理和应用实例也进行了分析和总结[6],但粗糙集理论在多属性评价的应用取得了进一步的进展,为了促进粗糙集在多属性评价方法的应用和多属性评价理论本身的完善,需要有新的专业文献对这类评价方法作出系统的总结和分析。基于此,本文对粗糙集在多属性评价中的应用的理论基础进行了介绍,并对一些经典文献进行总结和分析,以期为跨学科研究和利用粗糙集理论提供借鉴。
2 粗糙集基本理论介绍
在多属性评价过程中,主要运用了粗糙集属性重要度定义和粗糙集属性约简原理。首先引入粗糙集的一些基本概念:粗糙集理论用知识(论域U的任何非空子集簇)描述客观事物[7]。对于信息系统IS=(U,A,V,f),其中U为论域,A为非空条件属性集,f表示信息系统的信息函数,V为信息函数f的值域。对于属性集合B,其不可分辨关系和等价类可分别表示为:和[x]IND(B)={y|y∈U,x,y∈IND(B)}。当X⊆U时,粗糙集的正域可定义为
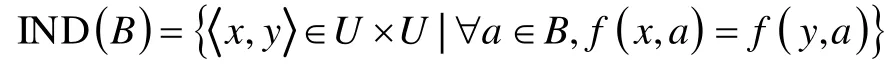
二元组K=(U,R)是U论域的一个知识库。其中,R为U上的一簇等价关系。对于等价关系P和Q,P∈R,Q∈R,称为Q和P间的依赖度。对于属性B'在属性集B中的重要度定义。粗糙集属性约简分为信息系统的属性约简和决策信息系统的约简两种情形。由于两类约简原理类似,这里仅对信息系统的属性约简定义进行描述。在IS=(U,A,V,f)中,B⊆A,∀p∈B,若集合B先后满足IND(B)=IND(A)和IND(B-p)≠IND(B)两个条件,则称B为A的一个约简。其约简原理可用自然语言描述为:属性集合B和属性集合A具有相同的数据分辨能力,若属性集合B去掉一个属性之后,数据分辨能力就会发生改变,那么属性集合B可称为属性集合A的一个约简。
3 粗糙集在多属性评价中的应用
3.1 Pawlak 粗糙集在综合评价中的应用
Pawlak 粗糙集模型是粗糙集理论的基础,其他拓展粗糙集模型都是为了满足特定类型数据处理的需要而在这个模型上进行的改进。Pawlak 粗糙集无论是在属性约简算法还是在模型应用方面的研究都相对深入。与其有关的评价方法大体可以分为两类,一类是利用约简原理对指标进行筛选后再进行评价,另一类则是直接利用属性重要度公式计算权重后进行排序,或者计算权重后再结合一些评价方法进行综合评价。
3.1.1 筛选指标
粗糙集的一个主要研究内容就是属性约简。属性约简又称特征选择,可以在不影响决策质量的前提下,去除冗余或不相关的属性,从而达到提高决策效率的目的。粗糙集约简原理在多属性评价中的应用实质就是将评价指标视为信息系统的属性,然后根据粗糙集约简原理进行指标处理,最后即可得到简化后的指标[8-12]。巴希等人[10]对风险分担进行综合评价之前,用粗糙集对指标进行预处理,剔除了具有相似功能的一些指标,同时又能使剩余指标达到分类目标。然后,结合传统的评价方法——理想点法对PPP 项目风险分担进行评价。王天擎等人[11]首先应用DEA 模型进行效率测度,然后利用粗糙集对产学研的投入和产出指标体系进行约简,从而找出了影响投入产出效率的关键因素。蔡中华等人[12]运用粗糙集属性约简方法,得出对养老服务质量影响较大的服务项目,在一定程度上克服了噪声数据的干扰,并利用粗糙集方法计算了各个属性的权重,提高了评价的客观性。
3.1.2 计算权重
粗糙集确定权重主要是依据属性重要度公式计算每个属性(指标)的重要度。在综合评价过程中,权重的计算大致可分为单独利用粗糙集计算权重以及结合其他主观赋权方法(主成份分析法、层次分析法、德尔菲法等)进行赋权两种方法。
第一类基于粗糙集的单独计算权重的方法主要是根据属性重要度计算公式直接进行指标的权重计算。仇国芳等人[13]利用粗糙集理论建立了绿色施工项目评价模型,模型主要是通过粗糙集的权重计算公式求解评价指标的权重,最后再计算综合得分。项勇等人[14]应用粗糙集计算影响影子收费因素的权重,从而明确对非营利性项目评估系统完善性影响最大的因素,文章在利用粗糙集计算权重之前,应用了粗糙集约简理论对评价指标进行了约简,达到了简化计算的目的。作为一种客观赋权方法,粗糙集权重计算方法完全依赖数据驱动,忽略了专家的一些经验,所以一些学者将粗糙集方法与一些主观赋权法相结合,并采用加法合成法、乘法合成法、博弈论等方法进行权重的融合,这便是第二类权重计算方法。张文宇等人[15]针对粗糙集计算客观权重和层次分析法(AHP)计算主观权重的不足,将两种方法相互结合,通过加法赋权方式进行组合赋权,最后应用于电子政务的评价说明,验证了该方法的可行性。与文献[15]类似,万荣等人[16]将基于粗糙集和基于模糊层次分析法(FAHP)的求解权重的方法进行集成,求解客户需求权重。该文献利用线性加权方法求解得到了最终权重。张健等人[17]用网络层次分析法(ANP)确定了新铁路客站绿色星级评估指标的主观权重,同时用经典粗糙集计算指标的客观权重,最后采用相对熵原理减小了主、客观权重融合时的误差,得出了更为合理的组合权重。
3.2 基于粗糙集拓展模型的评价方法的应用
为了弥补Pawlak 粗糙集在处理数据时仅限制于符号型数据的弊端,许多学者提出了拓展粗糙集模型,一些经典的拓展模型也应用到多属性评价问题中。拓展粗糙集在多属性评价中的应用,主要也是依据属性约简原理、权重确定方法,其评价过程类似于Pawlak 粗糙集,此处不再赘述。本文选择了几类较为经典的拓展模型(变精度粗糙集、模糊粗糙集、邻域粗糙集、优势粗糙集、区间值粗糙集)的应用实例进行了详细分析。在缺失数据的处理方面,传统的数据分析主要通过插值法对这类数据进行预处理。而变精度粗糙集由于引入了β阈值可以直接处理噪声数据。张金隆等人[18]将变精度粗糙集与层次分析法相结合,对IT 项目的投标风险进行评价,该方法避免了使用层次分析法过程中专家人为划分重要度的缺点,同时又简化了计算。谢松等人[19]为了解决变压器油纸绝缘状态评估中部分数据未知的问题,采用模糊C 均值法和模糊粗糙集的辨识矩阵法对绝缘状态进行评估,并通过实例演绎证明了该方法的有效性。郭春花[20]利用邻域粗糙集对信用风险的复杂数据进行降维,并采用马氏距离消除数据量纲的影响,建立了一种有效的评级方法。王静等人[21]引入优势粗糙集以克服Pawlak 粗糙集不能处理具有偏好信息的信息系统的缺点,首先利用优势粗糙集对评价对象的属性进行约简,然后利用极大熵进行赋权,建立了高校招生的资源配置评估模型。徐飞等人[22]研究发现以往的研究生教育质量的评价体系中存在冗余或不重要的指标,于是引入区间值模糊粗糙集对评价指标进行约简,并根据区间模糊粗糙集的属性重要度公式算出来各种指标的重要度。
3.3 对权重计算方法的改进
粗糙集在进行依赖度计算时会出现指标权重为零的情况,而所选择的评价指标一般都会对评价主体产生影响,权重为零则存在一定的不合理性。对于这类问题,有学者提出了通过专家再次打分的方法,重新计算指标的重要度[18],但这种方法需要耗费更多的人力成本。因此,一些学者对基于粗糙集的权重计算公式进行了改进[23-27]。其中,鲍新中等人[23]为了解决经典粗糙集模型无法确定冗余属性权重的问题,利用粗糙集信息观下表示更全面的特点,引入条件信息熵,提出了新的基于粗糙集条件信息熵的权重确定方法,并分析了该方法的合理性。朱红灿等人[24]指出鲍新中等人基于代数观改进的权重计算公式虽然可以避免权重出现零的情况,但有可能出现冗余属性的属性重要度大于非冗余属性重要度之一矛盾现象。于是依据重要度是否为零将其划分为高级或低级优先级队列,重新定义了权重的计算公式:其中,μ(c)表示条件属性(指标)c的队列的优先级。对于朱红灿改进算法的应用,刘姗等人[28]基于改进的权重计算方法建立了水质综合评价模型,将其应用到重庆市南川凤嘴江水质评价中,取得了较好的评价效果。施振佺 等人[27]指出朱红灿等人改进的权重计算方法会增加计算的额外开销,于是引入了知识粒度理论,提出了基于粗糙集和知识粒度的权重求解方法。该方法可以有效避免冗余特征权重为0 以及非冗余特征当成冗余特征等问题。
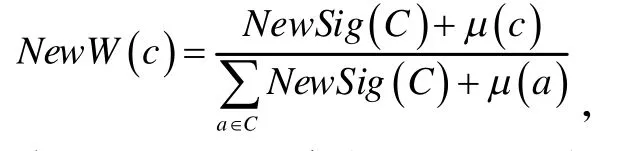
4 展望
粗糙集是处理不确定性问题的智能数学工具,也是一种智能评价方法,基于粗糙集的多属性评价方法已经在多个领域得到了一定程度的应用,但其应用并没有一些传统理论那么广泛以及在应用中还存在一些问题。因此,基于粗糙集的多属性评价方法在推广以及深入研究方面还需要作进一步的探索。
Pawlak 粗糙集在多属性评价中的应用最为广泛,但该模型应用前需要对原始数据进行离散化处理,离散化操作会导致原有数据所包含的信息缺失。一些经典的粗糙集拓展模型,比如模糊粗糙集、邻域粗糙集可以处理非符号性数据,但两类模型在应用中还存在以下问题:第一,邻域粗糙集阈值的确定,邻域粗糙集的阈值主要是采用胡清华在建立邻域粗糙集过程中使用的经典阈值,这个阈值并不一定适合所有的应用场景。第二,两类模型在处理数据中,计算量比较大,现阶段并没有相应的软件支持,而其他许多评价方法(层次分析法、灰色系统理论、理想点法、模糊评价法等)都有较为成熟的软件,这些软件将评价模型封装成黑箱模式,有利于这些评价方法的推广使用,为其他领域的研究人员使用此类方法提供了极大的便利。因此,开发相应的粗糙集评价软件,可以促进粗糙集评在其他领域的应用。
新模型的应用。为了更好地处理现实中的数据,粗糙集模型的拓展是一个重要的研究方向[29-30]。因此,不断有新的模型被提出,比如:局部粗糙集[31]、三支决策粗糙集[32]、多粒度粗糙集[33]等。其中,三支决策粗糙集在多属性评价中,运用三支语义,同原来的二支决策相比,决策更加科学,在社会科学的应用方面已经有一些研究成果出现[34-36]。将决策粗糙集应用到更多的领域可以为决策者提供更为有力的工具,提高决策的质量。多粒度粗糙集由于可以从多个视角分析问题,对于复杂的大型问题的解决具有重要意义,将多粒度粗糙集应用到多属性问题的评价,能够从不同角度分析问题,有利于问题的有效解决,将多粒度粗糙集应用到复杂问题的分析,可以为决策提供更为科学合理的信息。
多种方法的集成。随着数据科学的不断进步和发展,有多种分析处理数据的智能模型被提出,将粗糙集和这些先进的模型相结合可以避免某一类模型在处理数据中的弊端。云模型是一种处理模糊信息的较新的理论,它反映了知识的模糊性和随机性,构成了定量与定性的相互映射的关系[37],一些研究者将云模型与Pawlak 粗糙集结合进行综合评价[38-40],取得了较好的评价效果,为各个领域提供了新的评价方法。将这些方法应用到其他领域可以为这些具体领域提供一些新的评价模型,提升评价质量。另外,将粗糙集拓展模型和云模型结合也是一个研究方向。粗糙集的拓展模型某些性能要优于经典粗糙集,将这些拓展模型与云模型集成可以取得更好的评价效果。
5 结语
基于粗糙集的综合评价方法已经应用到很多领域,体现了该理论的优良性能。文章对基于粗糙集的综合评价方法的应用原理、经典文献以及研究中存在的一些问题进行了综述与分析,为进一步研究粗糙集在多属性评价中的应用提供了参考。
