基于深度学习的白菜田杂草分割
2020-05-16蒋红海孙腾飞王春阳尚建伟
喻 刚,蒋红海,孙腾飞,王春阳,尚建伟
(昆明理工大学 机电工程学院 云南 昆明 650504)
0 引言
我国是一个以农业为主的国家,促进农产品的发展具有很大的意义,而白菜有作为生活中常见的蔬菜之一,广受人民的喜爱,但是白菜的生长经常受到杂草的影响,田间杂草凭借其强悍的生存能力不且与白菜掠夺土壤养分和空间阳光等[1],而且有些杂草还是许多病虫的中间宿主,促使田间病虫害的发生。所以,田间除草对于提高白菜的质量和产量具有重要的意义。
目前田间杂草管理方法大致包括人力除草、喷洒化学除草剂和传统农耕机械除草三种方式。随着智能除草机器人的出现,在一定程度上代替传统除草方式,不仅提高了生产效率,同时也减少了农民的田间劳作时间和化学除草剂的喷洒,降低了农业生产成本,减少环境的破坏。近些年来,许多学者对除草算法进行了深入研究。关强等人[2]在田间植物图像的分割中使用二维OTSU算法对植物部分和背景部分进行处理,根据RGB 颜色模型和HSV 颜色模型的灰度化使用5种不同的图像分割算法;胡波等人[3]通过引入像素灰度级和邻域灰度级构成的二维直方图,提出了一种彩色图像算法进行杂草分割。Arefi等人[4]基于图像形态学和颜色,使用RGB和HSI颜色模型定义杂草颜色特征,采用两种形态学特征对杂草进行识别。
上述图像处理方法主要根据颜色特征或直方图对杂草图像进行分割,容易受到环境的影响。所以本文将深度学习引入杂草识别领域,应用 Mask R-CNN算法对杂草及白菜幼苗进行分割识别,并与传统图像算法对比。实验结果表明,该算法在自然环境下能对杂草和作物进行有效的识别。
1 Mask R-CNN算法原理
图像分割是在检测出图像中被测物位置并分类
的前提下,对被测物进行像素级别的分割。所以图像分割可以看作物体识别和语义分割的结合,它不仅要正确的找到图像中的物体进行识别,还要对其精确的分割。结合Faster R-CNN的图像分割和FCN语义分割算法,何恺明等研究员[5],提出了如图 1所示的分割算法Mask R-CNN,它从Faster R-CNN模型中借用了两个方面。首先是提取图像框(RPN),用来产生候选对象框。然后是作类别和边框预测,给每个RoI都输出一个二值掩模。其模型示意图如图所示。

图1 Mask R-CNNFig.1 Mask R-CNN
1.1 RPN网络
RPN是通过一个全卷积神经网络来实现的,其输入是一幅特征图像,输出的是一组带有对象得分的目标推荐矩形,与目标检测中的ss算法[6]类似。基准框在多次卷积后的特征图上滑动后映射到一个低维特征上,然后,这个低维特征被输入到边框回归层和边框分类层,最终生成一组有编号和坐标的锚框。
RPN在每一个滑动窗口位置同时预测多个区域枚举,并将最大可能枚举数目记录为 k。所以 reg层用4k输入编码k帧坐标,cls层输出2k得分以估量每个枚举是否是目标对象。特征图中每个红色框的中心点可以对应于原始图像中的像素点。对于每个锚点,选择9个不同大小和宽高比的矩形,一般为128*128,256*256,512*512的三种尺寸,每种尺寸按1∶1,1∶2,2∶1的长宽比缩放,并且它们的预测顺序被固定为要评估的RPN的候选框。其中具有最大重叠率的锚点被记录为前景样本,并且如果剩余锚点与某个校准重叠,则其大于0.7,记为前景样本; 如果它与任何校准重叠,则该比率小于0.3,将其记录为背景样品。而介于 0.3~0.7之间的锚点弃用。构造好锚点之后,训练RPN的问题就可以转化为最小化一个多任务损失函数。
1.2 掩模分支
Mask R-CNN采用了一个全卷积网络的掩模(mask)分支[7],与对象分类同时进行,对特征图进行像素级的分割。掩模分支在每个RoI上产生一个Km2维输出,为K个类别各编码一个m*m的二值掩模。掩模损失是一个用像素级 sigmoid定义的交叉熵损失,记为Lmask。
Sigmoid函数定义:

交叉熵损失函数定义如公式:
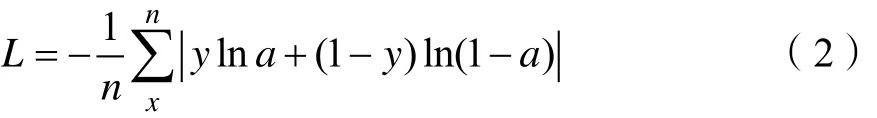
其中,x表示样本,y表示真实值,a表示输出值,n为样本总数。
整体损失函数表示为:

1.3 特征提取
图片输入到 Mask R-CNN网络后,首先经过ResNet分类网络,并从整幅图片中提取特征。特征提取的操作一般包括卷积层、Relu激活函数和池化层[8],经处理后得到特征图。
(1)卷积操作是让权值矩阵在图像上按照固定的步幅移动,权值矩阵每停下一个位置,就让权值矩阵中每个值与图像中对应的元素进行矩阵运算,得到的值就是这一步卷积层对应位置的值;同时卷积还能实现参数共享,减少计算量。图像中需要通过不同尺寸的的卷积核来提取相应的维度特征。
(2)ReLU激活函数是校正线性单元函数,它是神经网络中经常出现的一种激活函数,其表达式为:

(3)Mask R-CNN采用了一种RoIPool扩展层的池化操作,称为RoIAlign层,它摒弃了RoIPool的粗糙量化,通过插值在每个RoI网格的四个规则采样位置计算输入特征的精确值,在进行最大池化或平均池化的聚合处理。
2 数据采集与超参数设置
2.1 数据集
在kaggle官网公布了现有唯一的室内培育的杂草幼苗数据集,本文选取其中田间最常见的三种杂草幼苗各200张:田芥菜、马齿苋和白花藜,为了防止数据集单一,产生过拟合现象,数据集中加入野外杂草幼苗照片每类各50张。本文搜集白菜幼苗50张,并实际拍摄100张.由于白菜幼苗的图片较少,所以本实验需要对图片数量进行数据扩充到 250张。数据扩充的方式有很多,包括图像的水平翻转、移动、增加噪声、改变对比度、变换尺寸、色彩抖动等[9],在数据集上采取这些数据扩充的方法,可以有效地提高网络的泛化能力,降低错误率。变换效果图如图2所示。

图2 数据扩充Fig.2 Data amplification
2.2 超参数的选择
(1)Epoch和Batch Size
在深度学习中,训练集对网络训练一次是不能完全使网络收敛的,所以需要多次训练,它根据数据集中对象的多样性来确定,本次实验选取三种杂草和一种蔬菜,对象的复杂度较低,所以选取Epoch值为100。
在整个 Epoch中需要训练的数据集数量过于多,计算机可能无法承载,所以需要将它分成很多个较小的Batches。本次实验选择在电脑上训练,电脑CPU是英特尔志强X5570,主频2.93 GHz;显卡是NVIDIA GeForce 1050Ti,显存容量为6 GB,显存位宽64bit,实验将Batch Size的值设置为2。本文完成一轮迭代所需要的批次大小记为Iterations。
(2)学习率
学习率是控制深度学习中权值的更新速率的一个参数,它直接决定了权值沿梯度方向下降的变化情况。它对权重的变化可以表示为:

其中newω是更新后的权重,oldω是更新前的权重,α为学习率,gradient为梯度。
首先,实验分别选取学习率 0.1、0.01、0.001作为第一轮训练的学习率,来测试网络整体损失函数变化。从图3可以看出,当学习率α=0.1时,总损失函数值迅速下降,网络快速拟合,训练结果与真值之间的差值变小的速率很高,但当训练的批次达到100次以上时,损失函数值略有升高,并且在以后的训练过程后期呈震荡趋势。损失函数数值整体趋势呈现先降低后震荡的趋势,这是因为学习率过大,导致梯度出现震荡,网络较难收敛。当学习率α=0.001时,损失函数整体呈下降趋势,但下降速率低于α=0.1时的速率。当学习率α=0.00001时,损失函数值下降速度极为缓慢,这是因为学习率很低,权重更新速度慢,致使网络收敛速度变慢。

图3 α-lossFig.3 α-loss
本实验使用网络在COCO数据集上训练得到的参数作为初始值,网络初始就具有一定的收敛,因此初始学习率设为0.001,每两轮训练后降低50%。
(3)网络正则化
深度学习的一个核心问题是怎样使学习算法新的数据集上有优异的表现,这通常被称为“泛化能力”。往往深层网络在训练集中表现优异,但在测试集中的表现却差强人意,这种由于网络出现了过拟合现象,而利用“正则化”可以有效的避免过拟合的发生,提高泛化能力[10]。
l2正则化:假设网络层参数为ω,则公式可表示为

其中参数λ是决定正则项的大小,较大的λ值会在一定程度上约束模型复杂度,反之则亦然[11]。
l1正则化:

l1正则化不但能限制参数量级之外,同时还能让许多参数稀疏化,减少模型中的噪点和存储空间。随机失活是正则化中一种重要方法,本文将失活率设置为0.5。
综合以上分析,本次实验采用的超参数数据如表1所示:

表1 超参数Tab.1 Superparameter
经上文分析后,确定深度网络训练的超参数。本实验将800张白菜幼苗和三类杂草幼苗图像作为训练集对网络进行训练,200张作为测试集验证识别效果。
3 结果与分析
3.1 损失函数变化情况
首先,将 800张标注完成的照片投入到 Mask R-CNN卷积神经网络中训练,观察训练过程中总损失函数变化情况,评价网络拟合程度。图4是在100轮训练过程中损失函数数值变化数据。从图4展示的数据变化图不难看出,loss值在前25轮训练中下降较快,这是由于学习率比较高,网络参数更新速度较快。在随后的25轮训练中,α逐渐减小,loss值整体趋势虽然在下降,但是下降速度减小。在50-80轮训练中,loss值下降速度略有增加,网络继续收敛,当训练到80轮后,loss值趋于平稳,直至100轮,loss变化微小,网络趋于稳定。

图4 损失函数变化情况Fig.4 Loss function variation
3.2 实验对比
神经网络训练完成后,实验将200张未标注的植物照片作为测试集,投入到网络中测试准确率。本文将识别结果分为三个级别:定位和分类准确,且分割出植物主体95%以上的设为优秀;分类准确,定位框出现偏差或分割不完全的设为合格;出现定位框偏离物体较大或分类错误,即设为不合格。表2为基于Mask R-CNN算法的各级别所占比例:

表2 各级别占比Tab.2 Percentage by grade
下图是基于 OTSU阈值分割与基于 Mask R-CNN的识别效果的对比图像。
在第一组照片中,两种方案都有效识别,但Mask R-CNN算法的识别精度较高,对于杂草的定位和分割都较为准确。在第二组图像中,由于光照影响,OTSU阈值分割算法在白菜细小叶柄部分产生了过分割现象,将小叶片识别为杂草,这是由于强光照照射在物体和地面上,致使物体本身特征发生了变化,难以识别。而Mask R-CNN算法对白菜和杂草识别准确。在第三组照片中,白菜叶片遮挡了杂草区域,OTSU阈值分割算法未能将白菜与杂菜分割,进而在识别过程中将二者识别为一个整体;而 Mask R-CNN算法有效识别出连接的杂草和白菜,并且定位准确。所以,Mask R-CNN算法在处理复杂环境时表现更优。

图5 分割对比Fig.5 Segmentation effect
4 结论
本文将深度学习引入杂草分割领域,详细介绍了Mask R-CNN神经网络结构,并将该网络用于杂草与白菜的实例分割,得到了81%的合格率。与基于OTSU阈值分割的杂草识别方案进行对比,Mask R-CNN不仅能在不同光照下准确识别图像中物体种类,同时在作物叶片相互遮挡的情况下也能很好的识别和定位杂草,实现了户外环境下的图像定位和分类,证明了该算法在自然环境能对杂草和作物进行有效的识别。同时,Mask R-CNN算法结构还避免了传统图像识别过程中的分类器设置工作,有效的提高算法的适应性。
