基于卷积神经网络的验证码识别
2020-05-16李世成东野长磊
李世成,东野长磊
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
0 引言
验证码(CAPTCHA)是一种区分用户是计算机还是人的公共全自动程序。验证码通常由字母和数字组成,为防止被机器自动识别,其分辨率通常较低,图片噪声较大。字符被一定程度的扭曲或倾斜,字符间往往存在粘连,“用户”需要识别并键入正确的字符。人眼队验证码的识别率可以达到80%以上,但自动化程序识别准确率往往低于 0.01%。这对于防止金融欺诈、电商刷单、恶意注册等批量化行为具有较好的效果[1-2]。
鉴于验证码在互联网中的广泛应用,国内外对验证码的识别进行了相关研究,出现了很多破解验证码的技术。目前,验证码识别主要有支持向量机(SVM)、卷积神经网络(CNN)等方法[3]。对于噪声较少并且字符位数固定的验证码图片,使用深度神经网络对整张验证码图片进行多标签学习来完成分类任务也可以达到很好的效果。也可以使用卷积神经网络(CNN)与循环神经网络(RNN)结合的方式实现验证码图像端到端的识别[4]。
本文的验证码数据来源于 2019年全国高校计算机能力挑战赛,字符之间大多数存在粘连问题,使用端到端的识别模型很容易遗漏掉字符。所以本文先进行单个字符切割,对卷积神经网络添加注意力模块,并使用卷积神经网络对单个字符进行识别。
1 图像预处理
1.1 去除噪点处理
如图1所示,原始验证码图片中有很多椒盐噪声,这些噪声对图片识别效果有着很大的干扰作用。椒盐噪声也称为脉冲噪声,是图像中经常见到的一种噪声,它是一种随机出现的白点或者黑点,可能是亮的区域有黑色像素或是在暗的区域有白色像素(或是两者皆有)。中值滤波是一种典型的非线性滤波,是基于排序统计理论的一种能够有效抑制噪声的非线性信号处理技术,基本思想是用像素点邻域灰度值的中值来代替该像素点的灰度值,让周围的像素值接近真实的值从而消除孤立的噪声点。如图2所示,使用数字图像处理中的中值滤波方法可以有效去除图像中的噪点。
二维中值滤波的输出公式为:
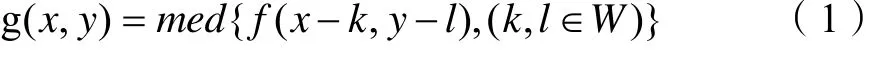
其中, (,)f x y, (,)g x y分别为原始图像和处理后的图像。W为二维模板,通常为3*3,5*5区域。也可以是不同的的形状,如线状,圆形,十字形,圆环形等。

图1 原始图像Fig.1 The original image

图2 去噪处理后的图像Fig.2 The denoised image
1.2 分割图像
如图3所示,在原始图像中有字符之间相互重叠的部分,直接使用多分类的图像处理方法很难识别出正确的字符。如图4所示,本文将原始图片切割成4份只有单个字符的图像,使用单分类的模型进行识别,可以大幅度提高识别精度。

图3 原始图像Fig.3 The original image

图4 切割之后的图像Fig.4 The image after cutting
2 使用CNN进行样本训练
2.1 卷积神经网络概述
验证码识别可以看作是图像分类问题,也可以看作是对图像的序列识别问题。近几年,深度卷积神经网络在图像分类问题上不断创新,突破极限。从比较简单的 LeNet5[5]到更加深层网络结构的VGGNet[6],说明了随着网络深度的增加,模型可以学习到更高级的图像特征,使得图像分类的效果更加准确。后来,研究者发现不断的堆叠网络结构并不能更进一步的提升模型识别的效果。叠加过多的神经网络层会出现梯度消失或爆炸问题,难以收敛。随着残差网络的提出,深层网络结构的梯度消失问题得以解决,ResNet[7]是经典的深度残差网络模型。对于基于图像序列的识别问题,有研究者提出了一种新颖的卷积循环神经网络(CRNN)[8],因为它是DCNN和 RNN的组合。对于类序列对象,CRNN与传统神经网络模型相比具有一些独特的优点:(1)可以直接从序列标签(例如单词)学习,不需要详细的标注(例如字符);(2)直接从图像数据学习信息表示时具有与DCNN相同的性质,既不需要手工特征也不需要预处理步骤,包括二值化/分割,组件定位等;(3)具有与RNN相同的性质,能够产生一系列标签;(4)对类序列对象的长度无约束,只需要在训练阶段和测试阶段对高度进行归一化;(5)与现有技术相比,它在场景文本(字识别)上获得更好或更具竞争力的表现;(6)它比标准DCNN模型包含的参数要少得多,占用更少的存储空间。
2.2 模型训练
2.2.1 图像及标签处理
验证码数据来源于 2019年全国高校计算机能力挑战赛提供的5000张训练图片和5000张测试图片。原始图像为40*120的RGB图像,按照预处理阶段进行去噪和分割,每张原始图像分割成 4张40*30的图像。标签总共62类,分别是数字10类、小写英文字母26类和大写英文字母26类。
2.2.2 网络结构
深度卷积神经网络中常用的图像分类模型有很多,例如:LeNet、VGG、ResNet和DenseNet[9]等。因为原始图像为3通道图像,大多数图像中字符与背景之间的对比度很小,并且更深层次的网络过于庞大,对于网络训练的硬件环境要求更高。所以本文选择ResNet50作为基础网络,并且在每个残差块中添加注意力模块(CBAM)[10]。
如图5所示,残差学习单元将输入端与输出端短路连接,复制一个浅层网络的输出加给深层的输出。残差学习单元的输出如下:

x为浅层的输出, ()H x为深层的输出, ()F x为夹在二者之间的变换。当浅层的x代表的特征已经足够成熟,如果任何对于特征x的改变都会让 loss变大的话, ()F x会自动趋向于学习成为0。在前向过程中,当浅层的输出已经足够成熟的时候,让更深层能够实现恒等映射的作用[7]。
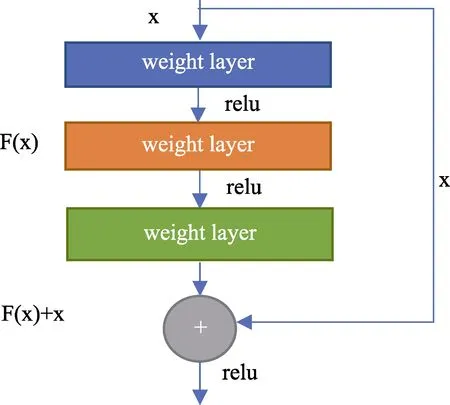
图5 残差学习的基本单元Fig.5 Residual learning:a building block
Convolutional Block Attention Module(CBAM),这是一种为卷积神将网络设计的,简单有效的注意力模块(Attention Module)。如图 6所示,对于卷积神经网络的特征图(feature map),CBAM从通道和空间两个维度计算特征图的注意力图(attention map),然后将注意力图与输入的特征图相乘来进行特征的自适应学习。对于中间层的特征图F∈将会顺序推理出一维的通道注意力图和二维的空间注意力图过程如下:

其中⊗为逐个元素之间相乘,首先将通道注意力模块的输出(channel attention map)与输入(feature map)相乘得到F′,之后计算F′的空间注意力模块的输出(spatial attention map),并将两者相乘得到最终的输出F′。
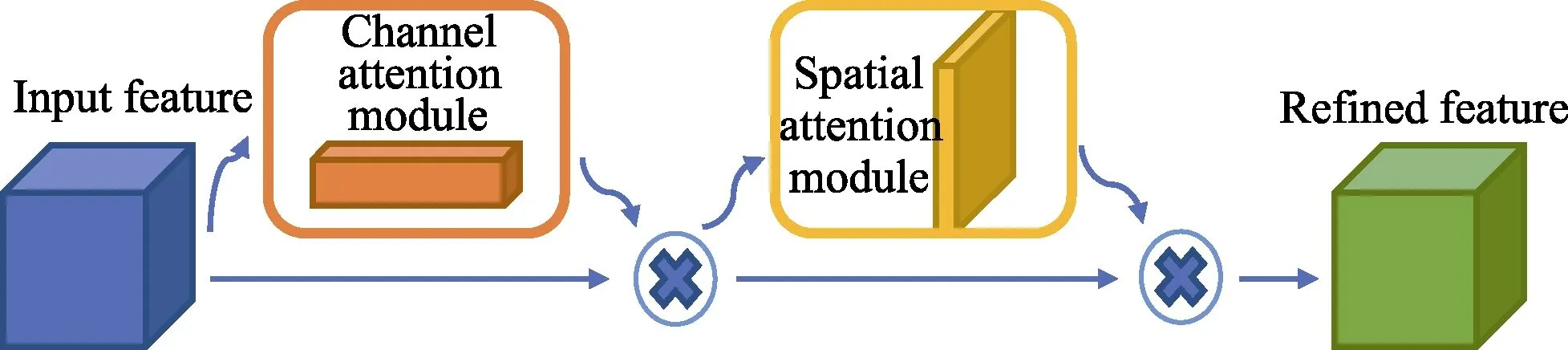
图6 卷积注意力模块Fig.6 Convolutional block attention module
特征图的每个通道都被视为一个特征检测器,通道注意力模块主要关注于输入图片中什么是有意义的。如图7所示,通道注意力模块使用最大池化和平均池化对特征图在空间维度上进行压缩,使用由 MLP组成的共享网络对这两个不同的空间背景描述进行计算得到通道注意力模块的输出。计算过程如下:

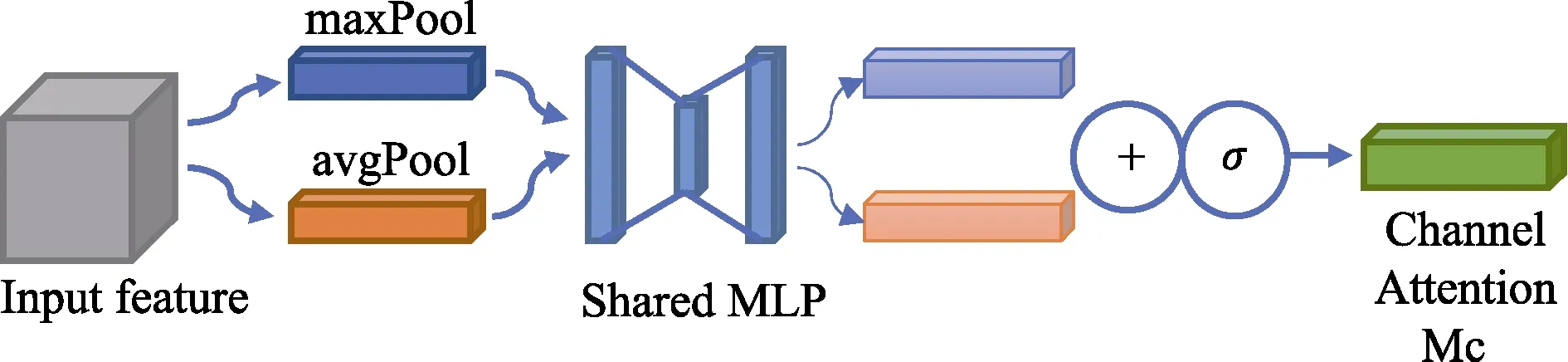
图7 通道注意力模块Fig.7 Channel attention module
空间注意力模块主要关注于位置信息。如图 8所示,空间注意力模块在通道的维度上使用了最大池化和平均池化得到两个不同的特征描述,然后将两个特征合并,并使用卷积操作生成空间注意力的输出。计算过程如下:
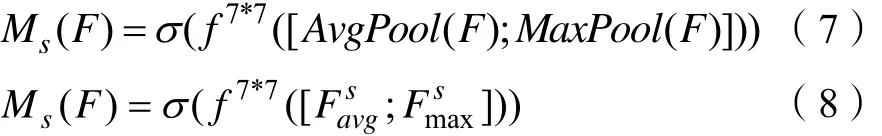
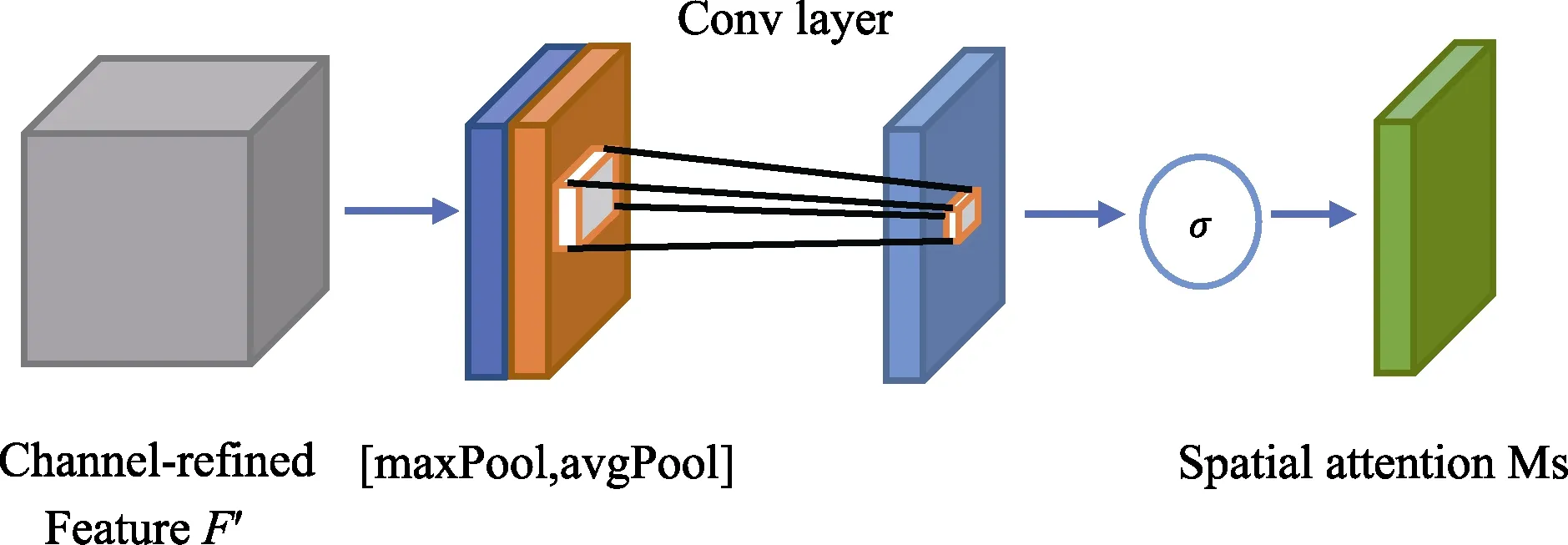
图8 空间注意力模块Fig.8 spatial attention module
在每个残差学习单元的第三层卷积之后添加CBAM模块。如图9所示。
图9 添加CBAM的残差学习单元Fig.9 Residual learning with CBAM
添加了注意力模块的 ResNet50模型的核心框架如表1所示,输入为224*224*3的图像,卷积层采用传统的 5层架构,第一层卷积使用 7*7的卷积核,步长为 2,padding为 3,接下来使用大小为3*3,步长为2的卷积核进行最大池化操作。输出为 112*112*64。第二层到第五层使用添加了注意力模块的残差块,每一层包含的残差块个数为[3,4,6,3]。最后经过自适应平均池化和全连接层输出结果。

表1 模型架构Tab.1 Model architecture
2.2.3 训练样本集
首先,将切割的图片数据按照每一类样本数据均等拆分成训练集和验证集,这样可以使训练样本更加均衡。使用Scikit-learn中的stratifiedKFold函数可以做到这一点。使用双线性插值法放大到224*224大小,并且在训练集中随机变换图片的亮度、对比度、饱和度和色度,用来增强模型的泛化能力。使用交叉熵损失函数计算训练损失,并使用AdaBound[11]优化函数进行优化。训练集和验证集的准确率随着迭代次数的变化如图10所示。
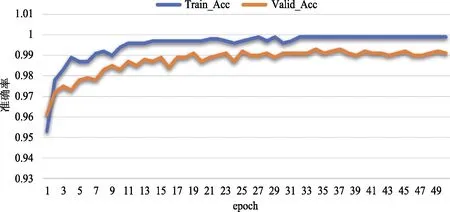
图10 训练集和验证集准确率变化图Fig.10 Plot of accuracy for training set and validation
2.3 模型测试
模型训练结束后,选取在验证集中准确率最高的模型最为最终的模型,并且在5000张测试集中测试模型的准确度。测试过程如图11所示,首先读取原始图片,将原始图片去噪并切割成4个单字符图片,每张单字符图片改变大小为 224*224,将 4个三维 224*224*3的单字符图片按顺序组合成四维4*224*224*3的数据,将组合成的四维数据输入模型进行测试,将输出的4个结果连接成字符串与正确的标签进行比较计算准确率。准确率的计算公式如下:
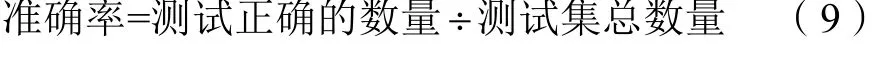
模型在5000张测试集中的准确率达到97.9%,部分识别结果如表2所示。
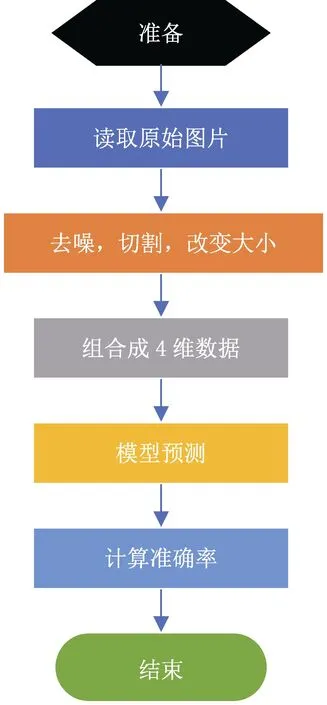
图11 测试流程图Fig.11 Test flow chart

表2 识别结果Tab.2 Recognition result
3 结论
本文通过卷积神经网络对验证码图片进行特征提取训练,在有线条干扰并且训练数据较少的情况下,模型依然能够达到接近98%的准确率。若能够去除干扰线、增加训练数据,或者使用多模型融合的方式,测试集的准确率将会进一步提高。从表 2可以看出,人眼能够识别的验证码图片,模型也都可以正确的识别,模型识别错误的图片,人眼也很难正确分辨。随着图像识别技术的不断发展,验证码的生成规则也将发生改变。
