基于卷积神经网络的多肉植物细粒度图像分类
2020-05-13黄嘉宝朱永华周霁婷高文靖
黄嘉宝, 朱永华, 周霁婷, 高文靖
(1.上海大学上海电影学院,上海200072;2.上海大学计算机工程与科学学院,上海200444)
细粒度图像分类是目前图像分类中的一个热门话题,其目标是在一个大类的数百数干个子类中正确识别目标.它在汽车车型、鸟类、猫犬和花的种类识别等领域有着广泛的应用,其中大部分使用了卷积神经网络.当前的研究热点是双线性卷积神经网络.本研究选择了原创数据集进行细粒度图像分类.一方面是利用迁移学习这一强大的工具来完成小型数据集的训练;另一方面是多肉植物肉眼不易分辨种类,希望通过特征提取和神经网络训练达到高识别率,从而促进多肉植物种植的推广和改善栽培管理.
与粗粒度图像分类(通用图像分类)相比,类间的细微差别使得细粒度分类非常具有挑战性.粗粒度和细粒度图像分类之间的区别如表1所示.可以看出,在粗粒度图像分类中,将4张输入图像分类为植物;而在细粒度图像分类中,可将其识别为所属子类,例如第一张图的植物名为紫珍珠.由于长相差异较小,除了小部分的多肉植物爱好者,人们很难正确辨别出多肉植物的特定名称.为了了解这些差异,需要一个大型的数据集来提供学习,但目前还没有现成的多肉植物数据集.此外,在因不同视角、背景、光效和成长阶段导致的视觉复杂度,有限的时间和计算机运算能力等条件限制下,完成这项任务十分困难.

表1 粗粒度图像分类和细粒度图像分类的区别Table 1 Basic-level image classification vs.fine-grained image classification
本研究设计、实施和测试了一个轻量级的端到端系统.该系统使用了目前流行的深度学习框架Caあe来对预先训练好的分类器进行微调,以便进行特定的细粒度分类测试.本研究基于在ImageNet上训练的深度学习模型,具有非常普遍的特征,并且尽可能少地改变以适应原创训练数据.
本研究对包含了20种不同种类多肉植物的原创数据集进行了实验.由于图像的自由度,这个数据集非常具有挑战性.但通过微调卷积神经网络后的强监督图像分类,依然获得了高质量的结果——96.7%的精准率.
1 相关工作
1.1 卷积神经网络
卷积神经网络是前馈神经网络中非常经典的模型,包括卷积层和池化层等.卷积神经网络主要用来识别位移、缩放以及其他形式扭曲不变性的二维图形.近年来,卷积神经网络已被用于大量的图像处理和分类工作,其能力不仅是学习特征的权重,更是学习特征本身.由于卷积神经网络在通用图像分类[1]上已经达到了非常高的精度,故本研究将广泛地使用卷积神经网络作为分类器的主要架构.
1.2 迁移学习
迁移学习是一种机器学习技术,侧重于对新任务的学习分类器进行重新研究[2].在卷积神经网络的迁移学习中,首先在基础数据集上训练基础网络来创建权重和特征;然后通过重新训练基础网络已有的权重和特征的一个子集,将这个分类器转移到新的数据集.整体效果是适合新数据集的分类器,工作量比重新训练新网络要少得多.当目标数据集显著小于基础数据集时,迁移学习可以成为一个强大的工具,使得训练大型目标网络时,最小化过拟合.在一些任务中,迁移学习展现了极佳的效果[3].
1.3 细粒度图像分类
细粒度图像分类是计算机视觉领域最基本、最具挑战性的开放性问题之一,在学术界和工业界引起了广泛关注.在鸟类[4-10]、植物[11-13]、食物[14]、汽车[15-18]和飞机[19]等多个领域进行的细粒度图像分类调查发现,大部分方法都使用卷积神经网络.对于大多数任务来说,每个分类的例子数量通常都相当大以允许良好的泛化精度,但本研究的数据集相对较小,故而难度相对增加.
2 多肉植物细粒度图像分类
2.1 实验流程
本研究将原创多肉植物的数据集通过预处理后作为训练集和测试集,再通过微调后的卷积神经网络训练,得到可用于图像分类的模型,具体流程如图1所示.
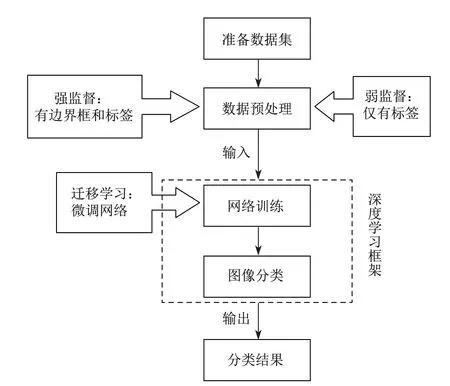
图1 实验流程图Fig.1 Experimental flowchart
2.2 准备数据集
本研究收集并整理了从百度和谷歌图库下载的共20 000张图片,完成了原创数据集.该数据集包含了20种不同种类的多肉植物(见图2),分为10 000个训练图像和10 000个测试图像.每个图像都包含至少一株背景不同、视角不同的多肉植物.由于焦距、照明和摄像机位置等原因,每个图像的质量差异大.

表2 多肉数据集样本Table 2 Samples of the succulents’dataset
2.3 数据预处理
所谓强监督分类是指在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框和部位标注点等额外的人工标注信息.弱监督分类的思路与强监督分类相似,也需要借助全局和局部信息来进行细粒度级别的分类.区别在于,弱监督分类希望在不借助部件标注点的情况下,也可以做到较好的局部信息捕捉[20].
步骤1 为数据集设置人工标签,编号为0~19.
步骤2 强监督分类和弱监督分类的区别在于数据集有无边界框.为了进行强监督分类,训练数据中的背景噪声需被排除.因此,使用描述每个图像中存在多肉植物正确位置的边界框来裁剪图像,其中使用工具LabelImg完成边界框的绘制,使用Python脚本完成图像裁剪.为了保留多肉植物周围的一些背景,边界框的每条边都在裁剪之前扩大了16个像素,裁剪前后变化如图2所示.

图2 强监督分类处理示意图Fig.2 Preprocessing of supervised classification
步骤3 由于训练集包含各种图像尺寸和横纵比,因此需要把每张图像尺寸调整为正方形,并且更改分辨率为227×227以配准模型要求.本研究是在不保留横纵比的情况下压缩了图像,而不是缩放或裁剪.
2.4 网络模型
为了减轻数据和运算时长的限制,本研究选择了一种侧重于迁移学习来快速创建和训练神经网络的方法.为了比较,采用AlexNet和GoogLeNet两种网络.
2.4.1 AlexNet
文献[1]提出的模型是一个深度卷积神经网络,它在ImageNet大规模视觉识别挑战数据集上成功训练了大约120万个1 000种不同类别的标记图像.AlexNet架构拥有约65万个神经元和6 000万个参数,包括5个卷积层、2个标准化层、3个最大池层、3个完全连接层和1个输出中具有Softmax激活的线性层.
2.4.2 GoogLeNet
GoogLeNet是对AlexNet的改进,共有22层.由于每个完全连接的层的权重较小,GoogLeNet的参数是AlexNet的1/12,并且更加准确[21].GoogLeNet在不同深度的每个输入都会产生3个输出.但为了简洁起见,本研究只使用最后一次的输出结果.
2.5 网络微调和训练
本研究做了4个实验:使用微调网络AlexNet和GoogLeNet分别进行强监督和弱监督细粒度图像分类,实验编号为①~④.使用流行的深度学习框架Caあe[22]来构建、训练和测试这两个网络.每个模型对原像素数据进行50 000次迭代,学习率为0.001,衰减率为0.9.
在使用ImageNet训练的权重对每个网络进行预初始化之后,对网络的最后3层进行了微调:对于AlexNet,在丢失输出之前调整最后3个完全连接层;对于GoogLeNet,在每个丢失输出之前立即调整2个完全连接层和卷积层.在多次调整后,选取了最佳的效果.实验参数对比如表3所示,网络结构如图3所示.
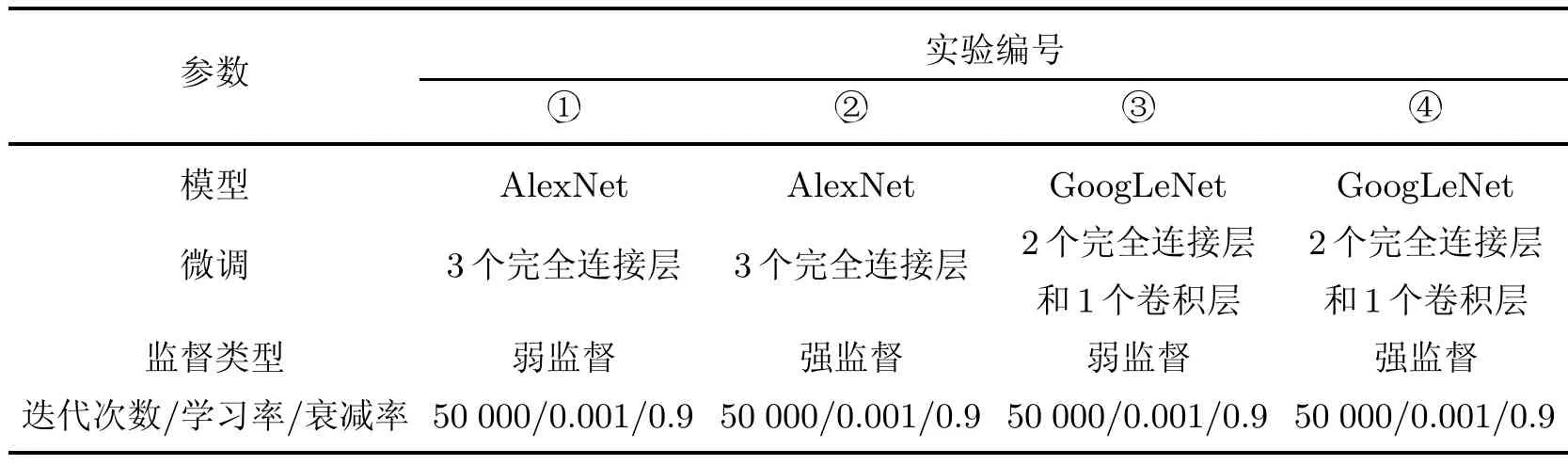
表3 4个实验的参数对比Table 3 Comparisons of parameters of the four experiments
2.6 图像分类
深度学习框架Caあe的核心是用C++编写的.可以使用Caあe的C++API实现类似于Python脚本的图像分类应用程序.本研究将网络训练后得到的4个模型结合官方文档来完成使用Softmax方式的图像分类.

图3 网络结构Fig.3 Network structure
3 实验结果
3.1 训练结果
表4整理了4个实验的3项数据:前1(Top-1)精准率、前5(Top-5)精准率和最终损失精度,其中最佳表现用粗体标出.可见,微调GoogLeNet的强监督分类达到了最佳效果,前1精准率达到了96.7%.
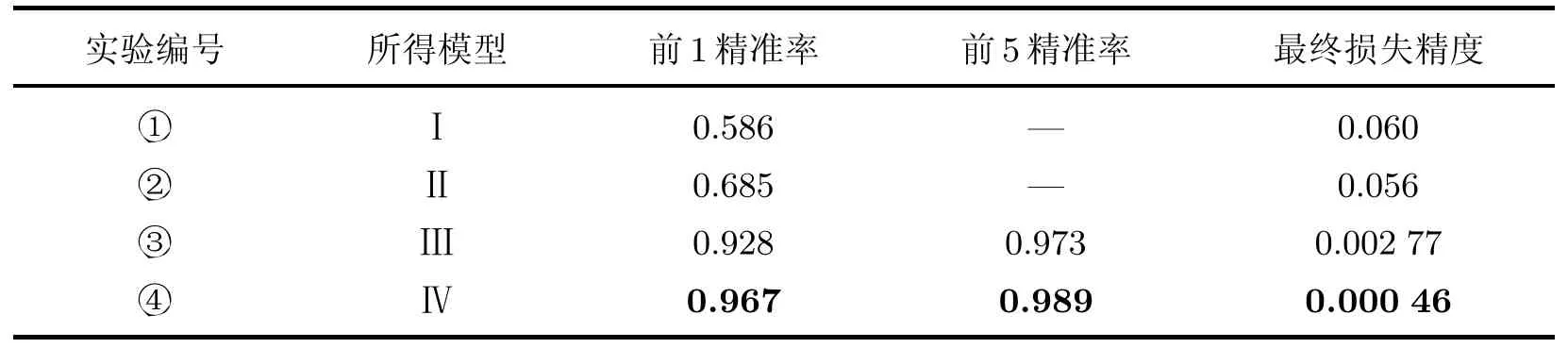
表4 4个实验的前1、前5精准率和最终损失精度对比Table 4 Comparisons of Top-1 accuracy,Top-5 accuracy and final loss of the four experiments
图4和5展示了4个实验过程中,精准率和损失率的数值变化.可以看出:对于AlexNet,迭代15 000次后,强监督分类的精准率在70%上下浮动,弱监督分类的精准率在60%上下浮动;对于GoogLeNet,迭代8 000次后,强监督分类的精准率基本稳定在97%,弱监督分类的精准率基本稳定在92%.
3.2 分类结果
本研究测试了多个图像的分类.图6为测试分类的样本,表5为7次分类的前1预测值,表6为模型Ⅳ测试样本“黄丽”的前5预测值.结果表明,微调GoogLeNet的强监督细粒度图像分类成果显著,能有效完成多肉植物分类的任务.
4 结束语
虽然本研究在多肉植物细粒度图像分类这一特定任务中取得了一定的进展,但仍有许多方面需要进一步探索和改进.本研究只测试了2个不同的典型卷积神经网络模型(AlexNet和GoogLeNet),还可以进行更多的迁移学习,并且这两种模型都是用ImageNet权重来设计和初始化的,明显缺乏多样性.
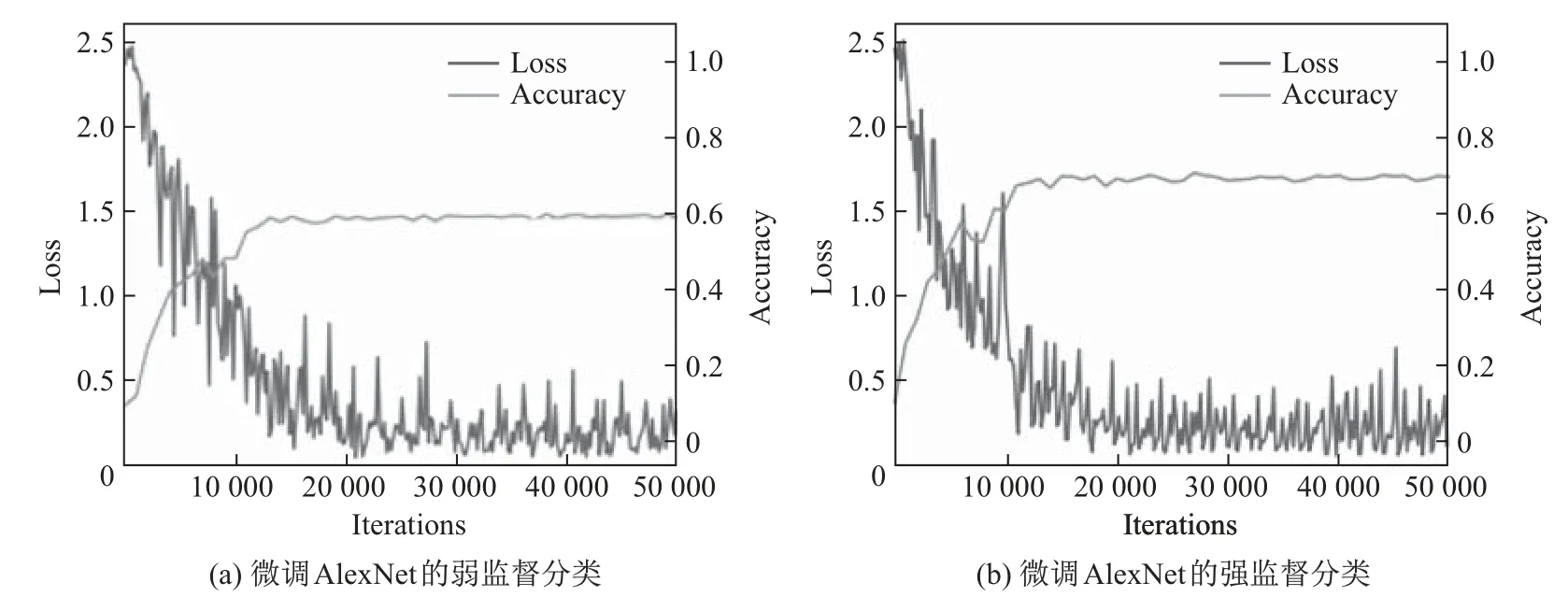
图4 微调AlexNet的弱监督分类和强监督分类Fig.4 Fine-tuning AlexNet’s weakly supervised classification and supervised classification
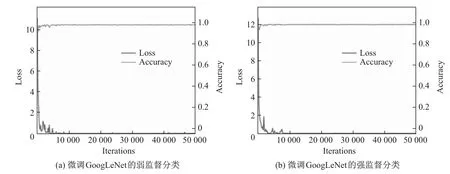
图5 微调GoogLeNet的弱监督分类和强监督分类Fig.5 Fine-tuning GoogLeNet’s weakly supervised classification and supervised classification

图6 测试样本Fig.6 Test samples
此外,最初的调查只是针对细粒度的分类,在原创数据集整理完成之后添加了数据约束.虽然这让本研究对稀疏数据训练的本质有了一些了解,但更丰富的数据会更有助于改进本研究.

表5 7次分类的前1预测值对比Table 5 Comparisons of the Top-1 predictive values of the seven classifications

表6 单次分类的前5预测值Table 6 Top-5 predictive values of a single classification
