动态奇异值网络的三维模型识别
2020-05-12罗文劼田学东
罗文劼,张 涵,倪 鹏,田学东
(河北大学 网络空间安全与计算机学院,河北 保定 071002)
E-mail:luowenjie@hbu.edu.cn
1 介 绍
卷积神经网络的出现使得三维模型识别任务得到了快速发展,如AlexNet[1],VGGNet[2]和GoogLeNet[3].对于大量的三维模型来说,较为成熟的研究工作是将2D图像与卷积神经网络相结合,但会导致每张图像不能充分表达三维模型的特征,如何更好地融合这些图像的信息使之具有更全面的表达是投影方法的研究重点.文献[4]使用最大池化(max pooling)方法将多个三维模型视图进行特征融合,如图1(a)所示.然而这样的最大值融合忽略了其他视图的有效信息,对于一些差距较大的视图信息不能全面地反应三维模型的整体特征.文献[5]利用视图之间的内部关联和区分度进行分组整合,得到一系列加权的视图特征作为三维模型的特征描述符,如图1(b)所示,但这样增加了额外的参数.
SVD分解和PCA(principal component analysis)都是主成分分析的表达方式,被广泛应用到图像识别任务中.文献[6]结合2D图像的张量表示,将每个视图特征的标准差作为权值与其特征相结合,提出加权多线性主成分分析方法.文献[7]将PCA与神经网络结构相结合,使用级联的PCA卷积核模拟卷积神经网络结构进行特征提取,展示了传统方法在浅层神经网络的有效性.但这样的结合方式只是简单的将PCA做一种固定化的线性降维手段,在多维特征属性下并不具备灵活性.文献[8]中的协调子层(Harmonizing sub-layer)和卷积子层(Conv sub-layer)也使用了SVD分解进行特征提取,但只是简单地将这一层中的所有特征作为一个整体进行操作,并不能很好地进行非线性变换.如图1(c)所示,动态奇异值法根据卷积神经网络训练时的权重对奇异值进行动态更新,提取出影响较大的动态奇异值信息,从而在神经网络训练过程中将同一三维模型的不同视图进行自适应融合.

图1 最大值融合法、视图分组融合法和动态奇异值融合法
2 相关工作
三维模型检索的种类分为基于三维结构(3D structures)和基于投影两大类型,基于三维结构计算的方式有点云(point clouds)、多边形网格(polygon meshes)和体积网格(volumetric grid)等,基于投影的方法则是利用模型2D图像进行特征提取.虽然三维结构可以全面地反应出模型的特征,但由于点与点之间的复杂结构,导致不能很好的与神经网络相结合,分类检索的效果不如投影方法.
2.1 基于三维结构方法
基于三维结构的方法是用距离、角度、区域面积、体积结构、距离直方图[9,24-26]、热扩散特征(Heat kernel signature)[10]和卷积神经网络[11]来学习.文献[12]模仿沙漏网络的编码器解码器(encoder-decoder),用kd-tree对三维点云模型建立encoder网络,通过学习调整decoder参数还原输入层.文献[13]通过深度信念网络(deep belief network)训练三维模型的点云数据,并构造2.5D图像来分类三维模型.然而基于三维结构的方法都要计算三维模型点与点之间的关系,这些点的信息具有数量庞大、丰富多变的性质,增加了分析计算的成本,方法[14]通过改进卷积神经网络的结构减小了计算量.
2.2 基于投影方法
投影方法致力于研究视图的角度、颜色、边缘特征等影响,文献[15]在预先定义的视点处设置一系列虚拟相机以捕捉视图,这些视点可以是十二面体的顶点,文献[16]将模型位于单位球体上投影.由于计算单位是像素值,相比于基于三维结构的方法更加简洁,而且分类检索效果也更好.对于不同角度进行分类处理的方法有文献[5],对于神经网络特征再处理的方法有文献[17],融合多种特征提取方法的文献有[18,24-26].
第3、4章分别描述了动态奇异值网络的组成部分和其在识别检索任务中的规则.
3 动态奇异值层
动态奇异值层是一个多级运算单元,集合了区域化层、自适应SVD层和压缩层.如图2所示,假设区域X×Y×C被划分为一系列x×y×C大小的矩阵,其中C表示通道维度大小,这些子区域经过自适应SVD层处理后联合得到中间层特征Fmid,这个特征可以根据条件要求选择性地进入区域层的级联模式,最后经过压缩层的维度变换得到最后的全局特征.

图2 动态奇异值层的计算过程
3.1 区域化层
通过步长值s将CNN的特征作为区域切分对象,这一属性类似于卷积神经网络中卷积核的计算过程,可以有效地关注局部特征.假设模型A具有N个角度的视图特征,用集合表示为A={a1,…,aN},这些特征的定义域为Rw×h×C×N,表示其张量大小为w×h×C.所有子区域及其定义域表示为K∈Rx×y,在每个独立的区域内会沿着所有通道进行相同的操作,其中x×y(x≤w,y≤h)代表了子区域的大小.因为在CNN的特征张量中都为方阵,所以也满足w=h及x=y.对于每一个a的子区域K按如下划分
⎣x+ms」=w,⎣y+ns」=h
(1)
每个子区域kZ(a)的划分在最初定义时就被固定且不变.
3.2 自适应SVD层
SVD分解过程被表示为
(2)

(3)

(4)
为了方便的表示梯度值计算,SVD分解被描述为
P→UWUT

(5)
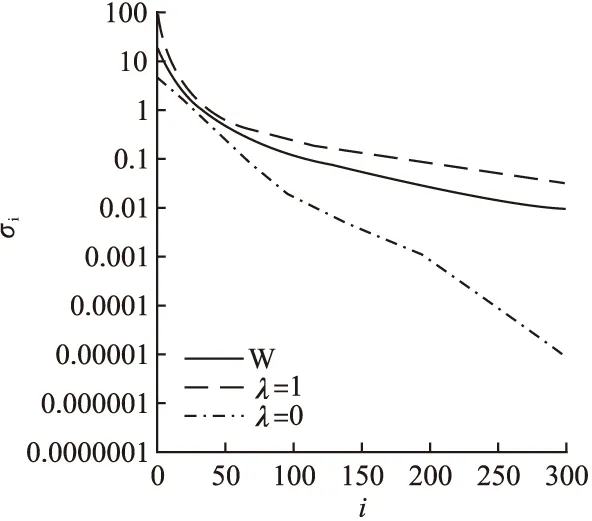
图3 自适应幂权值对奇异值的影响

(6)
其中⊙表示为阿达玛乘积(Hadamard product),关于SVD分解的详细的倒数推导在文献[19]中.矩阵φ定义为
(7)

(8)
其中It表示一个t×t对角线是零元素但其他位置都为1的矩阵,矩阵ψ′(W)被定义为
(9)
3.3 压缩层

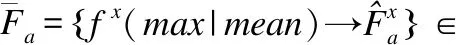
(10)
其中fx(.)表示为
(11)
重构层将2D目标矩阵的维度转换为1D 向量
(12)
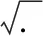
(13)
其中mat(.)是可以将一维向量转换为二维矩阵的方法.使用全连接层将全局特征进行L2归一化:
(14)

(15)
4 识别任务
经过动态奇异值层的特征计算后,模型A的全局特征被表示为
(16)
NA表示模型A的视图个数.
4.1 模型分类

(17)
Θ(γ)方法表示被分到γ类的视图个数,初始值为0.
(18)
4.2 模型Top-N检索
视图与模型存在着多对一对应关系,但每张视图所包含的信息量是不同的,由此可以利用信息量较大的图像代表每个模型,建立视图和模型的一对一方法,这样可以加速模型的检索速度.将虚拟相机倾斜于水平面夹角60度并且固定在非正视图的位置可以使更多的点被投影到图像中,有效地增大模型的拍摄面积.
单视图Top-N检索有多种评判方式,这里使用视图到模型的幂次距离来确定检索结果.幂次距离作为非线性变换的一种表达方法,可以增大较大值与较小值之间的差值,但相近的值不会有明显变化.以1为分界点,当特征的数值大于1时,幂次方将扩大数值的大小,否则减小数值大小.假设一个模型和其投影图像为B={b},需要对其进行逐模型的特征比较(shape-wise matching).用符号G表示数据集中所有的被查询模型,最小幂次距离法定义模型B到所有被查询模型的距离集合为

(19)
其中〈-〉表示逐元素相减(elements-wise subtract),TopN代表模型到模型之间的距离方法R(.,.)的排序结果,这种方法可以有效排除那些与视图差异较多的模型特征,将多数视图距离更近的模型排列到前排检索结果中.
平均幂次距离法可以有效降低单一视图的误差影响,同时在视图融合样也可以缓解单视图匹配的信息量不足的问题.与最小幂次距离法类似,查询模型B的视图要与被查询模型G的每个视图特征进行比较,表示如下

(20)
其中sum(α)方法表示对α中所有元素进行求和运算,α表示一个向量或一个矩阵.
5 实 验
实验用到的基础网络模型为Inception-v4[20],DSVN(Dynamic singular value network)的构建是通过去除网络最顶层并替换为动态奇异值层后得到的,图4展示了不同方法的精准率与召回率曲线,从中可以看出Inception-v4具有较好的泛化能力,可以很好地适应三维模型的特征提取任务,同样DSVN也展示出明显的提升.

图4 不同方法在Mode1Net40数据集上的准确率召回度曲线
ModelNet是一个开源的三维模型数据集,包含了训练和测试的数据文件,已经成为了众多研究者验证实验结果的数据来源和重要佐证.ModelNet 涉及10类和40类两种数据集,包含150K 3D CAD 模型和660个独立的模型种类.实验在这些模型中每个类别选取出80个训练样本和20个测试样本.
由于三维模型是由.obj、.off、.stl等文件格式构成,转换为2D图像就需要渲染过程,两种不同的渲染方式被应用到多视图三维模型识别中,Phong[21]和Blender(一种构建三维模型的软件)结合的渲染效果相比于OpenGL 细节更为突出,可以渲染出明显的纹理结构,但缺点是渲染时间较长.投影方法是将虚拟相机设立于与水平面呈30度的夹角,并旋转一周获得12个独立视角图像.为了确保与网络模型的输入层一致,每张图像的大小设定为224×224像素.
网络训练过程中要保证所有超参数(hyper-parameters)的一致性,确保所有对比实验的可靠性.学习率设定为4×10-4,使用批量梯度下降算法(mini-batch stochastic gradient descent)加速网络参数的收敛速度,每一轮(epoch)进行2000 次迭代,共进行20轮,所用设备为:GeForce GTX 1080Ti GPU、中央处理器Intel Xeon E5-2680 v2 2.80GHz、内存64 GB、操作系统CentOS 7.2.1511.训练大约花费1天时间,为了获得最好的模型参数,每一轮都保存参数模型结果.训练过程中σ和λ都会最终达到一个相对平衡的位置,可视化结果如图5所示.可以看出特征σ在5轮之后在0到1附近平衡,这代表了全局情况下的σ平均值变化情况,而λ先是有一个小幅度上升并在第5轮之后趋于平衡状态,最终在0.4附近震荡.(n,5,5,1536) 是网络结构中的最后一层输出的张量,其中n代表图像数量,后三个参数分别是5×5的特征大小和1536个通道维度.关于动态奇异值层的一种方案设计如下.

图5 多个三维模型的平均σ的变化(左)及平均λ的变化(右)
9×:动态奇异值网络结构的维度变换为:子区域化大小定义为3×3,CNN特征被划分为3×3×9×1536,再经SVD分解变换为3×9×1536的张量,最后维度压缩将特征变换为(n,9×1536)的向量.

图6 平均幂次距离法在ModelNet10数据集上的检索样本.其中错误的检索结果用方框标出
不同方法的性能对比如表1所示,较早的方法精度都低于80%,MVCNN的分类精度接近90%,GVCNN的分类精度超过了90%,然而所有的数据都低于MVCNN使用Inception-v4网络训练的精度.通过扩大9倍动态奇异值层输出维度以及使用最大压缩方式得到在ModelNet40数据集上的分类精度为94.4%,mAP值为93.4%.而使用平均压缩的方式分类精度在ModelNet40数据集上提升到95%,mAP提升到94%.
为了测试不同参数下的网络Top-N 检索性能,选择了每个类别50个三维模型和检索库中的每类20个模型进行比较.实验结果如表2所示,平均精度曲线(A-P curves)与平均找回曲线(A-R curves)如图7所示.由于特征向量的数值范围在[0,1]之间,为了扩大特征数值之间的距离,实验中取ρ,μ=2.对于在ModelNet10数据集上的最小幂次距离法, DSVN, max 9×高于MVCNN (Inception-v4) 2.1个百分点,DSVN, mean 9×高于MVCNN (Inception-v4) 2.9个百分点.而在ModelNet40数据集上的最小幂次距离法DSVN, max 9×高于MVCNN (Inception-v4) 1.8个百分点,DSVN, mean 9×高于MVCNN (Inception-v4) 2.5个百分点.对于在ModelNet10数据集上的平均幂次距离法,DSVN, max 9×和DSVN, mean 9×分别高于MVCNN(Inception-v4) 2.9和4个百分点,在ModelNet40数据集上分别高于3.7和4个百分点.
表1 不同方法在ModelNet40数据集上的分类和检索结果
Table 1 Classification and retrieval results of ModelNet40 dataset compared with the state-of-the-art methods

methodTraining Config.Pre trainFine tuneTest Config.#ViewsClassification(Accuracy)Retrieval(mAP)(1)SPH[22]———68.2%33.3%(2)LFD[23]———75.5%40.9%(3)3D Shape Nets[24]ModelNet40ModelNet40—77.3%49.2%(4)MVCNN[4],12✕ImageNet1KModelNet401289.9%70.1%(5)MVCNN[4],metric,12✕ImageNet1KModelNet401289.5%80.2%(6)MVCNN[4],80✕ImageNet1KModelNet408090.1%70.4%(7)MVCNN[4],metric,80✕ImageNet1KModelNet408090.1%79.5%(8)PointNet++[14]—ModelNet40—90.4%—(9)KD-Network[23]—ModelNet40—91.8%—(10)MHBN[21]ImageNet1KModelNet40692.2%—(11)GVCNN[9],8✕ImageNet1KModelNet40893.1%79.7%(12)GVCNN[9],12✕ImageNet1KModelNet401292.6%81.3%(13)MVCNN(Inception-v4)ImageNet1KModelNet401293.8%93.2%(14)DSVN,max 9✕ImageNet1KModelNet401294.4%93.4%(15)DSVN,mean 9✕ImageNet1KModelNet401295%94%
*metric=low-rank Mahalanobis metric learning
表2 两种距离方法在不同参数网络下的Top-10检索性能比较
Table 2 Performance of two distance methods in different network parameters result for top-10 retrieval

方法距离ModelNet10(精准度)ModelNet40(精准度)MVCNN(Inception-v4)min-power93.7%91.7%DSVN,max 9✕min-power95.8%93.5%DSVN,mean 9✕min-power96.6%94.2%MVCNN(Inception-v4)avg-power95.9%94%DSVN,max 9✕avg-power98.8%97.7%DSVN,mean 9✕avg-power99.9%98%
表3 不同网络参数下在ModelNet40数据集上的性能比较
Table 3 Performance of different parameters perform on ModelNet40 dataset

网络模型子区域大小压缩方式级联精准度mAPDSVN,max 5✕5×5max92.4%92%DSVN,max 3✕3×3max 93.6%92.8%DSVN,max 9✕3×3max94.4%93.4%DSVN,max 16✕2×2max94%93.1%DSVN,max 8✕2×2max 93.7%92.6%DSVN,mean 5✕5×5mean92.6%92.5%DSVN,mean 3✕3×3mean 94.1%93.4%DSVN,mean 9✕3×3mean95%94%DSVN,mean 16✕2×2mean94.5%93.2%DSVN,mean 8✕2×2mean 93.9%92.9%
图6展示了平均幂次距离检索的结果,方框中为错误检索的模型类别,而ModelNet中存在特征相似但不属于同一类别的模型,人眼也无法做到准确辨别,因此平均幂次距离法的相似度匹配具有较好的检索效果.
6 参数讨论
本节讨论动态奇异值网络不同参数对实验结果的影响以及幂次距离对检索的影响,网络中的参数包括区子域结构的大小、选取维度压缩的方式和影响输出维度大小的级联参数的使用.除了上一节介绍的9×外其余的参数模型如下:
5×:子区域大小为5×5是一种设计简单的方案,由于直接将CNN的输出特征作为整体,区域化层未被激活,从而特征维度变化最小,不利于局部特征的表达.
3×:子区域大小为3×3,这种方法同9×不同的是使用了选择性参数——级联,经过SVD分解得到1×9张量,所有被分解的张量聚合后有形成一个新的特征维度,再次被区域化层处理和自适应SVD层处理,得到1×3大小的张量,最后经过压缩层转变为(n,3×1536).
16×:2×2的子区域大小可以获得一个2×16的特征矩阵,却成为最大输出规模的方案.
8×:这种方案同样用到了级联属性,是在16×的基础上缩小了一半特征维度.
通过实验数据表3所示,使用了级联参数的模型表现效果并不理想,虽然这样的做法可以将网络维度缩小一半,但循环使用此方法提取特征会降低算法的有效性,建议每层只使用一次可以降低局部特征的损失.一个明显的结果是压缩方式的使用情况,多数的均值方法高于最大值方法的表现.而子区域大小选择3×3时效果最好.
表4分析了幂次距离中的参数ρ和μ对检索的影响,可以发现ρ,μ=2时的表现效果最好.

图7 平均准确率和平均召回率
表4 MVCNN(Inception-v4)使用平均幂次距离在ModelNet10数据集上的检索效果
Table 4 MVCNN(Inception-v4)uses avg-power distance to retrieve results on the ModelNet10 dataset

ρμ-1 123095.04%95.82%95.2%0.5—95.92%95.84%1—95.88%95.86%
7 结 论
本文提出了一种动态奇异值方法,与卷积神经网络形成端对端网络框架,动态幂权值的奇异值属性可以对多角度的视图进行自适应特征融合.同时,使用区域化方法和压缩方法极大地关注了局部特征的表达,平衡了多个维度下的特征参数.幂次距离与平均距离的结合方式对于三维模型的检索具有较为突出的效果,实验部分设计了多种方案对比不同参数的影响,并找到一组泛化能力最好的参数值,对检索问题中不同种类的模型有很强的特征区分度,验证了本方法在三维模型分类和检索工作中的有效性.
