移动云环境下的实时协同编程机制及策略研究
2020-05-12高丽萍赵春芽
高丽萍,赵春芽
1(上海理工大学 光电信息与计算机工程学院,上海 200093)
2(复旦大学 上海市数据科学重点实验室,上海 200093)
E-mail:lipinggao@usst.edu.cn;450190073@qq.com
1 引 言
近些年来软件行业的繁荣发展,移动云计算是当今的主要流行趋势,移动资源,云计算和云服务为协同交互应用带来了巨大挑战.同时网络技术的发展使大量的协同编辑应用程序得到了很大的开发,同时软件规模和复杂度也在提高,将计算机支持的协同工作与编程环境相结合是协同工作中重要的研究领域,协同编程不仅能提高工作效率,还能使各个站点的用户更方便工作.过去的几十年,已经有许多的协同软件研究者致力于协同编程软件或是协同编程方法的研究上,研发了一系列的协同开发工具.协同编辑工具在近年来得到了广泛的应用,在很多企业中也在使用协同办公软件很多的应用程序也广泛支持异步开发,比如wikis和版本控制系统.或者是同步协作,如分布式实时协作编辑器,协同设计工具或云集成开发环境.
乐观复制[5],即副本数据全部复制结构,是过去在集中式架构(Jupiter[14]算法和TIPs[15]算法),和一系列协同编辑中广泛采用的方法,这能够有效的解决分布式系统中网络延迟问题和数据一致性问题,如GoogleDrive(1)“Google drive,”https://drive.google.com.和Docs(2)Google Docs[ED/OL)://docs.google.com是在全部复制的基础上使用操作转换来保持一致性.但是在大规模数据并发下,比如Xia[4]提出的部分复制的概念去解决评论系统下的数据一致性,因为评论节点之间是树形结构,该部分复制的思想是如果对一个评论节点进行操作,需要把该节点的父节点和兄弟节点加载到本地,称之为骨架节点,在服务器端使用一个副本结构对本地骨架节点进行数据跟踪,用来完成对本地数据的数据同步和增量更新.
传统的协同编程体系中,在数据部分复制方面和控制语义冲突方面还有很多能够优化的地方.本文针对在云环境下,采用新的基于TIPs[1]的集中式架构进行操作转换,并根据Fan提出的共享锁[5]的结论来控制语义冲突的发生,论文整体结构如下:第二部分介绍了协同编程的研究背景及相关工作;第三部分是分析了在云环境下协同编程模型;第四部分提出了在服务器端进行的操作转换和冲突解决方案;第五部分对相应的操作转换算法进行可行性分析和评估;第六部分叙述了CloudCode原型系统设计的相关技术;第七部分进行总结和对未来的展望.
2 相关工作
在近些年来的研究工作中,协同编辑技术被大量的开发和应用.最常用的一致性维护技术有操作转换(Operation Transformation,OT)[6,7,9]技术和地址空间转换(Address Space Transformation,AST)[8]技术,以上两种技术最初都是在点对点的协同交互应用中提出的,在实时编辑时每个用户能够立即看到其他用户的改变.Xia[4]提出了适合在移动云环境下应用的地址空间转换方法,并将这一方法运用到了评论系统中.根据操作转换,可以对并发操作做出合并,包括Ellis和Gibbs[17]在文献中提出的DOPT算法,Sun和Ellis[7]提出的GOT和GOTO算法,Sun[11]在文献中提出的COT算法等.
操作转换技术(OT)适合于非线性文档中,例如Ng A,Sun C[9]在文献中提出的实现实时文件管理系统的一致性维护.SUN[11]等在文献中提出使用OT算法解决了3D系统中文档依赖冲突的问题.Fu[18]等人在文献中提出改进GOTO算法以支持表格文档协同编辑下的一致性维护.版本控制[12],是在团队协同开发中使用的,根据每一个时刻指针所指向的版本,可以恢复到原来的版本,可以有效的对代码进行整合.
FAN和SUN在文献[18]中提出的DAL技术能够保证在实时协同编程环境中避免语义冲突.与OT不同的是:该方法采用悲观锁的方式,自动对编辑的文档内容进行加锁,拒绝其他用户的编辑操作,这种悲观锁的方式在实际应用中是不合理的,因为这种悲观锁的方式假设加锁的部分没有覆盖部分,还假设动态依赖图是静止不变的,而在实际编程条件下代码节点之间的依赖关系都是会发生变化的.后来又提出了三种共享锁(shared-locking on common depended regions)[5],这种方法能够保证高的响应性,有效性和一致性,并能在实时编程环境中阻止语义冲突发生.
Nieminen等人研究的CoRED[13]系统指的是基于浏览器上的对Java应用程序进行实时协同开发,不仅能够对代码词汇进行突出显示和缩进,还可以进行错误检测和代码自动生成.You[19]提出的协同编程环境下基于CAS并发处理思想的语义冲突消解方法,其核心思想是通过对目标对象设定期望值,若目标对象的期望值由于并发更改发生变化时,则操作不能执行.
Jupiter[14]算法和TIPs[15]算法是目前支持集中式架构的算法,其中JupiterOT算法是第一个将操作转换用在C/S结构中的,它使用二维状态向量来跟踪转换路径,最终数据状态取决于客户端与服务器同步的顺序,JupiterOT无法保证会采用正确的转换路径并产生正确一致的最终状态,因此使用这个算法的最终结果是不能够收敛的.
在移动云环境下的一致性维护研究中,Gao[1]提出的实时协同图形编辑,对TIPs算法进行了改进,原本TIPs算法采用HTTP协议,服务器端不能够主动为客户端发送消息,服务器和客户端之间的同步需要设置一定的时间间隔,对于在编程中,时间间隔的大小不容易控制,间隔过小会不利于编程效果,过大的话不能够很好的做出响应,这会造成很多带宽资源的浪费,通过实验能够证明,使用改进之后的TIPs算法能够使协同编辑效率提高.
本文将对树形评论节点的部分复制[4]思想进行改进,在实际编程中,如果对一个代码节点进行编辑,这个代码节点只与它的依赖节点有关系,所以只需要将依赖节点加载到客户端即可,我们提出了基于依赖关系的部分复制(Partial replication based on dependency),经过一系列的实验证明了可行性,并得到了很好的效果.数据部分如果采取全复制的方式会严重浪费带宽资源,客户端也不能得到快速响应,在协同编程中,更适合采用部分复制的方式.但是为了提高快速响应的能力和支持离线操作中数据一致性问题,采用部分数据复制分方法,这对协同编程并在解决语义冲突方面有很大的挑战.
根据Fan[5]等人提出的共享锁的结论进行并发操作,可以有效的防止语义冲突.根据Fan的结论,每个客户端只有满足下面的条件,并发操作才能得到许可:
1.编辑操作是在开放域中;
2.编辑操作是在一个基本域中;
该基本区域被本地的程序员作为工作区域已经加锁;或者是该基本域没有被其他合作的程序员加锁,并且它的依赖域没有被其他程序员作为工作区域加锁.
可以得出,当编辑操作发生在同一个节点上或者并发操作所对应的节点之间有依赖关系时,才有可能发生语义冲突.而对于没有依赖或间接依赖关系的并发冲突的代码一致性维护,相当于文本的一致性维护,在前面很多文献中已经有很多的解决方法了,本文不作为重点研究.
根据代码节点之间复杂动态依赖关系,运用云计算环境,在部分复制的基础上,进行一致性维护和解决语义冲突有很大的挑战性.移动云计算能为客户提供低成本,可靠和稳定的服务,云环境下的新的架构为协同编辑提出了很多新的挑战.
3 云环境下协实时同编程系统的设计与分析
3.1 基于协同编程的技术挑战
在协同编程模型中如果采用全复制结构,由于本地资源带宽的限制,会浪费很多不必要的资源.移动云计算,就是要将移动终端设备的庞大计算量通过网络传输移动到计算中心,通过云计算不仅能满足用户高的性能体验,还能满足数据量的需求.
1.架构的变化.在移动云环境下,为了充分利用良好的跨平台性,一般都是采用B/S模式,移动云环境下的客户端主要是移动设备(手机或笔记本电脑),服务器端一般是分布式体系架构,具有高扩展,高效率,高可靠等优点.这里我们采用分布式服务框架Zookeeper来管理分布式环境中的数据.
2.如何对所需要的编辑节点进行部分复制并对本地数据节点进行动态更新.传统的协同编辑都是采用全复制来解决高的响应性.在移动云环境下,采用部分复制的方法对本地数据进行动态一致性的维护,这种方式能够有效的节约本地用户的存储资源并减少能量消耗.
3.如何在部分复制的情况下,采用不加锁的方式,动态的实现客户端和服务器端的数据同步,同时维持高的响应性并保证不发生语义冲突.
4.如何设计简单高效的算法进行交互,满足用户动态加入或离开,并保证移动端和服务器端的有效扩展.
3.2 数据结构和基本定义
操作转换能够使用户在不加锁没有阻碍的情况下修改本地副本的任何部分,在协同编程中,可以通过进一步的改进,操作转换算法允许用户的并发操作按照任意顺序执行,并发冲突发生时,会按照规定的操作转换算法自动的解决和融合并发操作冲突.如图1所示,对这个list类中的代码节点用连续的字母表示,字母之间的连接方向就表示代码节点之间的依赖关系.
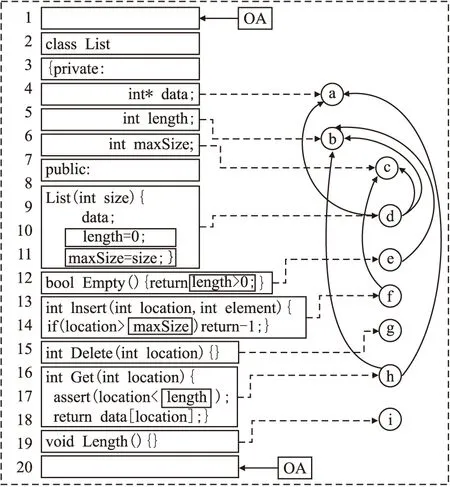
图1 代码节点之间的关系图
定义1.代码域(Code Area,CA)和开放域(Open Area,OA)
在一系列源代码组成的有语法意义的文档部分称为代码域(CA),代码文档之外的空白部分都是开放域(OA).
定义2.依赖关系
代码节点(Node)之间的依赖关系是动态变化的,依赖图之间的依赖关系代表代码节点之间的依赖关系.节点之间有直接依赖关系和间接依赖关系,例如C->B,B->A是直接依赖关系,C->A是间接依赖关系.
定义3.兼容关系(⊙)
代码编辑中的兼容关系表现为:1.并发操作发生在一对有依赖关系的节点上时,都是按照自己的意愿进行编辑的,且没有出现语义冲突;2.或者是并发操作发生在没有依赖关系的节点上;3.或者是并发操作所发生的节点有公共依赖节点.4.或者是并发操作都是发生在开放域(OA).
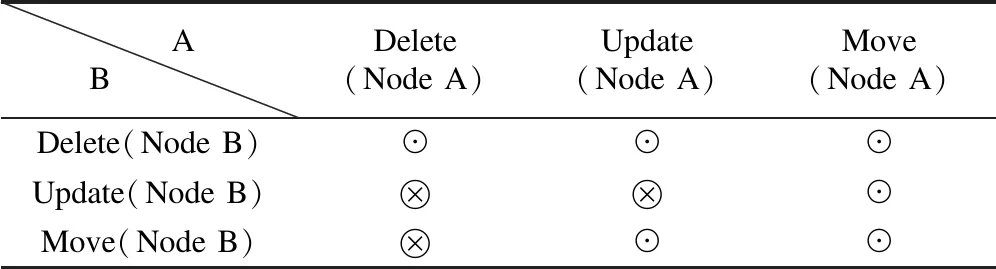
表1 并发操作发生在相互依赖的节点上如(B->A)情况时,会产生的冲突和兼容
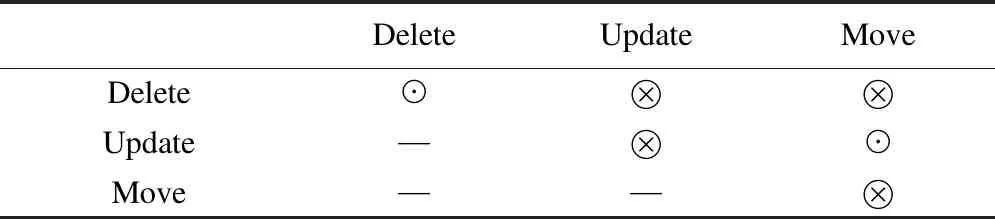
表2 并发操作发生在同一个节点时,会产生的冲突和兼容
定义4.相互排斥关系(⊗)
如表1、表2所示,如果多个用户并发对同一个节点进行操作,或者用户对有依赖关系的节点进行并发编辑也有可能发生语义冲突,相互排斥的关系不容易进行意愿融合,考虑到在实际编程的效果,出现相互排斥的关系时,系统会给产生并发操作的用户发送消息机制,根据返回的信息决定是保留哪个版本.下面的部分我们会详细说明,在并发操作发生在一个节点上,或发生在相互依赖的节点上的情况下,哪些情况可以进行意愿融合,哪些情况是通过发送消息机制来决定.
定义5.代码节点的数据结构(Node Structure)
每个代码节点(Node)包含的信息有唯一的位置标识符(AD),直接依赖的节点集合rootNode,对应代码域的文本内容(Code Content),被复制到客户端的代码类型Copy Type,如果该节点是工作节点就表示为WN,如果是依赖节点表示为DN,一个节点表示为{N | N=
定义6.全局唯一标识符Identifier(ID)
客户端对每个节点的操作O都会有一个标识符ID,这个标识符是一个二元组
定义7.操作类型(operate type)
编辑操作的类型和相关函数:
Create( ):表示创建相应的代码节点
Delete():表示删除指定的代码节点
Update():表示对指定节点进行修改或更新
Move():表示移动代码节点到一个新的位置.
定义8.操作(operate )
将客户端的一个操作O定义为四元组
3.3 部分复制
本文提出了基于依赖关系的部分复制(Partial replication based on dependency).在中心服务器端,整个完整代码节点目录会以主副本(Main Replica)的形式存在,客户端能够请求得到部分节点,在网页上进行编辑,程序编译和运行需要在服务器端进行,再将结果返回给用户,这样保证了移动端的运行效率,使能够随时随地在移动端进行编辑.当一个客户端加入这个编辑会话中时,有可能只需要编辑代码域的其中一部分,根据程序编程特点,在一个类中,基本包括两种语句,一种是定义,一种是函数,我们只需要把所编辑节点的依赖节点复制到本地.如图2所示,在这个依赖图中,如果对h节点进行编辑操作,为了保持节点之间的依赖关系,我们在复制服务器端副本的时候,需要把相关加点a和b都加载到本地,在编程的过程中有可能还会需要其他依赖节点,这就需要对本地数据进行增量更新,可以再次请求所需要的节点,而这不需要把整个代码文件全部下载下来,这会有利于节省本地的存储资源.这里需要注意的是,当一个代码节点被复制时,需要将记录在该节点的缓冲区的操作,也一同复制,便于得到最新的代码版本.
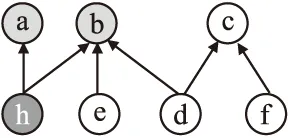
图2 代码节点的简单依赖关系结构
算法1.DetectTargetedNode(Node)
1.M={ }
2.If Node.rootNode is null
3. M=M+Node.AD
4. Return M
5.For item in Node.rootNode
6. Return M+DetectTargetedNode(item).AD
7.End
算法1的目的是:获取目标节点和依赖节点,即客户端所需要的所有的节点集合M.根据代码节点的唯一标识符定位该节点,再运用递归的方法获得所依赖的节点,再将得到的所有的节点的标识符记录下来,用来与骨架节点作比较(下文会有详细说明),只记录节点的标识符,可以节省所占用的内存空间,这一过程的时间复杂度可看做是O(1).
本地副本的增量构建:当一个客户端加入编辑会话的时候,第一个Request请求会发送到服务器,以获得客户端指定的代码节点.如果其他客户端的操作对本地相关节点进行更改,或者再次请求新的节点,就需要后续的Update操作根据服务器端的主副本来更新本地副本.但是为了节约带宽,如果请求的节点或者所对应的依赖节点已经在本地客户端存在,这个时候就只需要把本地没有的节点挑选出来返回给用户即可.在客户端的数据我们称之为副本数据(Replica Data).
为了快速高效的决定返回哪些节点给客户端,以响应再次请求,同时避免返回本地已经有的节点,我们需要在服务器端保存一个与客户端相同的骨架依赖节点(Skeleton Dependent Node),这个骨架依赖节点只用节点的标识符和复制类型来表示节点之间的关系,为了节省空间和快速查找,并没有存储实际的数据.该骨架依赖节点记录了哪些节点复制到了客户端以及节点复制的类型(CopyType),DN指的是复制成依赖节点,WN指的是复制成工作节点,目的是为了更好的跟踪每个客户端的数据状态.
算法2.RequestNode( R,q )
1.q ← Sync(R,q)
2.S ←Skeleton Dependent Node
3.M ←DetectTargetedNode()
4.Forall N∈M do
5.Case1:N∉R∩N∉S R.N.CopyType=DN and return N
6.Case2:N∉R∩N∈S R.N.CopyType=WN and return N
7.Case3:N∈R∩N∉S return null
8.Case4:N∈R∩N∈S R.N.CopyType=WN and return null
9.Update R and q
10.end
R指的是客户端副本数据,算法显示了响应RequestNode请求q的过程,包含了一个节点查询操作和提交本次请求之前的未提交给服务器处理的本地客户端操作.到服务器端,调用Sync( )函数进行同步从客户端发送过来的操作,该算法具体执行过程在下节给出.然后首先在最近更新过的主副本(main replica)上查询所需要的节点集合M以及M的依赖节点.
例如,如图2所示,如果客户端需要对h和e节点进行编辑,就需要请求节点S={h,e},根据前面的论述,通过一个查找依赖节点的函数(DetectTargetedNode( ))得到需要复制的节点集合M= {a,b,h,e},M中的节点指的是需要复制的所有的节点,如果客户端所请求的数据中,一部分节点有可能已经在客户端存在了,所以只需要返回客户端没有的节点即可,服务器端根据集合M中节点的复制类型,按照下面的几种情况以增量的方式返回相应的数据:
Case1指的是所要复制的节点在副本数据中不存在,也不属于客户端直接请求的节点,所以是属于依赖节点,要把该节点返回给客户端,并标记为依赖节点.
Case2指的是所要复制的节点是客户端直接请求的操作节点,所以将该节点标记为工作节点,并把该节点返回给客户端,显示为工作节点.
Case3指的是该节点已经存在客户端副本中,客户端没有直接请求作为工作节点,所以不需要返回任何数据.
Case4指的是客户端请求的工作节点在副本中已经存在,是作为依赖节点存在的,只需要将依赖节点修改为工作节点即可,不需要返回该节点的数据.
3.4 客户端与服务器端的交互
如图3所示,服务器端会同时处理很多个客户端请求,用RBCj和SBCj分别标识对应的客户端操作队列,SBSj和RBSj分别对应其它中心服务端的操作,从客户端接收的操作需保存在服务器端的对应缓存队列RBCj中,即将发送给客户端的操作,存储在缓存队列SBCj中,当对应的用户进入系统或离线状态时,服务器端只需要创建或者删除该缓冲队列SBCj和RBCj即可,这样的设计在服务器端会有很好的扩展性,又能节省不必要的资源.RBSj表示从其他服务器中心接收的数据缓存队列,SBSj表示该服务中心发送到其他服务器的缓存队列,每个服务器都能将更新的操作队列主动发送到对应的客户端或其他站点的中心服务器.

图3 系统的分布式结构图
3.5 服务器端对并发操作的检测
因果序列要求:我们的方法要符合正确的因果关系,根据之前的协同编辑理论,在云环境下我们假设每个中心服务器在发送给其他服务器或者客户端的时候都是按照相同的因果顺序.
算法3.nwayMerge(sqlist)
1.L ←sqlist;N ← length(L)
2.WhileN > 1 do
3. N,M ← N/2,N/2
4.For(i=0;i 5. L[ i ] ←extractConcurrentOperations(L[ i ],L[ N + i ]) 6.End while N=1 7.extractConcurrentOperations(L[ i ],L[ 1 ]) 8.End 在算法3的目的是:在服务器端,有规律的对接收到的N路序列进行合并,这些序列是上下文有序的,也就是满足相同的因果关系的N个操作序列.例如:有5个客户端加入了协同会话中,在服务器端就会有5个缓存队列来接受客户端提交的操作,假如是sqlist[0],sqlist[1],sqlist[2],sqlist[3],sqlist[4],首先对sqlist[0],sqlist[3]进行并发操作检查,再对sqlist[1],sqlist[4],最后再将结果与sqlist[2]进行合并检测. CNi表示操作O对应的客户端副本节点,这里用代码节点的标识符来表示; Oi指的是代码节点CNi对应的操作,缓冲队列中的操作都是按照操作的因果关系存储的; T表示操作O在本地编辑完成时间; T′表示操作O对应的节点CN在最近一次与服务器端完成同步的时间; 这里的T和T′都是指中心服务器的物理时间,在过去的端对端架构或者一些集中式协同系统中,很多都是采用二维时间戳来表示操作的执行时间,这在共享数据是完全复制的状态下是可以适用的,但是在部分复制的情况下,每个站点的数据状态不一致,采用统一的物理时间在全局中比较容易计算. 对于客户端,缓冲序列RQj中任意一个操作序列P中,代码节点O对应的产生时间O.T必然大于O.T′,因为节点O在本地产生时,是与服务器端进行同步完成之后产生的,而在O.T之后产生的新操作必定还没有经过中心服务器的主副本上进行同步的,或者是即将提交到服务器的操作.服务器端上的RBCj队列表示从客户端接收的操作,根据操作序列的时间大小和副本节点是否相同得出操作之间的并发关系,对于任意两个操作Oi和Oj,可以得出以下两个结论: 如果Oi.T 如果Oi.T >Oj.T′ 且Oi.CN=Oj.CN,得出Oi || Oj,Oi并发于Oj ; 算法4.extractConcurrentOperations(L[i],L[N+i]) 1.CO[ ] ← Concurrent Operation Set 2.WhileL[ i ] or L[N+i]do 3.Forall Oi,Oj ∈L[ i ],L[N+i] do 4.ifOi.T >Oj.T′ 5. HandlerOT(Oi,Oj); 6.elsereturn 0; 7.End if 这个函数的目的是:依次扫描RBCj 和RBSj,集中的找出提交到服务器端的每组并发操作序列,其中这些并发操作包括针对一个节点的操作和针对不同节点的操作,如果判断的是并发操作,就用HandlerOT函数也就是操作转换来解决(下节会有详细说明).同一个客户端的一个操作队列中,操作之间的关系是因果关系.如果并发操作对应的节点之间没有依赖或者间接依赖的关系,可以不用考虑. 根据定义,如果服务器端缓存区接收到一个操作O,与其并发的操作,就是执行完成时间T大于 O.T′,且对应的客户端不相同,其中O.T′就是O对应的副本节点最近一次与服务器同步结束的时间. 首先需要满足一下几个性质:1.客户端在任何时刻都能加入或离开一个合作对话.2.客户端能够独立的决定什么时候与服务器端进行同步.3.服务器也能单独决定什么时候处理从客户端接收的操作.4.有高的并发性,不同的客户端能够对共享文档的任一部分进行编辑,能够避免过多的交互延迟.5.使用redis缓存队列来做消息处理和任务调度.Redis缓存可以是基于内存的,可以对数据进行快速访问,不会产生过多的延迟,并且由于缓存文件可以重复利用,还可以减少带宽,降低网络负荷.另外,可以对缓存队列中的每项操作设置过期时间,过期后可以自动对数据进行删除. 算法5.Control Procedure at Client 1.Initialization: 2. Tj=[ ];LHBj=[ ];RQj=[ ]; 3. RequestPartialNode( ); 4. Get partial code nodes replica R from Server 5.Thread1: 6. executeOj at local partial code nodes 7. append Ojinto Tj 8.LHBj=ERMerge(O,LHBj ); 9.LHBj=[ ];// only if LHBjis received by the server 10.Thread2: 11.casesq: 12. receive sequence sq in RQj from Server 13. sq=RQj;RQj [ ]; 14.Forall O∈sq do 15.ifO is at open area 16. execute O at R directly 17.elseexecute O to update R 18. save( ); 19.caseFetch: 20. Send local buffer operation LHBj to server directly 21. End if 客户端的算法要更加简单高效.客户端连接到系统之后,先请求所需要的数据节点,系统会进行一些初始化的操作,为客户端建立必要的数据结构.客户端的线程主要是处理本地操作和远程并发操作,这两个线程是并行执行的,可以有效地利用多核处理器,提高了运行效率. 在算法5中,新加入的客户端首先应通过DetectTargetedNode()请求所需要的节点,本地产生的操作会立即执行,并存储在Tj操作集合中,LHB操作缓冲区存放待发送到服务器端的操作,ERMerge( )函数的作用是使操作序列满足“effect relation”关系,这样能够加快操作转换的效率.RQj队列存放服务器发送到客户端的操作.线程一负责本地操作的执行,执行完本地操作,还需要把执行过的操作先存入缓冲区.线程二负责接收从服务器端发送过来的操作,并执行这些操作,因为这些操作是在本地站点执行过的操作或是有并发关系的远程操作,经过与服务器端的同步,会与远处站点的编辑操作进行一系列的操作转换,返回到客户端,用来更新本地站点的副本节点.当客户端接收到Fetch指令时,客户端向服务器发送本地执行过的操作LHB. 算法6.Control Procedure on Serveri 1.Initialization: 2. RBCj=[ ];SBCj=[ ];RBSj=[ ];SBSj=[ ]; 3.Thread1: 4. For all sqjin RBCj,RBSj 5.Ifsqjis null 6. sendFetch to clientjor server j 7. Get operation sequence sq from ClientjorServerj 8. SQj=ERMerge(sq,RBCj,RBSj); 9.ElseSQj=ERMerge(sq,RBCj,RBSj); 10.Forall Oi∈SQjdo 11. CO[ ]=extractConcurrentOperations(Oi,SQj); 12.Thread2: 13.Forall Oiof COido 14.ifOiis at open area,Oiis executed directly 15.elseTj′=HandlerOT(Oi) 16. First execute Tj′ on primary copy 17. then add Tj′ into SBCj,SBSj 18. sendSBCj,SBSjto Clientjor Serverj 19. End if 服务器端的四个操作队列都是先经过操作转换,再在中心服务器端的主副本上同步执行之后的操作.线程1的作用主要是将从客户端或服务器端接收到的远程操作,按照操作之间的依赖关系和因果关系重新排列,这里不是本文研究的重点.然后再将接收到的操作分类,也就是找出客户端操作所对应的的并发操作.线程2的任务主要是对远程并发操作进行操作转换,再将操作转换结果应用到中心服务器的主副本上,这样的目的是为了让所有的客户和服务器都能共享相同的数据状态,也能保证代码数据的完整性.然后再将操作转换之后的结果发送到对应客户端和远处服务器端. Fan提出的共享锁中,如果编辑区域是在一个开放域中,就不会发生语义冲突;如果并发操作有共同的依赖节点,也不会发生语义冲突;冲突的情况只会发生在并发编辑同一个节点,或者是发生在有依赖关系或者间接依赖的节点上. 所以,在服务器端首先要做的是,当检测到对应站点的并发操作之后,就要再次确认并发操作所对应的节点之间的动态依赖关系. 如果是并发对有依赖关系的节点编辑时,需要用编辑器检测或者是发送消息给客户端,再次判断操作的关系,其中会出现的三种关系是兼容关系,排斥关系或者依赖关系. 这样的方法能阻止语义冲突的发生,还能保证程序员的连续工作,即使依赖图是动态改变的,这中间是没有中断的. 算法7.HandlerOT(Oi) 1.Forall S∈Oido //对Oi每组并发操作进行分析 2.ifSi.rootNode=Sj.rootNode//有共同的依赖节点 3.Oiis directly executed 4.elseifSiandSjhas dependent relation 5. ConDetect(Si,Sj)//判断依赖关系和冲突检测 6.elseSi.ID=Sj.ID//指的是同一个节点 7. Awareness solution(Si,Sj) 8.endif 该函数的作用是对并发操作分类处理,并发操作都发生在开放域,则不会发生语义冲突,这种情况是直接执行的,只需要维护每个站点代码节点的上下顺序一致就可以了,在这里,可以通过每个操作的全局标识符,通过比较标识符的大小来排序.如果并发操作所对应的节点,有依赖关系的话,就需要进行冲突检测,使用ConDetect()函数进行冲突消解(下文会有解释).如果并发操作是针对一个节点,就需要用下面的方法来解决. 如果是针对同一个节点的并发编辑,操作的类型会有插入,更新,删除和移动节点,根据人的编辑意识操作,采用操作转换对结果进行合并,这种方法可以有效解决冲突. 算法8.Awareness solution(Si,Sj) 1.receiveO1,O2 2.ifO1and O2are both creationsthen 3. keep two operates and highlight new result 4.elseifO1and O2are both updatethen 5. show two versions to client 6.elseifO1is update and O2is deletethen 7. delete this code node and show it 8.elseifO1is update and O2is movethen 9. move the updated version and highlight it 10.elseifO1and O2are both deletethen 11. delete and nothing needed 12.elseifO1is delete and O2is movethen 13. delete this code node and show it 14.elseO1and O2are move delete 15. create clones and highlight clones 16.endif 上面的算法展示了并发冲突发生在同一个节点上的时候,是如何解决的.如果是两个客户端在相同的节点下并发创建新的节点,根据前面的许可审查条件,在开放域中创建节点不会产生语义冲突,这种情况应该考虑节点之间的前后顺序即可,可以根据客户端的标识符或产生的节点标识符排序. 算法9.ConDetect(Si,Sj) 1.Oi ←Si,Oj ← Sj 2.WhileOj.targetNode—>Oi.targetNode do 3.IfOj and Oi both are Deletethen 4.Oj.targetNodeand Oi.targetNode both are Delete 5.ElseIfOj is Delete and Oi is Updatethen 6.Oj.targetNode is Delete and Oi.targetNode is Update 7.ElseIfOj is Delete and Oi is Movethen 8.Oj.targetNode is Delete and Oi.targetNode is Move 9.ElseIfOj is Update and Oi is Deletethen 10. Oj.targetNode and Oi.targetNodeboth areDelete 11.ElseIfOj is Update and Oi is Updatethen 12. Oj.targetNode and Oi.targetNode both are Update and show it 13.ElseIfOj is Update and Oi is Movethen 14. Oj.targetNode is Update and Oi.targetNode is Move 15.ElseIfOj is Move and Oi is Deletethen 16. Oj.targetNode and Oi.targetNode both are Delete 17.ElseIfOj is Move and Oi is Updatethen 18. Oj.targetNode is Moveand Oi.targetNode is Update 19.ElseOj is Move and Oi is Movethen 20. Oj.targetNodeand Oi.targetNode are Move 21.End 在服务器端对并发操作的检测之后,如果并发操作之间有间接依赖或直接依赖的关系,则会调用算法9.根据共享锁的特点和实际编程中的效果,假如:Oi 对应的节点是A,Oj对应的节点是B,B依赖于A,A的操作直接决定着B是否会有语义冲突,A和B的操作可以是删除(Delete),更新(Update)和移动(Move),如果A是删除,那么B无论做什么操作,都是无效的,所以A如果是删除操作的话,冲突消解的办法只能是把A和B节点同时删除.如果A节点是更新或移动操作,B节点是删除操作,B节点的操作对A节点没有影响,所以这两个操作是兼容的.如果A和B两个节点都是更新操作,则会想对应的客户端发送消息机制,可以避免意义冲突的发生.如果A是移动操作,B是更新操作,则不会发生语义冲突,这两个操作是兼容的.如果A节点更新,B节点移动,这两个操作也是兼容的.如果A和B节点(在合理的范围内,A节点一直在B节点之前)同时发生移动的操作的话,这两个操作也是兼容的. 为了证明算法的合理性,设计了一个基于Vaadin框架的浏览器端的java代码编辑器(CloudCode),利用Web端软件良好的跨平台性,选择Java作为目标语言,Vaadin作为主要框架,选择Vaadin的原因是:它所运行的代码都是在服务器端的,编译速度快,能够支持所有的Java库,而且开发效率高,只需要Java语言即可,不需要JavaScript和XML进行配置.使用基于webSocket的协议进行信息传输. 客户端使用Ace编辑器,Ace只一种开源的,基于浏览器端的代码编辑器,能够支持多种语言,且具有强大的功能.在服务器端安装JDK作为分析源代码的工具. 在服务器端,JDK作为分析代码的工具,该应用程序的前端包括GUI图形界面和代码编辑器.并且使用多线程机制,可以同时响应和处理多个客户端请求. 图4 前端界面的编辑布局 如图4是一个客户端进行编辑交互的界面,客户端的控制按钮都是基于JavaScript的Ace editor编辑器实现基本功能.进入该界面的客户端需要先点击request请求操作,加载一部分数据到本地,再返回到CloudEditer编辑器界面进行编辑,根据用户所编辑的位置信息进行监听,通过接口ExamineArea( )进行判断用户所编辑的操作是在代码域或开放域中,如果是在开放域,就不会与其他客户端发生冲突,就不需要与其他并发编辑的客户端进行意识交互;如果是对代码节点进行编辑,就会通过服务器进行检测,是否与其他客户端所编辑的节点是否是并发的,如果是并发操作,就会HandlerOT进行操作转换. 图5 编辑时的信息交互模型图 系统界面左边可以看到在线人数,同时显示与本地客户端发生并发编辑的客户端的编辑信息,可以选择在线人员进行交互.如果与并发编辑的客户端共同编辑同一个节点或者是有依赖关系节点时,会出现一个消息提示框,触发Awareness solution()和ExaminateCurrent()接口,进行判断操作之间的关系,或者是给其他客户端发送意识消息,便于能得到更好的结果,如图5所示. 合理性:整个程序的运行时间效率分为客户端效率和服务器端效率.服务器端的性能表现在两个方面:处理客户端请求的时间:a)N路合并的时间和查找并发操作的时间,b)执行并发操作的时间.客户端性能也包括两个方面:请求目标代码节点的时间,执行本地操作的时间和RQj中远程操作的时间.从以上分析可以得出:整个程序的最终性能取决于客户端提交的操作数量和代码总量. 如果是采用全部复制的方法,随着在线的协同编辑的用户的增多,代码量的不断增加,传输效率会随着代码量的增加而减少,如果加入一个新用户,如果在带宽流量不好的情况下,会严重阻碍协同的效率.客户端的算法是用JavaScript来实现的,我们假设在带宽充足的情况下,采用Socket协议进行传输,分析协同编辑完成的效率,整个效率跟每个客户端的运行效率都有关系.但是如果采用部分复制的方法,每个新加入的客户端不会随着时间的变化出现效率的降低,因为请求加载数据量不会逐渐增大.在线人数多的时候,效果会比较明显. 本文提出了基于云端的CloudCode编程系统,在算法方面,采用了改进之后的TIPs集中式架构,运用部分复制提高了系统效率,最重要的是采用共享锁的思想,使用中心服务器来检测操作之间的复杂关系,检测是否会发生语义冲突,并阻止了语义冲突的发生,操作转换的结果更能符合用户要求. 在系统架构方面,还可以进行很多改进,可以将软件应用程序设计为微服务架构的形式.在协同编程中,如果要求返回到原来的版本,对一系列连续的操作进行撤销的话,如何高效的进行Undo-Redo操作,对于项目中的一系列文件如何进行协同处理,如何提高用户的体验度,在数据库设计方面,如何提高检索效率,这些都是以后研究的方向.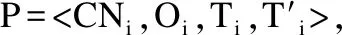
3.6 客户端的算法设计
3.7 服务器端的算法设计
3.8 解决每个站点操作的并发冲突
4 CloudCode原型系统
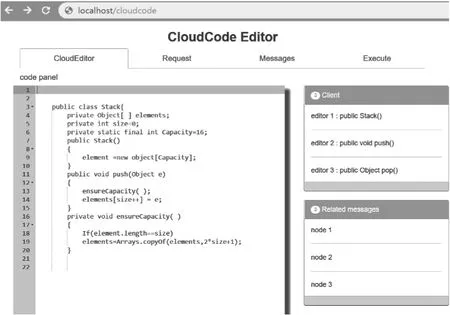

5 实验分析
5.1 复杂度分析
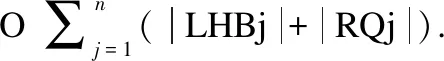
5.2 乐观复制中的全复制和部分复制的对比分析
6 总结与展望
