基于多普勒雷达的发音动作检测与命令词识别
2020-05-09吴鹏飞凌震华
吴鹏飞,凌震华
(中国科学技术大学 语音与语言信息处理国家工程实验室,合肥 230027)
1 引 言
语音是从肺部呼出的气流通过声门、声道等各种器官作用而产生的,人类在发音时需要调动多个发音器官,如软腭、舌、牙齿、唇等[1].发音器官在发音过程中的位置和运动称作发音动作特征(articulatory feature).发音动作特征相对于语音的声学特征具有变化缓慢、可解释性强、不易受声学噪声影响等优点[2],因此已有研究人员将发音动作特征应用到语音识别和语音合成方法的研究中,以提高噪声环境下的识别准确率[3]、实现静默语音接口[4]和增强合成语音的自然度与灵活可控性[5]等.
发音动作特征可以用多种技术手段采集,例如X射线微束影像[6]、磁共振成像[7]、图像采集外部发音器官运动[8]、表面肌电[9]及电磁发音仪[10]等.这些发音动作特征采集手段虽然能有效检测发音器官运动,但往往存在侵入人体、非便携、成本高等问题.近年来,基于微波雷达的面部姿态[11]和舌部动作识别[12]方法被提出,这些方法利用微波雷达的多普勒特性检测面部肌肉的微小动作,在简单的面部动作和舌部动作识别任务中取得了良好的性能.微波雷达采集方法具有无侵入性、成本低等优点,且适用静默语音场景,因此本文使用多普勒微波雷达采集发音动作,研究基于所采集动作的命令词识别方法.相对于先前的简单舌部动作检测任务[12],命令词识别中发音动作特征的组合模式更加复杂;相对于传统语音识别任务,本文所研究方法不依赖声学特征,仅使用多普勒微波雷达采集的发音动作特征来完成命令词的识别,这对于高噪声、隐私保密等场景中的语音控制具有应用价值.
本文首先设计实现了一个基于多普勒微波雷达的发音动作采集系统,基于该系统采集了2个说话人的发音动作信息以构建命令词识别数据库.利用所采集的微波雷达数据,本文研究了基于支持向量机和基于卷积神经网络的命令词识别算法.实验结果显示,本文设计的数据采集系统可以有效记录命令词发音过程中的发音动作特征,本文提出的基于卷积神经网络的微波雷达数据分类方法可以取得90%以上的命令词识别准确率.该方法可用于静默语音控制,在一些高噪声、或者无法发声的环境下实现通信和语音控制.
2 数据采集系统
2.1 原理简介
多普勒微波雷达是基于多普勒效应设计的.所谓多普勒效应,即物体相对于波源移动时观察到的反射波的频率与发射波的发射频率之间会因物体相对波源的运动方向不同而产生差异.若目标靠近波源,则接收频率大于发射频率;反之,若目标远离波源,则接收频率小于发射频率.该雷达基于此效应设计,包含一个发射器和一个接收器,通过计算发射器和接收器之间的频率差即可得到所检测动作的运动速度.现假设fr为接收波的频率,ft为发射波的频率,v为物体的运动速度,c为光速,则fr与ft的关系可表示为式(1).
(1)
频率偏移fd=fr-ft,当v≪c时,有fd=2vft/c.由于人在发音时脸部肌肉运动速度有限,因此这个频率一般在10Hz以下[12].
本文采用的雷达为24GHz的K波段多普勒雷达探测器K-LC2,使用连续波模式,解调方式为正交解调,解调输出为I、Q双通道输出,其中I通道为解调后的真实的频移信号,Q通道为I通道相移90°.后得出的信号,发射信号与接收信号之间的相位差可通过式(2)得出[12].
(2)
其中λ为波长,Ø0为初始相位.由该式可知θ可以度量包括运动速度和方向在内的目标运动信息.
已有工作[12]表明该微波雷达可以有效检测到舌部来回运动、舌位保持等动作带来的微小面部肌肉运动.另一方面,人在发音时面部、舌部、下颚等多个部位同样会产生微小的肌肉动作,并且相同的发音时这些动作具有类似的模式,本文旨在研究基于该微波雷达数据检测发音动作并进行命令词识别的方法.
2.2 系统框架
本文设计实现的数据采集系统框图如图1所示.该系统平行采集两路信号:一路是语音信号,语音通过一个USB接口的电容麦克风录制;另一路包括三个雷达的输出数据,共6个通道,雷达输出数据经处理后由单片机通过串口发送至PC上.

图1 数据采集系统框图Fig.1 Flow chat of data acquisition system
2.3 硬件实现
本文设计了一个可佩戴的头盔用于放置微波雷达.为了减少对于发音人正常朗读的影响,要求设备体积不能太大.因此本文使用了三个K-LC2双通道24GHz微波雷达,该微波雷达具有体积小、抗噪性能强的优点.三个雷达分别定位于发音人的左、右脸颊和下巴处,用于检测发音时这些部位的动作.
雷达的输出信号是经解调的频移信号,该信号是一个交流小信号,在本文的应用场景内,其幅值范围为[-80 mv,80mv],这个特性决定它无法直接被单片机的片上ADC直接采集.首先,对于片上ADC来说,由于其采集范围为[0,3.3V],因此其无法采集交流信号;其次,信号幅度小容易导致无法采集到信号的有用成分.因此,需要设置相应的电压放大、抬升电路,雷达输出信号经过本文设计的电压放大、抬升电路后,其电压范围为[350mv,1.95V],适合单片机上ADC的信号采集.最后,单片机将采样的数据经串口发送至PC端用于分析处理.
2.4 软件实现
由图1可知,语音和雷达数据最终被传入PC上,故需要在PC端设计相应的处理、接收的上位机程序.本文中,语音数据使用ffmpeg工具录制,串口数据使用现有的串口函数库接收并写入文件中.本文设计的上位机程序共有两个线程,其中一个线程负责启动ffmpeg用以录制语音,启动完成后,该线程即结束;另一个线程负责与下位机的通信和串口数据的读取与保存.两个线程协同工作,从而保证语音数据与雷达数据在时间上对齐,以便后续进行命令词的切分.
3 基于雷达数据的命令词识别
3.1 数据库构建
已有的基于发音动作检测的语音识别方法研究通常从孤立词或孤立音素的识别入手.例如,在文献[13]中作者使用了含有9个词语和13个音素的语料集合来研究基于电磁发音仪的静默语音识别方法;类似地,文献[14]中作者为研究声道的电磁传输与反射特性对音素识别的影响,构建了一个含有25个音素的微波信号数据库.参考上述工作,本文利用第2节中介绍的数据采集系统,构建了一个含有两个说话人的命令词识别数据库.该数据库使用一个含有10个命令词的词表,如表1所示.每个说话人对词表进行10遍朗读,每遍朗读中这10个词之间的顺序随机打乱,同时保证前后两个词不是相同的词,以减少录音中的语序影响.

表1 本文使用的10个命令词词表Table 1 Ten command words in this paper
本文中的数据库是在一个专业的隔音密闭录音室完成的.录制时说话人佩戴好头盔,朗读屏幕上显示的命令词,在其前方安置电容麦克风.为减少其他操作给说话人带来的干扰,屏幕上命令词的更换操作由录音室外的控制人进行.在录音过程中,说话人被要求尽量不要有其余额外的脸部动作以减少干扰,同时在每个命令词的前后,留有1秒左右的静音段以方便后续处理.
在数据采集过程中,雷达数据采样率设为500Hz.为便于切分得到每个命令词的起止位置,该数据库还同步录制了命令词的语音音频,音频采样率为48kHz.
3.2 数据预处理
对每位发音人,录音得到的原始雷达数据是经ADC量化的、含有100个命令词的整段数据.为满足后续实验需要,本文对原始雷达数据进行了数据预处理,包括真实电压值转换、去均值、滤波、切分、降采样等.
串口接收到的数据是经片上的12比特ADC量化的数字量化等级值,故这个值在0-4095之间,根据式(3)可将其转换为真实的电压值.
V=ADC_value·3.3/4096
(3)
其中ADC_value为串口直接接收的数据,V为被转换的真实电压值.以上处理后的电压往往含有较大的直流成分,因此本文利用全局均值进行了去均值操作.此外,采集到的数据含有一定噪声.针对这个问题,本文设计了一个截止频率为10Hz的20阶数字低通滤波器用于滤除噪声.
本文在命令词的录音过程中采取的是单个说话人连续录制的方式,因此对单个说话人来说,得到的雷达数据是100个命令词及它们之间的静音段按时间先后排列组成的.为了开展命令词识别方法研究,需要将这100个命令词从连续的数据流中切分出来.为此,本文在数据库构建过程中同步录制了命令词的语音数据,通过对语音数据的VAD处理[15]可以得到每个命令词的起止时刻.由于雷达数据和语音数据是同步录制的,且发音动作可能先于语音产生而晚于语音结束,我们对以上VAD边界前后各延伸0.5秒后得到每个命令词的雷达数据起止位置,并依据此位置进行数据切分.考虑到发音动作特征的缓变特性,本文对切分后的命令词微波雷达数据进行8倍下采样到62.5Hz以减少数据量.
至此,经过以上预处理步骤后,一个具有两个说话人、每个说话人100个命令词数据段的微波雷达数据库构建完成.
3.3 特征选择
本文使用使用两种特征进行基于雷达数据的命令词识别:
1)帧级的雷达数据;
2)从帧级雷达数据中提出的命令词段统计参数,本文参考已有工作[16]使用的波形统计参数如表2所示.

表2 本文使用的波形统计参数Table 2 Waveform statistical parameters
这两种特征各有其优点,直接使用帧级的雷达数据可以最大化地保留原始信息,但是在分类时需要考虑由于发音速度差异带来的数据不等长问题;使用从波形中提取的统计参数可以无需考虑数据长度不等的问题,但是会带来一定的信息损失.
3.4 分类模型
本文研究了两种分类方法用于命令词的识别,即支持向量机方法和卷积神经网络[17]方法,下面将分别进行介绍.
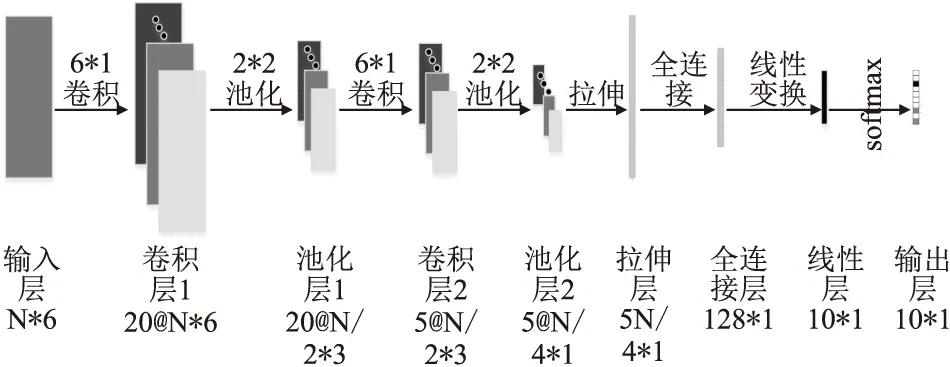
图2 CNN模型结构示意图Fig.2 CNN model struct
3.4.1 PCA-LDA-SVM分类模型
我们使用雷达数据的段级统计参数构建支持向量机模型.支持向量机是一种按监督学习方式对数据进行二元分类的广义线性分类器,其可通过引入核方法进行非线性分类.它的目的是寻找一个超平面来对样本集进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解.其输入为每个样本的多维特征,输出为该样本对应的类别.支持向量机是针对二分类任务设计的,对多分类任务要进行专门的推广.本文使用“一对多余(OVR)”策略[18]将其推广至10分类任务,核函数使用径向基函数.
考虑到特征维数有60维而样本数目较少,故在使用支持向量机进行分类时,首先对特征使用主成分分析(Principle Component Analysis,PCA)和线性判别分析(Linear Discriminat Analysis,LDA)进行降维处理.经PCA和LDA降维后,使用SVM分类不会产生过拟合,且在相对低维的空间进行分类效果会更好.另外,考虑到使用原始波形数据维度太高,降维后信息损失过于严重,故在使用SVM方法时,未使用原始数据作为特征.
3.4.2 CNN分类模型
卷积神经网络(Convolutional Neural Network,CNN)是一类包含卷积计算且具有深度结构的神经网络,其具有平移不变性等多个优点,对图片、语音等时序数据具有很好的学习能力.在本文的任务中,由于CNN具有平移不变性,在使用帧级特征时,可以应对由于语速、发音起止位置等因素的不一致带来的影响.本文中使用的CNN结构如图2所示,其中“@”前数字表示该层特征通道的数目,若某层无该符号,则代表该层只有1个通道.该结构中,池化时选择最大池化,激活函数使用修正线性单元(Rectified Linear Uint,ReLU)[19].
在使用CNN进行分类时,本文对比使用了帧级雷达数据和段级统计参数两种特征,若使用原始波形作为输入,则输入层中的N是所有样本的最大时间长度,其余样本补零为该长度;若使用统计参数作为输入,则各样本的输入长度相等,即N为10.
4 实验与结果
4.1 实验配置
由于数据库中样本数目有限,实验使用5-折交叉验证的方法进行训练集和测试集的划分,即对每个说话人的100个雷达数据,随机划分为5组,保证这5组中样本类别是均衡的(即每个命令词都有2个样本).实验时每次从这5组中取一组作为测试集,剩余4组作为训练集,如此重复5次直至每一组都曾被挑选作为测试集,最后将5次测试结果的均值作为最终的评估结果.
实验中构建了以下三个模型用于对比分析:
1)SVM_seg:使用段级的统计参数作为特征.首先将各样本的6个通道的10维统计参数拼接成一个60维特征向量,然后使用PCA与LDA进行降维,经实验调试后,先使用PCA将该特征向量将至20维,然后继续使用LDA将其降维至8维,最后使用SVM对降维后向量进行分类;
2)CNN_seg:使用段级统计参数作为特征输入,但输入与SVM_seg不同,此处将每个通道的10维段级统计参数组合成10*6的矩阵;
3)CNN_frm:使用帧级的雷达数据作为特征输入.首先计算所有样本的最大长度N,然后其余样本补至长度N,输入即为N*6大小的矩阵.
基于上述三个模型,每个模型均进行单话者建模、多话者建模实验.其中单话者建模指的是训练集和测试集均使用单个说话人的数据,每个说话人分开进行实验;而多话者建模指的是训练集和测试集中同时含有两个说话人的训练数据.使用5-折交叉验证进行实验,每个模型、每种实验方式均重复1000次以获得一个平均结果.
4.2 实验结果与分析
4.2.1 单话者建模命令词识别结果
表3为在单话者建模实验中,两个说话人使用各模型的分类准确率情况.其结果显示,在单话者建模实验中,CNN_seg模型的结果最差,SVM_seg其次,而CNN_frm模型的结果最好,对两个说话人的命令词识别准确率都在90%以上.CNN_seg的识别结果不尽如人意,相对于CNN_frm,此模型只是使用的输入数据不同,说明在此模型配置下,数据之间的模式不再那么容易区分,其原因可能是在提取统计参数时丢失了部分与命令词标签相关的信息;SVM_seg的识别准确率在80%左右,这个结果虽比CNN_frm稍差,但是也表明本文命令词数据库中的数据具备一定模式,使用传统的SVM方法也可以取得一定性能;CNN_frm模型的结果最好,说明CNN可以充分利用帧级特征的优势,从而达到最优的分类效果.
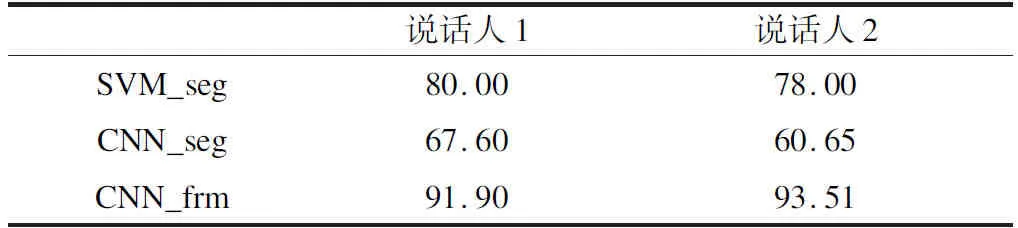
表3 单话者建模命令词识别准确率(%)Table 3 Recognition accuracy of single-speaker modeling(%)
图3是说话人1各模型某次测试结果对应的归一化混淆矩阵图,在混淆矩阵图中,纵向表示真实标签,横向表示预测标签,图中数字为预测准确率.首先,三个模型都具有较明显的对角趋势,但混淆程度各有不同,CNN_frm模型的结果近乎对角阵,而CNN_seg模型的结果比较分散.其次,对比CNN_seg与SVM_seg两个模型,可以看出虽然两者都有一定的误分类结果,但是CNN_seg在混淆矩阵图上更为分散,以“上升”与“左边”两个标签为例,这两个标签在测试过程中都出现了4个不同的预测结果;SVM_seg系统则不然,其很大一部分误分类都是被误分类为“右方”.这两个模型的原始输入相同,但是后者首先进行了PCA降维去除了40维之多的冗余信息,然后使用LDA再次降维至8维,使得其结果具有更小的混淆度.

图3 各模型测试结果混淆矩阵图Fig.3 Confusion matrix of three models
对比CNN_frm与CNN_seg两个模型,可以明显地看出使用帧级的雷达数据作为输入的模型可以有效地避免上述问题,且能达到比传统SVM方法更好的结果.前者的输入是段级的统计参数,这些统计参数在一定程度上丢失了原始雷达数据的时序性与部分模式信息.
4.2.2 多话者建模命令词识别结果
多话者建模实验的结果如图4所示.对比表3和图4可见在多话者建模实验中,SVM的性能有较明显地下降,而使用CNN的模型仍保持和单话者建模实验中相近的水平,从而再次证明CNN模型可以较好胜任本文的命令词识别任务.
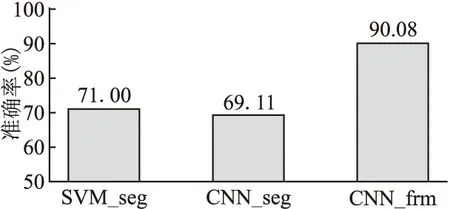
图4 多话者建模命令词识别结果Fig.4 Recognition accuracy of multi-speaker modeling
SVM性能下降的一个可能原因是两个说人在命令词数据模式上具有较大的差别,SVM并没有足够的能力同时学习到两个说话人的发音动作特征.为验证这个猜想,本文设计了一个话者交叉的多人建模补充实验,该实验使用一个说话人的全部数据作为训练数据,另一个说话人的全部数据作为测试数据,仍使用前述的CNN_frm模型,结果显示测试集分类正确率仅为20%左右,此实验证明两个说话人的模式差异性较大.在多人建模实验中,虽然测试集和训练集都包含了相同的2个说话人,但是SVM模型的性能却由于两个说话人模式的差异性出现一定的下降;而CNN模型却几乎没有性能损失,可见CNN模型可以同时学习两个说话人各自的特征模式.
综合单话者建模实验与多话者建模实验结果,可以得出一个在本文任务中性能最佳的模型,即CNN_frm,该模型无论在单话者建模还是多话者建模任务中,都保持了90%以上的分类正确率.实验结果证明本文构建的发音动作检测系统确实能检测到发音相关的参数,而后续提出的基于CNN与帧级雷达数据的模型可以从中提取出与命令词相关的模式并很好地将它们进行分类.
5 结 论
本文构建了一个基于多普勒微波雷达的发音动作检测系统,并基于此系统录制了一个含有两个说话人共200个样本的命令词识别数据库.基于此数据库,设计了三个模型进行对比实验,通过对比实验得出了一个基于CNN和原始数据的命令词识别分类模型,该模型在命令词识别任务上可以达到90%以上的准确率.多话者建模实验的结果显示,不同人的发音动作数据模式之间差异较大,对于如SVM之类学习能力不够的传统方法,会严重影响其分类性能,而本文构建的CNN模型可以较好的同时学习到多个说话人的数据模式.后续计划包括录制更多说话人数据、研究话者无关的命令词识别方法等.
