生成对抗网络进行感知遮挡人脸还原的算法研究
2020-05-09魏赟,孙硕
魏 赟,孙 硕
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
随着深度学习的发展,带来了许多新的方法,在不断刷新人脸识别的准确率.但是这些超高的识别率是建立在特定的条件下,如果人脸图像由于围巾、眼镜、口罩等造成的遮挡而缺失部分信息,则他们的识别性能会大幅度降低.为了解决这一问题,人们尝试去恢复遮挡区域的像素,即人脸修复[1,2].但是考虑到遮挡的多样性和人脸细节的复杂性,这项任务变的非常具有挑战性.
近些年来,已经提出了各种方法来处理人脸图像的遮挡问题,对于在一定约束下得到的人脸图像[3-6].在文献[3]中,Park等人使用PCA来重建眼镜遮挡住的区域.Robust-PCA框架[4]用于利用非遮挡的面部图像集检测输入图像的遮挡遮罩,然后基于先验信息对遮挡的部分进行修复.在文献[5]中,周等人将马尔可夫随机场模型结合到被遮挡人脸图像的稀疏表示的计算中以保证重建误差的局部空间连续性.唐等人[6]提出了一个强大的基于Boltzmann机器的模型来处理遮挡和噪声.这种无监督模型使用乘法门控来诱导两个高斯的像素混合.这些方法都需要没有任何遮挡的面部图像以及与数据集相应的遮挡图像.很难收集具有大量图像和各种遮挡的这种数据集.因此,为了训练这样的方法,通常使用来自常用面部数据库的具有不同遮挡物(例如围巾、太阳镜)的人工生成的遮挡图像.
传统的图像修复方法[7,8]通过依赖于低级视觉特征,从本地信息中搜索可用的补丁来填补缺失区域,但是当在源图像中找不到匹配的补丁时它们可能会失败.文献[9]使用大型外部图像数据库来缓解这个问题,然而在处理对象图像(例如人脸图像)的修复任务中,每个部分可能是唯一的,所以它们也不能保证匹配补丁在语义上是有效的.
最近,Generative Adversarial Networks(GANs)[10]在各种机器学习任务中获得了可观的成果.由此衍生出的各种基于GAN的生成模型被用于解决人脸图像修复问题.Pathak等人[11]提出了一种编码器-解码器架构,名为Context Encoder,通过训练一个神经网络对上下文信息进行编码,来预测缺失区域的信息,但是当缺失区域具有任意形状时,它会产生模糊或不真实的信息.在文献[12]中,作者通过应用局部和全局两个鉴别器来促进缺失区域和整个图像的损失梯度的反向传播,并采用一个预先训练好的语义解析网络来整合学习视觉表示,以生成语义上合理且视觉上真实的内容.Yeh等人[13]提出了一种通过情境和感知损失(实际上是对抗性损失)训练DCGAN的方法,需要在测试时间内进行对此迭代,来找到潜在空间中损坏图像的最接近映射,来完成修复.然而,上述方法假设要修复的图像区域的位置/尺寸是预先已知的.这种假设可能不适用于实际的修复任务(或者它需要从输入图像中手动分割遮挡区域).
因此,本文提出了一种新的人脸图像还原算法,考虑到真实场景下的不同的遮挡(如眼镜、口罩等)大小和位置对图像还原的影响,它集成了深度生成模型和遮挡区域自动检测功能,以满足在实际场景图像中高质量修复任务.给定具有遮挡的面部图像,使用预先训练好的DCGAN作为遮挡检测与生成网络,通过最小化损失来学习最接近遮挡图像的编码,然后这种编码通过生成模型推断缺失的内容,考虑到遮挡的大小是未知的,这里加入新的损失函数,通过交替优化技术来定位遮挡.最后,生成的面部以遮挡感知的方式与遮挡面部整合,从而恢复无遮挡面部.引入语义感知网络,通过对恢复的人脸进行语义规范化,并帮助优化上面的遮挡检测与生成模型的训练过程,使生成的内容更加真实并且在视觉上保持一致性.
2 方 法
2.1 深度卷积生成对抗网络概述
通常GAN框架由生成模型G和判别模型D组成.生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器.判别器则需要对接收的图片进行真假判别.在整个过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗,最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像.
GAN的目标函数如下:
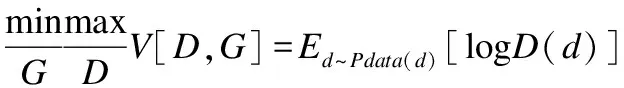
(1)
这里的G(z)表示G的输出,即生成的欺诈数据,z被看作是一个从先验分布P_Z中随机抽取的R_P向量.D(d)表示D的输出,即输入d为真实数据的概率.由于训练阶段的不稳定性和生成的图像的随机性,原来的GAN结构已经不适合图像的修复任务[13].Radford等人在文献[14]中改进了GAN的网络结构,以提高原GAN在训练期间的稳定性和结果的质量.与原来的GAN相比,DCGANs的改进主要有:
不采用任何池化层(Pooling Layer),在判别器D中,用带有步长(Stride)的卷积来代替池化层.
在G、D中均使用Batch Normalization帮助模型收敛.
在G中,激活函数除了最后一层都使用ReLU函数,而最后一层使用tanh函数.使用tanh函数的原因在于最后一层要输出图像,而图像的像素值是有一个取值范围的,如0~255.ReLU函数的输出可能会很大,而tanh函数的输出是在-1~1之间的,只要将tanh函数的输出加1再乘以127.5可以得到0~255的像素值.
在D中,激活函数都使用Leaky ReLU作为激活函数.
2.2 感知遮挡人脸还原模型
在本节中,将描述所提出的感知遮挡人脸还原模型.针对有遮挡人脸图像IOC∈Rm×n×3,本文提出的方法旨在事先不知道遮挡大小和位置的情况下恢复IOCC的像素.
本文将重建的图像输出表示为Irec∈Rm×n×3,其中包含有遮挡人脸图像IOCC中无遮挡区域的像素和遮挡区域的预测像素.
IrecM⊙IOCC+(1-M)⊙G(z)
(2)
G(z)是生成器,用于预测遮挡区域的像素输出.M是一个二值掩模图像,其中值为0的像素表示遮挡区域,值为1的像素表示无遮挡区域.
图1为感知遮挡人脸图像还原模型的流程图,主要步骤如下:
1)预训练DCGAN,通过最小化损失来学习最接近遮挡图像的编码;
2)引入新的损失函数,通过交替优化技术来定位遮挡;
3)将生成的面部与未遮挡部分进行融合.并通过语义感知网络来规范.
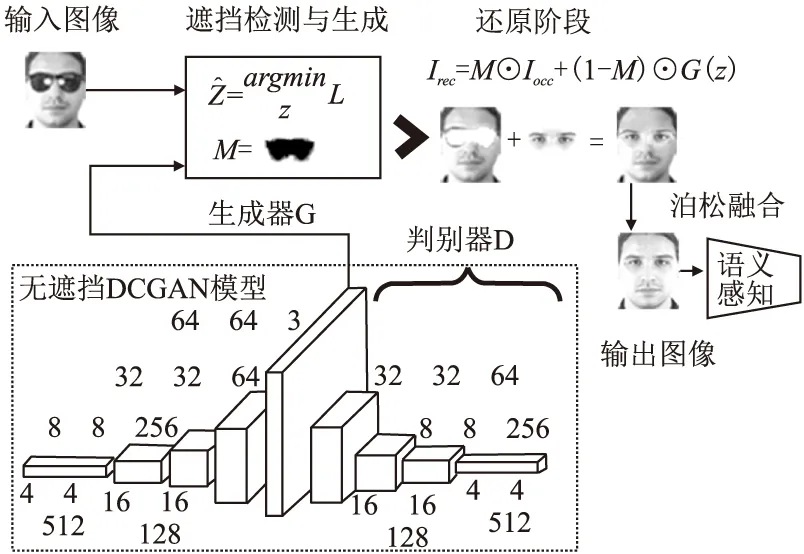
图1 本文方法的流程图Fig.1 Model flow chart
2.2.1 模型的大小与架构
本文的模型基于预训练的DCGAN,生成器和辨别器的网络结构互为逆操作,总共有8个卷积层,图片尺寸和层深度变化如表1所示,生成器的所有转置卷积运算都使用5×5大小的卷积核,步长为2,其层深度从512逐渐降到3,此处的3代表RGB彩色图像的3个通道,最终生成64×64大小的图片.
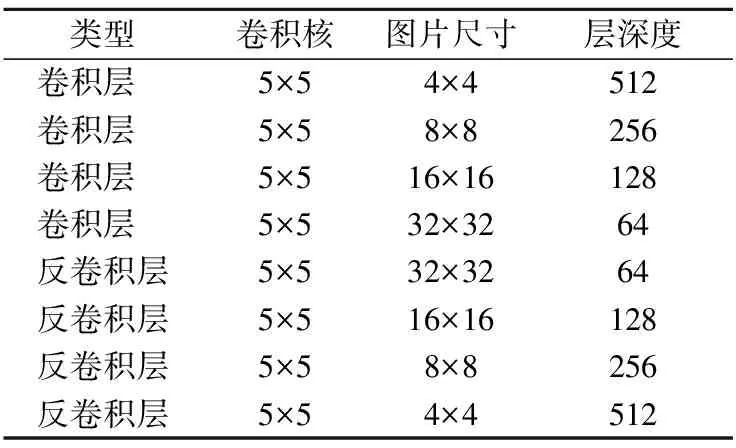
表1 模型的体系结构Table 1 Architecture of the model
2.2.2 遮挡检测与生成
根据图1所示,首先使用预训练的DCGANs来定位遮挡并生成对应的面部图像,这需要最小化损失来自动学习和推导输入向z∈Rp量和二值掩模M.
学习最佳输入z
引入了[13]中的损失函数:
(3)
该损失函数有两部分组成:第一项上下文损失(Contextual Loss)LC和第二项先验损失(Prior Loss)Lp.
上下文损失表示生成图像与IOCC图像中的无遮挡区域的差异,这里直接设置W等于M.
先验损失是指一类基于高层次图像特征表示而非像素级差异的损失.在GANs中,鉴别器D被训练来区分生成的图像和真实的图像,因此选择DCGAN中的鉴别器损失来作为先验损失,这里是平衡两种损失的参数.z被更新来欺骗D,并使相应生成的图像更加真实.
考虑到遮挡的大小和位置是未知的,加入新的损失函数:
(4)
其中Xi,j表示掩模M的每个像素值,R和C表示行和列中的像素数,通过计算每个像素与它的周围像素的相似度,来生成平滑的掩膜M.
通过交替优化技术来定位遮挡,并在随后的迭代训练中将遮挡检测信息传播给生成网络中,使其专注于生成遮挡区域而不是整个面部.
整个损失函数的形式为:
L=Lc+λ1Lp+λ2LO
(5)
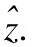
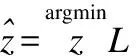
(6)
推导遮挡掩模M
为了自动检测出图像中的遮挡区域并生成掩模,引入一个剩余函数ρ(e)[14]:
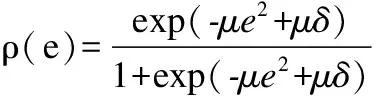
(7)
其中M(i,j)表示二值掩模矩阵,矩阵e表示输入图像IOCC和重建图像Irec的像素差.这里如果e较大,则ρ(e)的结果近似于0,如果e较小,则ρ(e)的结果近似于1.相应的可以得到二值掩模矩阵M.
2.2.3 算法流程
根据上述推导细节,遮挡检测与生成过程总结如下:
输入:训练好的DCGANs,IOCC,初始化M,z
输出:M和G(z)
for迭代次数do
随机抽取一个100维度的输入向量z;
哪有什么星星,天阴着呢,范青青就是在找借口和他约会,他们出去吃了夜市,范青青那晚特别兴奋,眉眼之中写满快乐,和之前的范青青有点儿不一样。田铭的心也跟着陌生地愉悦起来。
计算整个损失项L;
使用Adam梯度下降法更新z;
将z的值限制在[-1,1];
使用随机梯度下降法更新M;
对M进行标准化到[0,1];
retrunM、z
将学习到的最优z传给G,来生成G(z)
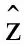
2.2.4 人脸图像还原
尽管能够很好的从被遮挡的面部恢复人脸结构信息(例如眼睛、嘴和他们的空间位置),但上面介绍的模型仅考虑无遮挡人脸图像与恢复后的人脸图像之间损失的最小化.假设输入人脸图像的下半部分被遮挡时,仅利用上面的信息,很难确定下面实际是什么样子,也就是说,对于人脸图像的遮挡区域存在多种合理的外观表现,如果强制模型完全适合每个像素的值,则人脸图像遮挡修复后的部位更倾向于所有外观的平均值,从而导致了面部辨别细节的丢失,影响人脸识别的准确率.本文利用Light-CNN[19]网络的最后两层架构作为语义感知网络S.语义感知网络旨在维持还原后的面部和实际面部之间的面部感知相似性,提高恢复面部的视觉质量.感知损失表述为:
(8)
其中Wk,Hk表示Light-CNN网络中的空间维度.i∈{1,2}代表Light-CNN的最后两层.
3 实 验
3.1 数据集
在DCGANs训练阶段,本文使用数据集CelebA[20],它包含10177个名人身份的202599张人脸图片,因为只需要使用无遮挡的图片训练,这里删除了带有太阳镜、口罩等遮挡图像.然后使用MS-Celeb-1M[21]来训练语义感知CNN网络,并对模型进行微调,在训练之前,使用OpenFace对每个图像进行对齐,并确保大小为64*64像素.
为了评估所提模型的还原效果,本文使用两个数据集进行测试,即AR人脸数据库1和LFW[22],AR包含了足够数量的遮挡图像,对于LFW,本文只选择带有太阳镜或合成掩模遮挡的图像作为测试输入.
3.2 设置与实施细节
本文训练所使用机器配置NVIDIA GeForce 1080Ti显卡,16GB内存,基于TensorFlow深度学习框架.
对DCGAN迭代训练25个周期,每个周期迭代训练1000次,在遮挡检测与生成阶段将损失项的参数λ1设置为0.001,λ2设置为0.003.
遮挡检测与生成的过程的中间输出,如图2所示.第一行显示遮挡人脸生成的预测输出,第二行显示遮挡的检测结果.开始阶段模型的生成阶段产生一个可能的人脸,其中被遮挡部分可能不如非遮挡的部分那么清楚.遮挡检测网络提供遮挡区域的粗略估计,然后根据前面步骤的状态逐步细化输出,也就是说越来越多的结构和纹理添加到脸部轮廓.

图2 遮挡检测与生成的演变过程Fig.2 Evolution of occlusion detection and generation
图3给出了本文提出的方法在检测遮挡的图像区域时的平均收敛速度,其中纵轴表示检测到的遮挡区域的像素差,而横轴表示迭代次数.可以看出,基于本文的实验,所提算法将在6次迭代中收敛,以通过GAN执行面部修复.
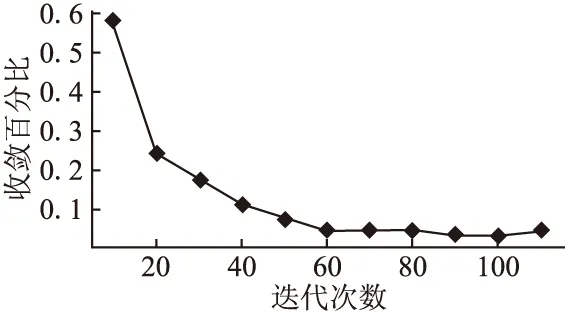
图3 遮挡检测与生成模型的收敛性Fig.3 Convergence of occlusion detection and generation model
3.3 结果与比较
3.3.1 结果
针对不同类型和大小的遮挡检测,遮挡检测与生成的结

图4 遮挡检测与生成效果图Fig.4 Occlusion detection and generation
果如图4所示,图中第1列和第4列为不同类型的遮挡图片,第2和第5列检测到的遮挡掩模,第3和第6列为还原后的人脸图像.最后两行是在LFW数据集上做的测试,可以看出,对具有同一规律的不同测试集,经过训练的模型也能给出合适的输出,通过对输出结果的对比,本文模型的泛化能力得到了较好的展现.
3.3.2 视觉比较
本文比较了与Yeh等提出方法[13]的还原效果,如图5所示.图5(a)为有遮挡图像,图5(b)为文献[13]中预定义的掩模,图5(c)是文献[13]中方法的还原结果,图5(d)是本文方法自动检测出的遮挡掩模,图5(e)是本文方法的还原结果.由于文献[13]中的方法需要预定义图像中遮挡区域的位置和大小,如果定义的遮挡掩模包含未被遮挡的像素,也会被预测生成的图像所覆盖.相较之下,本文提出的方法能够自动检测出遮挡区域,不会生成多余的像素.因此将优于文献[13]的使用.

图5 还原结果对比Fig.5 Comparison of reduction results
3.3.3 定量比较
除了视觉效果的比较,在本文的实验中,进一步验证了加入语义感知CNN后对遮挡图像还原的提升,如图6最后一列所示,加入感知损失后,可以理解人脸的语义结构并很好地保持身份,从而大大提高了还原的面部视觉质量.

图6 不同损失项对结果的影响Fig.6 Impact of different loss items on the results
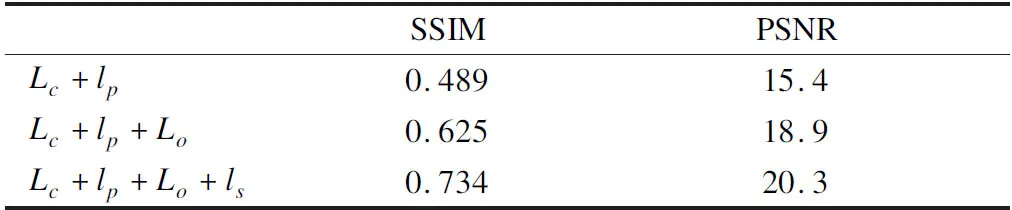
表2 AR数据集在不同损失项下的SSIM和PSNRTable 2 SSIM and PSNR for AR data sets under different loss terms
本文在AR测试数据集上采用两个度量,即峰值信噪比(PSNR)和结构相似性指数(SSIM).在不同的损失项所获得的还原结果与原始面部图像之间计算这两个度量,如表2所示,加上感知损失项后得到了更高的SSIM和SSIM值.表3示出了不同还原方法的SSIM值和PSNR值,与PatchMatch[7]相比,本文的方法能够推断出图像的正确结构,与Context Encoder[11]相比能够保留更多的人脸的精细细节.
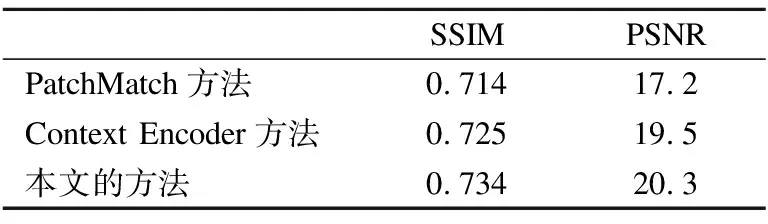
表3 不同还原方法的SSIM和PSNRTable 3 SSIM and PSNR with different methods
4 结 论
本文提出了一种新的方法来还原有遮挡人脸图像,与现有的人脸还原方法相比,本文的方法已经证实可以在不知道遮挡位置和大小的情况下,进行遮挡检测并还原,还原后的人脸图像,能够保留更多的面部细节.
