基于耦合CNN评分预测模型的个性化商品推荐
2020-05-09韩晓龙顾兆旭徐孟阳刘志国
冯 勇,韩晓龙,顾兆旭,王 龙,徐孟阳,刘志国
1(辽宁大学 信息学院,沈阳 110036)2(辽宁轻工职业学校 计算机系,辽宁 大连 116100)3(中国石油天然气股份有限公司 华北化工销售公司,郑州 450000)
1 引 言
随着多媒体技术的迅猛发展与移动互联的广泛应用,互联网用户数量得到急速增加.根据IDC报告显示,进入2020年后全球的数据总量预计超过40ZB,人类社会将正式进入“信息大爆炸”时代[1].用户的角色由传统的信息消费者变成信息提供者,在此转变过程中用户间的信任关系显得尤为重要,用户往往更愿意接受自己相信的人提供的信息.在电子商务的商品推荐过程中用户也更愿意选择自己信任用户给予好评或推荐的商品[2].
Web2.0技术的兴起使得用户可以自由地发表对商品的评论,相对于稀疏的评分数据,如何从商品的在线评论短文本中挖掘代表用户兴趣、喜好的主题,已经成为众多学者研究的热点.在线评论反映的是用户对购买商品或享受服务后最直观和最真实的感受,包含着用户对商品正向和负向的客观评价.电商平台可以依据评论数据发现商品的受欢迎程度,以便发现质量差或令客户不满意的商品,对商品采购以及经营策略做出正确地调整;也可以依据评论发现客服、物流等相关服务出现的问题,并及时做出应对管理[3].
传统的推荐方法中普遍存在因评分数据稀疏而导致推荐准确率低等问题,因而很多学者考虑分析用户或项目的其他相关信息来进行评分的数据填充,以提高推荐准确率[4].因此,在商品的个性化推荐系统中,大量存在的评论信息可以充分反应用户对所购买物品的喜好.因此,本文利用构建的耦合CNN模型对评论文本进行分析,从中提取商品特征、预测用户对商品的评分而生成相应的预测评分矩阵,最终将高预测评分商品推荐给用户.
2 相关工作
2.1 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是在人工神经网络基础上发展起来的一种具有卷积操作的特殊前馈神经网络,已经在语音识别、图像处理和自然语言处理等方面得到广泛应用[5].典型的CNN模型主要包括:输入层、隐含层(卷积层、池化层、全连接层)、输出层.卷积层和池化层的组合可以在隐含层中多次出现.
隐含层各组成部分功能如下:
1)卷积层:对输入的数据进行特征提取操作,由m个卷积核(神经元)组成,通过对输入层过来的数据进行卷积运算得到新特征.
2)池化层:在特征映射上的最大池化操作,取最大值作为对应于这个特定内核的特征.这种方案可以处理不同长度的文本.在最大值合并操作之后,卷积结果被减少为固定大小的向量.
3)全连接层:将经过多个卷积层和池化层提取出来的特征,利用全连接网络进行特征分类,最终得到一个关于输入层的概率分布函数.
2.2 数据稀疏的处理
针对数据稀疏问题,Sarwar Badrul等人[6]最早提出了基于项目的协同过滤算法,该方法比基于用户的推荐方法更加稳定,并且在实验中加入奇异值分解,以此降低高维数据维度,填补稀缺数据,较好地解决了数据稀疏问题,但推荐准确率却不尽人意.
Koren Yehuda等人[7]提出采用矩阵分解技术来降低数据维度,解决数据稀疏问题,并成为近年来推荐系统研究的热点.该方法通过将用户和商品特征分别映射到不同的低维空间中,将用户-评分矩阵降维,得到用户矩阵和商品矩阵,以两个低维矩阵乘积的形式表示原来的高维矩阵.
程芳等人[8]考虑传统用户相似度计算存在的问题,提出了直接相似度与间接相似度的概念,然后引入关键人物权重计算最终评价值.该算法在一定程度上解决了稀疏性问题,但关键人物的选取以及在缺少关键人物情况下,该解决方案尚存问题.
李全等人[9]在解决信任数据稀疏时,提出了一种融合信任度与项目关联度的推荐方法,其关键在于将用户信任矩阵进行分解降维,并引入用户影响力,以此提出局部信任度和全局信任度的概念,并通过项目相关度与流行度进行模型构建,以此提高推荐的效果.
随着深度学习在图像处理、自然语言处理和语音识别等领域的迅猛发展,学者研究的焦点转移到将深度学习与推荐系统相融合,以此来构建更加符合用户需求的个性化推荐模型.Oord等人[10]提出了基于CNN模型的音乐推荐系统,通过训练CNN模型,学习用户的历史收听记录和音乐的音频信号,将两种记录通过CNN模型映射到共享空间,来寻找用户和音乐的隐式表达,进而为用户推荐其感兴趣的音乐,在一定程度上缓解了数据稀疏为推荐系统带来的制约.
受到上述推荐算法的启发,本文构建了由用户网络和商品网络组成的耦合CNN模型,利用该模型进行商品推荐时,将用户评论和商品评论文本输入到模型中,利用对评论数据的分析来提取商品的特征信息,同时模拟用户对感兴趣商品进行评分的行为来生成商品的预测评分矩阵.本文所提的商品推荐策略并不依赖于原始评分数据,而是使用CNN模型形成的预测评分矩阵来生成推荐列表,因此即使原始评分矩阵为稀疏矩阵也不会影响本文算法的推荐效率.最后通过实验验证,本文所提的基于预测评分的商品推荐算法与使用原始评分矩阵进行商品推荐的传统算法在准确率上具有明显的优势.
3 基于耦合CNN评分预测模型
模型中使用用户评论和商品评论模拟用户行为和商品属性,将学习到的用户和商品特征汇集于共享层,共享层使相互独立的不同特征交互后形成商品的评分预测.
3.1 耦合CNN评分预测模型结构
基于耦合CNN评分预测模型结构如图1所示.

图1 耦合CNN评分预测模型Fig.1 Scoring prediction model of coupled CNN
该模型由一个用户网络和一个商品网络耦合并行而成.该耦合CNN模型由三层构成:
1)输入层:将用户评论数据和商品评论数据,分别从两个并行网络的输入层输入.
2)隐含层:包括卷积层、池化层和全连接层,用于对输入的评论数据进行字向量角度的语义分析,使用多个并行的卷积层,利用多个大小不同的卷积核对句子进行特征提取,并产生相应的商品特征输出.
3)共享层:汇集来自两个并行网络输出的用户特征与商品特征后,使用机器学习算法(Factorization Machine,FM)进行商品评分预测.
3.2 句子表示
目前,评论的处理方式大都采用词袋模型[11],但词袋模型不考虑句子中词语的顺序,往往会将评论隐含的主题提取出完全相反的结果.例如,“正义最终打败了邪恶”和“邪恶最终打败了正义”,在词袋模型中拥有完全相同的表示方法,但实际却是完全相反的表达[12].另外,在进行评论主题特征提取方面,目前主要做法是对句子进行分词处理,但现在的短文本通常是噪声大、网络用语多且没有足够的上下文信息作参考[13],使用传统分词方法常常会产生歧义或者无法切分分词.针对这些问题,本文将从字向量的角度,对句子进行处理,学习评论的主题特征,以提高评分预测准确率.
从字角度来解析句子,就是将单个字作为句子的基本组成单位,对单个字进行字向量级别的训练.例如,“我喜欢学习”,分词处理结果是“我-喜欢-学习”,分字处理的结果便是“我-喜-欢-学-习”.
在对句子进行处理时,往往会碰到两方面的问题:一是不同的句子其长度不同,最后得到的特征向量长度也不同;二是句子中的主题特征信息将会出现在句首、句中和句尾等不同的地方[14,15].利用耦合CNN模型进行处理时,可以有效地解决上述问题,问题一的解决是通过在隐含层进行最大池化操作,从而得到固定长度的主题特征向量;问题二的解决是采用多个大小不同的卷积核对句子进行处理,卷积操作后可以得到句子中所有字的局部特征[16].
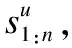
(1)
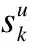
3.3 模型评分预测过程
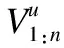
(2)
其中*是卷积运算符,bi是一个偏置项,f是一个激活函数——线性整流函数(ReLU),通过加入ReLU可以避免了梯度爆炸和梯度消失问题,加速随机梯度下降的收敛速度,大大提高训练的速度[17].f的选择我们采用斜坡函数如式(3)所示.
f(x)=max{0,x}
(3)

图2 句子处理过程Fig.2 Sentence processing
接着,将在特征映射层上进行最大池化操作,取操作后的最大值作为对应的这个特定卷积内核的特征.这种方法可以处理不同长度的文本,在最大合并操作之后,卷积结果被减少为固定大小的向量[18],如式(4)所示.
(4)
通过从一个卷积核中提取一个特征的过程可知,卷积层的输出向量经过最大池化操作时,只会选取句子中特征最强的局部信息,而把其他信息抛弃,所以该模型使用多个滤波器来获得各种特征,卷积窗口t的大小不同,致使学习到的局部信息是不同的,利用多个并行的卷积层,可以得到不同的n-gram信息[19],如公式(5)所示.
R={R1,R2,R3,…,Rj}
(5)
其中,R表示所有卷积核输出特征的集合,j为卷积层中进行卷积操作的卷积核数.
来自最大池化层的结果被传递到具有权重矩阵W的全连接层.如公式(6)所示,全连接层的输出Xu被认为是用户u的特征.
Xu=f(W×R+b)
(6)
上述过程是以用户网络为例得到用户特征,同样,将商品评论由商品网络输入,将会得到商品特征Yc,两个网络并行运行,最终输出用户特征Xu和商品特征Yc.
这些输出特征虽然是从用户评论和商品评论中得到的,但它们存在于两个网络的不同映射空间中,两者之间并不具有可比性.因此,为了将它们映射到相同的特征空间,我们引入了一个共享层来耦合用户网络输出和商品网络输出,将Xu和Yc连接成单个向量Z=(Xu,Yc).为了模拟Z中的所有相互独立的用户与商品变量之间的交互关系,我们引入FM算法进行相应的评分预测.因此,给定N个训练样本,我们可以用公式(7)进行训练.
(7)
其中,S表示评分预测,w0表示模型参数,wj表示全局偏置,k表示分解所得隐因子向量维度,vj,fvi,f分别为特征j和i对应隐向量的一个隐因子.
最终,对于预测的商品评分进行由高到低的排序,采用top-k的方法选取前k个高评分商品推荐给用户.
3.4 模型训练
本文通过公式(7)来训练耦合的CNN评分预测网络.对公式(7)中函数y求关于z的偏导数[20],得到公式(8).
(8)
对于不同层中的其他参数的导数可以通过链式法则进行计算.给定一组由N个样本组成的训练集T,通过RMSprop梯度下降法进行模型优化[21].该方法对于梯度的绝对值自适应地控制步长,通过将每个权重的更新值按其梯度范数的运行平均值进行缩放来实现.
4 实验分析
4.1 实验环境配置
本文实验环境具体的配置如表1所示.
表1 实验环境配置
Table 1 Configure of experiment environment

名称规 格硬盘SATA 1TB 7200转内存8G DDRIII 1600CPUCORE I5-4590 3.3GHz 6MB缓存操作系统Windows 7 64位系统编程平台JetBrains PyCharm 2017编程语言Python
4.2 从字角度划分句子的有效性实验
在评论处理方面,本文选用新浪微博数据对本文提出的利用耦合CNN从字角度划分文本的方法进行有效性验证.该数据集是从2012年11月26日至2012年12月28日之间的微博数据中随机爬取的75740条记录组成实验数据集,主题分布如表2所示.
表2 微博数据主题分布
Table 2 Microblog data topic distribution
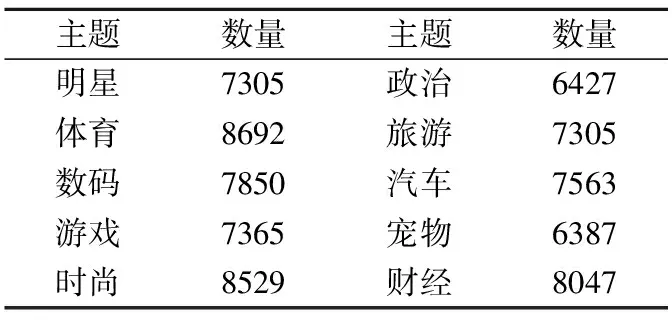
主题数量主题数量明星7305政治6427体育8692旅游7305数码7850汽车7563游戏7365宠物6387时尚8529财经8047
本文选用余弦相似度作为评价标准,对比实验分别从字角度和词角度划分句子,相似度计算如式(9)所示.
(9)
相似度计算结果如表3所示.
实验结果可以看出,评论文本从字角度作为原始特征取得了更好的实验效果.原因主要在于:字级别特征的粒度比词级别的粒度小,字角度向量相比于词角度向量可以学习到更加具体的特征.
4.3 模型重要参数的选取实验
在实验中选择了两个聚数力的Amazon公开数据集1对模型进行评估,Amazon Food(642M)抓取了截止2012年10月份在Amazon网站上的568454条数据,包括用户、评论内容、食品评分等9项数据;Unlocked Mobile phone(141M)抓取了在Amazon网站上的40万条数据,包括用户、无锁移动手机的价格、用户评分、评论等8项数据.实验中选择数据集的70%作为训练集,10%作为验证集,用于调整模型的超参数和用于对模型的能力进行初步评估,20%作为测试集.实验选择均方误差(MSE)作为评价标准,如式(10)所示.
(10)
表3 余弦相似度比较
Table 3 Comparisons of cosine similarity
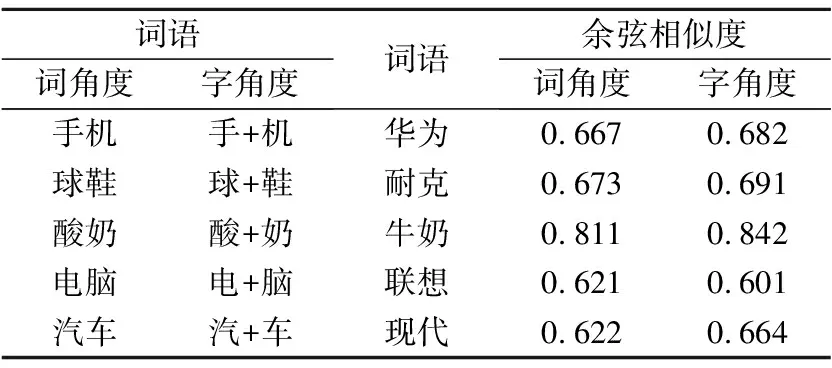
词语词角度字角度词语余弦相似度词角度字角度手机手+机华为0.6670.682球鞋球+鞋耐克0.6730.691酸奶酸+奶牛奶0.8110.842电脑电+脑联想0.6210.601汽车汽+车现代0.6220.664
潜在因子Xu和Yc的选择实验,结果如图3所示.
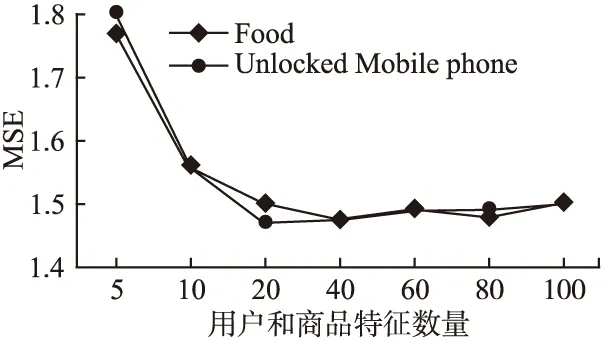
图3 潜在因子数量Fig.3 Number of potential factors
在图3中显示了模型在两个所选数据集上的性能,潜在因子数量的变化范围从5到100.从结果可以看出,当潜在因子的数量大于50时,模型的性能几乎不变.因此,实验中设置潜在因子Xu=Yc=40.
卷积核数量m的选择实验,结果如图4所示.
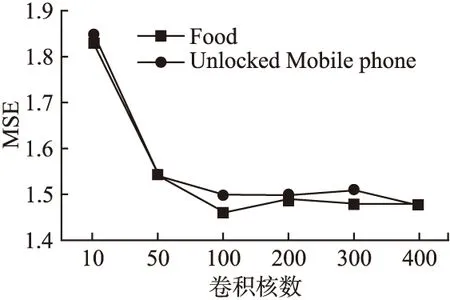
图4 卷积核数量Fig.4 Number of convolution cores
图4中,m的取值范围从10到400,观察模型在两个所选数据集上的性能可以看出:当卷积核数量m大于100时,模型的性能将不再提高.因此,实验中卷积核数目m=100.实验中其他超参数的设置如下:卷积窗口t=3,维度c=400,学习率λ=0.001和batch_szie=100.
4.4 模型评分预测效果对比
在对预测评分数据推荐准确性进行评价的实验中,实验数据集仍采用Food和Unlocked Mobile phone数据集.首先,使用本文所提出的CNN评分预测模型对数据集中的评论文本进行分析得到预测评分矩阵,然后依据评分矩阵将评分高的商品推荐给用户.对比算法中的LDA方法同样也是利用文本分析生成评分矩阵进行推荐,而其他算法的推荐依旧是基于原始评分矩阵.因为本文方法在推荐商品时不使用原始评分矩阵,因此即使原始评分为稀疏数据集,对本文算法的推荐结果亦无任何影响.
评价评分预测结果的指标除了采用MSE,还使用均方根误差(RMSE)、平均绝对误差(MAE)作为评价标准,如式(11)、式(12)所示.
(11)
(12)
在参数确定的情况下,将本文评分预测模型与MF、LDA、SVD、SVD++、LFM等评分预测方法进行对比.在Food和Unlocked Mobile phone两份数据集上以MSE、RMSE及MAE为指标进行对比,如图5所示,本文模型在各指标的对比上均优于其他方法.

图5 不同评分预测模型对比Fig.5 Comparison of different scoring prediction models
通过图5的对比结果可以看出,本文模型在评分预测的各个指标上均优于其他对比方法.在指标MSE上,本文方法在Food数据集上提高了4.8%,在Unlocked Mobile phone数据集上提高了4.9%,平均提高了4.8%;在指标RMSE上,本文方法在Food数据集上提高了2.5%,在Unlocked Mobile phone数据集上提高了6.3%,平均提高了4.3%;在指标MAE上,本文方法在Food数据集上提高了1.6%,在Unlocked Mobile phone数据集上提高了6.7%,平均提高了4.1%.
图6是本文方法与对比算法在处理每个用户数据的平均时间,本文方法在时间效率上要略差于SVD、SVD++及MF算法,原因是对比的三种方法均是基于对数值型矩阵的分析,而本文方法是基于对评论文本的分析;本文方法的处理时间要优于LFM和LDA,其原因是:LFM要在提取隐式因子的基础上进行矩阵计算,而隐式因子的提取会耗费大量时间,从而降低LFM算法的时间效率;而LDA作为非监督机器学习算法,在处理大量短文本评论时,需要重复遍历计算主题概率以提取主题,因而处理效率较低.
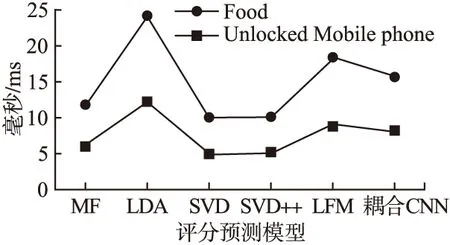
图6 不同模型算法时间对比Fig.6 Time comparison of different model algorithm
5 结 论
本文将卷积神经网络引入到个性化商品推荐中,提出了基于耦合CNN评分预测模型的个性化商品推荐方法.该方法主要通过构建的耦合网络分别进行用户和商品评论分析,以提取商品特征和模拟用户行为,在共享空间进行交互评分预测,最终选取高评分商品推荐给用户.所提方法充分利用卷积神经网络在短文本分析方面的优势,并通过对比实验验证了所给评分预测方法在MSE、RMSE、MAE等指标方面均有明显提升.在今后的研究工作中,考虑充分利用深度学习模型处理异构数据的优势,例如处理评论中的图片数据,进而充分挖掘评论数据中蕴含的价值,进一步提升推荐的准确率.
