最近邻注意力和卷积神经网络的文本分类模型
2020-05-09陈世平
朱 烨,陈世平,2
1(上海理工大学 光电信息与计算机工程学院,上海 200093)2(上海理工大学 信息化办公室,上海 200093)
1 引 言
随着互联网的大规模应用,信息资源不断增加,文本信息成为一种十分重要的信息资源.如何快速、准确、全面的获得有效信息是当前研究的热点问题.近年来,文本分类技术作为自然语言处理和机器学习中的一项基本任务,在情感分析、垃圾邮件识别以及舆情分析中受到了人们的高度重视.
目前文本分类方法主要包括决策树、K近邻(KNN)、支持向量机、朴素贝叶斯、神经网络以及粗糙集等方法[1].但是在传统算法中文本数据存在高维稀疏、特征表达能力较弱、特征项之间易相互影响的缺点,故可能会导致分类时间较长且分类结果较差.
卷积神经网络(Convolutional Neural Network,CNN)是近年来最流行的深度学习算法之一.其显著特点在于:不同卷积核设置不同权重,提取多维特征,通过卷积层和池化层获取文本敏感信息;卷积独特的网络结构使得降维(特征提取)速度更快,结合权值共享使得训练的参数相对较少;网络结构高效简单适应性强[2].
2014年,Kim[3]首先提出卷积神经网络对句子级文本分类,将单词转化为定长词向量,然后采用多尺寸卷积核对词向量卷积,最后进行池化、分类.但该文的不足之处是卷积和池化操作丢失了文本词汇的顺序和位置信息,使语义特征更难捕获.2015年,Lai[4]使用卷积神经网络结合循环神经网络构造网络结构,提出循环卷积神经网络(Recurrent Convolutional Neural Networks,RCNN),将双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)生成的上下文信息与词向量进行拼接并映射到低维空间,最后通过池化获取有效特征,但其主要缺点就是重复计算.2016年,Conneau[5]在Kim的卷积神经网络基础上实现了非常深层次的卷积结构,即使用小卷积和池化,池化层使用的K-MaxPooling可以获得特征值中最具代表性的Top-K个值,保留了更多的信息.此模型卷积层多达29层,并且成功应用于句子分类.但深层次的神经网络会使模型退化,分类效果降低.
近年来,许多学者通过研究深度神经网络和注意力机制,构建网络模型,获得文本隐含的特征信息,使之具有更好的分类效果.2015年,Yin W[6]引入注意力机制对卷积神经网络加权计算,分别在卷积前加入注意力、池化层加入注意力、输入层和池化层同时加入注意力,将句子和词语间的相互影响通过注意力机制加权到卷积神经网络模型中,并运用在语句模型创建上,取得了不错的分类效果.2017年,Pappas[7]提出分层注意力模型对段落进行分类,使用双向GRU获得词语和句子的表征,以及两个级别的注意力机制,使模型获取不同级别的信息,但是没有考虑文本对象信息对分类结果的影响.2017年,Wang Z[8]提出使用最近邻算法增强神经网络对文本进行分类.首先使用BiLSTM对文本进行训练,融合KNN算法计算注意力机制对K个文本加权,并取得了不错的效果.但是BiLSTM的时间复杂度较高,导致训练速度较慢.
从整体上来看,目前的注意力机制模型大多采用独特的网络结构对输入文本建模,但并未考虑文本实例对象对整体分类效果的影响.本文提出最近邻注意力和卷积神经网络的文本分类模型,通过最近邻注意力机制增强卷积神经网络的分类能力,使得用于分类的特征更加准确.首先通过改进的最近邻算法从训练集中获得文本的对象信息,基于文本相似度构建文本对象注意力.然后将注意力机制与卷积神经网络相结合实现全局特征和局部特征的融合.最后通过softmax函数进行文本分类.本文通过采用搜狗新闻语料库、中山大学语料库以及英文新闻语料库AG_news进行实验.结果表明,本文采用的改进算法相较于基准算法效果更优.
2 相关工作
2.1 最近邻算法(KNN)
最近邻算法是模式识别和数据挖掘中最常用的算法之一.其算法思想相对简单,并且对噪声具有一定的鲁棒性.采用KNN算法进行文本分类,首先使用词向量模型将训练集和测试集的文本表示为向量,然后采用距离公式计算待分类文本和训练集中每个文本的相似度,选出相似度最高的K个文本,则待分类文本的类别被预测为K个文本中出现概率最大的文本类别标签,其中距离相似度通常采用欧氏距离、余弦距离、马氏距离、曼哈顿距离等.
给定文本训练集:N={X1,X2,…,Xm},对应类别标签为:L={y1,y2,…,ym}.
最近邻算法距离相似度公式为:
(1)
公式(1)中:Xi是待分类文本,Xj是文本训练集N中的一个文本,Xiz是Xi的第z个特征,Xj是文本训练集N中的一个文本,Xjz是Xj的第z个特征,d是文本向量的特征维数.
对于给定的输入文本,采用距离公式计算相似度,从训练集中找出K个距离最小最相似的文本:{X1,X2,…,Xk},其对应类别标签为:{y1,y2,…,yk}.
2.2 基于卷积神经网络的文本分类模型
文本分类是根据给定文本数据,预测每个测试文本对应的类别[9].每个文本由文本之间的局部特征和全局特征相互作用决定.针对文本内部相互作用的关系,采用由多个尺寸卷积核组成的卷积神经网络进行实验,提取文本特征项之间的复杂关系.
Mikolov[10]等人提出word2vec模型,根据给定的语料库,经过优化后的训练模型可以快速有效地将一个词语表示成对应的词向量.本文利用word2vec模型训练文本语料库,得到词向量.单个文本的最大词语数目为v个:{t1,t2,…,tv},每个词语的词向量为d维,组成一个v*d维的矩阵,作为文本分类模型的输入,传入多尺寸卷积神经网络模型(MCNN)(如图1所示).
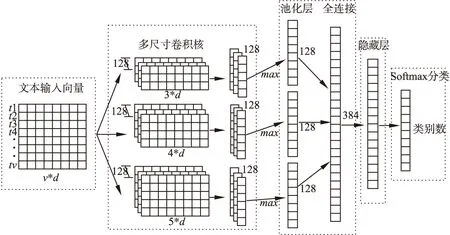
图1 多尺寸卷积神经网络模型Fig.1 Multi-size convolution neural network model
卷积神经网络文本分类模型由卷积层、池化层、全连接层、softmax分类函数组成.
1)卷积层
将文本向量作为卷积神经网络模型的输入,使用多尺寸卷积核进行卷积,提取不同类型的多维特征.每个卷积核都设有一个固定的滑动窗口,每次对窗口内的特征进行卷积,并使用激活函数激活.本文使用的卷积核高度h分别为3、4、5,滑动步长为1,每个尺寸的卷积核数目为128个.
{t1:h,t2:h+1,…,tv-h+1:v}
(2)
公式(2)表示输入文本的窗口.
每个窗口ts:s+h-1卷积特征值的计算公式为:
(3)
其中Wh为卷积核的权重Wh∈Rh*d,h为卷积核的高度,bh∈R为偏置,s代表卷积核的滑动窗口的参数,⊗为卷积计算,f(x)为激活函数,常用的激活函数为Sigmoid、Tanh和Relu等,本文采用Relu函数激活,Relu函数能够更好地学习优化.
滑动窗口经过一个卷积核卷积后的特征图为:
(4)
2)池化层
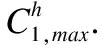
每个尺寸都有128个卷积核,则尺寸h=3卷积后的特征图为:
(5)
尺寸h=4卷积后的特征图为:
(6)
尺寸h=5卷积后的特征图为:
(7)
将经过Max-pooling后的不同尺寸特征图进行拼接,构建文本的全局特征图:
C=[C3,C4,C5]=[T1,T2,…,T384]
(8)
共提取出384个特征,作为全连接层的输入.
3)全连接层
将384个特征输入至全连接层,隐藏层节点数为128,输出层节点数为类别数,全连接神经网络的计算公式为:
C′=f(W1C+b1)
(9)
C″=f(W2C′+b2)
(10)
其中W1、W2为全连接层的两层权重,b1、b2为偏置,f(x)采用激活函数Relu激活.
4)分类函数softmax预测
(11)
多尺寸卷积神经网络进行一次前向传播后,利用反向传播来对卷积核的权重进行更新,进行多次更新后,取得最优的预测模型.
3 算法框架
3.1 改进的最近邻算法(AKNN)
最近邻算法通常采用欧式距离作为相似度衡量.但欧氏距离只考虑了各个特征项之间的绝对距离,而忽略了相对距离.在分类问题中,往往采用特征项的相对距离来作为距离的衡量标准.卡方距离通过卡方统计量衡量个体特征之间的差异性,从而体现特征项之间的相对关系,因此本文使用基于特征属性加权的卡方距离计算相似度.
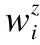
(12)
本文提出基于卡方距离结合属性空间分布的特征值加权:
1)公式(13)的第一部分分母表示沿特征项方向测试文本和所有文本的卡方距离之和以及对应的训练文本和所有文本的卡方距离之和,分子为测试文本与所有训练文本之间沿特征项方向的卡方距离之和,整体表示测试文本与所有文本的相对位置影响.
2)公式(13)的第二部分分母表示该待分类训练文本和其他训练文本之间沿特征项方向的卡方距离之和,分子表示测试文本与所有训练文本之间沿特征项方向的卡方距离之和,整体表示测试文本与所有训练文本的相对位置影响.
(13)
通过加权的卡方距离计算文本相似度,找出K个最近邻文本为:{X1,X2,…,Xk},其对应类别标签为:{y1,y2,…,yk}.
3.2 CNN-AKNN分类模型
本文首先使用上述改进的KNN算法提取与类别实例相关的K个文本.然后对相关文本进行注意力加权,以此获取文本隐含的特征信息.最后将注意力权重与卷积神经网络池化层的输出进行拼接,一起输入至全连接层,对模型(如图2所示)更好的训练.
利用上述改进的AKNN算法得到每个文本的K个训练文本,并定义其文本向量表示为{X1,X2,…,Xk},其对应标签为{y1,y2,…,yk}.
使用相似度函数分别计算待分类文本X和得到K个训练文本的相似度:
Si=sim(X,Xi)
(14)
S={S1,S2,…,Sk}
(15)
其中i∈{1,2,…,k},Si表示待分类文本X与第i个文本的相似度,S是由K个训练文本构建的注意力权重,分别使用注意力权重S对改进KNN算法输出的标签和文本向量加权.
对AKNN算法输出的文本标签加权的计算公式为:
(16)
利用S对标签加权得到加权文本标签y′,其中yk是文本实际标签.
对AKNN算法输出的文本向量加权的计算公式为:
(17)
利用S对文本向量加权得到加权文本向量X′.
将基于神经网络的模型和基于实例的学习相结合,可以获得良好的效果.将上述注意力加权的训练文本标签和注意力加权的训练文本向量拼接后融入到卷积神经网络的全连接层.
模型训练环节使用随机梯度下降法Adma算法[12]对权重进行更新.定义交叉熵函数为训练目标的损失函数:
(18)
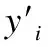
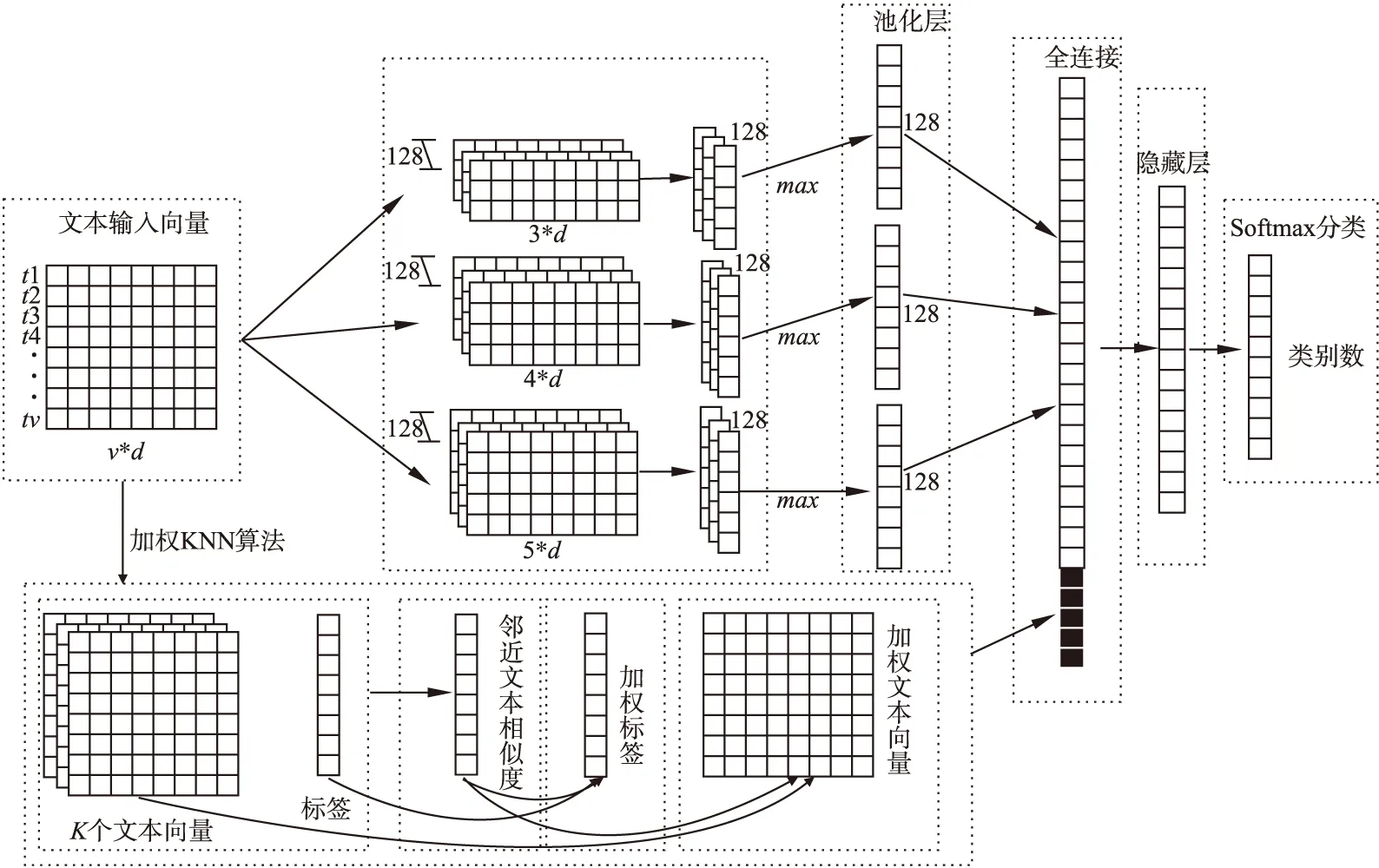
图2 最近邻注意力和卷积神经网络的文本分类模型Fig.2 Text classification model based on nearest neighbor attention and convolution neural network
4 实验以及结果分析
4.1 实验环境
实验环境如表1所示.
表1 实验环境
Table 1 Lab environment
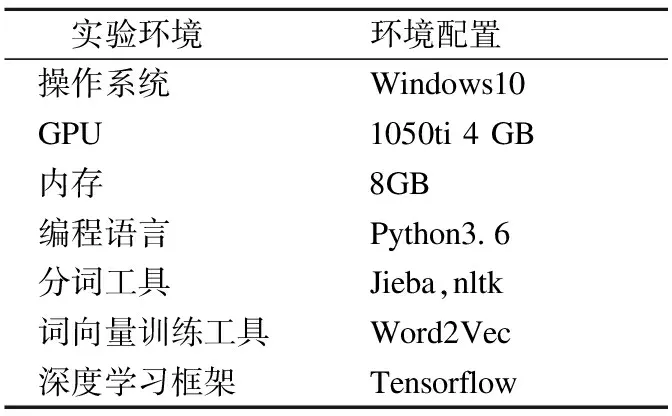
实验环境环境配置操作系统Windows10GPU1050ti 4 GB内存8GB编程语言Python3.6分词工具Jieba,nltk词向量训练工具Word2Vec深度学习框架Tensorflow
4.2 数据集
本文选取来源于搜狗实验室、中山大学两个中文新闻数据集以及英文新闻数据集AG_news,三个数据集均是中英文文本分类中最常用的新闻语料库.选取搜狗数据集10个类别(体育、财经、房产、家居、教育、科技、时尚、时政、游戏、娱乐)共20000条数据,中山大学数据集8个类别(交通、健康、娱乐、教育、文化、科技、游戏、经济)共18000条数据.AG_news数据集4个类别(World、Sports、Business、Sci/Tech)共27200条数据.具体实验信息如表2所示.
4.3 参数设置
本文的参数主要设置如下.
使用Word2vec训练词向量,词向量维数200,词语个数6000,得到文本向量的尺寸大小为6000*200.
表2 数据集的统计信息
Table 2 Statistics of data set

名称训练集验证集测试集类别数共计搜狗10000500050001020000中山大学1000040004000818000AG_NEWS1200076007600427200
设置不同尺寸的卷积核,第一种卷积核的个数128,尺寸大小为3*200,第二种卷积核的个数128,尺寸大小为4*200,第三种卷积核的个数128,尺寸大小为5*200.全连接层隐藏节点数为128.
丢弃率dropout为0.5,学习率为0.001,学习率指数衰减率为0.9,梯度阈值为5.0,迭代次数为20,批次数为64.改进最近邻算法,K设置范围为[1,20].
4.4 实验结果和分析
本文采用最近邻注意力和卷积神经网络的文本分类模型,对文本进行分类.选取部分实验结果作为展示,本文采用四个实验对模型的分类结果进行衡量.
实验1.为了验证模型的预测性能,本文采用基准模型:卷积神经网络(CNN)[13]、字符集卷积神经网络(Char Convolutional Neural Network,CharCNN)[14]、循环卷积神经网络(RCNN)[4]、长短时记忆网络(Long Short-Term Memory,LSTM)[15]、双向长短时记忆网络(BiLSTM)[16]、最近邻注意力和卷积神经网络(CNN_KNN)、加权卡方最近邻注意力机制和卷积神经网络(CNN_AKNN).其中CNN_KNN模型采用传统的KNN算法和多尺寸卷积神经网络构建网络模型,CNN_AKNN模型采用加权卡方距离改进的AKNN算法和多尺寸卷积神经网络结合构建网络模型.本文分别采用准确率(Accuracy)、召回率(Recall)、精确率(Precision)、宏F1值对模型评价.TP表示预测为正样本且分类正确的样本数,TN表示预测为负样本且分类正确的样本数,FP表示实际为负且分类错误的样本数,FN表示实际为正且分类错误的样本数.
(19)
(20)
(21)
(22)
表3为不同数据集上各个模型的准确率、精确率、召回率、宏F1值的比较结果.从表3看出,相比CNN、CharCNN、RCNN、LSTM、BiLSTM,本文模型在三种数据集上都表现出了良好的性能,相比传统的卷积神经网络模型分类效果分别提高了2.96%,1.34%,1.81%.这是因为本文在模型中综合考虑了文本词语的隐含特征,更适合文本分类的实际特点,获取文本特征提高分类准确率.本文采用的改进AKNN算法比传统的KNN算法分类效果更好,这是因为本文采用文本特征属性对文本相似度加权,更好的衡量相对距离.
表3 各模型准确率对比
Table 3 Comparison of accuracy rate of models
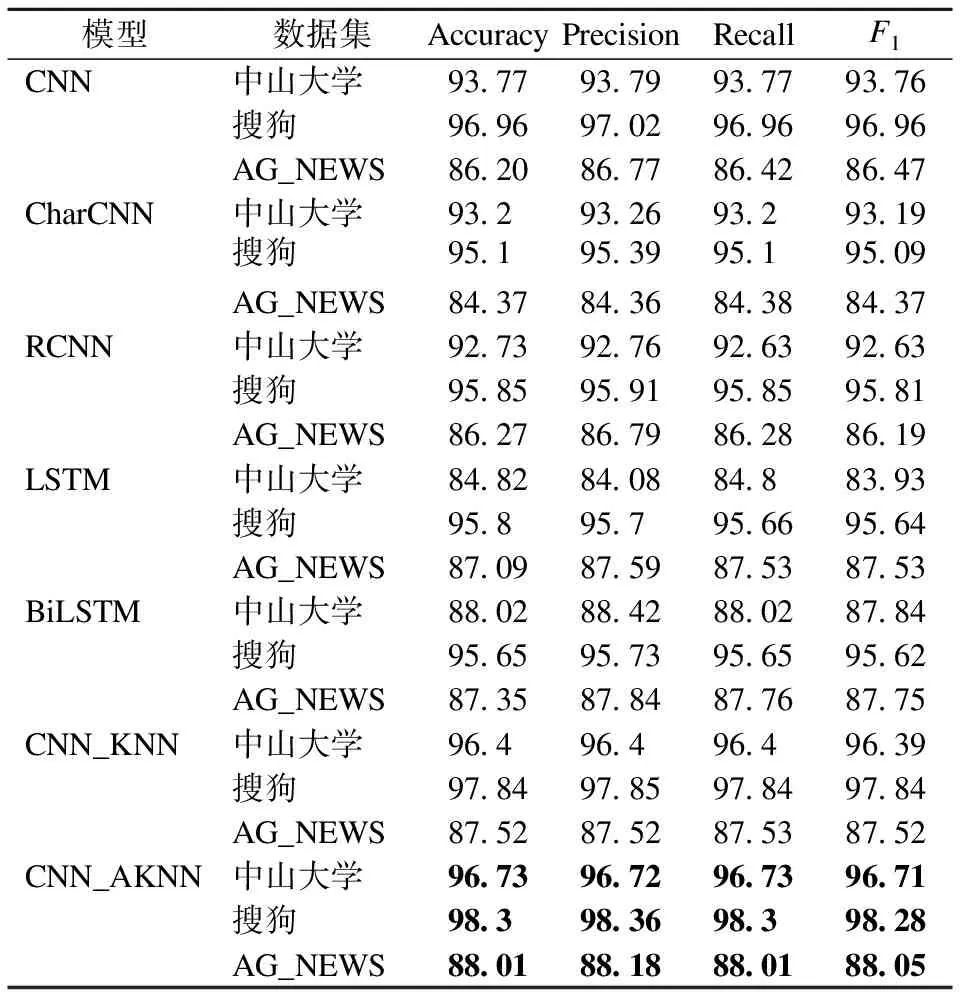
模型数据集AccuracyPrecisionRecallF1CNN中山大学93.7793.7993.7793.76搜狗96.9697.0296.9696.96AG_NEWS86.2086.7786.4286.47CharCNN中山大学93.293.2693.293.19搜狗95.195.3995.195.09AG_NEWS84.3784.3684.3884.37RCNN中山大学92.7392.7692.6392.63搜狗95.8595.9195.8595.81AG_NEWS86.2786.7986.2886.19LSTM中山大学84.8284.0884.883.93搜狗95.895.795.6695.64AG_NEWS87.0987.5987.5387.53BiLSTM中山大学88.0288.4288.0287.84搜狗95.6595.7395.6595.62AG_NEWS87.3587.8487.7687.75CNN_KNN中山大学96.496.496.496.39搜狗97.8497.8597.8497.84AG_NEWS87.5287.5287.5387.52CNN_AKNN中山大学96.7396.7296.7396.71搜狗98.398.3698.398.28AG_NEWS88.0188.1888.0188.05
实验2.为了测试AKNN算法中K的取值对模型分类准确率的影响,本文选取K的变化范围为[1,20],步长为1,并比较三个不同数据集上K的变化范围对本文模型准确率的影响.
从图3可以看出,K取0时表示多尺寸卷积神经网络模型(MCNN),其中搜狗实验室数据集准确率达到96.96%,中山大学语料库达到93.77%,英文新闻语料库AG_news达到86.2%.当多尺寸神经网络模型结合改进的最近邻算法得到CNN-AKNN模型时,三个数据集的准确率均有显著的提升.当K取6时,搜狗实验室数据集的准确率达到98.3%,当K取9时,中山大学语料库的准确率达到96.73%, 当K取6时,英文新闻数据集AG_news的准确率达到88.01%.从图3中的三条曲线的变化规律可以看出,当K值增加时,模型的分类准确率在上升,但是当K上升到一定程度时,由于过多的相似文本导致特征冗余,过多的噪声干扰分类的准确率,导致准确率下降.从实验2可以看出,合适的K确实可以增大实验的准确率.
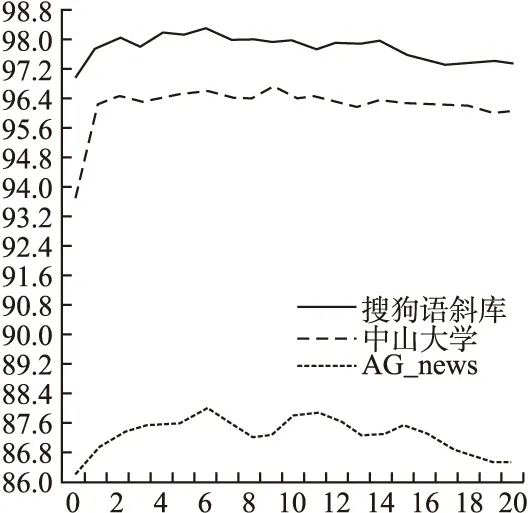
图3 K的不同取值对结果的影响Fig.3 Influence of different values of K
实验3.为了验证最近邻注意力和卷积神经网络的文本分类模型(CNN-AKNN)和多尺寸神经网络模型(MCNN)在不同卷积核尺寸作用下,对文本分类准确率的影响.本文共设置了7组不同的卷积核,卷积核尺寸分别为3、4、5、(3,4)、(3,5)、(3,4,5),并测试两个模型在三个不同数据集上的准确率.
表4 不同卷积窗口尺寸的效果
Table 4 Effects of different convolution window sizes
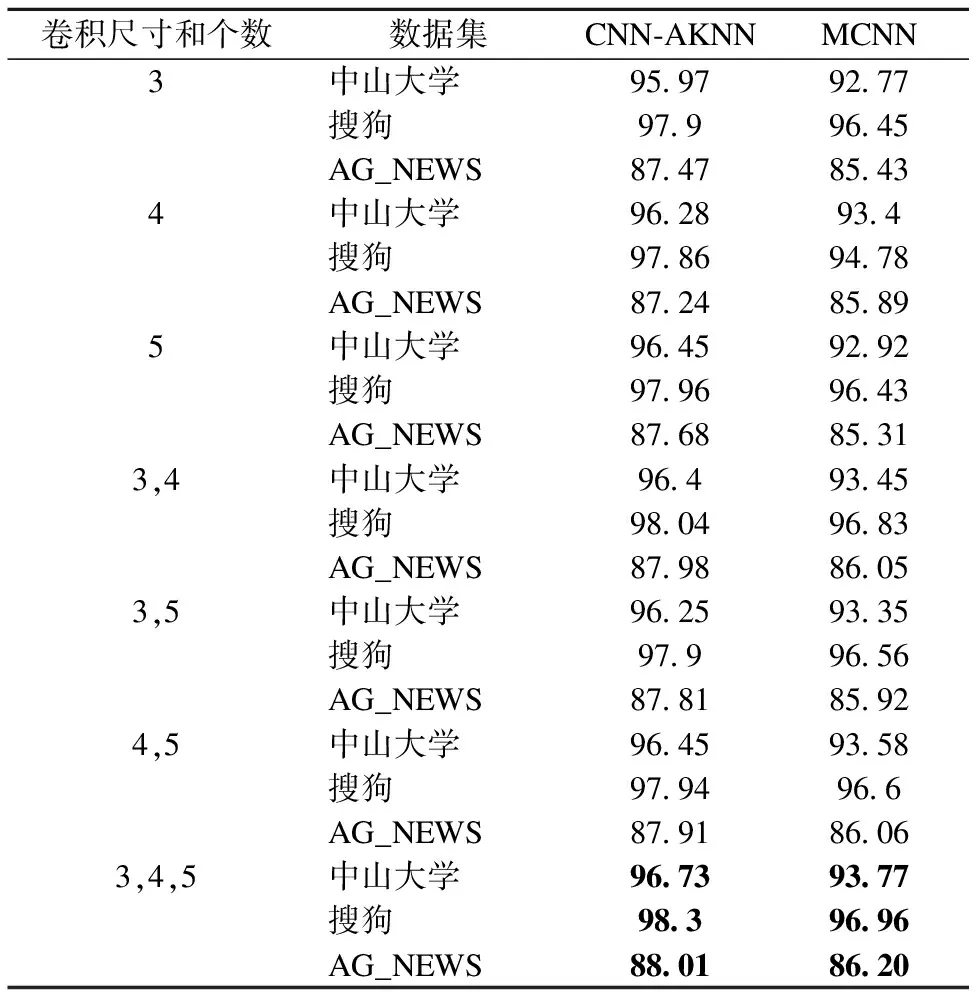
卷积尺寸和个数数据集CNN-AKNNMCNN3中山大学95.9792.77搜狗97.996.45AG_NEWS87.4785.434中山大学96.2893.4搜狗97.8694.78AG_NEWS87.2485.895中山大学96.4592.92搜狗97.9696.43AG_NEWS87.6885.313,4中山大学96.493.45搜狗98.0496.83AG_NEWS87.9886.053,5中山大学96.2593.35搜狗97.996.56AG_NEWS87.8185.924,5中山大学96.4593.58搜狗97.9496.6AG_NEWS87.9186.063,4,5中山大学96.7393.77搜狗98.396.96AG_NEWS88.0186.20
表4为两个模型在不同卷积核尺寸作用下的分类准确率.由表4可知,卷积核尺寸为(3,4,5)的分类结果均优于其他的卷积核尺寸,在多尺寸卷积核的相互作用下,分类准确率比单尺寸卷积核的分类准确率高,证明多尺寸卷积核可以提取出更多的文本特征,对提高分类算法的准确率有正向促进作用.
实验4.为了测试加权文本标签以及加权文本向量对模型分类效果的影响,本文设计了加权文本标签(CNN-Label)、加权文本向量(CNN-Text)以及结合加权文本标签和加权文本向量(CNN-AKNN)的实验,验证本文模型的有效性.
表5 加权文本标签和加权文本向量对结果的影响
Table 5 Influence of weighted text labels and
weighted text vectors
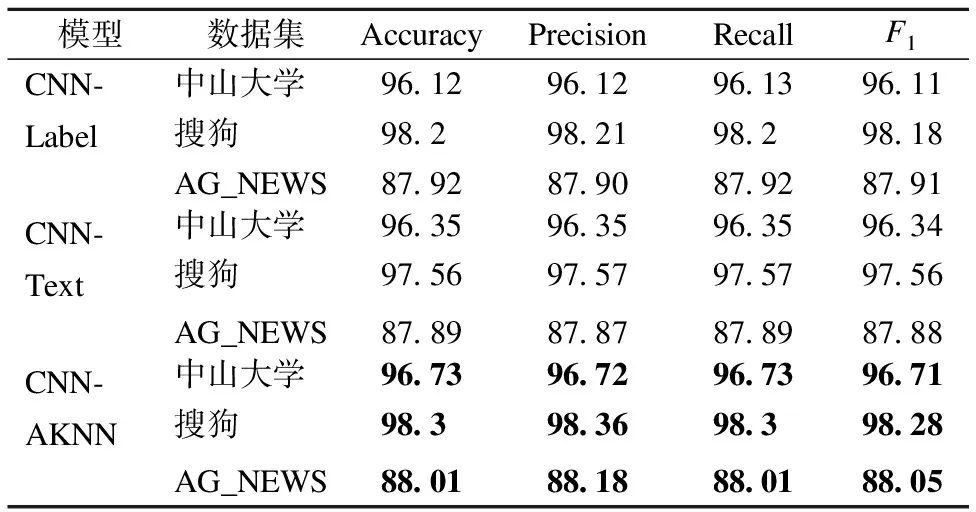
模型数据集AccuracyPrecisionRecallF1CNN-Label中山大学96.1296.1296.1396.11搜狗98.298.2198.298.18AG_NEWS87.9287.9087.9287.91CNN-Text中山大学96.3596.3596.3596.34搜狗97.5697.5797.5797.56AG_NEWS87.8987.8787.8987.88CNN-AKNN中山大学96.7396.7296.7396.71搜狗98.398.3698.398.28AG_NEWS88.0188.1888.0188.05
表5为加权文本标签和加权文本向量对分类效果的影响.由表5可知,三个实验结果都优于实验1中基准算法的分类结果.由此可见,由AKNN计算得到的加权文本标签和加权文本向量通过构建注意力机制能够获得文本的全局特征.另外,由于结合了加权文本标签和加权文本向量,模型的分类效果要优于只加了一种改进变量的模型.可以看出,在加权文本标签和文本向量的共同作用下,本文模型的预测效果最优,可以更好地捕获文本特征之间的依赖关系,证明了多尺寸卷积神经网络结合AKNN算法进行加权的可行性.
5 结束语
由于目前的注意力机制大多采用独特的网格结构对文本建模,并未考虑文本对象对分类结果的影响.故提出了最近邻注意力和卷积神经网络的文本分类模型.
本文的分类模型有两个创新之处:一是使用多尺寸的卷积神经网络结合改进KNN算法得到的实例信息,能够提取更加丰富的文本特征.二是考虑到文本特征属性空间分布对特征值的影响,使用加权卡方距离的最近邻改进算法,利用文本的空间属性值对距离加权,从而对文本进行分类,其效果优于传统的KNN算法.其中多尺寸卷积神经网络模型的参数和KNN的参数均具有一定的鲁棒性,使模型适合各种不同的数据集.本文通过四个实验的对比,表明本文的模型相比其他基准的深度学习模型效果有明显的提高,为文本分类提供的一个新的思路.
今后的研究将尝试以下工作:KNN算法由于其需要计算测试文本和每个训练文本的相似度,导致时间复杂度较高.考虑使用特征结构存储KD-Tree与神经网络结合,减少计算距离的次数,从而降低时间复杂度和空间复杂度.
