MOEA/D线性插入方向向量策略研究
2020-05-09林梦嫚王丽萍
林梦嫚,王丽萍,周 欢
(浙江工业大学 经贸学院, 杭州 310023)
1 引 言
多目标问题(Multi-objective problems,MOPs)中目标函数之间一般是相互冲突的,没有一个最优解能够同时优化所有的目标.Pareto最优解对于决策者来说是一种很好的选择.由于进化算法一次运行能够提供多个Pareto最优解,且不受目标函数数学性质的影响,因此利用进化算法求解多目标优化问题成为近年来的研究热点[1].
近年来,多目标进化算法(Multi-objective evolutionary algorithms,MOEAs)的应用极为广泛.根据现有的研究,MOEAs分为以下3类:
1)基于Pareto支配的多目标进化算法[2,3],该类方法以Pareto支配选择较优的解,随着目标个数的增多,非支配解的比例明显增加,搜索能力明显退化[4].
2)基于指标的多目标算法[5-7],该类算法以某些性能指标作为参考信息选择较优的解,然而计算性能指标的复杂度较高,耗时较长.
3)基于分解的多目标算法[8-10],该系列算法将多目标问题分解为多个单目标子问题协同优化,该类算法求解效率高,解集性能较优,其中以Q.Zhang[11]提出的基于分解的多目标进化算法(Multi-objective evolutionary algorithm based on decomposition,MOEA/D)效果最为显著.
基于分解的多目标进化算法有几个显著的优点.与Pareto支配的进化算法相比,有着较强的搜索能力,能够很好的处理组合优化问题,计算简单,求解效率高,能够很好的处理复杂Pareto Sets[12]的多目标问题等优点.MOEA/D获得2009年进化计算“无限制多目标进化算法”的冠军[13],并普遍应用于诸多实际问题中.
至今为止,为提高MOEA/D的性能,学者们已经做了大量的研究,根据研究的主要内容,大致分为两大类.一类为生成均匀的权重向量,尝试依靠均匀分布的权重向量获取均匀分布的解集.另一类则为算法进化过程中,根据进化得出的解集,调整权重向量,维持解集较好的分布特性.为研究的方便,本文侧重于后者.
自Q.Zhang 2007年提出MOEA/D以来,很多学者已经证明MOEA/D中预先设定的固定权重向量并不能够保证解集均匀分布整个Pareto前端.2010年,Gu和Liu[14]根据当前权重向量集合周期性地更新权重向量,在此基础上提出W-MOEA/D(A Novel Weight Design in Multi-objective Evolutionary Algorithm,W-MOEA/D)算法,相比原始的MOEA/D,该算法求出解集的整体质量有所提高,然而W-MOEA/D算法依靠WS(Weighted Sum,WS)聚合方法,由于WS聚合方法本身存在不能处理非凸问题的缺陷,因此阻碍了该算法的适用性.2011年,Jiang et al[15]提出paλ-MOEA/D(Multi objective Optimization by Decomposition with Pareto-adaptive Weight Vectors,paλ-MOEA/D),该算法根据Pareto前端的几何特性对权重向量进行调整,该算法能够获得收敛性和多样性较好的解集,然而该算法要求求解的多目标优化问题的PF(Pareto Front,PF)为四分之一圆形或者球形.实际求解过程中,待求解问题的PF都是未知的,因此,该算法存在一定的缺陷.2013年,Wang et al[16]提出使用预处理策略调整权重向量,为初始化的个体找到距离相对较近的权重向量,为叙述的简便,本文将该算法简记为MOEA/D-pre(An enhanced MOEA/D using uniform directions and a pre-organization procedure,MOEA/D-pre),该算法能够提高解集的收敛性,然而初始化的个体随机性较大,导致MOEA/D算法中引入预处理策略的效果较差.随后Qi et al[17]提出MOEA/D-AWA(MOEA/D With Adaption Weight Adjust,MOEA/D-AWA)算法,MOEA/D-AWA提出一种新的权重向量初始化技术,同时根据复杂的Pareto前端自适应调整权重向量,提高解集的均匀性.然而MOEA/D-AWA中需要维持一定数量的外部非支配解,根据这些非支配解的拥塞距离自适应调整权重向量,这种方法增加了计算的复杂性,并消耗一定的时间.随后,Yuan et al[18]提出MOEA/D-DU(Balancing Convergence and Diversity in Decomposition-Based Many-Objective Optimizers,MOEA/D-DU),根据解与相关子问题之间的垂直距离,调整解集的分布.实验证明,该算法在高维多目标优化问题中效果显著,然而持续性的计算解与子问题的垂直距离消耗的计算资源较多,同时对于复杂的PF,依旧难于处理.2016年,Jiang et al[19]分析Pareto前端为尖峰、低尾、不连续的情况,提出两阶段策略的MOEA/D-TPN(an improved MOEA/D with a two-phase strategy(TP)and a niche-guided scheme,MOEA/D-TPN)算法,实验表明该算法通过分析运行过程中问题的难易程度,把多目标问题的优化分为两个阶段,合理利用计算资源,能够有效地求解具有复杂PF的问题.然而,该算法具有两个缺陷:其一,该算法设计的参数较多,在PF未知的情况下,算法中一系列的参数难以确定.其二,该算法不易预测种群的拥塞程度.
本文,首先分析均匀分布的权重向量、均匀分布的搜索方向二者与均匀分布的解集之间的关系,提出一种新的权重向量设置方式;其次利用进化过程中解集的分布特性,提出不依赖于外部种群的线性插入搜索方向策略,并将其转换为对应的权重向量,同时在MOEA/D中周期性使用该策略调整搜索方向,获取分布均匀的解集,提出使用调整权重向量的MOEA/D-AW算法,为比较公正性,采用WFG多目标算法测试函数进行系列仿真试验,并将该算法与原始的MOEA/D、使用均匀分布的搜索方向MOEA/D、使用预处理的MOEA/D、MOEA/D-DU进行性能比较.
2 背景知识
2.1 权重向量的生成
当决策者没提供任何的偏好信息的时候,希望得到的结果是均匀分布在Pareto前端上.因此对于MOEA/D来讲,使用相对均匀的权重向量的结果比不均匀的权重向量效果更好.为此,MOEA/D中生成权重向量的方法.描述如下:
λ1+λ2+…+λk=1
(1)
(2)
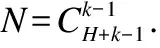
2.2 MOEA/D中均匀权重向量、均匀搜索方向、均匀Pareto最优解三者之间的关系
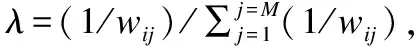
图1中标识为权重向量的线条代表原始的MOEA/D预先设定的权重向量,虚线表示与预先设定的权重向量对应的方向向量.根据对聚合函数的几何特性分析可知,Pareto最优点为方向向量与PF的交点,如图中的圆圈,而不是预先设定的权重向量与PF的交点.因此,均匀分布的方向向量能尽可能地保证均匀分布的Pareto最优解集,预先设定的均匀分布的权重向量却并不能够保证产生均匀分布的Pareto最优解集.文献[16]中也给出相关的证明.基于以上的分析,本文决定使用2.3小节中的方法生成目标空间中的搜索的方向向量,然后根据表达式(3)将其转换为对应的权重向量.
(3)
其中λij即为采用2.3小节中的方法生成的方向向量的分量.表达式(3)有如下的修订,当λij为0时,修改为λij+ε,其中ε为0.000001,其他情况,不做任何修改.采用这一策略,尽可能在初始化时产生均匀分布的方向向量,提高算法求得解集分布的均匀性.
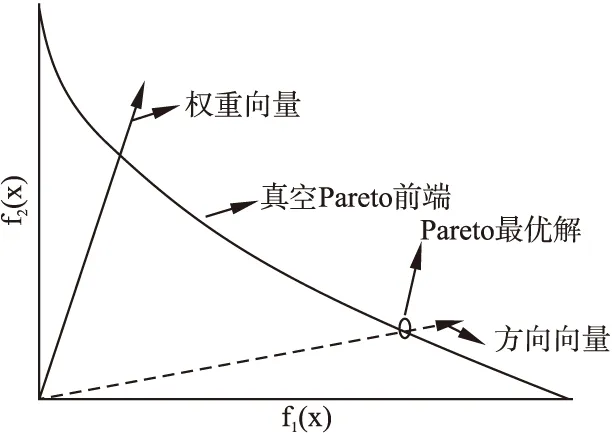
图1 MOEA/D中权重向量、方向向量、Pareto最优解三者之间的关系Fig.1 Relationship between weight vector,direction vector and Pareto optimal solution in MOEA/D
3 具有复杂Pareto前端的多目标问题及MOEA/D存在的缺陷分析
3.1 复杂Pareto前端的多目标问题
现实生活中,多目标问题的Pareto前端都是未知的.因此均匀分布的搜索方向只能尽可能地提高解集分布的多样性,但对于复杂的Pareto前端的多目标问题,仅依靠预先设定的均匀分布搜索方向显然是不够的.
3.2 MOEA/D存在的缺陷
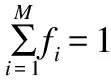
4 线性插入搜索方向策略
基于以上的分析,本文将使用k近邻方法求出进化过程中算法解集的密集度,删除解集中最密的个体,对于解集中最稀疏的区域,利用附近的个体对应的方向向量,线性插入搜索方向(如图2所示),并利用附近的个体产生出新的个体,达到增强解集多样性的效果.具体算法流程如下:
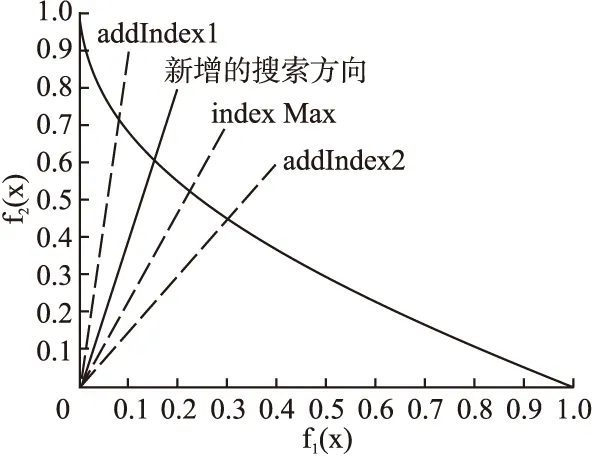
图2 线性插入方向向量示意图Fig.2 Linear insertion direction vector diagram
输入:
1.多目标优化问题;
2.停止条件;
3.N:MOEA/D分解的子问题个数即种群规模大小;
4.λ1,λ2,…,λN:采用2.3中方法构造的N个方向向量并利用式子(3)将其转换为对应的权重向量;
5.T:预定的邻域大小;
6.Adjust_Gen:0.8*MaxGen开始使用线性插入策略的代数;调整的周期为 delta.
输出:PF:{F(x1),F(x2),…,F(xN)}.
Step 1.初始化:
Step 1.1.计算任意两个权重向量之间的欧式距离,为每个权重向量选出最近的T个向量作为它的邻域.设B(i)={i1,i2,…,iT},i=1,2,…,N,其中λi1,λi2,…,λiT为距离λi最近的T个权重向量.
Step 1.2.采用随机或均匀设计方法初始化种群x1,x2,…,xN,设FVi=F(xi),i=1,2,…,N.
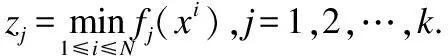
Step 2.更新:
i=1,2,…,N,执行
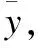
Step 2.2.修正:应用问题特定的修正或启发式的改进策略作用于y生成y′.
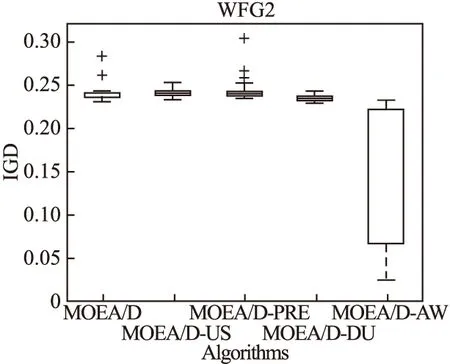
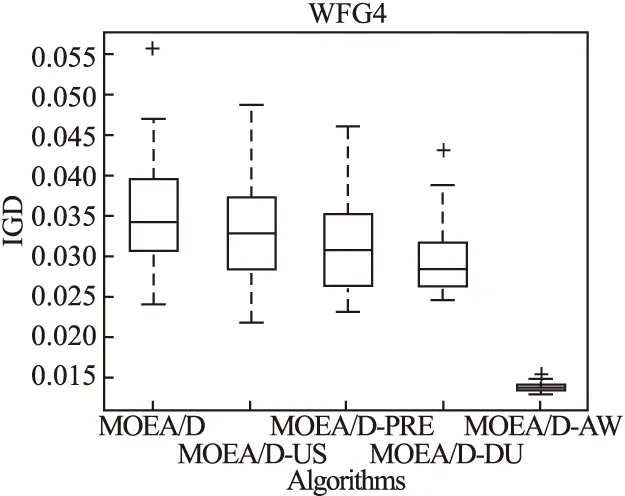
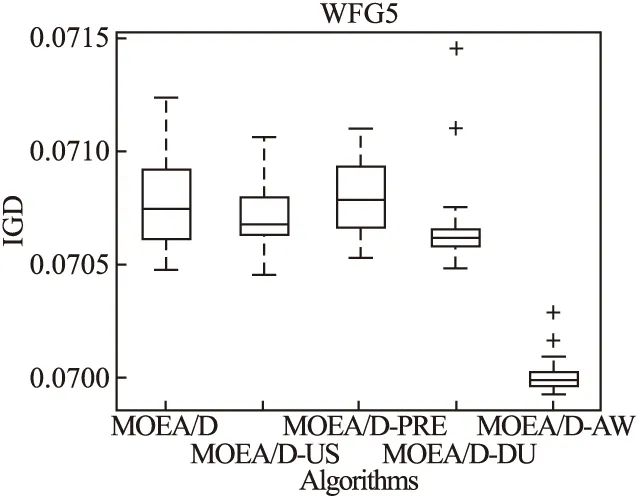
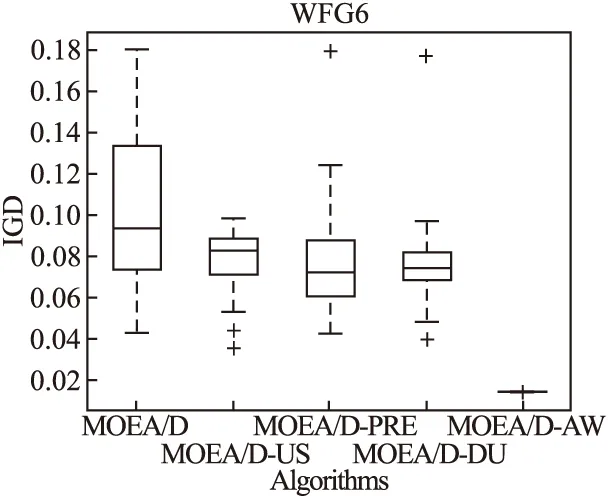
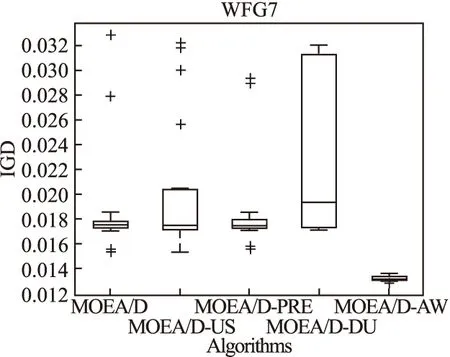
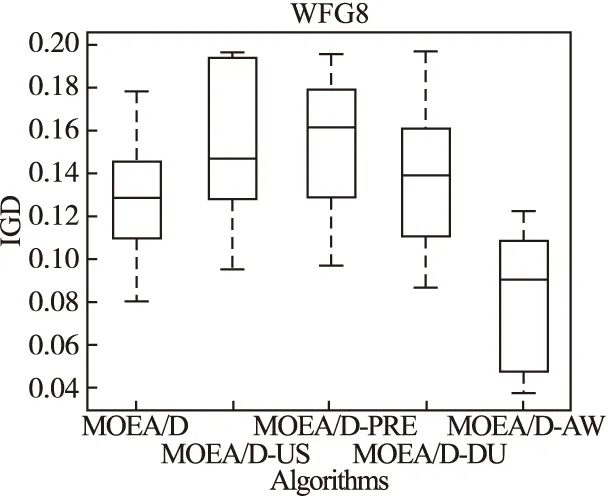
Step 2.3.更新z:若fj(y′) Step 2.4.更新邻域解:若gte(y′|λj,z)≤gte(xj|λj,z),j∈B(i),则xj=y′,FVj=F(y′). Step 3.线性插入搜索方向并更新解集:若算法迭代次数大于或者等于Adjust_Gen,每隔delta代,使用线性插入搜索方向策略;具体步骤为,计算每个个体的k近邻值,找出k近邻最大的个体对应的子问题记为indexMax,找出k近邻最小的个体对应的子问题记为indexMin.删除indexMin对应的个体,找到indexMax对应的个体,计算方向向量与indexMax个体方向向量最近的两个个体,序号记为addindex1和addindex2,假设addindex1个体对应的k近邻值大于addindex2个体对应的k近邻值,确定加入的搜索方向向量在indexMax与addindex1之间,反之为indexMax与addindex2之间.根据以上找出的两个个体,对其方向向量求均值,线性插入一个方向向量,并转换为权重向量,在以上的两个个体中随机复制某一个个体(仅复制x与f(x)值)给新增的个体.最后重新计算邻域并更新z(示意图如图4所示). 图3 WFG1的IGD指标对比Fig.3 Index comparison of IGD of WFG1 Step 4.停止判断:若满足停止条件,则算法停止,输出PF,否则返回Step 2继续执行. 图4 WFG2的IGD指标对比Fig.4 Index comparison of IGD of WFG2 对于步骤3中,在算法迭代次数大于一定值,周期性引入线性插入搜索方向向量的策略的解释如下:算法在初期,解集随机产生,并不具备任何代表性,此时解集的分布远离真实的Pareto前端,因此需要在进化到一定的代数后,解集能够显示出Pareto前端大概分布的情况下开始尝试调整搜索方向,达到均匀分布解集的效果.周期性的调整是为了使新增的个体有着一定的时间去使用种群的进化,有利于种群在进化过程中保留相对较好的解. 本文选择典型的二维测试函数WFG1-WFG9[20],选择算法为原始的MOEA/D,使用均匀分布的方向向量MOEA/D-US,使用预处理的MOEA/D-pre和MOEA/D-DU算法,与本文提出的MOEA/D-AW算法进行性能对比分析.与MOEA/D对比的原因在于,本文的算法是在其基础上改进,而MOEA/D-US则是为了排除采用均匀搜索方向这一措施产生的影响,使得比较更加公正.至于后两者都是复杂PF的算法类型,对比是为了验证改进算法的性能.性能评价指标采用世代距离指标(GD)[21]、Spacing指标(SP)[22]、反向世代距离指标(IGD)[23]、超体积指标(HV)[24]对解集收敛性、多样性及整体性能进行对比分析.各算法对每个测试函数独立运行20次. 本次实验采用的实验条件如下:平台为Intel(R)Core(TM)i3,4.00GB RAM,实验环境为MATLAB2014a.算法的种群为100,迭代次数为800,目标维度为2,邻域大小为20,单次替换最大个数为5,分别独立运行20次,杂交算法为差分算子,杂交概率为0.9,F为0.5,CR为0.5,变异为多项式变异,变异位置为20,变异概率为1/n,其中n为测试函数的变量个数. 为分析改进算法相比原始算法求得解集的收敛性及多样性,本次实验选择以上给出的GD指标和S指标分别对算法的收敛性及多样性进行比较.GD指标中,在标准的Pareto前端上采样500个点,所得结果如表1所示. 表1 两种算法的GD均值及S均值 测试问题GD均值S均值MOEA/DMOEA/D-AWMOEA/DMOEA/D-AWWFG10.08780.06830.03510.0386WFG20.00140.00150.03880.0220WFG30.07560.05930.02380.0138WFG40.16340.13100.02530.0163WFG50.12760.10830.02510.0148WFG60.00890.00100.02580.0160WFG70.08760.07420.02460.0155WFG80.03040.03550.02630.0278WFG90.06720.06070.02230.0156 表1给出两种算法在WFG1-WFG9测试问题上的GD均值和S均值.观察GD均值中的MOEA/D-AW算法一栏可知,除了WFG2和WFG8,其他的测试问题上,改进算法求出的解集的GD均值均比原始算法求出解集的GD均值小,WFG4测试问题上最明显.表明采用均匀搜索方向和线性插入搜索方向策略后,可以改进算法求出解集的收敛性.原因在于,进化过程中,根据算法求出解集的分布性,适当调整搜索方向,进而调整对应的权重向量,可以有效地引导解集朝向真实的PF,避免部分个体陷入局部最优,提高算法的收敛性.至于WFG2和WFG8,改进算法的效果相对略差.观察表1中S均值对应的两列,可以得出,大部分的测试函数,改进的算法的S均值相比原始的MOEA/D算法求出的解集的S均值小很多,说明采用线性插入方向向量,进化过程中根据解集的分布性,通过探测真实的PF,不断调整搜索的方向,删除密集区域的重复个体,稀疏区域增加个体,有利于提高算法的多样性.以上两组数据表明,改进的算法可以提高求出解集的收敛性与多样性. 为比较改进算法与原始算法求得解集收敛性与多样性的整体性能.本次测试采取能够评价算法整体性能的IGD指标,采样点数为500点.为简易直观显示出MOEA/D与MOEA/D-AW两种算法的性能,以下将给出5种算法在9种测试问题上的箱须图. 由图3至图11可知:在使用IGD指标对算法的整体性能进行测试时,结果显示出MOEA/D-AW算法求出IGD的均值在以上的几个测试问题均比MOEA/D等其它4个算法求出均值小;除了WFG9函数,MOEA/D-AW算法求出的IGD均值与MOEA/D算法求出均值相差不大,但在该测试问题上,MOEA/D-AW算法求出IGD指标的方差比MOEA/D算法求出IGD指标的方差小很多(MOEA/D-AW算法的盒子长度比MOEA/D盒子长度小很多),说明MOEA/D-AW求解性能更加稳定,其他的几幅图中也可观测出稳定性;在WFG1,WFG3-WFG7几个测试问题上,可以看出MOEA/D-AW求出结果的IGD指标的均值,最小值,最大值均比原始的MOEA/D算法求出的指标值小很多,说明MOEA/D-AW中采用线性调整权重向量的策略能够根据进化过程中求出的解集分布适当地调整搜索向量,有效地解决稀疏区域甚至不连续区域搜索向量的资源浪费问题,极大地增加了算法求解的多样性,同时使用更多的个体搜索解,增大算法求解的收敛性,从而极大地提高了算法的整体求解性能. 图5 WFG3的IGD指标对比Fig.5 Index comparison of IGD of WFG3 图6 WFG4的IGD指标对比Fig.6 Index comparison of IGD of WFG4 图7 WFG5的IGD指标对比Fig.7 Index comparison of IGD of WFG5 图8 WFG6的IGD指标对比Fig.8 Index comparison of IGD of WFG6 图9 WFG7的IGD指标对比Fig.9 Index comparison of IGD of WFG7 图10 WFG8的IGD指标对比Fig.10 Index comparison of IGD of WFG8 为进一步分析改进算法的求出解集的整体性能,本次实验选择更为精确的超体积(HV)指标度量,超体积即被非支配解集覆盖的目标空间区域大小,其度量方法,在理论上具有良好的数学性质,即在所有的一元测度中,是一个能够判定非支配解集比另一个非支配解集更优的有效方法,其值越大,解集质量越高.比较的算法有如下几种:原始的MOEA/D,MOEA/D-US,MOEA/D-pre,MOEA/D-DU,MOEA/D-AW,HV指标中采样点数为100000,参考点为1.2*F(max),其中F(max)为所求解集的各个分量的最大值.便于直观地比较,以下分别给出5种算法在WFG1-WFG9测试问题上的HV指标的箱须图. 图11 WFG9的IGD指标对比Fig.11 Index comparison of IGD of WFG9 图12至图20分别为MOEA/D,MOEA/D-US,MOEA/D-pre,MOEA/D-DU和MOEA/D-AW在WFG1-WFG9测试函数上算法独立运行20次,得到的超体积指标值对比图.分析以上9幅图可以得出如下几点结论: 图12 WFG1超体积指标对比Fig.12 Comparison of WFG1 hyper volume index 1)MOEA/D-US算法求出解集的HV指标值对应的盒须图的中值基本上都略高于MOEA/D算法求出解集的HV指标值的中值,WFG1,WFG6,WFG9测试函数上显示出MOEA/D-US算法求出解集的HV指标值分布相比原始的MOEA/D算法求出的HV指标值更为集中.表明采取均匀的搜索方向比均匀的权重向量略好. 图13 WFG2超体积指标对比Fig.13 Comparison of WFG2 hyper volume index 2)对比MOEA/D,MOEA/D-US,MOEA/D-AW三个算法在以上九个测试函数上的HV指标值分布情况看,MOEA/D-AW算法求出解集的HV指标值的最小值(盒须图的最下面的横线)中值及最大值(盒须图的最上面的横线)均大于(高于)MOEA/D-US算法求出的HV指标对应的值,表明本文提出的线性插入方向向量的策略有利于提高算法求得解集的整体质量.除了WFG2测试函数以外,其他的几个测试函数对应的图上显示出, MOEA/D-AW算法求出解集的HV指标值的离散程度远远小于MOEA/D-US,MOEA/D算法的求出解集的HV指标值.表明引入线性插入搜索方向策略可以提高算法的求解的稳定性.得出质量相对较好的解集. 图14 WFG3超体积指标对比Fig.14 Comparison of WFG3 hyper volume index 图15 WFG4超体积指标对比Fig.15 Comparison of WFG4 hyper volume index 图16 WFG5超体积指标对比Fig.16 Comparison of WFG5 hyper volume index 3) 以上9幅图均显示出MOEA/D-AW算法求出的解集的HV指标对应的盒须图的最小值、中值、最大值都高于其他的四个算法求出的解集的HV指标对应的值,表明引入线性插入搜索方向策略,根据进化过程中解集的离散分布情况,适当调整搜索方向,通过减少密集区域的搜索方向,去除重复的个体,稀疏区域增加搜索方向,增加新的个体,引导解集均匀分布在Pareto前端,有利于提高算法求解的整体质量,得到更优的解.WFG6,WFG7测试函数上显示出算法求出高质量解集稳定性更好(对应的盒须图长度最短),WFG1,WFG4,WFG6,WFG9测试函数上的结果显示出MOEA/D-AW求出解集的HV指标的中值远远大于其他的四种算法求出超体积指标的中值,再次验证引入线性插入搜索方向策略,能够求出质量更好的解集. 图17 WFG6超体积指标对比Fig.17 Comparison of WFG6 hyper volume index 图18 WFG7超体积指标对比Fig.18 Comparison of WFG7 hyper volume index 图19 WFG8超体积指标对比Fig.19 Comparison of WFG8 hyper volume index 4) 以上的几幅图显示出MOEA/D-pre,采用预处理的方式调整权重向量仅能略微提高算法的性能,MOEA/D-DU相比前面的三种略好,但是相比MOEA/D-AW,性能则差很多,原因在于,MOEA/D-DU仅注意到新产生的个体到子问题的垂直距离,并没有考虑复杂Pareto前端带来的影响. 以下给出5种算法在9种测试函数上的HV均值(HV最大值)的详细数据(表2). 图20 WFG9超体积指标对比Fig.20 Comparison of WFG9 hyper volume index 表2 4种算法对应的HV均值及HV最大值 测试问题MOEA/DMOEA/D-USMOEA/D-preMOEA/D-DUMOEA/D-AWWFG10.5276(0.5494)0.5412(0.5900)0.5324(0.5709)0.5990(0.6486)0.6769(0.6982)WFG20.4575(0.4718)0.4588(0.4676)0.4566(0.4691)0.4627(0.4699)0.5478(0.6893)WFG30.6393(0.6475)0.6405(0.6465)0.6412(0.6470)0.6401(0.6467)0.6473(0.6503)WFG40.4244(0.4359)0.4266(0.4351)0.4258(0.4363)0.4271(0.4319)0.4494(0.4528)WFG50.4252(0.4294)0.4248(0.4291)0.4244(0.4271)0.4257(0.4279)0.4287(0.4310)WFG60.4066(0.4269)0.4098(0.4351)0.4087(0.4360)0.4082(0.4275)0.4509(0.4535)WFG70.4448(0.4528)0.4456(0.4533)0.4431(0.4549)0.4439(0.4546)0.4508(0.4539)WFG80.3721(0.4022)0.3150(0.4164)0.3052(0.4040)0.3452(0.4008)0.4204(0.4522)WFG90.4167(0.4445)0.4155(0.4359)0.4130(0.4352)0.4121(0.4381)0.4350(0.4419) 表2中给出5种算法在以上9个测试函数上的超体积指标均值及最大值的具体数值,结果显示出对于所有的测试函数,MOEA/D-AW算法求出的超体积指标的均值都大于其他四种算法求出解集的超体积指标对应的均值,表明引入线性插入搜索方向策略及均匀分布的搜索方向向量策略后,算法求解的性能极大地提高.在WFG1,WFG2,WFG6测试函数上,改进的算法性能提高的效果尤为显著.至于改进算法MOEA/D-AW求出解集超体积指标值的最大值,除了WFG7和WFG9测试函数以外,基本上大于其他的四种算法,表明改进算法的具有求出更高质量的解集. 本文首先通过分析均匀分布的权重向量,均匀分布的搜索方向向量及均匀分布的最优解集之间的关系,提出MOEA/D中应采取均匀分布的搜索方向向量产生策略.进一步分析复杂Pareto前端的几种情况,鉴于现实生活中的多目标测试问题的前端一般都是未知,提出了能够获得更为均匀的线性插入搜索方向的策略,并与原始的MOEA/D算法相结合,提出MOEA/D-AW的改进算法.通过对WFG1-WFG9多种典型的测试函数进行算法性能测试,仿真实验结果采用GD指标,S指标分别度量解集的收敛性与多样性.实验证明,改进的算法能够获得收敛性更好,分布相对均匀的解集.最后,为验证算法求出解集的整体质量,采用更严格地,具有代表性的超体积指标度量MOEA/D-AW相比MOEA/D等四种算法的性能,结果证明改进的算法MOEA/D-AW求出解集的整体质量有着显著地提高.后续的研究中,将进一步研究在高维空间中如何动态,并且准确的引入线性插入搜索方向,尽可能提高解集的多样性,从而提高解集的整体质量.
5 仿真实验及结果分析
5.1 算法的GD指标、S指标测试
Table 1 Mean value of GD and the mean value of S
of the two algorithms.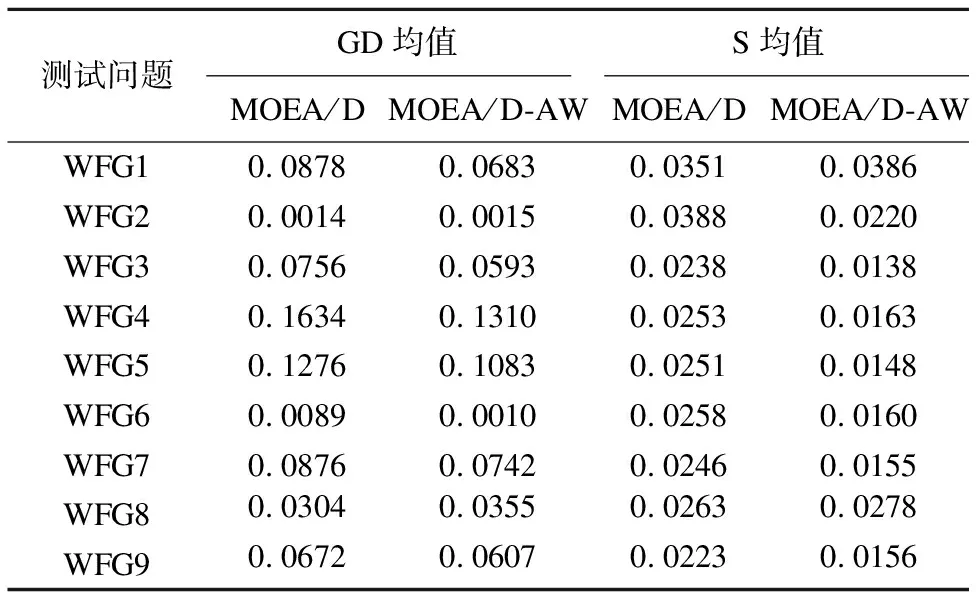
5.2 算法的IGD指标测试

5.3 算法的HV指标测试

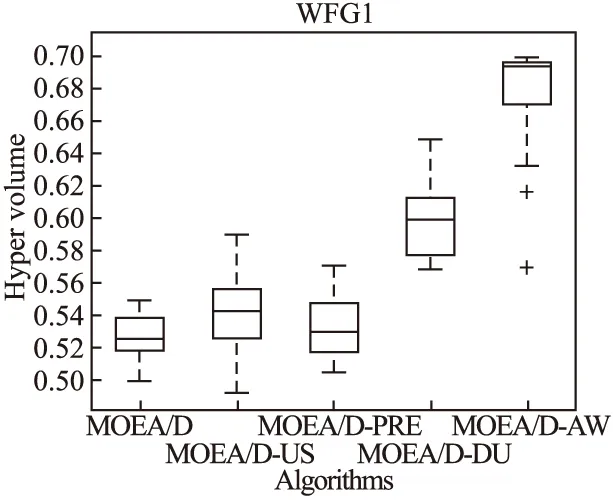
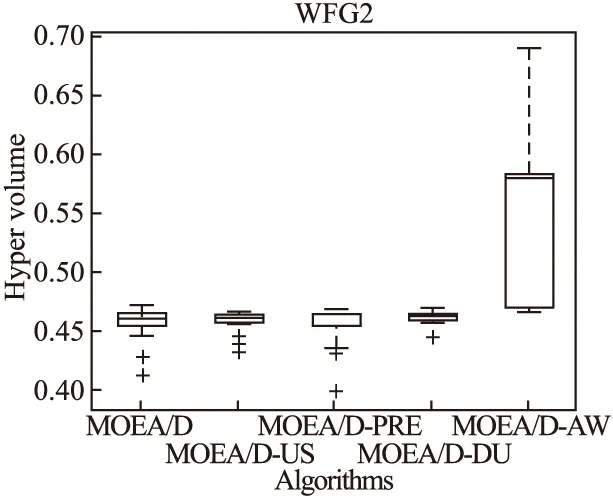
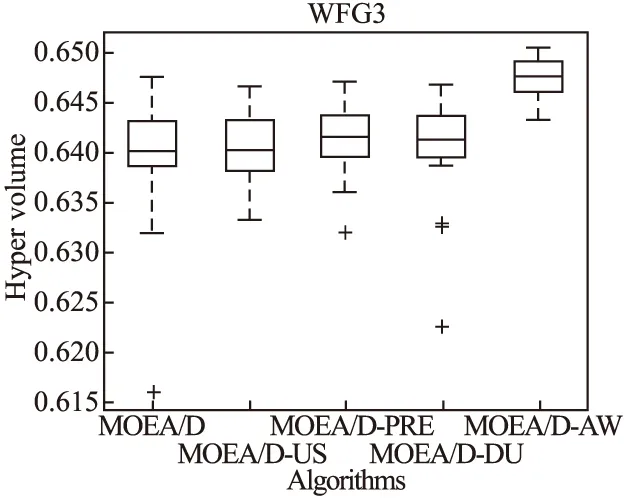

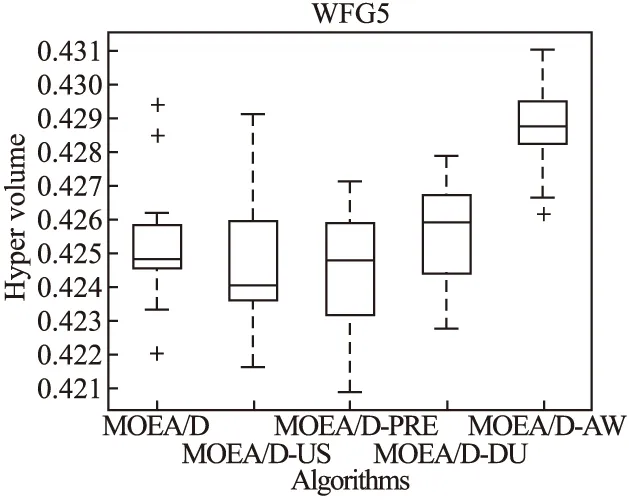
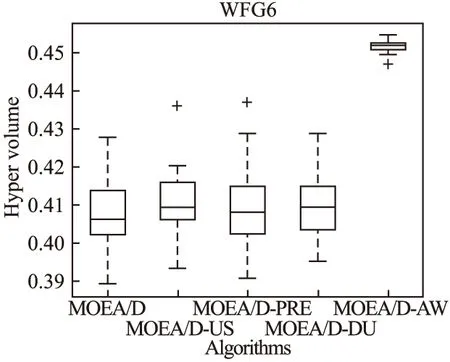
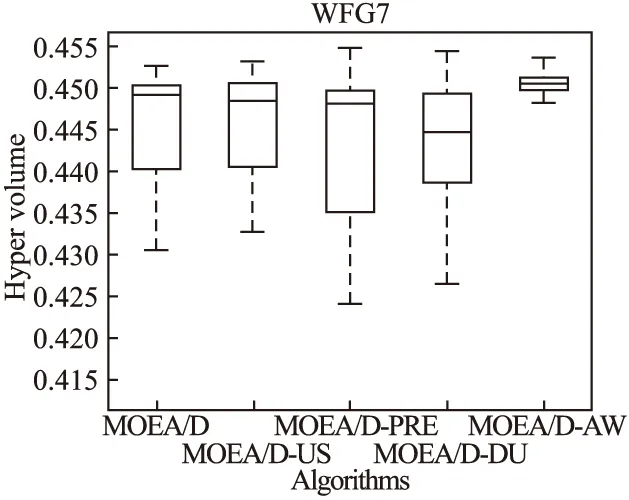

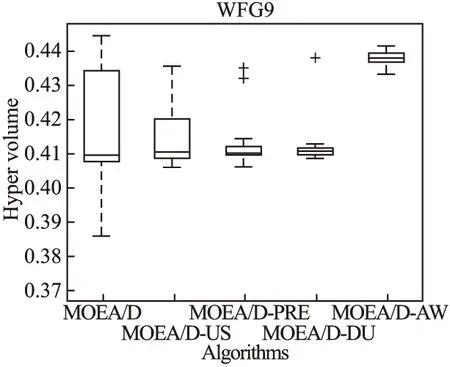
Table 2 Mean value and maximum value of HV of the four algorithms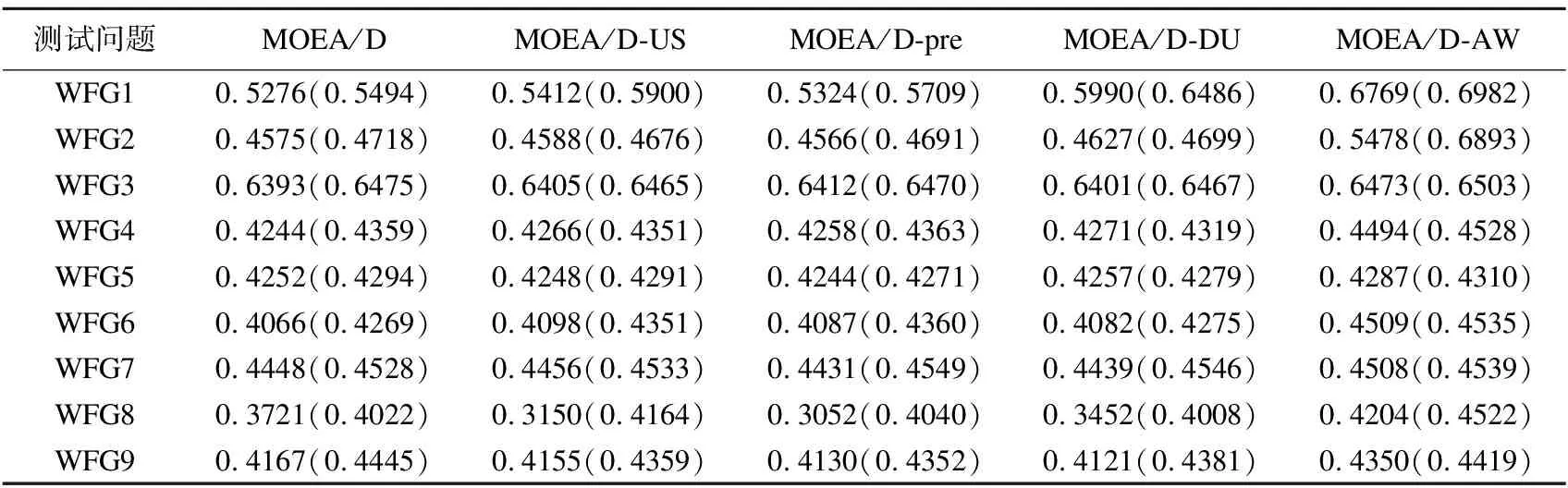
6 结 论
