自我注意力机制中基于相对位置的句子表示方法
2020-05-09徐若易李金龙
徐若易,李金龙
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
1 引 言
句子表示方法是自然语言处理(NLP)任务的基础之一,一般是用一个向量来表示句子.对于不同的任务,有两种常用的结构:卷积神经网络(CNN)和循环神经网络(RNN).RNN通过时序结构捕获长句特征[1],以最后一个隐含状态向量或所有隐含状态向量的组合(串联、加和、均值或最大值)来表示句子,而CNN通过n元词组捕获短语特征[2],以词语向量的组合来表示句子.近年来,注意力机制作为额外信息被用于生成句子表示,如机器翻译[3],阅读理解[4,5]和情感分析[6]等.与RNN和CNN相比,注意力机制有三点优势:①在捕捉句子特征方面,更加灵活,不限于RNN的时序结构,也不止于CNN的短语结构;②在模型的可解释性方面,对重点词以及词组有更高的权值,更直观;③在模型训练方面,注意力机制计算的并行度远高于RNN,不亚于CNN.
注意力机制使用额外信息来获得句子表示,这里的额外信息通常指需要查询的信息,例如阅读理解任务中的原文本信息,然而注意力机制不适合只有单个句子作为输入的任务,例如情感分析任务.为了解决这一问题,Lin等人提出自我注意力机制[7],它能够从单个输入句子中提取多个不同的向量表示作为额外信息,此方法还能减轻上游RNN的长期记忆负担.Vaswani等人率先提出不使用RNN、CNN结构而仅仅使用注意力机制来获得句子表示的方法[8],在他们的模型中,自我注意力机制也被广泛使用.
但是,Vaswani等人也在他们的研究中发现自我注意力机制缺少词语间相对位置信息的问题,因此他们在模型中加入了对已考虑的词汇信息屏蔽的措施,来避免顺序信息的丢失.在句子的局部信息方面,Im等人提出基于距离的自我注意力网络[9](Distance-based Self-Attention Network,DbSAN),用词语之间的距离信息对自我注意力值加惩罚,考虑了词语间相对距离的信息.另外,Shen等人提出强化自我注意力网络[10](Reinforced Self-Attention Network,ReSAN),结合强化学习手段,寻找关联较大的词对,考虑了词语间的相对位置信息.
本文提出了基于相对位置自我注意力网络(Relative Positional Self-Attention Network,RPSAN)来得到句子表示,不仅考虑了句子的顺序信息,也考虑了句子的局部信息.这符合我们的阅读过程,既会考虑句子中局部词语所表达的意思,也会考虑上下文关联起来的意思.总的来说,我们的RPSAN有以下创新点:
①针对句子的局部信息,提出了远距离屏蔽矩阵,通过将距离较远的自我注意力值置为零,能够生成不考虑较远词的句子表示;
②为了获得包含更多信息的句子表示,并且避免训练权值过多,我们设计了融合机制,将不同的句子表示整合为一个;
③我们在SST数据集和四个公开的文本分类数据集上进行实验,与其他方法对比的结果证明了我们方法的有效性.
2 基于相对位置的自我注意力句子表示方法
2.1 词向量表示方法
GloVe[11](Global Vectors)是一种用于获得词的向量表示的无监督学习算法.GloVe对整个语料库的词对共现频度进行统计,并设计代价函数训练,所得到的词向量表示能以向量的接近程度(例如余弦相似度)来衡量词的相似度.进一步,直接用词向量拼接而成的句子表示,我们称之为句子的词向量表示.
本文中所有模型均基于GloVe方法得到的词向量.
2.2 注意力机制
注意力机制通过计算句子和额外信息的相互关系,得到句子中每一个词的权重,最后加权得到句子表示.
具体情况下,对于一句话的词向量表示v=[v1,v2,…,vn]和额外信息向量q∈dq,其中n表示句子有n个词,vi∈dv是第i个词向量表示,dq和dv分别表示额外信息向量和词向量的维度.注意力机制通过兼容函数f(vi,q)来计算vi和q之间的关联分数,兼容函数如公式(1)所示:
f(vi,q)=wTσ(W(1)vi+W(2)q)
(1)
其中W(1)∈dh×dv、W(2)∈dh×dq和w∈dh是待训练的权值,T表示转置,σ(·)是激活函数,这里激活函数作用于矩阵,矩阵中每一个元素都经过激活函数作用后得到矩阵输出,且有f(vi,q)∈.
由兼容函数f(vi,q),我们能得到每个词的权重p(z|v,q),如公式(2)所示:
(2)
p(z|v,q)表示在额外信息q下,第z个词的权重.最终,在额外信息q下的句子表示s如公式(3)所示:
(3)
这里有s∈dv.
2.3 自我注意力机制
自我注意力机制是注意力机制的一个变体,其实是注意力机制的多次使用.具体来说,对于句子的词向量表示v=[v1,v2,…,vn],我们将每个词向量vj,j∈{1,2,…,n}作为公式(3)中的额外信息向量q,利用注意力机制,会得到句子表示sj=Attention(v,vj),j∈{1,2,…,n},我们将n个注意力机制产生的句子向量表示sj拼接到一起,最终自我注意力机制得到的句子表示就是S=[s1,s2,…,sn].形式化的,自我注意力机制如公式(4)所示:
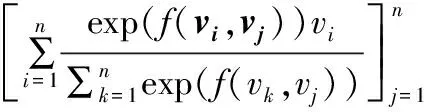
(4)
2.4 屏蔽矩阵
屏蔽矩阵一般用在自我注意力机制上,通过给兼容函数f(vi,vj)增加Mij,使p(z=i|v,vj)改变.带屏蔽矩阵的自我注意力(Masked Self-Attention,MSA)机制结构如图1所示,图中fi,j表示f(vi,vj),计算方式如公式(5)所示:
S=MSA(M,v)

(5)
如果Mij=0,那么由公式(2),p(z=i|v,vj)=0,屏蔽了特定位置的自我注意力值,就得到了在特定屏蔽矩阵M下的句子表示S.

图1 MSA结构图Fig.1 Masked self-attention
由于屏蔽矩阵能让我们考虑特定词对之间的关系,词之间的相对位置信息就能很明确的在模型中体现.我们给出两类屏蔽矩阵的设计:①基于局部信息的屏蔽矩阵;②基于顺序信息的屏蔽矩阵.
2.4.1 基于局部信息的屏蔽矩阵
我们提出远距离屏蔽(Distant Mask,Dt)矩阵MDt(c),这里c是超参,如公式(6)所示:
(6)
针对第j个词,远距离屏蔽不考虑距离大于c的词和第j个词本身,即远距离屏蔽只考虑2c+1元词组且不考虑中心词汇.
2.4.2 基于顺序信息的屏蔽矩阵
顺序信息一般指句子的方向,包含前向和后向.所以,有前向屏蔽(Forward Mask,Fw)矩阵MFw(7)和后向屏蔽(Backward Mask,Bw)矩阵MBw(8).
(7)
(8)
前向屏蔽矩阵不考虑第j个词及其之前的词,而后向屏蔽矩阵不考虑第j个词及其之后的词.
2.5 融合机制
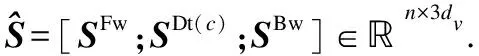
这里我们提出了一种新的融合机制(Fusion Mechanism),将不同的句子表示整合到一起,而且表示维度和原来的句子表示维度大小一样,如公式(9)-公式(12)所示:
a=softmax(WTv+b)
(9)
W=[Wv;WFw;WDt;WBw]
(10)
b=[bv;bFw;bDt;bBw]
(11)
a=[av;aFw;aDt;aBw]
(12)
这里有v∈dv×n,Wv,WFw,WDt,WBw∈dv×dv,W∈4×dv×dv,bv,bFw,bDt,bBw∈dv,b∈4×dv.则WTv+b∈4×dv×n,softmax函数对维度为4的第一维作用,之后得到a∈4×dv×n,切分后有av,aFw,aDt,aBw∈dv×n,分别表示v,SFw,SDt(c),SBw∈dv×n的权重.并由公式(13)获得最后整合后的句子表示
=av⊙v+aFw⊙SFw+aDt⊙SDt(c)+aBw⊙SBw
(13)
2.6 模型总结
我们的模型为基于相对位置的自我注意力网络(Relative Positional Self-Attention Network,RPSAN),模型结构如图2所示.
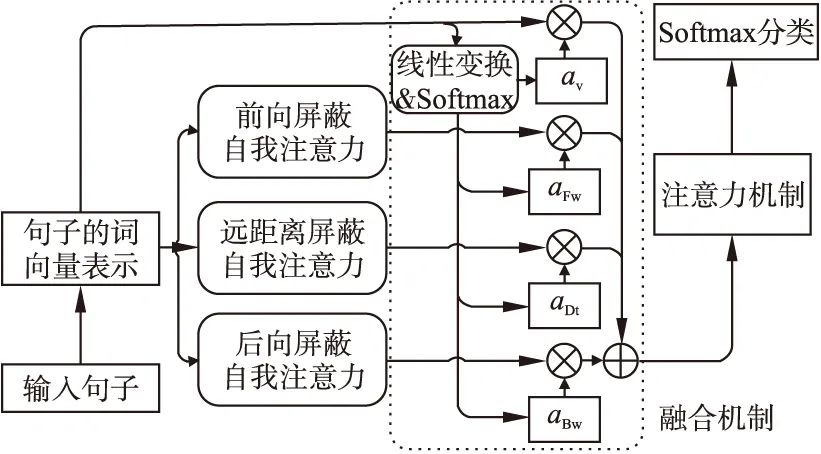
图2 RPSAN结构图Fig.2 Structure of the RPSAN
在我们的RPSAN中,给一个句子,首先我们通过GloVe词向量得到句子的词向量表示,然后我们通过公式(5)的MSA以及三种屏蔽矩阵(6)-(8)对句子的词向量表示进行编码,得到三种不同的句子表示.对这三种句子表示,外加句子的词向量表示共四种表示,应用融合机制,得到新的句子表示.最后,我们将该句子表示,应用到不同的下游模型,来解决不同的任务,例如,在RPSAN中,我们在新的句子表示之后接注意力机制模块和softmax分类模块,来解决情感分析任务、文本分类任务.
3 实验结果与分析
3.1 实验数据集
为验证RPSAN的有效性,我们在SST数据集和四个公开的文本分类数据集上验证该模型的性能.其中,SST目的是识别一句话的情感,文本检索会议(Text REtrieval Conference,TREC)是一种问题类型的分类数据集,顾客评论(Customer Reviews,CR)包括对各种产品的评论,多视角问答(Multi-Perspective Question Answering,MPQA)检测短语级别的意见,主观性(SUBJectivity,SUBJ)涉及将句子分类为主观还是客观.实验数据集详细信息如表1所示.表格中测试样本中为数字表示原数据已经划分出测试集合,而CV则表示交叉验证(Cross Validation).
表1 实验数据集描述
Table 1 Details of datasets
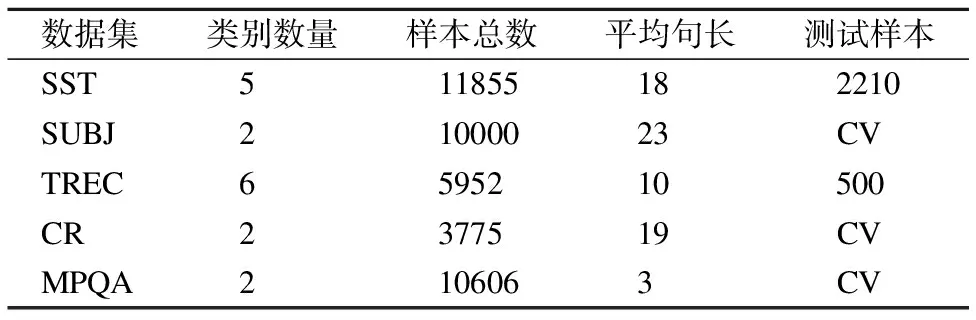
数据集类别数量样本总数平均句长测试样本 SST511855182210 SUBJ21000023CV TREC6595210500 CR2377519CV MPQA2106063CV
3.2 实验设置
对于所有任务,我们使用GloVe[11]方法预先训练的词向量GloVe-6B-300D来初始化我们的RPSAN中的词向量表示,词向量大小为300.对于训练集中的不在预先训练词向量中的词汇,我们使用(-0.05,0.05)的均匀分布来随机初始化这些词.我们将自我注意力机制中的隐藏节点数设为1,而其他未指定的隐藏节点数都设置为300.我们模型中的所有待训练权值都由Xavier[12]方法初始化,并且所有待训练偏差都是零初始化.我们在模型的各层之间添加了Dropout[13],以概率0.7保留信息.没有被指定的激活函数均设置为ELU[14].我们使用交叉熵损失和L2正则化惩罚之和作为最终的损失函数,L2正则化衰减因子是10-6.至于学习方法,我们使用随机梯度下降方法的改进算法Adadelta[15]来最小化损失函数.训练集一个批次大小为64,学习率为0.5.所有训练都使用TensorFlow-1.4.0,并在单个Nvidia GTX-1080Ti GPU卡上完成.
本文所有实验只要采用交叉验证,均采用1次10折交叉验证,未采用交叉验证的实验,均采用5次取平均.如果是有测试集合的数据集,每500次训练后保存模型权值,并在验证集上得到模型准确率表现,然后取验证集上准确率最高时的模型在测试集上得到结果,最终结果取5次的平均结果.如果是交叉验证,采取1次10折交叉验证,将数据集随机等分为10份,每次用9份作为训练集,用1份作为验证集,每100次训练后得到模型在验证集上的表现,取最好的准确率结果,最终结果是10份轮换训练的平均结果.
3.3 情感分析
情感分析的目的是识别一句话的情感倾向.斯坦福情感分析数据集(SST)包括8544个训练样本,1101个验证样本和2210个测试样本,每个句子都有0-10的情感打分.官方提出细粒度标签分割,以2分为一个阶段,以打分从高到低分成了5种情感:非常积极,积极,中性,消极,非常消极.
3.3.1 参数调整
我们对模型中部分参数进行了敏感度分析,包括①远距离屏蔽的距离大小c;②dropout的保留率dp;③L2正则化衰减因子wd.模型其他部分,例如词向量初始化方法、隐藏节点数、学习率大小、权值初始化方法、激活函数方法、优化器选择方法、训练批次大小等均视为模型设置.
我们对提出的三种参数进行了组合,以下列范围进行实验:①c∈{1,2,…,9};②dp∈{0.5,0.6,0.7,0.8,0.9};③L2正则化衰减因子wd∈{10-8,10-7,10-6,10-5,10-4}.每次实验都训练足够多的次数,每个参数组合做5次实验取平均结果.模型整体性较优时,参数的设置为:①远距离屏蔽的距离大小为3;②dropout的保留率为0.7;③L2正则化衰减因子为10-6.这里,我们给出在每个参数在另两个参数固定的情况下的变化曲线,如图3所示.

图3 参数敏感度分析Fig.3 Analysis of parameter sensitivity
3.3.2 模型比较
我们选取了三大类共7种情感分析模型进行比较:①RNN为基础的Bi-LSTM[16]、Tree-LSTM[17];②CNN为基础的CNN-non-static[2]、CNN-Tensor[18];③注意力机制为基础的Multi-head[8]、DiSAN[19]、Bi-BloSAN[20].
由于和我们的RPSAN相近,这里我们对以注意力机制为基础的模型进行详细的说明:1) Multi-head[8]:Vaswani等人提出的仅使用注意力机制来获得句子表示的方法,该方法不使用任何CNN或者RNN的结构,而主要使用了他们新提出的多头注意力(Multi-head Attention)模块; 2) DiSAN[19]:Shen等人提出的定向自我注意力网络(Directional Self-Attention Network,DiSAN),模型中的自我注意力机制用句子中每个词作为额外信息,并用屏蔽矩阵的方式在自我注意力机制中仅考虑前和后两个方向的句子信息; 3) Bi-BloSAN[20]:Shen等人提出的双向块状自我注意力网络(Bi-directional Block Self-Attention Network,Bi-BloSAN),以固定词语个数,生成短语表示,再以句子中所有短语表示,生成句子表示.
注意力机制为基础的模型的分类正确率由原论文参数及代码做5次实验取平均结果,括号内是标准差,RNN、CNN为基础的模型在SST上的分类正确率直接从论文中摘抄,没有标准差.训练权值数量由代码统计得到,单位为百万(Million).结果如表2所示.
表2 各模型在SST上分类准确率
Table 2 Test accuracy of various model on SST dataset
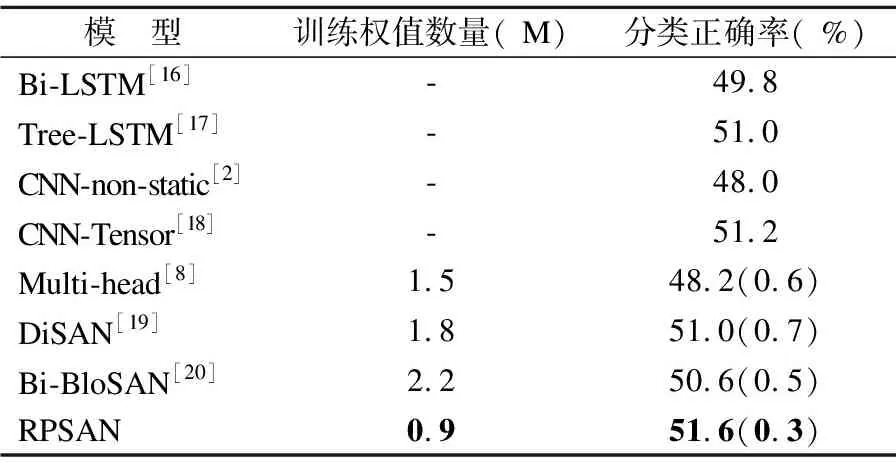
模 型训练权值数量( M)分类正确率( %)Bi-LSTM[16]-49.8Tree-LSTM[17]-51.0CNN-non-static[2]-48.0CNN-Tensor[18]-51.2Multi-head[8]1.548.2(0.6)DiSAN[19]1.851.0(0.7)Bi-BloSAN[20]2.250.6(0.5)RPSAN0.951.6(0.3)
从表2可以看出:①RPSAN的训练权值数量比其他以注意力机制为基础的模型都要低,这是由于我们设定自我注意力机制中的隐藏节点均为1,而非其他模型中的300,所以兼容函数中的权值数量大大减少,训练成本也随之减少;②RPSAN的分类正确率高于对比的各类模型,而且分类正确率的标准差低于其他以注意力机制为基础的模型,结果更加稳定.
3.4 文本分类
文本分类任务与情感分析任务略有不同,重点不在于情感的打分,而在于句子的类别,但视为分类问题上很相似.我们在四个数据集(SUBJ、TREC、CR、MPQA)上验证我们RPSAN得到的句子表示在分类任务上的性能.因数据集的选取问题,我们对比的模型略有不同,但对比重点都是注意力机制为基础的模型.表3是我们的模型在4个数据集上的参数设置,表4是实验结果.
表3 各个数据集上参数设置
Table 3 Parameter settings on various datasets
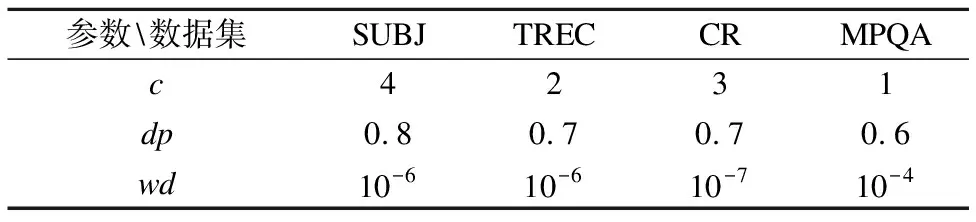
参数数据集SUBJTRECCRMPQAc4231dp0.80.70.70.6wd10-610-610-710-4
从表4可以看出,在注意力机制为基础的模型范畴内,我们的模型在MPQA数据集上能达到最好的分类正确率,而在SUBJ、TREC和CR数据集上分别超过最好的分类正确率0.1%、0.2%和0.6%.
4 结论与展望
在本文中,我们在自我注意力机制下提出了远距离屏蔽,针对句子中相对位置较近的词关系获得句子表示.此外,结合前向屏蔽和后向屏蔽,我们提出了融合机制来整个不同的句子表示.我们的RPSAN比DiSAN,Bi-BloSAN等目前最好的基于自我关注机制的模型在SST数据集上的训练成本更低,预测正确率更高,而且RPSAN在另外四个开放文本分类数据集上有着不低于其他模型的分类正确率.在未来的工作中,我们将尝试寻找一种结构能够自适应调整窗口大小的值,以适应数据集中不同长度的句子和不同语境下的词,并且我们将在更多任务中验证RPSAN的性能.
表4 文本分类任务分类正确率
Table 4 Test accuracies on sentence classification tasks

模 型SUBJTRECCRMPQACBOW[21]91.387.379.986.4Skip-thought[22]93.692.281.387.5DCNN[23]93.0---AdaSent[24]92.2(1.2)91.1(1.0)83.6(1.6)90.4(0.7)Multi-head[8]94.0(0.8)93.4(0.4)82.6(1.9)89.8(1.2)DiSAN[19]94.2(0.6)94.2(0.1)84.8(2.0)90.1(0.4)Bi-BloSAN[20]94.5(0.5)94.8(0.2)84.8(0.9)90.4(0.8)RPSAN94.6(0.7)95.0(0.2)85.4(1.4)90.4(0.8)
